手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)
手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)
目录
- 手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)
- Stable Diffusion 原理图
- Stable Diffusion的原理解释
- Stable Diffusion 和Diffusion 的Unet对比
- Lora 微调原理
- Stable Diffusion 添加lora微调代码
- Part1 添加lora.py文件 - 用于设置lora层以及替换
- 1. 引入相关库函数
- 2. 定义LoraLayer的类
- 3. lora层的替换
- Part2 添加lora_finetune.py,用于参数微调训练得到lora参数.pt文件
- 1. 引入相关库函数
- 2. 替换模型中的注意力机制里面的Wq, Wk, Wv,替换线性层
- Part3 修改 denoise.py,修改测试的时候的lora参数加入
- 1. 引入相关库函数
- 2. 定义去噪的函数
- 3. 测试-去噪
- 参考
Stable Diffusion 原理图
Stable Diffusion的原理解释
Stable Diffusion的网络结构图如下图所示:

- 改动1:利用 AE,VAE,VQVAE 等自编码器,进行了图像特征提取,利用正确提取特征后的图像作为自己原本在Diffusion中的图像。
- 改动2:在训练过程中,额外添加了一些引导信息,促使图像生成,往我们所希望的方向去走,这里添加信息的方式主要是利用交叉注意力机制(这里我看图应该是只用交叉注意力就行,但是我看视频博主用的代码以及参照的Stable-Diffusion Unet图上都是利用的Transoformer的编码器,也就是得到注意力值之后还得进行一个feedforward层)。
- **改动3:**利用 AE,VAE,VQVAE 等自编码器进行解码。(这个实质上和第一点是重复的)
- **注意:**本次的代码改动先只改动第二个,也就是添加引导信息,对于编码器用于减少计算量,本次改进先不参与(555~,因为视频博主没教),后续可能会进行添加(因为也比较简单)。
Stable Diffusion 和Diffusion 的Unet对比


- 我们可以发现,两者之间的区别主要在于,在卷积完了之后添加了一个Transformer的模块,也就是其编码器将两个信息进行了融合,其他并没有改变。
- 所以主要区别在卷积后的那一部分,如下图。

- 这个ResnetBlock就是之前的卷积模块,作为右边的残差部分,所以这里写成 了ResnetBlock。
- 因此,如果我们将Tranformer模块融入到Restnet模块里面,并且保持其输入卷积的图像和transformer输出的图像形状一致的话,那么就其他部分完全不需要改变了,只不过里面多添加了一些引导信息(MNIST数据集中是label,但是也可以添加文本等等引导信息) 而已。
Lora 微调原理
- LoRA算法

- 算法过程:对于原先的参数不改变,通过右边添加一个参数矩阵来进行微调,也就是利用新的参数矩阵来微调拟合新领域的参数和初始参数的差距。也就是ΔW。
