【02】智能合约与虚拟机
Solidity底层
ABI接口详解
ABI是什么?
ABI:Application Binary Interface(应用程序二进制接口)
- 蚂蚁链BaaS平台提供的Cloud IDE,会在合约编译后,一并生成对应的ABI文件(JSON格式描述)
ABI被设计用于合约的接口文档说明,包含合约中定义的属性、方法签名等相关信息
- 包括字段名称、字段类型、方法名称、方法参数名称、方法参数类型、方法返回值类型等
ABI是区块链外部与合约进行交互以及合约之间进行交互的一种标准方式
- 交互数据(根据类型)会按照特定规则来进行编码

为什么需要ABI?

如何获取ABI的JSON描述文件

Solidity代码与ABI JSON描述文件

ABI JSON描述文件参数说明
| 参数 | 说明 |
|---|---|
| name | 函数名称 |
| type | 方法类型,包括function、constructor、fallback(缺省方法),默认为function |
| constant | 布尔值,如果为true,则表示方法不会修改合约字段的状态变量 |
| payable | 布尔值,表示方法是否可以接收系统转账 |
| stateMutability | 状态类型,包括pure(不读取区块链状态)、view(和constant类型一样,只能查看,不会修改合约字段)、nonpayable(和payable含义一样)、payable(和payable含义一样) |
| inputs | 数组,描述参数的名称和类型 |
| name 参数名称 | |
| type 参数类型 | |
| outputs | 和inputs一样,如果没有返回值,缺省是一个空数组 |
Constructor的ABI描述

Event的ABI描述

如何使用ABI文件

ABI编码是什么?
EVM虚拟机中最终执行的是字节码,我们使用ABI调用合约方法,最终在EVM虚拟机中也是以字节码的形式来执行的;
Solidity需要将ABI方法调用编码后,才能在EVM虚拟机中执行;
ABI的编解码工作均需要按照一定的规则来执行,需要对以下内容进行:
- 调用的方法名称
- 方法参数传递的值

ABI编码示例
以add方法为例:
使用ABI调用该方法,参数传递:a参数传递1,b参数传递2

ABI编码规则
函数编码(函数选择器)
- EVM中,每个函数调用都由4个byte长度的16进制值来唯一标识,我们可以称其为函数签名,也被称为函数选择器;
- 函数签名总是位于数据的前4个字节;
- 每个函数签名唯一指定一个函数,EVM会通过函数签名找到对应函数,并执行JUMPI跳转到对应函数;
- 编码后的数据为16进制表示,前4个字节即:16进制数据的前8位;
- 函数签名运算公式:对函数名、函数参数做keccak哈希运算后,取哈希值的前4个字节
函数参数编码
- 从第五个字节开始,为函数参数的编码;
- 根据函数参数类型的不同(整型、布尔型、数组类型等),有不同的编码方式;
- 每一个参数都是以32字节形式传入的,参数值如果不够铺满整个32字节,则高位或低位补0(由参数类型决定);
- 如uint8长度只有8字节,无法铺满整个32字节;
- 将uint8编码在32字节的最后8个字节上,高位补0

ABI函数参数不同类型编码规则
| 参数类型 | 编码规则 | |
|---|---|---|
| 静态类型 | uint<M> | M位(M必须为8的倍数,且0<M≤256)无符号整数,直接编码为16进制,高位补0,例如:uint8、uint16等 |
| int<M> | 以2的补码作为符号的M位(M必须为8的倍数,且0<M≤256)整数,直接编码为16进制,高位补0,例如:int8、int16等 | |
| uint | 等同于uint256 | |
| int | 等同于int256 | |
| address/identity | address类型等价于uint160,蚂蚁链专属identity类型等价于uint256 | |
| bool | 等同于uint8,取值只能取0或1,高位补0 | |
| 动态类型 | bytes<M> | M字节的二进制类型,0<M≤32,直接编码为16进制,低位补0 |
| 定长数组类型 | 定长数组:<type>[M],有M个元素的type类型数组 | |
| 非定长类型 | bytes、string、非定长数组(<type>[]) |
编码规则
- 静态类型会被直接编码,动态类型会在当前数据块之后单独分配的位置编码;
- 动态类型编码一般有三个步骤:
- 存储实际编码的位置
- 存储个数(动态类型的个数,即len(type))
- 依次存储其数据部分的编码
ABI encode编码函数


ABI decode解码函数

ABI非标准打包(编码)模式

合约间交互
为什么需要合约间交互
代码复用
可以将各个模块中相同的逻辑抽离出来,放到一个共有库中
减少冗余代码,提高代码复用
Solidity中不允许在Library中定义Storage类型变量,所以需要将库转化为合约
大型项目落地
不可能在一个合约中实现所有的功能
无法分工合作,效率低下
通常情况下,会按照功能划分为不同库(合约),各个库(合约)之间通过接口相互调用
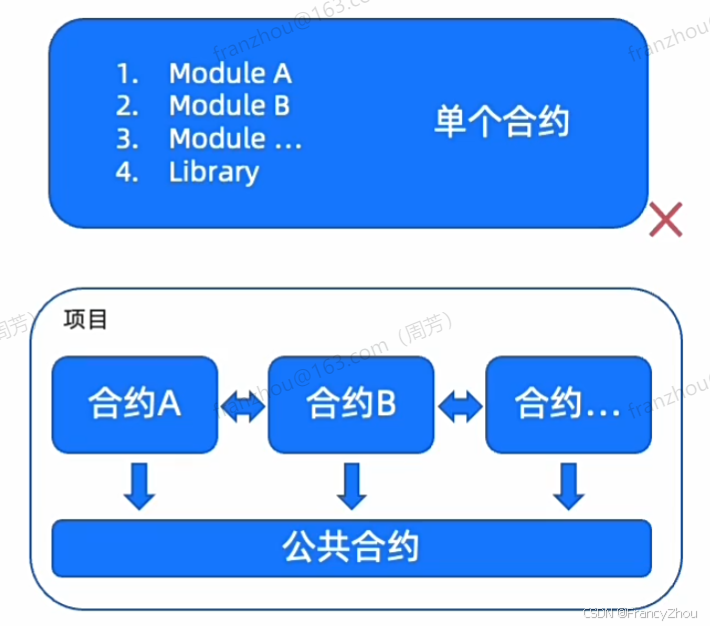
合约间交互方式
CALL
合约间可以通过消息调用(CALL)方式来调用其他合约
消息调用(CALL)和交易非常类似,它们都有源、目标、数据、GAS等
实际上,每个交易都由一个顶层消息调用组成,该消息调用又可以创建更多的消息调用
最常用的调用方式
调用后内置变量msg的值(msg.sender,msg.value)会修改为调用者
上下文环境为被调用者的上下文环境
调用成功后返回true或false

