Cypher入门
文章目录
- Cypher入门
- 创建数据
- 查询数据
- match
- optional match
- where
- 分页
- with
- 更新数据
- 删除数据
- 实例:好友推荐
Cypher入门
- Cypher是Neo4j的查询语言。
创建数据
- 在Neo4j中使用create命令创建节点、关系、属性数据。
create (n {name:$value}) return n //创建节点,节点的属性是name,n为该节点的变量,创建完成后返回该节点

create (n:$Tag {name:$value}) //创建节点,指定标签

create (n)-[r:knows{name:$value}]->(m) //创建n指向m的关系,并且指定关系类型为:KNOWS


查询数据
match
[match where] //条件查询
[option match where] //选择查询,查询不到使用null代替
[with [order by] [skip] [limit]] //查询的结果以管道的方式传递给下面的语句,聚合查询必须使用with
return [order by] [skip] [limit] //返回、排序、跳过、返回个数
- MATCH 语句通过模式(Patter)来检家数据库。它常与带有约束或者断言的 WHERE语句一起使用,这使得匹配的模式更具体。断言是模式描述的一部分,不能看作是匹配结果的过滤器。
- MATCH 可以出现在查询的开始或者末尾,也可能位于 WITH 之后。如果它在语句开头,此时不会绑定任何数据。Neo4j将设计一个搜索去找到匹配这个语句以及 WHERE 中指定断言的结果。这将牵涉数据库的扫描,搜索特定标签的节点或者搜索一个索引以找到匹配模式的开始点,这个搜索找到的节点和关系可作为一个“绑定模式元素(Bound Patter Elements)”。它可以用于匹配一些子图的模式,也可以用于任何进一步的 MATCH 语句,
- Neo4j 将使用这些已知的元系来找到更进一步的未知元素。
- Cypher 是声明式的,因此查询本身不指定搜家的算法。Neo4i会自动地用最好的方法去找到开始节点和匹配模式。WHERE 中的断言可以在模式匹配之前、匹配中或者匹配后进行处理。这可以通过查询编译器来影响这个决定。
- 创建查询语句需要的数据
create (n:User {name:"张宇"}) create (n)-[:sing]->(:Song {title:"月亮惹的祸"}) create (n)-[:sing]->(:Song {title:"雨一直下"}) create (n)-[:sing]->(:Song {title:"大女人"}) create (n)-[:love]->(:User {name:"十一郎"}) - 查询所有节点
match (n) return n

- 查询所有User节点
match (n:User) return n

- 查询所有与“张宇”有关系的节点
match (n:User{name:"张宇"})--(m) return n,m

- 查询所有与张宇演唱的歌曲
match (n:User {name:"张宇"})-->(m:Song) return n,m

- 将查询赋值与变量
match p=(n:User {name:"张宇"})-->(m:Song) return p

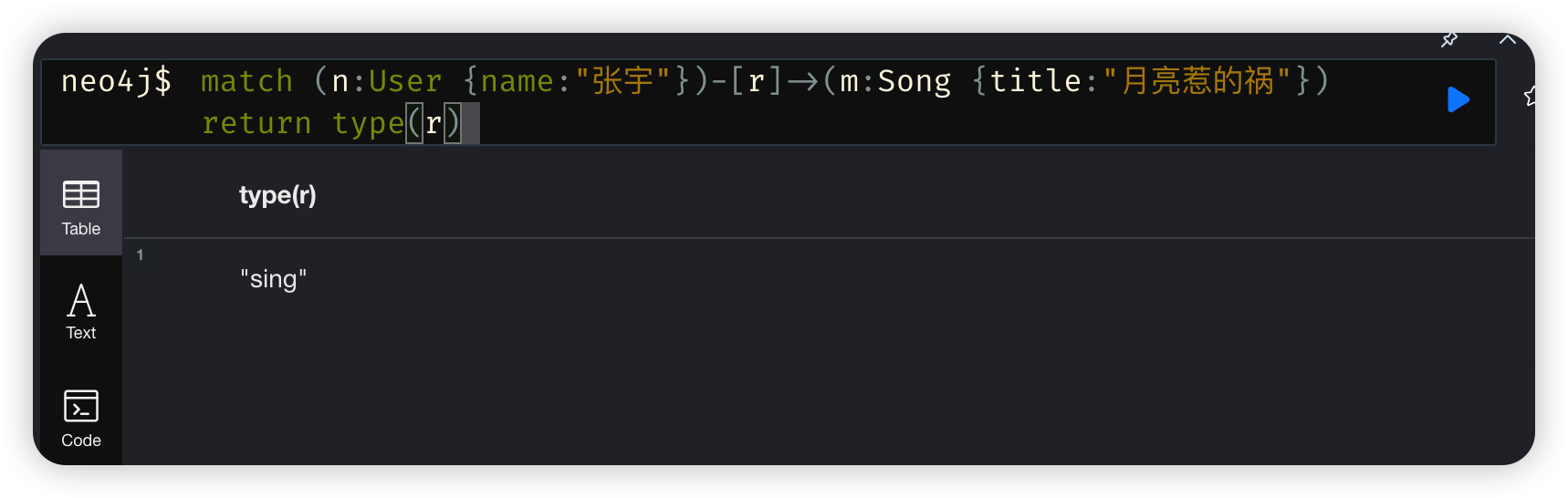
- 查询张宇与月亮惹的祸之间的关系
match (n:User {name:"张宇"})-[r]->(m:Song {title:"月亮惹的祸"}) return type(r)
- 指定关系标签查询
match (n:User {name:"张宇"})-[:sing]->(m) return n,m

