大数据数仓实战项目(离线数仓+实时数仓)1
目录
1.课程目标
2.电商行业与电商系统介绍
3.数仓项目整体技术架构介绍
4.数仓项目架构-kylin补充
5.数仓具体技术介绍与项目环境介绍
6.kettle的介绍与安装
7.kettle入门案例
8.kettle输入组件之JSON输入与表输入
9.kettle输入组件之生成记录组件
10.kettle输出组件之文本文件输出
11.kettle输出组件之表输出、插入更新、删除组件
12.kettle整合hadoop
13.Hadoop file input组件
14.Hadoop file output组件
15.Kettle整合Hive
16.Kettle-Hive表输入组件
17.Kettle-Hive表输出组件
18.Kettle执行hivesql组件
19.kettle转换组件之值映射、增加序列、字段选择
20.kettle流程控件-Switchcase组件
21.kettle流程控件-过滤记录组件
22.kettle连接组件
23.kettle作业介绍
24.kettle-转换命名参数
25.kettle Linux部署
26.pansh执行转化任务
27.kitchensh执行转换任务
1.课程目标


2.电商行业与电商系统介绍







3.数仓项目整体技术架构介绍





4.数仓项目架构-kylin补充

5.数仓具体技术介绍与项目环境介绍


6.kettle的介绍与安装





7.kettle入门案例

这个连线是点击shift键,然后鼠标左键拖动


ctrl+s保存一下

csv输入配置




Excel输出配置


配置完
Ctrl+s保存一下


8.kettle输入组件之JSON输入与表输入
JSON输入









==========================================================
表输入


放到下面这个地方











查看主机地址






输出成功

但有些字段的格式有点问题
我们需要在这里控制一下

如果想让上面设置的MySQL连接可以重复使用



9.kettle输入组件之生成记录组件








10.kettle输出组件之文本文件输出







如果我们不想要头数据
则


防止中文乱码问题,还要设置编码

11.kettle输出组件之表输出、插入更新、删除组件
表输出






这里kettle会帮我们创建表





插入更新




上面就是认为当id相同时,这两个记录就算同一个记录
我们先看一下原先的数据是什么样子


然后启动

插入更新成功

删除





删除成功

12.kettle整合hadoop














最好重启一下




这里的bigdata-37就是下面的newhadoopcluster
13.Hadoop file input组件






上面就是我们的hdfs集群的路径






14.Hadoop file output组件







注意这里的编码要改成Linux对应的编码




15.Kettle整合Hive









这里我们已经创建好了
我们还是清空一下,重新创建一下


为空
下面创建文件



创建完加载到hive






16.Kettle-Hive表输入组件











17.Kettle-Hive表输出组件









执行成功,但这里速度特别特别的慢
18.Kettle执行hivesql组件




如果要在kettle中执行SQL
要新建一个作业




成功
下面我们查看一下hive中数据


19.kettle转换组件之值映射、增加序列、字段选择


值映射



1

2


3

4



==================================================================================================================================================
增加序列





==================================================================================================================================================
字段选择