理论:预训练大型语言模型在适应新任务时具有较低的“内在维度” , 所以当对于一个预训练模型来说,原先的参数是有非常多的冗余的,因此我们可以利用低维空间(也就是降维)去表示目标参数和原先参数之间的距离。因此ΔW是相对W来说维度非常小的,减少了非常多的参数量。
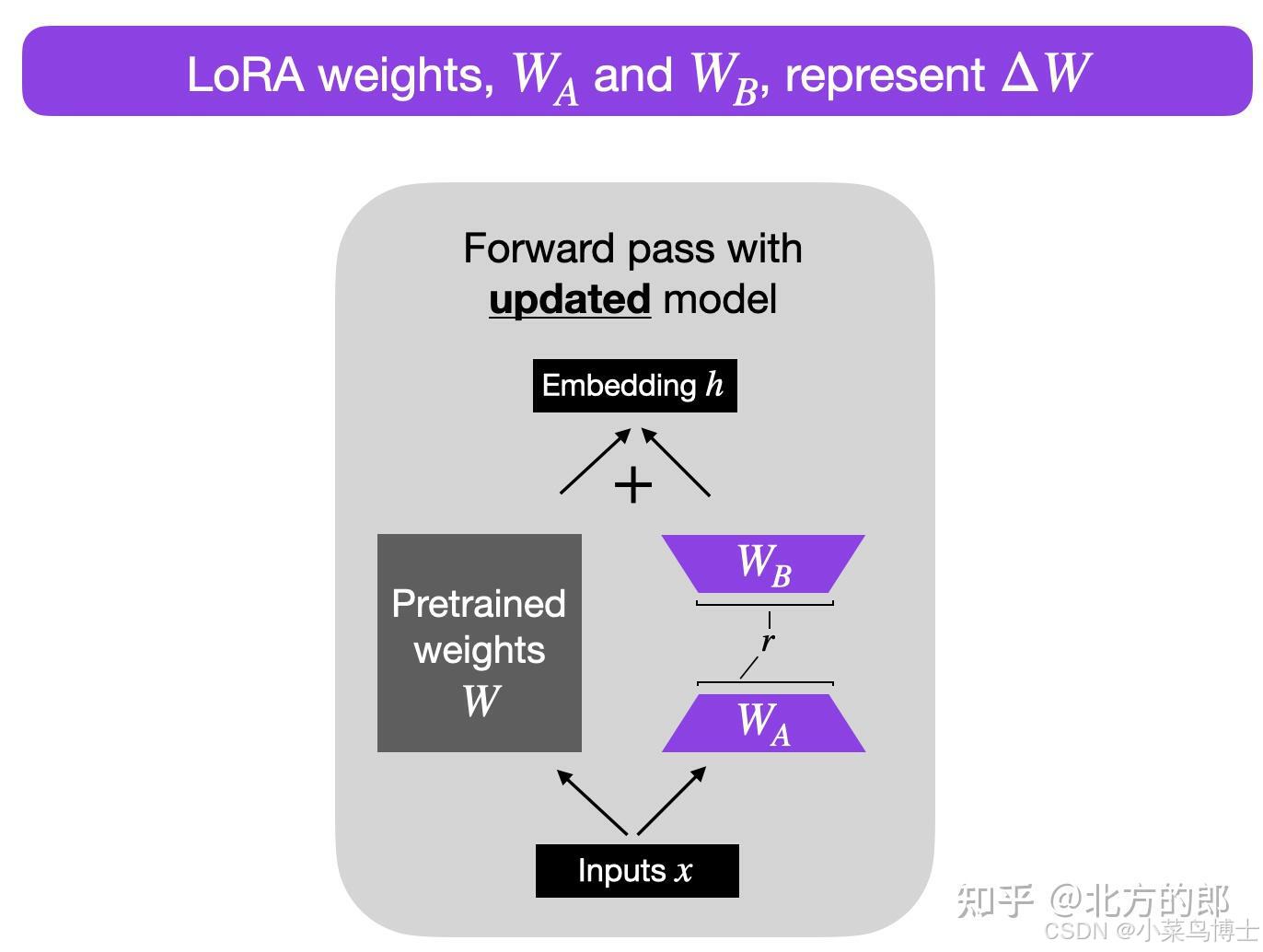
-
因为要保证输入和输出的维度和原本的参数W一样,所以一般参数输入的维度还是相同的,但是中间的维度小很多,从而达到减少参数量的结果。比如原本是100x100的参数量,现在变为100x5(r)x2,减少了10倍。
- 其中r就是低秩的那个秩数。可以自定义。
o u t p u t = n e t ( x ) + t o r c h . m a t m u l ( x , t o r c h . m a t m u l ( l o r a a , l o r a b ) ∗ a l p h a ( 可能这里也会除以 r ) output=net(x)+torch.matmul(x,torch.matmul(lora_a,lora_b)*alpha(可能这里也会除以r) output=net(x)+torch.matmul(x,torch.matmul(loraa,lorab)∗alpha(可能这里也会除以r)
alpha或者alpha/r 是一个缩放因子,用于调整组合结果(原始模型输出加上低秩自适应)的大小。这平衡了预训练模型的知识和新的特定于任务的适应——默认情况下,alpha通常设置为 1。另请注意,虽然W A被初始化为小的随机权重,但WB被初始化为 0,因此训练开始时ΔW = WAxWB = 0 ,这意味着我们以原始权重开始训练。
Stable Diffusion 添加lora微调代码
Part1 添加lora.py文件 - 用于设置lora层以及替换
1. 引入相关库函数
# 该模块主要是实现lora类,实现lora层的alpha和beta通路,把输入的x经过两条通路后的结果,进行联合输出。
# 然后添加一个函数,主要是为了实现将原本的线性层换曾lora层。
'''
# Part1 引入相关的库函数
'''
import torch
from torch import nn
from config import *
2. 定义LoraLayer的类
'''
# Part2 设计一个类,实现lora_layer
'''
class LoraLayer(nn.Module):
def __init__(self, target_linear_layer, feature_in, feature_out, r, alpha):
super().__init__()
# 第一步,初始化lora的一些参数,包含a矩阵,b矩阵,r秩.比例系数等等。
self.lora_a = nn.Parameter(torch.empty(feature_in, r), requires_grad=True)
self.lora_b = nn.Parameter(torch.zeros(r, feature_out), requires_grad=True)
self.alpha = alpha
self.r = r