- 指定多种关系标签查询
match(n:User {name:"张宇"})-[:sing|:love]-> (m) return n,m

- 在关系查询中指定关系的深度
-[:TYPE*minHops..maxHops]->//查询有1~2层关系的节点 match (n:Person {name:"Keanu Reeves"}) -[r:ACTED_IN*1..2]-(m) return n,m,r //查询有2层关系的节点 match (n:Person {name:"Keanu Reeves"}) -[r:ACTED_IN*2]-(m) return n,m,r


- 查询两个节点之间的深度为1~10的路径
match (n:Person {name:"Keanu Reeves"}),(m:Person {name:"Danny DeVito"}),p = shortestPath((n)-[*1..10]-(m)) return p

- 查询两个节点之间最短的路径
match (n:Person {name:"Keanu Reeves"}),(m:Person {name:"Danny DeVito"}),p = shortestPath((n)-[*]-(m)) return p

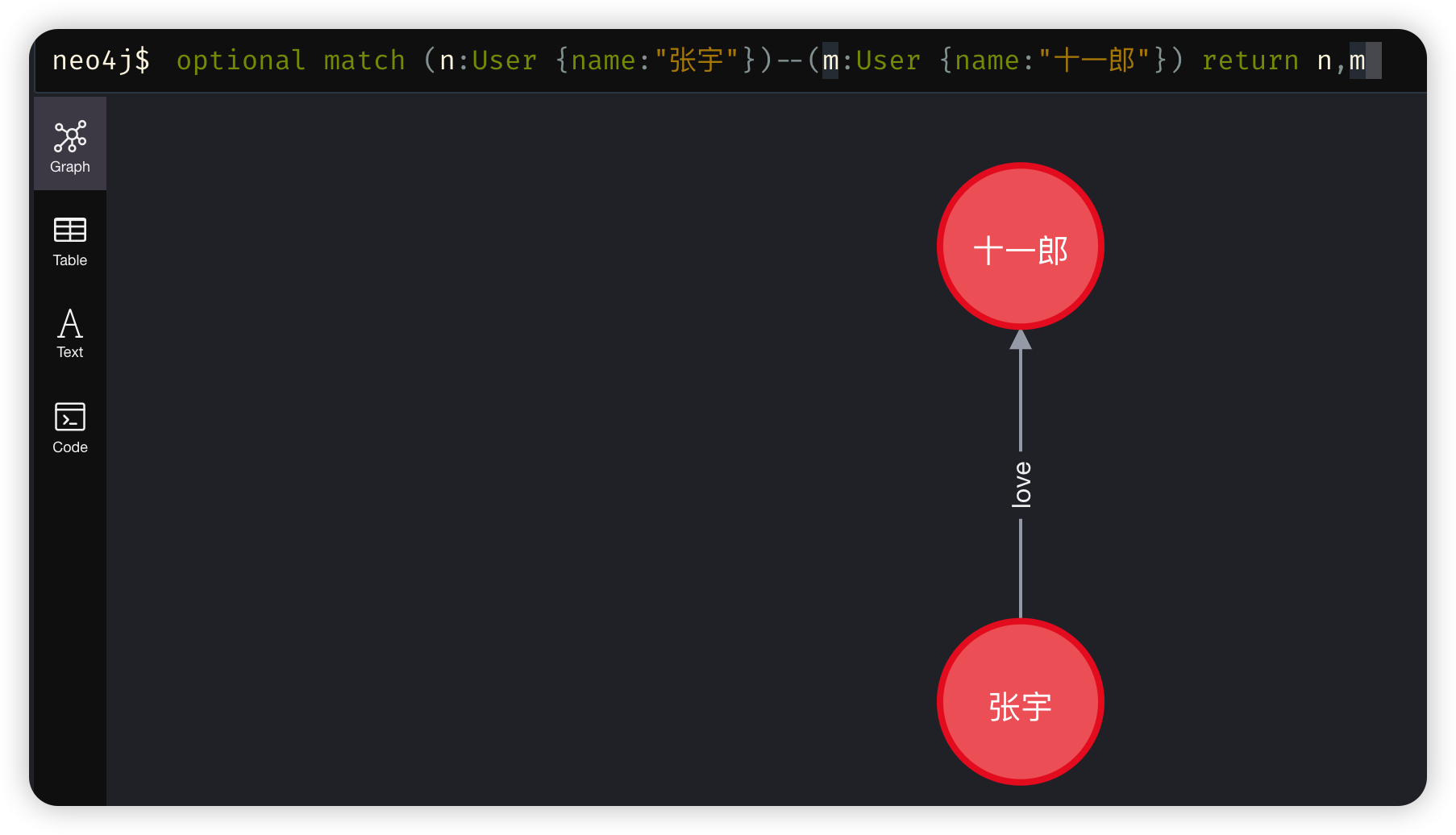
optional match
- OPTINAL MATCH 匹配模式,如果没有匹配到,OPTINAL MATCH 将用 null 作为未匹配到部分的值。OPTINAL MATCH 在 Cypher 中类似SQL 语句中的 outer join。要么匹配整个模式,要么都未匹配。
- WHERE 是模式描述的一部分,匹配的时候就会考虑到 WHERE 语句中的断言,而不是匹配之后。这对于有多个(OPTINAL)MATCH 语句的查询尤其重要,一定要将属于 MATCH 的 WHERE 语句与 MATCH 放在一起。
optional match (n:User {name:"张宇"})--(m:User {name:"十一郎"}) return n,m

