浅尝模型微调Getting Started
我们从在一台未搭建任何环境的电脑上开始,安装Anaconda、配置LLaMA-Factory、安装Pytorch-GPU、拉取模型文件、准备数据集、调整参数并进行模型微调。
文章目录
- 一、安装 Anaconda
- 1.下载Anaconda
- 2.检验是否安装成功
- 二、安装 LLaMA-Factory
- 1.拉取 LLaMa_Factory 文件:
- 2.创名为 **llama_factory** 的 Conda 虚拟环境:
- 3.激活虚拟环境并进入
- 4.安装 pytorch-gpu
- 查看系统的 cuda 版本:
- 选择适合的安装命令
- 验证
- 5.安装项目依赖
- 三、模型拉取
- 四、浅尝
- 1.数据集准备
- 2.参数调整
- 3.启动微调
- 4.模型对话
- 命令行调试
- 参考
一、安装 Anaconda
1.下载Anaconda
从这个页面选择合适的版本下载并完成安装,可自定义安装路径或者选择默认,不多赘述。
2.检验是否安装成功
检查是否安装成功,能否正常使用:
在电脑左下角搜索找到 Anaconda Prompt,点击打开后,在控制台中输入:
conda --version
回车如果返回了 conda 版本信息则说明安装成功。

继续输入:
conda list
返回当前环境下已经安装好的包,如果出现该列表则说明 conda 已经正确安装。其中,包含了对应的解释器 python 3.9.1 (Ps,该电脑环境安装的是 minicinda,是 Anaconda 的轻量版,只包含最核心的组件,适用于对磁盘空间有限制的用户)

二、安装 LLaMA-Factory
LLaMA-Factory 是一个基于 Meta 的 LLaMA(Large Language Model Meta AI)系列模型的开源工具或框架,旨在简化 LLaMA 模型的微调(Fine-tuning)、部署和应用。具体参考:LLaMA-Factory
在安装 LLaMA——Factory 之前,需要完成 conda 虚拟环境的安装以及Pytorch-gpu 的安装。
1.拉取 LLaMa_Factory 文件:
git clone https://github.com/hiyouga/LLaMA-Factory.git
(拉取前需安装 git)
2.创名为 llama_factory 的 Conda 虚拟环境:
conda create -n llama_factory python=3.10
# python版本为3.10,至少3.9
3.激活虚拟环境并进入
conda activate llama_factory
cd LLaMA-Factory
4.安装 pytorch-gpu
查看系统的 cuda 版本:
nvidia-smi

选择适合的安装命令
打开 pytorch官网安装页面,选择合适 CUDA 合适的版本,(一定要对应cuda的版本!!!,可适当向下兼容,但不要相差太大)
选择对应的命令(Command)到虚拟环境下 (所有操作都在新建的虚拟环境下进行)粘贴回车,等待下载完成。

验证
验证pytorch-gpu是否安装成功:
在虚拟环境下,输入 python,进入python命令行后:
import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__

5.安装项目依赖
pip install -e '.[torch,metrics]'
验证:输入以下命令获取训练相关的参数指导, 否则说明库还没有安装成功
llamafactory-cli train -h
三、模型拉取
开源的模型文件,数据集等可浏览的 modelscope 或者 Hugging Face
首先需拉取对应模型,以Meta-Llama-3-8B-Instruct 为例,
请确保 lfs 已经被正确安装
git lfs install
拉取:
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
四、浅尝
1.数据集准备
我们将使用 llamafactory 自带的数据集 identity.json(位于/data目录下,可打开该进行替换和修改)
部分数据如下:
[
{
"instruction": "hi",
"input": "",
"output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
},
{
"instruction": "Who are you?",
"input": "",
"output": "I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
}
]
对文中的变量 {{name}} 和 {{author}} 进行替换成自己需要的内容。
2.参数调整
我们直接使用 GUI 界面进行操作,
llamafactory-cli webui
运行完毕后将自动在浏览器打开该页面:

数据集选择 identity,其他参数可选择默认或者参考下方(!!! 模型路径处记得选择):

| 区域 | 参数 | 建议取值 | 说明 |
|---|---|---|---|
| ① | 语言 | zh | 无 |
| ② | 模型名称 | LLaMA 3-8 B-Chat | 无 |
| ③ | 微调方法 | lora | 使用 LoRA 轻量化微调方法能在很大程度上节约显存。 |
| ④ | 数据集 | identity | 选择数据集后,可以单击 预览数据集 查看数据集详情。 |
| ⑤ | 学习率 | 1 | 有利于模型拟合。 |
| ⑥ | 计算类型 | bf 16 | 如果显卡为 V 100,建议计算类型选择 fp 16;如果为 A 10,建议选择 bf 16。 |
| ⑦ | 梯度累计 | 2 | 有利于模型拟合。 |
| ⑧ | LoRA+学习率比例 | 16 | 相比 LoRA,LoRA+ 续写效果更好。 |
| ⑨ | LoRA 作用模块 | all | all 表示将 LoRA 层挂载到模型的所有线性层上,提高拟合效果。 |
3.启动微调

