18 大量数据的异步查询方案
在分布式的应用中分库分表大家都已经熟知了。如果我们的程序中需要做一个模糊查询,那就涉及到跨库搜索的情况,这个时候需要看中间件能不能支持跨库求交集的功能。比如mycat就不支持跨库查询,当然现在mycat也渐渐被摒弃了(没有处理笛卡尔交集的问题),基本上都选shradingjdbc了。我们暂时不讨论数据库中间件的技术选型问题,讨论下我们一般面对海量数据的查询问题。
我们知道在数据库中的模糊查询需要全盘扫描,找的匹配的字符并返回,性能上就会比较慢,特别是数据量比较大的时候就是一个灾难。这个时候我们一般选择使用elasticsearch倒排索引去做模糊查询的中间件。es通过把字段进行分词操作,并把分词的元字段存储起来。通过分词映射到实际数据的方式避免全盘扫描的问题,如果是海量数据,es的存储压力比较大,那么我们把海量数据存储在分析型数据库中即可。如下图所示:
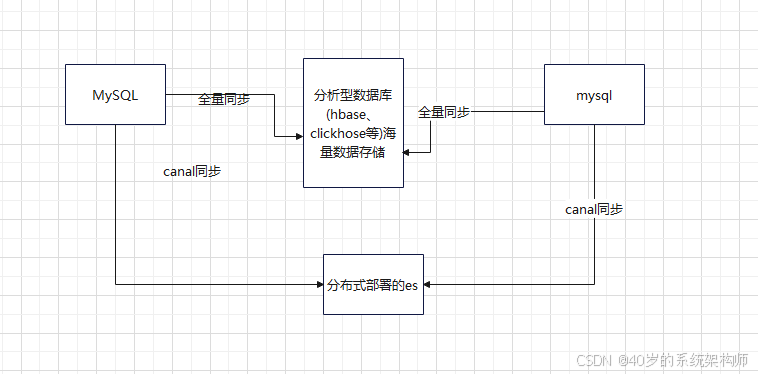
关于分析型数据库的列式存储不同数据库的实现不同,有兴趣的可以去了解下。主流的两种hbase和clickhouse,千亿条数据查询也是很快的,但是分析型数据库对修改的操作性能非常差,我们使用的时候注意这一点就可以了。这里不做细究。
我们在java程序中查询的时候通过es的分词找的数据实体,然后需要找全量数据的时候再到分析型数据库中查询即可。这样就可以解决海量数据查询的性能问题