这里就是要移除的字段

这里就是要改名的字段


20.kettle流程控件-Switchcase组件





21.kettle流程控件-过滤记录组件





22.kettle连接组件

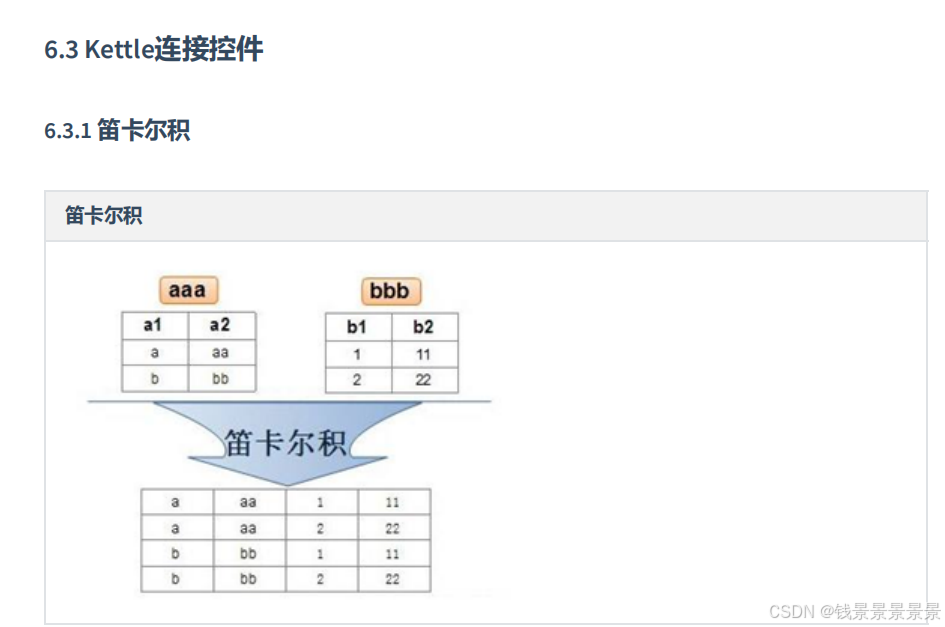





==================================================================================================================================================


这里第一个步骤相当于左表,第二个步骤相当于右表




23.kettle作业介绍






转换组件可以找到我们之前开发好的任务






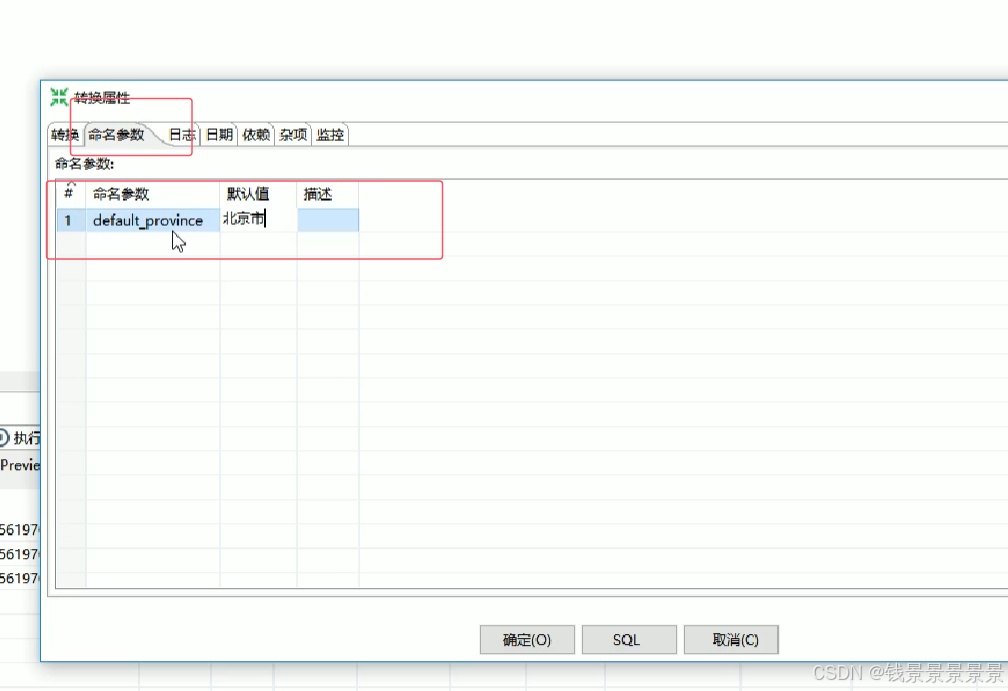
24.kettle-转换命名参数





======



查询成功,但这里的查询条件是写死在SQL语句中的
我们可以设置转换命名参数
双击转换的空白处


25.kettle Linux部署









26.pansh执行转化任务
下面我们看一下如何在Linux中执行一个转换任务

这里parm参数就是之前的转换命名餐参数



=========================
1

2
上面的路径全是Windows系统中的路径
我们要修改一下



3


27.kitchensh执行转换任务






=============================
将上一节转换命名参数去掉

在作业命名参数中,设置input和output

将转换和作业上传到Linux中


成功