CALLCODE
还可以通过CALLCODE来进行合约间调用
它和CALL的不同之处在于上下文环境不同
调用后内置变量msg的值(msg.sender,msg.value)会修改为调用者
上下文环境为调用者的上下文环境
调用成功后返回true或false

DELEGATECALL
委托调用(DELEGATECALL)是一种特殊类型的消息调用方式
DELEGATECALL不会改变msg.sender和msg.value的值
调用后内置变量msg的值(msg.sender,msg.value)不会修改为调用者
上下文环境为调用者的上下文环境
调用成功后返回true或false

CALLCODE和DELEGATECALL区别
CALLCODE
msg随着调用链而改变,msg为调用链上游调用者msg
官方已经不推荐使用

DELEGATECALL
无论有多少次合约调用,msg始终为原始调用者msg
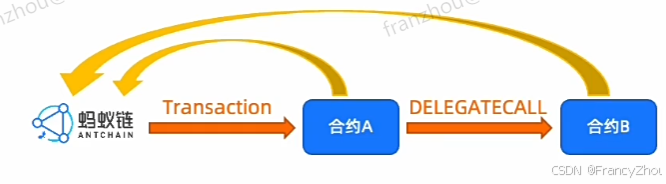
CALL、CALLCODE与DELEGATECALL调用

消息调用安全问题
CALL注入问题
原理
调用后内置变量msg的值(msg.sender,msg.value)会修改为调用者
CALL函数拥有极大的自由度:
- 对于一个指定合约地址的call调用,可以调用该合约下的任意函数
- 如果call调用的合约地址由用户指定,那么可以调用任意合约的任意函数
注入示例

在合约中,有两个方法:info和secret,secret方法中有一个require语句表明该方法仅供该合约调用;
info方法中有call方法可供外部用户使用,如果我们传入的data为特殊准备过的一段字节序列,如info代码中的第二行,那么就可以绕过secret方法中的require语句。
DELEGATE滥用问题
原理
DELEGATECALL调用后内置变量msg的值不会修改为调用者,而是依旧使用原始msg,且上下文环境是调用者的上下文环境

Parity MultiSig钱包合约漏洞
事故
可将Parity Wallet Library合约变成一个普通的Multi-Sig钱包,并通过调用该initWallet函数称为其所有者。
一个典型的DELEGATECALL滥用问题

可升级合约
为什么需要升级合约?
智能合约一旦上链,即不可篡改,这也是合约双方相互信赖的基石。
考虑如下几种情况:
- 基于合约双方都同意的情况下,想对合约的部分内容进行修改,该怎么办?
- 合约中发现了较为严重的漏洞,如何进行修复?
- 合约双方均同意增加新功能,如何对合约进行更新?
如何设计合约以支持升级?
智能合约一旦重新部署,地址就变了,所以设计可升级合约的一个要求就是合约升级后对外公布的合约地址是不变的。
有两种方式来支持升级
代理模式
即所有的消息调用(包括交易)都通过代理合约,代理合约随后再调用最新部署的合约;
如果要升级,将升级后的合约地址更新到代理合约中即可。

数据逻辑分离

代理合约的三种模式
继承存储
Inherited Storage
代理合约和逻辑合约继承自相同的存储结构(storage structure)以保证逻辑合约内部拥有完整的代理合约存储结构
依赖DELEGATECALL
继承存储模型中每一个版本都继承自上一个版本;
“可升级的代理合约”继承自“代理合约”和“某个可升级合约”,即保障了代理合约的可升级性,也可以用来代理特定的合约实现;
“可升级合约”和“可升级的代理合约”继承自同一个可升级合约,可以保证在“可升级合约”内部拥有一个完整的“可升级的代理合约”内部存储结构;
开发者的其他合约均必须继承自“可升级合约”,如“合约1‘,”合约2“;
“合约2”需要继承“合约1”内部的一些特定存储结构,做到向上兼容。

永久存储
Eternal Storage
使用一个独立的存储合约来存储逻辑合约所需要的所有状态变量,且该存储合约对代理合约透明(通过继承)
依赖DELEGATECALL
使用“永久存储”合约存储所有逻辑合约所需要的状态变量(定义好之后不可以再新增状态变量);
所有的逻辑合约“合约1”、“合约2”均继承自“永久存储”合约,保证了后续版本拥有上个版本所有的存储结构;
“可升级代理合约”保证了“代理合约”的可升级性;
“永久存储”代理合约继承自“永久存储”合约和“可升级的代理合约”,一方面保证代理合约存储结构的稳定性,另一方面由于继承自“永久存储”合约,知道“永久存储”合约中都定义了那些状态变量,所以可以保证其不会覆盖“永久存储”合约中的状态变量。

非结构化存储
Unstructured Storage
和继承存储类似,但是不继承和升级相关的状态变量
依赖DELEGATECALL
基于“继承存储”,但是重新定义了升级所需要的合约的存储结构;
不使用状态变量(可以称之为结构化数据),而是使用固定的存储插槽(fixed storage slots)来存储升级所需要的数据

逻辑合约和数据合约
分割数据和逻辑
行业内的各个其他方向都在尝试将计算和存储进行分离,一些耳熟能详的案例:分布式文件存储、分布式计算MR、分布式结构化存储等;
存算分离的架构可以极大的增强系统弹性,使其更加灵活拓展,并充分利用资源,节省成本;
智能合约也是一样,上述课程中我们主要聚焦在合约中的存储结构,现在我们可以尝试将合约中的存储与逻辑进行抽离:
- 逻辑合约
- 存储合约

传统的存算分离架构:
- 负载均衡更灵活,调度更方便;
- 解耦之后,系统更加健壮,系统之间单独维护;
- 资源利用率提高,节省成本
逻辑和数据使用不同的合约,注意逻辑合约可以升级,但是数据合约不进行升级;
这里需要考虑两个问题:
- 数据合约访问策略?
- 逻辑合约升级策略?