where
- WHERE 在 MATCH 或者 OPTINAL MATCH 语句中添加约束,或者与 WITH 一起使用来过滤结果。
- WHERE 不能单独使用,它只能作为 MATCH、 OPTINAL MATCH、 START 和 WITH 的一部分。如果是在 WITH 和 START 中,它用于过滤结果。对于 MATCH 和 OPTINALMATCE, WHERE 为模式增加约束,它不能看作是匹配完成后的结果过滤。
- 设置属性条件
match (n:Song) where n.title='雨一直下' return n

- 设置布尔条件
match (n:Song) where n.title='雨一直下' or n.title='大女人' return n

- 关系属性过滤
match (n:Person) -[r:ACTED_IN]-> (m:Movie) where r.roles=['Neo'] return n,r,m

- 属性以xxx开头、包含xxx
match (n:Person) where n.name starts with 'K' return n

match (n:Person) where n.name contains 'un' return n

- 属性比较
match (n:Person) where n.born >1980 return n match (n:Person) where n.born>1970 and n.born >1990 return n


分页
- 在Neo4j中进行分页查询,可以使用SKIP和LIMIT子句
MATCH (p:Person) RETURN p.name ORDER BY p.name SKIP $skip LIMIT $limit - SKIP用于跳过指定的记录数,通常你根据页码计算这个值。例如,如果每页显示10条记录,第二页的skip值为10,第三页的skip值为20,以此类推。
- LIMIT用于限制查询结果的数量,即每页要显示的记录数。
match (n:Person) return n order by n.born desc skip 5 limit 10

match (n:Person) with n order by n.born desc limit 10 return n

with
- WITH 语句将分段的查询部分连接在一起,查询结果从一部分以管道形式传递给另外一部分作为开始点。
- 使用 WITH 可以在将结果传递到后续查询之前对结果进行操作。操作可以是改变结果的形式或者数量。WITH 的一个常见用法就是限制传递给其他 MATCH 语句的结果数。通过结合 ORDER BY 和 LIMIT,可获取排在前面的x个结果。
match (n:Person {name:"Keanu Reeves"}) --(m:Movie)
with m,n limit 3
match (m)--(k)
return k,m,n

更新数据
- 更新数据是使用set语句进行标签、属性更新。set操作是等幂性的。
match (n:User {name:"张宇"})
set n.age=40
return n

- 所有User节点年龄增加1
match (n:User) set n.age=n.age+1

- 通过set增加标签
match (n:User) set n:User2 return n

- 通过remove移除标签
match (n:User) remove n:User2 return n

match (n:User) remove n.age return n
- 没有age属性设置age=20
match (n:User) where n.age is null set n.age=20 return n