# 第二步对alpha进行初始化
nn.init.kaiming_uniform_(self.lora_a)
# 第三步,初始化原本的目标线性层
self.net = target_linear_layer
def forward(self, x):
output1 = self.net(x)
output2 = torch.matmul(x, torch.matmul(self.lora_a, self.lora_b)) * (self.alpha / self.r) # 得到结果后,乘上比例系数(alpha/r)
return output2 + output1
3. lora层的替换
'''
# Part3 定义一个函数,实现lora层的替换
'''
def inject_lora(module, name, target_linear_layer): # 输入完整的模型,目标线性层的位置,目标线性层
name_list = name.split('.') # 按照.进行拆分路径
# 获取到目标线性层的模型的上一层所有参数和模型{模型name1:模型,模型name2:模型}
for i, item in enumerate(name_list[:-1]):
module = getattr(module, item)
# 初始化需要替换进入的lora层
lora_layer = LoraLayer(target_linear_layer,
feature_in=target_linear_layer.in_features, feature_out=target_linear_layer.out_features,
r=LORA_R, alpha=LORA_ALPHA)
# 替换对应的层
setattr(module, name_list[-1], lora_layer)
Part2 添加lora_finetune.py,用于参数微调训练得到lora参数.pt文件
1. 引入相关库函数
# 该模块主要实现对于模型的一些模块进行微调训练,只对lora里面的新增参数进行训练。
'''
# Part 1 引入相关的库函数
'''
import os
import torch
from torch import nn
from dataset import minist_train
from torch.utils import data
from diffusion import forward_diffusion
from config import *
from unet import Unet
from lora import inject_lora
2. 替换模型中的注意力机制里面的Wq, Wk, Wv,替换线性层
if __name__ =='__main__':
'''
# Part2 对需要训练的模型参数进行设置,将需要替换的线性层进行lora替换,并且只对lora进行训练
'''
# 首先第一步得先下载网络
net = torch.load('unet_epoch0.pt')
# 开始对所需的部分进行替换。
# 首先,我们要对线性层进行lora替换,所以需要,输入inject_lora的参数包含(整个模型,路径,layer)
for name, layer in net.named_modules():
name_list = name.split('.')