数据合约访问策略

逻辑合约升级策略

内联汇编
Assembly概念


Solidity中的汇编

Solidity内联汇编示例

内联汇编vsSolidity原生


优势
- 可以使用汇编码直接与底层虚拟机进行交互,实现更细粒度的控制;
- 汇编语言可以直接操作Storage/Memory slots,Solidity原生语言是不支持的;
- Gas消耗少,上述例子中,使用内联汇编实现需要消耗20936 gas,而使用原生Solidity语言实现则需要消耗20978 gas,这还仅仅是一个简单的例子;
- 内联汇编更加接近底层虚拟机,执行速度更快
劣势
- 不共享其他内联汇编块空间;
- 汇编中都是uint(为了提高效率,底层虚拟机将每个值都视为256位数字),但是在Solidity中我们可以指定较小的类型,如uint8;
- 不易理解,开发成本高,维护成本高;
- 直接访问底层虚拟机,从而绕过了Solidity语言层面的一些安全检查,使用时需要格外注意
内联汇编基础示例

基础语法
判断

循环

常用指令

布局模型
虚拟机模型

变量在存储中的布局模型
Storage存储为非易失性持久存储,可以存储合约中的状态变量等需要持久化存储的变量;
Storage为一个Map,容量为2^256个插槽;
插槽(slot)为虚拟机规定的一段固定大小的值,称之为插槽;
每个插槽的容量为32字节,256位;
相关汇编指令:
- sload:从storage中加载字节到stack;
- sstore:存储字节到storage中;
Solidity合约定义的状态变量都会存储在storage中,按照某些规则(布局模型)来依次存放在插槽中。


映射和动态数组

变量在内存中的布局模型
Memory存储为易失存储,无法持久化存储,需要格外注意;
主要在运行期间存储数据;
可以在字节级别寻址,一次可以读取32字节且每个元素均占用32字节;
对应的汇编指令:
- mload:从memory加载机器字到stack;
- mstore:存储一个值到指定地址,mstore(p,v)表示将v值存储到地址p;
- mstore8:存储一个字节到指定地址
在方法中定义的值类型变量默认都是在memory中的;
Memory中预留了4个32字节的插槽
- 暂存空间(临时空间):64字节
- 当前分配的内存大小(也作为空闲内存指针):32字节
- 零位插槽:32字节


内存模型和存储模型区别
| storage | memory | |
|---|---|---|
| 变量 | 合约内声明的变量,即状态变量 | 函数内部声明的变量,即局部变量 |
| 实际类型 | Map | 字节数组 |
| 位置 | 区块链上,永久存在 | 内存中,函数调用结束后消失 |
| 存储优化 | 会做优化,如果不满32字节,可能会将不同变量放在同一slot | 不会优化,每个元素都是32字节 |
| 运行的位置 | 区块链网络上 | 单个节点 |
| 传递属性 | 指针传递 | 值传递 |
| Gas消耗 | 开销大 | 开销小 |
关于值传递和引用传递:
- Memory->Memory:值传递
- Memory->Storage:值传递,相当于该值在两处都有值
- Storage->Storage:引用传递
- Storage->Memory:值传递
CallData布局
Calldata也叫做Args,是一个不变的临时位置,和Memory很类似
常用汇编指令:
- Calldatasize:返回calldata的大小
- Calldataload:从calldata中加载32bytes到stack中
- Calldatacopy:拷贝字节到内存中
不可修改,这意味着在函数体中不可修改该参数变量
calldata只能用于函数声明参数中,不可用于函数体中(这一点不同于Memory)
如果是external function,并且接收的是动态参数(如动态数组),则必须用calldata
Calldata是易失的

Solidity代码优化
变量清理的目的
变量清理为Solidity编译器的一个内部机制;
Solidity虚拟机内部实现为一个巨大的Map,且Map中每一个插槽的存储容量为32字节;
当一个值占用的位数小于32字节时,就会留下一段没有被使用的位置,而这些没有被使用的位置在执行前会被Solidity虚拟机去除掉(这些位置有可能是有脏数据的);
无论是向Memory中写入数据,还是向Storage中写入数据,都会将未用到或不需要的字节位清除掉。
- 虚拟机每次操作32字节,如果元素比32字节少,虚拟机必须执行额外的操作以便将其大小缩减到元素所需的大小。

输入数据的清理
除了上述规则之外,solidity编译器也会将输入数据加载到堆栈时,对这些输入数据进行清理。不同类型有不同的清理无效值的规则。
| 输入数据类型 | 有效值 | 无效值 |
|---|---|---|
| enum of members | 0 until n-1 | 抛出异常(exception) |
| bool | 0 or 1 | 当做1 |
| signed integers | 有符号且在范围内 | 抛出异常 |
| unsigned integers | 无符号且在范围内 | 抛出异常 |
代码优化的必要性

代码优化的方式
代码优化分为两部分,一部分是开发者对业务代码的优化,另一部分是Solidity编译器对代码的优化
业务代码优化
- 开发者需要在编写代码的时候负责
- 需要日常积累,编写高质量代码
- 常用的优化手段:
- 合理组织变量,将其打包,减少插槽消耗
- 使用内联汇编代替一部分原生Solidity操作
- 使用合理的数据类型:数据类型(如使用定长数组代替动态数组)、数据类型长度
- 其他优化方法
Solidity优化器
- 由Solidity编译器负责进行优化
- 除了必要的参数外,开发人员无需特殊关注,编译器会自动进行优化
什么是opcode?

代码优化器
Solidity代码优化器实际上是基于opcode的,也就是基于汇编来进行优化的;
优化器会试图简化复杂的代码逻辑或公式,从而减少代码量和Gas消耗;
优化器会在JUMP和JUMPDEST处将opcodes拆分为一个个独立的基本代码块;这些代码块是原子的,即要么完成,要么不完成,不会在运行一半的时候跳跃(JUMP)到其他地方;
编译器会在各个原子代码块中寻找等效替代;如将x-y替换为一个非零常量。



优化器参数运行
使用Solidity合约编译工具:solc-js进行编译的时候,可以指定参数来开启Solidity优化器,而且还可以指定代码中每个操作码被执行的次数

合约元数据
合约元数据存储当前合约的相关信息,包括:编译器版本、所使用的源代码、应用二进制接口ABI(Application Binary Interface)等信息;
这些信息会以JSON格式存储在一个JSON文件中;
在与合约进行交互的时候,可以查看该JSON文件来了解合约元数据信息,更加安全;
JSON文件会附在每个合约的字节码文件末尾,这样交互放在认证后就可以直接拿到,而不需要一个中心化的地方来存储。