4.模型对话
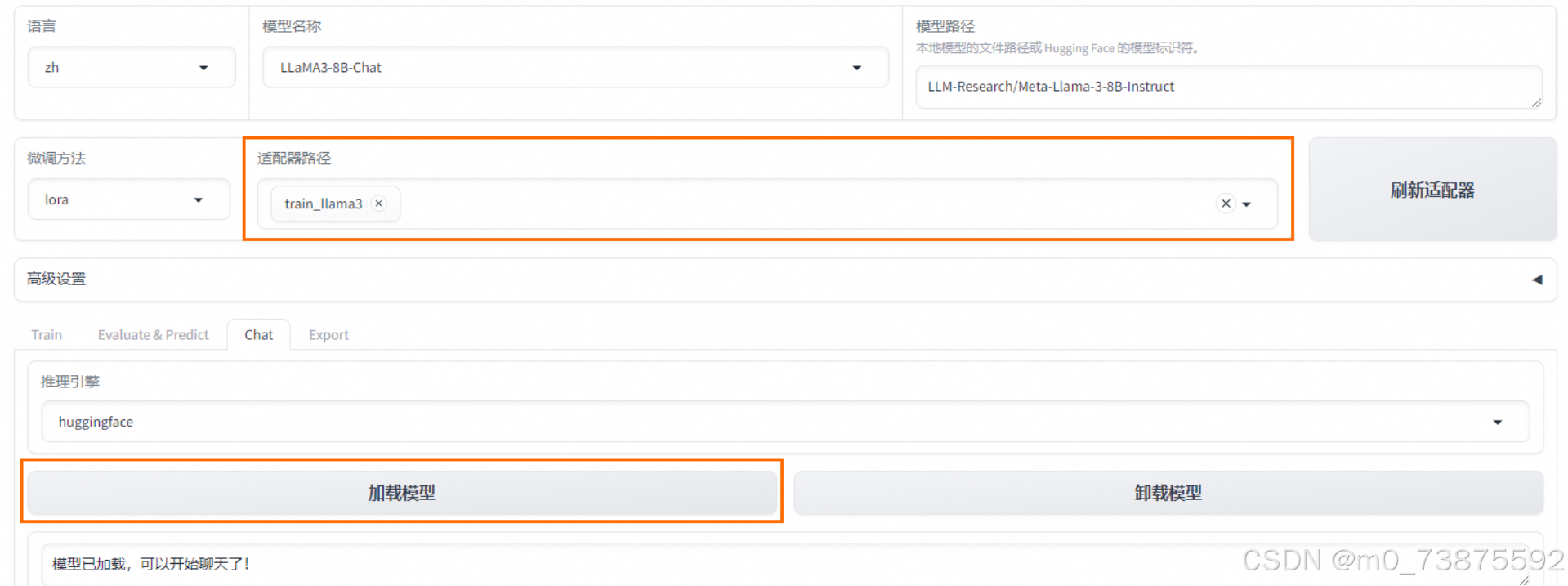
在Chat页签中,确保适配器路径是train_llama3,单击加载模型,即可在Web UI中和微调模型进行对话。
命令行调试
在微调模型中,除了使用 UI 界面,也可以使用命令行
modelPath=/media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct
#填写模型路径
llamafactory-cli train \
--model_name_or_path $modelPath \
--stage sft \
--do_train \
--finetuning_type lora \
--template llama3 \
--dataset identity \
--output_dir ./saves/lora/sft \
--learning_rate 0.0005 \
--num_train_epochs 8 \
--cutoff_len 4096 \
--logging_steps 1 \
--warmup_ratio 0.1 \
--weight_decay 0.1 \
--gradient_accumulation_steps 8 \
--save_total_limit 1 \
--save_steps 256 \
--seed 42 \
--data_seed 42 \
--lr_scheduler_type cosine \
--overwrite_cache \
--preprocessing_num_workers 16 \
--plot_loss \
--overwrite_output_dir \
--per_device_train_batch_size 1 \
--fp16
参考
- LLaMA-Factory QuickStart
- 使用LLaMA Factory微调LlaMA 3模型
- 大模型微调实战:基于 LLaMAFactory 通过 LoRA 微调修改模型自我认知