target = ['Wq', 'Wk', 'Wv']
for i in target:
if i in name_list and isinstance(layer, nn.Linear):
# 替换
inject_lora(net, name, layer)
# 替换完之后,先看看需不需要添加之前的参数
try:
# 先下载参数
lora_para=torch.load('lora_para_epoch0.pt')
# 再填充到模型里面
net.load_state_dict(lora_para,strict=False)
except:
pass
# 替换完之后,需要对所有的参数进行设置,不是lora的参数梯度设置为False
for name, para in net.named_parameters():
name_list = name.split('.')
lora_para_list = ['lora_a', 'lora_b']
if name_list[-1] in lora_para_list:
para.requires_grad = False
else:
para.requires_grad = True
'''
# Part3 进行训练
'''
epoch = 5
batch_size = 50
minist_loader = data.DataLoader(dataset=minist_train, batch_size=batch_size, shuffle=True)
# 初始化模型
loss = nn.L1Loss()
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
n_iter = 0
net.train()
for i in range(epoch):
for imgs, labels in minist_loader:
imgs = imgs * 2 - 1
# 先随机初始化batch_t
batch_t = torch.randint(0, T, size=(imgs.size()[0],))
# 首先对清晰图像进行加噪,得到batch_x_t
batch_x_t, batch_noise = forward_diffusion(imgs, batch_t)
# 预测对应的噪声
batch_noise_pre = net(batch_x_t, batch_t, labels)
# 计算损失
l = loss(batch_noise, batch_noise_pre)
# 清除梯度
opt.zero_grad()
# 损失反向传播
l.backward()
# 更新参数
opt.step()
# 累加损失
last_loss = l.item()
# 更新迭代次数
n_iter += 1
print('当前的iter为{},当前损失为{}'.format(n_iter, last_loss))
print('当前的epoch为{},当前的损失为{}'.format(i, last_loss))
# 保存训练好的lora参数,但是得先找到
lora_dic = {}
# 遍历net的参数
for name, para in net.named_parameters():
name_list = name.split('.')
need_find = ['lora_a', 'lora_b']
# 如果最后一个名字在需要找的参数里面
if name_list[-1] in need_find:
# 在存储的字典里面添加参数和名字
lora_dic[name] = para
# 先存储为临时文件
torch.save(lora_dic, 'lora_para_epoch{}.pt.tmp'.format(i))
# 然后改变路径,形成最终的参数(主要是为了防止写入出错)
os.replace('lora_para_epoch{}.pt.tmp'.format(i), 'lora_para_epoch{}.pt'.format(i))
Part3 修改 denoise.py,修改测试的时候的lora参数加入
1. 引入相关库函数
# 该模块主要实现的是对图像进行去噪的测试。
'''
# 首先第一步,引入相关的库函数
'''
import torch
from torch import nn
from config import *
from diffusion import alpha_t, alpha_bar
from dataset import *
import matplotlib.pyplot as plt
from diffusion import forward_diffusion
from lora import inject_lora
from lora import LoraLayer
2. 定义去噪的函数
'''
# 第二步定义一个去噪的函数
'''
def backward_denoise(net, batch_x_t, batch_labels):
# 首先计算所需要的数据,方差variance,也就公式里面的beta_t
alpha_bar_late = torch.cat((torch.tensor([1.0]), alpha_bar[:-1]), dim=0)
variance = (1 - alpha_t) * (1 - alpha_bar_late) / (1 - alpha_bar)
# 得到方差后,开始去噪
net.eval() # 开启测试模式
# 记录每次得到的图像
steps = [batch_x_t]
for t in range(T - 1, -1, -1):
# 初始化当前每张图像对应的时间状态
batch_t = torch.full(size=(batch_x_t.size()[0],), fill_value=t) # 表示此时的时间状态 (batch,)
# 预测噪声
# 修改第十四处
batch_noise_pre = net(batch_x_t, batch_t, batch_labels) # (batch,channel,iamg,imag)