合约元数据文件格式

EVM底层原理
EVM定义及特点
以太坊虚拟机定义
以太坊虚拟机(Ethereum Virtual Machine,简称EVM)是一个基于栈的、大端序的256bit的虚拟机,负责执行以太坊网络中的智能合约。
两种实现方式
基于堆栈的虚拟机架构
基于堆栈的虚拟机架构(Stack Based Virtual Machines):
- 存储数据的内存结构是一个栈结构;
- 依照栈FIFO的操作方式,数据出栈执行操作后,操作结果又入栈;
在基于栈的虚拟机中,计算两个数值之和的操作通常会按如下方式执行:
- PUSH1 20
- PUSH1 7
- ADD
基于栈的虚拟机架构优势是简单、好移植
基于寄存器的虚拟机架构
基于寄存器的虚拟机架构(Register Based Virtual Machines):
- 操作数存储的数据结构基于CPU寄存器;
- 不存在入栈出栈的操作,不同于基于栈的虚拟机模型拥有一个栈指针指向下一个操作数;
- 指令中包含存储操作数的寄存器地址;
例如,在基于寄存器的虚拟机架构中执行一次加法运算,指令大致会按如下方式执行:
- ADD R1, R2, R3;
优势:
- 免去了出入栈所带来的开销
- 指令调度循环使得指令执行更快
- 能实施某些无法在基于堆栈的模型上采取的性能优化手段
例如,在代码中存在很多减法表达式时,寄存器模型可以计算一次后便将计算结果存储在寄存器中,再次执行相同减法表达式时使用寄存器存储的值,从而减少了表达式重复计算造成的开销。
栈式虚拟机与寄存器式虚拟机对比
| 栈式VS寄存器式 | 对比 |
|---|---|
| 指令条数 | 栈式>寄存器式 |
| 代码尺寸 | 栈式<寄存器式 |
| 转移性 | 栈式优于寄存器式 |
| 指令优化 | 栈式更不易优化 |
| 解释器执行速度 | 栈式解释器速度稍慢 |
| 代码生成难度 | 栈式简单 |
| 简易实现中的数据移动次数 | 栈式移动次数多 |
以太坊虚拟机架构
EVM采用基于栈的架构,主要由代码存储区ROM、内存Memory、存储storage三部分组件组成。

EVM特点
确定性
一个确定的程序能够向同一组输入提供相同的输出,而与它执行相同代码的次数无关。
隔离性
智能合约在完全隔离的环境中运行,以确保如果智能合约发生黑客攻击或bug,而不会影响底层协议的其余部分。
图灵完备
以太坊智能合约是图灵完备的。
以太坊中支持循环语句,可以运行无限循环的合约程序。
注意:以太坊使用gas限额来终止超出执行额度的智能合约
智能合约执行
智能合约经过编译器编译为EVM可识别的指令集EVMcode
EVM调度器从EVMcode中逐个取出指令在栈上操作,根据指令对数据进行分发指派到Memory和Storage
执行过程受gas消耗的限制

EVM数据管理
以太坊虚拟机(EVM)中运行的智能合约状态在链上永久存储
值存储在长度为2^256的数组中
下标从零开始且每一个数组能够存储32字节
在EVM中,该数组中的每个元素位置被称为插槽(Slot)

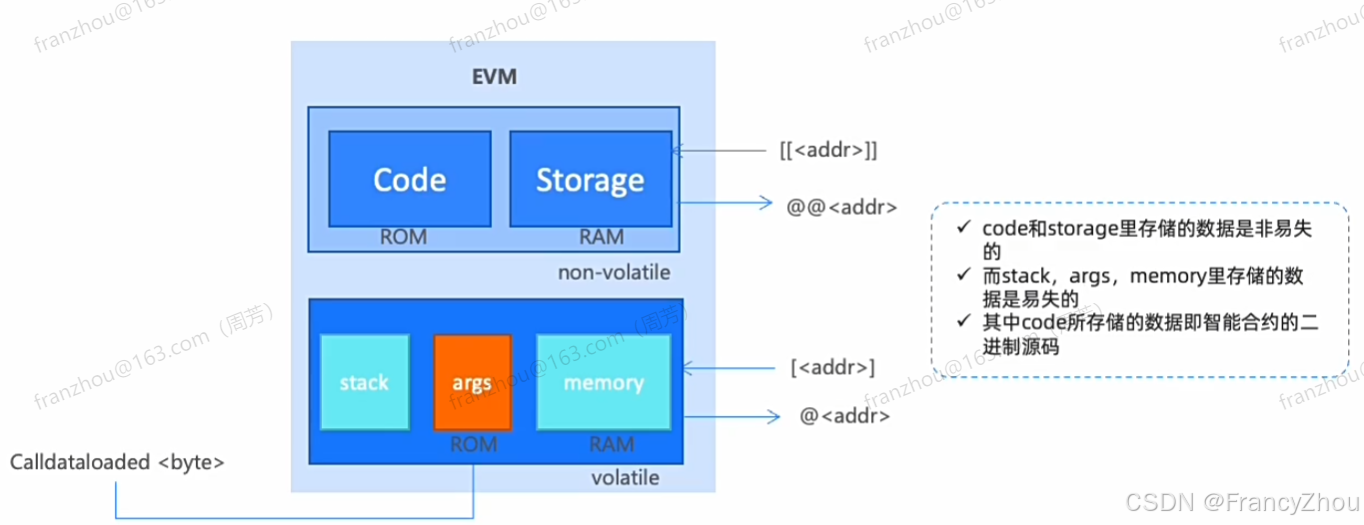
三种数据空间
Stack
用于存放小型的局部变量
使用开销极低
容量有限
Memory
用于暂存数据
存储的内容会在函数被调用(包括外部函数)时擦除
使用开销相对较小
Storage
用于存储合约声明中的变量
虚拟机为每个合约分别划出一片独立的存储storage区域,并且在函数相互调用时持久存在
使用开销非常大
合约数据存储布局
定长数据存储
在Solidity语言中,某些值类型占用固定大小的存储
如布尔类型,占用1字节;uint16占用2字节
Solidity编译器在编译合约时,将严格根据定义顺序,依次给他们设定存储位置