删除数据
- 删除数据通过delete、detach delete完成。其中delete不能删除有关系的节点,删除关系就需要detach delete
- 删除User标签下的所有数据
match (n:User) detach delete n - 删除单个节点 无法删除有关系的节点
match (n:User {name:"张宇"}) delete n - 删除节点和关系,只适用于少量数据
match (n:User {name:"张宇"}) detach delete n - 删除所有节点(谨慎使用)
match (n) detach delete n
实例:好友推荐
- 在社交网站中常常会有这样的功能,”你可能认识的人〞。图数据库是非常适合这样的场景的,接下来我们就尝试着使用Neo4j实现简化版的好友推荐。
CREATE (u1:User {name: "郭靖"})
CREATE (u2:User {name: "令狐冲"})
CREATE (u3:User {name: "岳不群"})
CREATE (u4:User {name: "左冷禅"})
CREATE (u5:User {name: "东方不败"})
CREATE (u6:User {name: "风清扬"})
CREATE (u7:User {name: "张无忌"})
CREATE (u8:User {name: "谢逊"})
CREATE (u9:User {name: "杨道"})
CREATE (u10:User {name: "乔峰"})
CREATE
(u1)-[:FRIEND_OF]->(u2),
(u1)-[:FRIEND_OF]->(u3),
(u2)-[:FRIEND_OF]->(u4),
(u2)-[:FRIEND_OF]->(u5),
(u3)-[:FRIEND_OF]->(u6),
(u3)-[:FRIEND_OF]->(u7),
(u5)-[:FRIEND_OF]->(u8),
(u8)-[:FRIEND_OF]->(u9),
(u3)-[:FRIEND_OF]->(u10)

match (n:User) return n

- 查询郭靖好友
match (n:User {name:"郭靖"}) -[:FRIEND_OF]->(m) return *

- 查询郭靖好友关系为2~3层的用户
match (n:User {name:"郭靖"}) -[:FRIEND_OF*2..3]->(m) return m

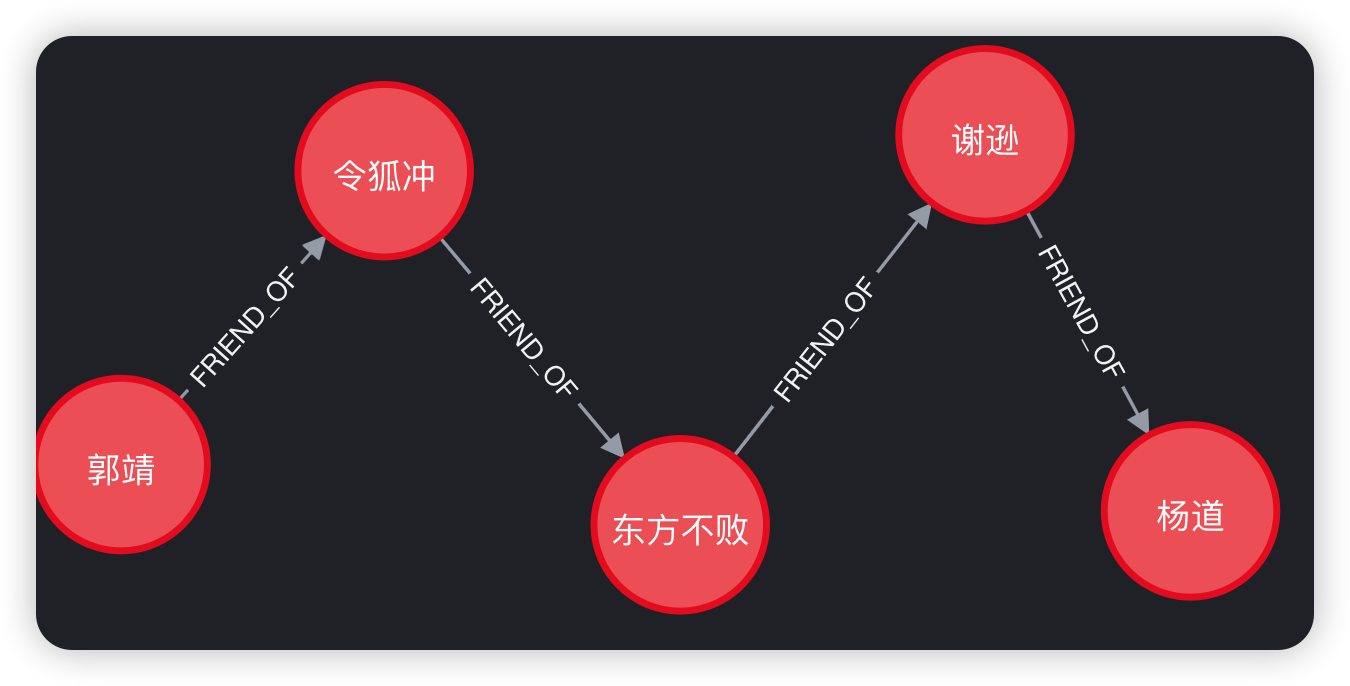
- 郭靖要想和杨道认识,最短的路径是什么?
match (u:User {name:"郭靖"}),(m:User {name:"杨道"}),
p=shortestPath((u)-[*]-(m))
return p