# 开始去噪(需要注意一个点,就是去噪的公式,在t不等于0和等于0是不一样的,先进行都需要处理部分也就是添加噪声前面的均值部分)
# 同时记得要统一维度,便于广播
reshape_size = (batch_t.size()[0], 1, 1, 1)
# 先取出对应的数值
alpha_t_batch = alpha_t[batch_t]
alpha_bar_batch = alpha_bar[batch_t]
variance_batch = variance[batch_t]
# 计算前面的均值
batch_mean_t = 1 / torch.sqrt(alpha_t_batch).reshape(*reshape_size) \
* (batch_x_t - (1 - alpha_t_batch.reshape(*reshape_size)) * batch_noise_pre / torch.sqrt(
1 - alpha_bar_batch.reshape(*reshape_size)))
# 分类,看t的值,判断是否添加噪声
if t != 0:
batch_x_t = batch_mean_t \
+ torch.sqrt(variance_batch.reshape(*reshape_size)) \
* torch.randn_like(batch_x_t)
else:
batch_x_t = batch_mean_t
# 对每次得到的结果进行上下限的限制
batch_x_t = torch.clamp(batch_x_t, min=-1, max=1)
# 添加每步的去噪结果
steps.append(batch_x_t)
return steps
3. 测试-去噪
# 开始测试
if __name__ == '__main__':
# 加载模型
model = torch.load('unet_epoch0.pt')
model.eval()
is_lora = True
is_hebing = False
# 如果是利用lora,需要把微调的也加进去模型进行推理
if is_lora:
for name, layer in model.named_modules():
name_list = name.split('.')
target_list = ['Wk', 'Wv', 'Wq']
for i in target_list:
if i in name_list and isinstance(layer, nn.Linear):
inject_lora(model, name, layer)
# 加载权重参数
try:
para_load = torch.load('lora_para_epoch0.pt')
model.load_state_dict(para_load, strict=False)
except:
pass
# 如果需要合并,也就是把lora参数添加到原本的线性层上面的话,也就是把插入重新实现一遍,这次是把lora_layer换成linear。
if is_lora and is_hebing:
for name, layer in model:
name_list = name.split('.')
if isinstance(layer, LoraLayer):
# 找到了对应的参数,把对应的lora参数添加到原本的参数上
# 为什么要确定参数位置的上一层,因为setattr只能在上一层用,不能层层进入属性。
cur_layer=model
for n in name_list[:-1]:
cur_layer=getattr(cur_layer,n)
# 首先计算lora参数
lora_weight = torch.matmul(layer.lora_a, layer.lora_b) * layer.alpha / layer.r
# 把参数进行添加,线性层的权重矩阵通常是 (out_features, in_features),所以需要对lora矩阵进行转置
layer.net.weight = nn.Parameter(layer.net.weight.add(lora_weight.T))
setattr(cur_layer, name_list[-1], layer)
# 生成噪音图
batch_size = 10
batch_x_t = torch.randn(size=(batch_size, 1, IMAGE_SIZE, IMAGE_SIZE)) # (5,1,48,48)
batch_labels = torch.arange(start=0, end=10, dtype=torch.long) # 引导词promot
# 逐步去噪得到原图
# 修改第十五处
steps = backward_denoise(model, batch_x_t, batch_labels)
# 绘制数量
num_imgs = 20
# 绘制还原过程
plt.figure(figsize=(15, 15))
for b in range(batch_size):
for i in range(0, num_imgs):
idx = int(T / num_imgs) * (i + 1)
# 像素值还原到[0,1]
final_img = (steps[idx][b] + 1) / 2
# tensor转回PIL图
final_img = TenosrtoPil_action(final_img)
plt.subplot(batch_size, num_imgs, b * num_imgs + i + 1)
plt.imshow(final_img)
plt.show()
参考
视频讲解:Lora微调代码实现_哔哩哔哩_bilibili
原理博客:手撕Diffusion系列 - 第九期 - 改进为Stable Diffusion(原理介绍)-CSDN博客,自学资料 - LoRA - 低秩微调技术-CSDN博客