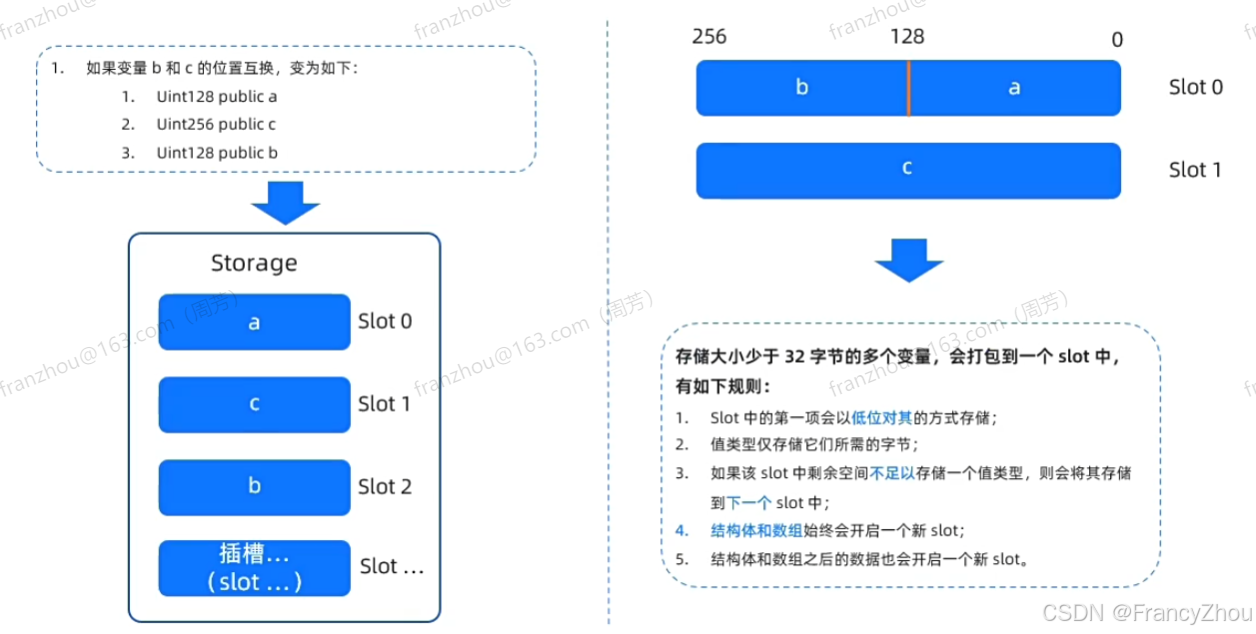
紧凑存储及存储优化
原因:某些值类型实际上不需要用到32字节,如布尔型、uint1到uint256.
方案:编译器在发现某个值所需存储不足32字节时,将会将其和后面字段尽可能的存储在一个存储中。

紧凑存储

紧凑存储机制引发另一个问题:EVM每次读取数据都是32字节,当数据小于32字节时需要更多的指令操作才能将所需值取出。
如实例中,当取c值时,首先要读取插槽1的32字节数据外,还需要截取32字节中的中间一小部分。使得相比取32字节值的数据,需要花费更多的gas来获取小于32字节的数据。
这种开销,相当于更多的存储占用要便宜得多。
在编写合约时,合理安排字段定义顺序可针对该开销进行优化
大端序和小端序
什么是字节序?
字节序,又称端序或尾序(Endianness)。指内存中或数字通信链路中,占用多个字节的数据的字节排列顺序。
字节的排列方式有两个通用规则:
- 大端序(Big-Endian):将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合开发者阅读习惯。
- 小端序(Little-Endian):将数据的低位字节存放在内存的低位地址,高位字节存放在高位地址。这种排列方式符合CPU读取内存中的数据时,从低地址向高地址方向进行读取的方式。

动态数组
动态数组由两部分组成,即数组长度和元素值
在Solidity中定义动态数组后,将在定义的插槽位置存储数组元素数量
元素数据存储的起始位置是:keccak256(slot)
每个元素协议根据下标和元素大小来读取数据

映射字典
字典的存储布局是直接存储Key对应的value,每个key对应一份存储
Key的对应存储位置是keccak256(key.slot)
其中“.”是拼接符号,实际编码时进行拼接abi.encodePacked(key.slot);可直接获得map[key]的存储位置。

字节码
字节码是软件解释器或虚拟机的高效执行而设计的抽象指令集。
字节码以数字格式表示。
EVM执行的是智能合约编译后的字节码
字节码包含用户的状态数据
EVM只识别字节码格式
字节码包含EVM能执行的指令

操作码
算数操作码指令
算数操作码指令主要是对栈顶元素进行加减乘除处理。
| 指令 | 含义 |
|---|---|
| ADD | 对当前栈顶的两个元素进行加法操作 |
| MUL | 对当前栈顶的两个元素进行乘法操作 |
| SUB | 对当前栈顶的两个元素进行减法操作 |
| DIV | 对当前栈顶的元素进行整数除法操作 |
| MOD | 对当前栈顶的元素进行取模运算操作 |
| EXP | 对当前栈顶的元素进行乘方运算操作 |
| SHA3 | 对内存中给定数据进行keccak256的哈希运算操作 |
栈操作码指令
栈操作码指令主要是对内存空间中的内容进行操作。
| 指令 | 含义 |
|---|---|
| POP | 移除栈顶的一个元素 |
| MLOAD | 在指定内存空间中加载一个字空间的内容 |
| MSTORE | 在指定内存空间中保存一个字空间的内容 |
| SLOAD | 在指定内存空间中保存一个字节空间的内容 |
| MSIZE | 获取指定已分配内存空间的字节数大小 |
| PUSHx | 添加一个x字节大小的元素到栈顶上 |
| DUPx | 复制从栈顶向下数的第x个元素到栈顶上 |
| SWAPx | 将栈顶元素从栈顶往下数的第x个元素进行交换 |
流程处理操作码指令
流程处理操作码指令主要是对计数器进行计算机汇编语言侧的操作。
| 指令 | 含义 |
|---|---|
| STOP | 停止执行 |
| JUMP | 将程序计数器设置为任意数值 |
| JUMPI | 基于条件修改程序计数器的值 |
| PC | 取得程序计数器的数值 |
| JUMPDEST | 标记一个有效的跳转地址 |
EVM操作码示例

向智能合约发起交易时,首先执行的是合约的dispatcher(调度器),Dispatcher会处理交易数据,确定协议交互的具体函数。
| 操作指令 | 栈 |
|---|---|
| PUSH1 0x60 | 0x60 |
| PUSH1 0x40 | 0x40 0x60 |
| MSTORE | [] |
| PUSH1 0x4 | 0x4 |
| CALLDATASIZE | how long the calldata is 0x4 |
| LT | ? |
| LT | 1 |
| PUSH 0x3f | 0x4c 1 |
| JUMPI |
PUSH有16个不同的版本(PUSH1...PUSH16)。EVM通过不同编号来了解往栈上压入多少字节。前两条指令(PUSH1 0x60以及PUSH1 0x40)分别代表将0x60以及0x40压入栈。
将0x60存入到0x40位置。
mstore会从栈中取出两个元素,因此栈现在处于清空状态。
CALLDATASIZE函数会将calldata的大小压入栈中。
可以向智能合约发送任意数据,CALLDATASIZE会检查数据的大小。
LT(x,y)如果x<y则为1,否则为0。
如果第一个参数小于第二个参数,则LT会将1压入栈,否则就压入0。
在本例中,根据此时的栈布局,这条指令为
LT((how long the calldata is),0x4)
即判断calldata的大小是否小于0x4字节。
为什么EVM需要检查calldata大小是否至少为4个字节?
EVM会通过函数keccak256哈希的前4个字节来识别函数。即函数原型(函数名以及所需参数)需要交给keccak256哈希函数处理。在这个合约中,可以得到如下结果:

因此,"withdraw(uint256)"函数的函数标识符是0x2e1a7d4d,是结果哈希的前四个字节。
函数标识符总是4个字节长,如果发送给合约的交易的整个数据字段小于4个字节,那么除非定义了fallback函数,否则没有交易可能与之通信的函数。
由于在Faucet.sol中实现了这样的fallback函数,所以当calldata的长度小于4个字节时,EVM会跳转到此函数。
如果calldata字段少于4个字节,LT将弹出堆栈的前两个值并将1推到其上。否则,它会推入0.
假设:calldata字段少于4个字节。
JUMPI代表的是“jump if”(条件满足则跳转),如果条件满足,则跳转到特定的标签或者位置。
JUMPI(lable,cond),如果cond非零则跳转值lable。
本例中lable为代码中的0x3f偏移地址;并且cond为1;程序将跳转到0x3f偏移处。fallback函数存在于Faucet.sol智能合约中的地方。
世界状态
状态机定义
状态机由状态寄存器和逻辑组合电路两部分组成,能够根据一系列输入指令或逻辑信号按照预先设定的规则进行状态转换,状态机是协调相关输入信号指令并完成特定操作达到状态变更的自动化机器。

状态机中的状态
状态机全称为“有限自动机”,在任意时刻状态机只会处于一个状态中。
| 状态 | 概念 |
|---|---|
| 现态 | 状态机当前状态 |
| 条件 | 触发动作或执行状态转移需满足的前提 |
| 动作 | 被满足后会执行的动作 |
| 次态 | 条件满足后状态机迁徙到的新状态 |
以太坊通过状态机来维护全网以太坊节点间的状态一致性。
以太坊中的状态机
以太坊就是一个基于交易的状态机,以太坊中由普通账户直接或间接发起的每一笔交易,都会导致以太坊的状态发生变更。
以太坊中状态变更如图:

以太坊状态表达式如下图:
- S为现态,即交易前的状态;
- TX为交易;
- S'为次态,即交易后的状态。

账户基本概念
外部账户
EOAs-外部账户(external owned account)是由用户通过私钥创建的账户。
外部账户是真实世界的金融账户的映射,拥有该账户私钥即可控制该账户。
以太坊中的交易需要使用私有外部账户进行签名。
合约账户
合约账户地址用于存储合约代码以及合约部署或执行过程中产生的存储数据。
合约账户地址在部署到以太坊时生成,由合约创建者地址已发送的交易笔数(nonce)共同生成。
只能通过外部账户来驱动合约执行合约代码。
外部账户与合约账户对比
外部账户是用户和以太坊沟通的唯一媒介
外部账户和合约账户相辅相成。

账户数据结构
账户状态通过以账户地址为键,维护在表示世界状态的树中。所有账户也存在一棵表示此账户的存储数据的树。

以太坊使用“账户”余额模型。相当于比特币,以太坊丰富了账户内容,出余额外还能自定义存放任意多数据,并利用账户数据的可维护性,构建智能合约账户。


默克尔压缩前缀树-MPT
在账户模型中,账户存在多个属性(余额、代码、存储信息),属性(状态)需要经常更新。
因此需要一种数据结构来满足几点要求:
- 在执行插入、修改或者删除操作后能快速计算新的树根,而无需计算整个树。
- 即使攻击者故意构造非常深的树,它的深度也是有限的。否则,攻击者可以通过特意构建足够深的树使得每次树更新变得极慢,从而执行拒绝服务攻击。
- 树的根值仅取决于数据,而不是取决于更新的顺序。以不同的顺序更新,甚至是从头重新计算树都不会改变树的根值。
MPT全称是Merkle Patricia Trie 也叫Merkle Patricia Tree,是Merkle Tree和Patricia Tree的混合物;
Merkle Tree(默克尔树)用于保证数据安全,Patricia Tree(基数树,也叫基数特里树或压缩前缀树)用于提升树的读写效率;
MPT是以太坊数据安全与效率的保障,是以太坊关键改良之一;
Trie树
Trie树即字典树或前缀树,是一种树形数据结构;
Trie树体现在使用公共的前缀作为树的组成部分;
举例说明:
英文组合分别有以下6种:taa tan tc in inn int

优点
- 插入和查询的效率都很高,都是O(m),m是插入或查询字符串的长度。
- 可以对数据按照字典排序
缺点
空间消耗的比较大。
Patricia Trie树
Patricia Trie树是一种升级版的Trie树,不同之处在于:非根节点可以存储字符串,而不是只能存储字符,也就是路径压缩了的Trie树,因此节省了在内存空间的开销。
举例说明:
分别用两种树来表达abc,d
 考虑左图若再插入一个新单词的场景:
考虑左图若再插入一个新单词的场景:
取决于插入键的分布稀疏情况,原本压缩的路径可能需要扩展;
分布越稀疏,压缩效果越好;
以太坊中采用160位地址,数值大具备稀疏特性,因此Patricia Trie树在以太坊环境下使用非常高效。
MPT(Merkle Patricia Trie)树
MPT树结合了字典树和默克尔树的优点,在压缩字典树中根节点是空的,而MPT树可以在根节点保存整棵树的哈希校验和,而校验和的生成则采用了和默克尔树生成一致的方式。以太坊采用MPT树来保存交易,交易的收据以及世界状态,为了压缩整体的树高,降低操作的复杂度,以太坊又对MPT树进行了一些优化。将树节点分成了四种:
- 空节点
- 叶子节点
- 分支节点
- 扩展节点

EVM世界状态
世界状态是一个以太坊地址(160位数值)到账户数据的映射;
以太坊账户存储账户余额、Nonce、合约哈希、账户状态等内容;
从创世状态开始,随着将交易作为输入信息,将世界状态推进到下一个新的状态中;

通过世界状态定位到目标账户的账户状态,可查询到在现态中账户余额。
举例说明:
当Bob转账5给Alice时,将使得状态从{Bob:8,Alice:2}转移到{Bob:3,Alice:7}状态。

EVM状态数据库StateDB
StateDB本质是一个KV数据库。
StateDB负责将数据做初步的记录。
Trie负责将所有数据结构化,方便后续的存储查询回滚等操作。Trie分两种,State Trie和Storage Trie。前者是世界状态树,记录了账户的余额、nonce等信息。后者用于记录各种合约数据。世界状态树只有一棵,合约状态树有很多棵,因为每个合约都有棵属于自己的合约状态树。
TrieDB将Trie中的节点序列化后存储在内存中。TrieDB的主要作用是作为最终插入硬盘数据之前的缓存层。整个结构中最后一环就是最终硬盘上的数据库。

WASM智能合约开发
WASM概述
WebAssembly(缩写为WASM)规定了一种二进制指令集,应用在基于堆栈的虚拟机。
WASM被设计为编程语言的可移植编译目标,通过虚拟机运行到浏览器以及其他平台。

WASM除了应用在浏览器中,还可以将WASM用在嵌入式、IOT物联网、AI和区块链等特殊的领域和场景中。
智能合约
目前蚂蚁链智能合约平台支持以下几种类型的合约开发:
- Solidity
- WASM(可以提供更优异的性能及多种开发语言的支持)
- C++ WASM
- Go WASM
- TypeScript WASM(测试版本)
- Rust,Java等
蚂蚁链WASM合约特点
多语言
WASM合约 企业级开发首选
为了支持更加复杂的业务逻辑和对性能有要求的业务场景,蚂蚁链引入了WASM虚拟机,可以使用C++、Go、JavaScript等高级语言开发智能合约,借助高级语言强大的表达能力,可以在合约代码中非常方便地描述复杂的业务逻辑。
虚拟机
-
安全第一
在执行合约前的加载阶段,对合约字节码进行多种扫描检测,对诸如非法字节码,内存越界访问,非法访问等。
-
极致性能
综合运用编译器优化技术,底层优化技术,新增CPU专用指令等多种手段来实现极致的性能优化。
-
开发友好
在虚拟机层面增加调试,错误定位,运行统计profiling的能力。
功能扩展
-
合约功能扩展
丰富的密码学库,链上随机数,零知识证明,也支持第三方库调用。
-
结构化存储技术
合约内实现结构化数据上链,通过map类型进行查询/修改/更新等操作,轻松管理上亿条资产数据。
合约部署、执行流程

功能扩展

- 密码学库 如RSA签名验签
- 链上随机数,基于多方安全协议,保证随机、公平、不可预测。
- 隐私保护,非交互式零知识证明
- JSON、XML解析、Base64编解码
- 调用第三方库
- 结构化数据查询
- MyBuffer结构化数据管理
- 定义数据结构,生成数据访问层代码
- 具有复杂数据查询能力

基本语法
合约基本形式
一个智能合约是C++中的一个类(class),必须继承于mychain::Contract,其构造函数与析构函数由编译器生成,不得改写。
编写智能合约所需的数据结构和API均位于mychain命名空间中,方便起见,推荐使用using namespace mychain;
示例:

每个合约都有一个版本号,以32位无符号整数表示,用宏CONTRACT_VERSION()定义
数据类型
基本类型(POD)
支持C++标准的所有基本类型:

合约平台内置数据类型
ACCOUNT_STATUS

Identity
是合约或账户的唯一标识,内容为32个字节,其定义如下:

示例:

语言特性
基础设施
合约语言对重载、模板与继承这些基础设施支持良好,且允许组合使用
从安全与审计角度考虑,不推荐使用以下基础设施:
- 指针
- 数组
- 全局变量和静态成员变量
C++标准
标准库支持如下
- malloc/free、new/delete等内存管理类操作。已改写以保证安全性。
- abort/exit等进程控制类操作。不应在合约中使用。
- iostream/cstdio中包含IO操作。合约语言不允许。同时提供了print接口调试输出使用
- 不支持随机数
合约语言不支持任何系统调用
不支持的C++特性
- 异常
- 线程
- 浮点数-整数转换
- RTTI
未定义行为
- 基础操作(越界访问,访问未初始化变量)
- 整数运算(有符号整数溢出,非法位移运算,非法数学运算)
- 指针操作(访问空指针,访问已释放的指针)
推荐使用的编译选项
| 选项 | 对应编译选项 |
|---|---|
| -Wall | 对可疑的代码写法提出告警 |
| -Wextra | 在-Wall的基础上提供一些额外的检查 |
| -Werror | 把所有的告警当做编译错误 |
运行时资源限制
- 栈空间-限制为8K,超出会异常终止,错误码10201
- 内存空间-最多16M,超出会异常终止,错误码10201
- 合约间调用深度限制不能超过1024,否则错误码10002
合约编译
普通wasm合约

执行命令 my++ -o hello.wasm hello.cpp
生成三个输出文件
- hello.wasm - 合约的wasm字节码文件
- hello.abi - 合约的ABI定义文件
- hello.wasc - 合约字节码和ABI的文件
如果使用-o选项指定的文件名不是以.wasm结尾,那么产生wasc文件
- 命令 my++ -o abc hello.cpp生成 abc.wasc
编译多个源文件
- my++ contract.cpp until.cpp -o contract.wasc
构建静态库,假设编写两个C++源文件和一个头文件,foo.cc/bar.cc/foobar.h
用以下命令编译源代码,然后打包成一个静态库
- my++ -c foo.cc bar.cc
- llvm-ar rcs foobar.a foo.c bar.o
使用静态库,只需在合约代码包含头文件,然后编译合约时指定静态库路径
- my++ main.cc foobar.a -o contract.wasc
合约调用
要调用一个已完成部署的合约,需要指定被调用的方法,这个方法被称为合约接口

INTERFACE 宏
使用形式

示例

INTERFACE_EXPORT 宏
使用形式

示例

合约间调用
合约运行的上下文环境
合约上下文指的是合约运行环境。例如,谁调用了这个合约(sender),本合约的ID是什么(self),当前合约能使用的gas是多少,这些信息可以通过以下API获取到:
| API | 功能 |
|---|---|
| Identity GetSender(); | 该数据表示本次调用是谁发起的,消耗的gas是由发起者提供的。 |
| uint64_t GetValue(); | 该数据表示本次调用调用者给了本合约多少资产。 |
| uint64_t GetGas(); | 该数据表示当前合约还剩余多少可用gas。 |
| Identity GetSelf(); | 该数据表示返回本合约的唯一标识-Identity。 |
| Identity GetOrigin(); | 返回交易发起者的ID。这是一个不随着调用深度变化的值 |
普通调用
函数调用时,当前合约的上下文被保存,智能合约平台随后切换到被调用合约的上下文环境并执行相关代码
例如A合约调用B合约的某个方法f,则在f执行过程中,上下文环境切换到B合约
普通调用使用CallContract,基本形式为
![]()
其中TYPE是被调用合约方法的返回值类型。ret是一个自动模板结构,其定义如下:


数据处理
数据序列化
基础数据序列化
可序列化的数据可以使用pack()函数序列化为字节串(即std::string),并且可以使用unpack()函数将对应的字节串反序列化为原来的值

可序列化数据类型分为两大类:
- 合约平台自身支持的可序列化数据类型
- 用户自定义的可序列化数据类型
合约平台自身支持的可序列化数据类型

pack函数按照下面的规则进行序列化

用户自定义的可序列化数据类型
可以使用SERIALIZE宏将自定义数据类型(struct/class)序列化。

示例

使用Schema持久化数据
开发智能合约时,经常需要将某些数据持久化存储,或者从持久化存储中读取数据内容。智能合约平台引入基于Schema的存储系统。首先通过Schema描述存储对象数据结构以及各数据结构间的逻辑关系,然后在智能合约中使用根据Schema生成的API来操作数据对象,智能合约在运行时会自动将数据对象的修改持久化存储。
Schema语法
Schema中的table-对应C++中的Class,在table中可以定义任意数目的不同类型字段,每个字段包含类型、名字、默认值(可选,如果未设置,默认为0/NULL),同时字段还有附加属性。
示例

Schema数据类型
Schema中table字段类型支持基础类型、数组、map、string等。其中基础类型的长度如下:

命名空间
Schema中可通过namespace来声明命名空间,这样生成的所有C++代码会包裹在该命名空间中。

Root类型
Schema中最后通过root_type来声明根类型table
![]()
根类型的table将会作为合约中访问存储数据的人口,合约必须也只能从根table对象开始访问遍历数据对象信息
Schema生成C++代码
Schema中定义的每一个table都对应C++中的一个类,C++中生成的类名与Schema中的table名称基本一致,但带M后缀。例如上述示例中的table Account,生成的C++类名为AccountM
合约升级
对于已经部署的合约,通过SDK进行升级,即用一个新的合约替代一个旧的合约。
合约升级时,仅仅会用新的合约代码替代原来的合约代码,不会执行合约中的任何方法
通过发送一个特殊的交易进行合约升级
UpdateContract- 升级合约,同步方式调用
- 函数原型
![]()
- 返回字段
![]()
- 示例

AsyncUpdateContract- 升级合约,异步方式调用
- 函数原型
![]()
- 请求参数
![]()
- 返回字段
![]()
- 示例

处理异常
在合约执行过程中,一旦出现异常,合约会立即停止执行并回滚其所造成的一切变更以确保世界状态不会受其影响,注意,如果出现合约异常之前已使用log接口发出通知事件,那么这些信息将在回执(receipt)中体现。
异常分类
- 通过调用Revert()或Require()主动抛出异常,此时异常信息会进入到交易回执的output字段中
- 合约代码存在逻辑错误,导致mychainlib等第三方库中抛出异常
- 合约代码存在逻辑错误,导致虚拟机执行字节码过程中抛出异常
- 编译好合约后,不小心修改了字节码文件,导致合约是非法的字节码
- 调用合约时,指定的合约接口名称或合约接口参数不正确
当合约调用执行出错时,可以在交易回执output字段找到详细的错误信息
合约互相调用过程中的异常处理
如果在合约相互调用过程中出现异常,处理规则如下:
- A->B,B执行过程中出现异常,那么B造成的一切世界状态变化都不会生效,A不受影响
- A->B,在调用B之后A合约出现异常,A合约造成的一切世界状态变化都不会生效。B造成的一切世界状态变化都不会生效
上面提到的“造成的一切世界状态变化”指的是存储变量和TransferBalance函数造成的变化。而Log(data,topics)所产生的事件,无论合约是否出现异常,都会进入交易回执中。
合约调用栈信息
合约异常终止时,虚拟机会在交易回执中新增一条主题为“backtrace”的log,记录合约退出时的调用栈信息。
如果编译合约时保存了函数名(使用编译选项-dump-names),那么调用栈信息会包含每个被调用的函数名,如:

如果没有保存函数名,那么调用栈会包含每个被调用函数的编号,如:

合约API
区块链交互API

Pedersen密码学API(非TEE版本支持)

调试类API

ElGamal隐私保护API(仅在非TEE版本中支持)

工具类API

内置类库
时间格式化
WASM合约内无法直接获取系统时间信息,因为区块链不同节点的时间无法保证一致。用户通过GetBlockTimeStamp,或者合约调用传参的方式,在合约内获取一个有一致性保证的时间信息
接口定义
-
localtime
把以秒为单位的时间t分解后转换存入struct tm格式

-
strftime
根据指定的格式符,格式化tm格式的时间,并把结果放入指定的buffer

-
gmtime
把以秒为单位的时间t分解后转换存入struct tm格式。该接口默认时区是GMT

预编译合约(原生合约)
预编译合约概述
Solidity合约的使用与不足:
虚拟机执行性能低、代价高、开发复杂
对于联盟链,一些参数需要链上节点保持一致,如果使用Solidity,部署复杂
预编译合约框架,允许用户使用C++来写智能合约
由于不进入EVM执行,预编译合约可以获得更高的性能
适用于合约逻辑简单但调用频繁,或者合约逻辑固定而计算量大的场景。
预编译合约优点
无需学习Solidity语言即可上手
可访问分布式存储接口
并行模型大幅提升处理能力
更好的性能表现
蚂蚁链函数库
蚂蚁链合约平台在Solidity的基础上,添加了部分函数库的支持,包括对JSON/XML数据格式的构造和解析,采用预编译合约的方式加入到蚂蚁链合约平台中。示例如下:

预编译合约的架构
预编译合约会被区块执行引擎所调用
区块验证器通过区块执行引擎来执行区块
执行引擎执行区块时,根据被调用合约的地址,来判断使用EVM还是预编译合约引擎
- 当被调用的合约地址是EVM合约时,执行引擎会创建并执行EVM来执行交易;
- 当被调用合约地址是已注册的预编译合约地址时,执行引擎通过调用地址对应的预编译合约接口来执行交易

预编译合约的执行流程
执行引擎首先根据预编译合约地址拿到合约对象,然后通过调用合约对象的call接口来获取执行结果。call接口中的操作主要包括
- 根据调用参数解析出被调用的接口
- 根据ABI编码解析传入的参数
- 执行被调用的合约接口
- 将执行结果ABI编码并返回

预编译合约应用
联盟链治理
扩展Solidity能力
提供密码学算法
提升SDK易用性,降低开发门槛