正则表达式高阶技巧之匹配模式(使用python实现)
匹配模式
- 介绍
- 不区分大小写模式
- 模式的指定方式
- 应用
- 单行模式
- 多行模式
- 注释模式
- 其它模式
- 修饰符的作用范围
介绍
- 我们在正则中所说得匹配模式(match mode),指的是匹配时使用的规则。设置特定的匹配模式,可能会改变对正则表达式的识别,也可能会改变正则表达式中字符的匹配规定
- 常见的匹配模式一共有四种:不区分大小写模式、单行模式、多行模式、注释模式
不区分大小写模式
- 在日常使用中,用户可能关心的只是文本的意义,而不是它具体形式。比如单词the,在句子中写作the,在句子开头写做The,还可能为了表示强调写作THE;可是用户可能不关心大小写,只希望找到所有的the
- 为了实现上述需求,我们可以使用字符组
[tT][hH][eE],这样的写法是没有问题的,但是如果单词较长,写起来就是比较麻烦的。比如:beautiful就要写成[bB][eE][aA][uU][tT][iI][fF][uU][lL]。更重要的是,这样的表达式不够直观,很难明白此表达式要匹配的是beautiful - 为了解决上述的问题,正则表达式提供了不区分大小写的匹配模式,指定此模式之后,在正则表达式中可以直接写
the,就可以匹配the、THE、The、THe等等各种大小写形式的the,提升了直观程度,还大大降低了理解的难度
模式的指定方式
- 在了解此模式的应用实例之前,必须要先了解模式的指定方式。通常是有两种方法来指定匹配模式的:以模式修饰符指定,或者以预定义常量作为特殊参数传入来指定
模式修饰符
- 模式修饰符即模式对应的单个字符,使用时将其填入特定结构
(?modifier)(其中modifier为模式修饰符),嵌在正则表达式的开头。比如不区分大小写的模式对应的模式修饰符是i(case Insensitive),对于the来指定此模式,完整的表达式为(?i)the
如下举例:
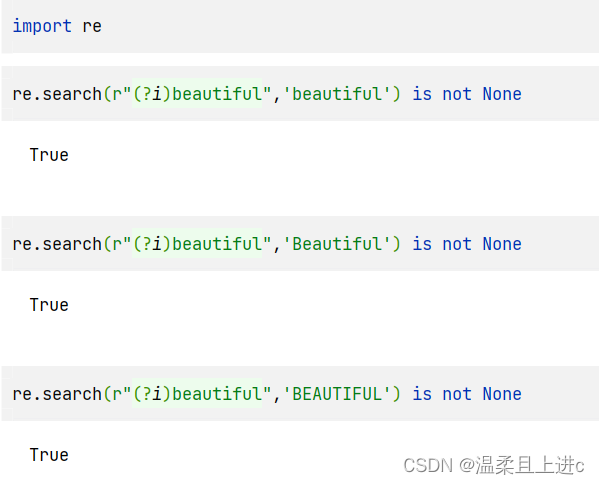
import re
re.search(r"(?i)beautiful",'beautiful') is not None
re.search(r"(?i)beautiful",'Beautiful') is not None
re.search(r"(?i)beautiful",'BEAUTIFUL') is not None
预定义好的常量作为特殊参数传入来指定
- 我们可以使用预定义好的常量作为参数,传入正则函数
- 在python中不区分大小写的预定义常量是Re类的静态成员re.IGNORECASE(一般来说。它是某个类的静态成员)
| 语言 | 常量 |
|---|---|
| python | re.I或re.IGNORECASE |
如下举例:
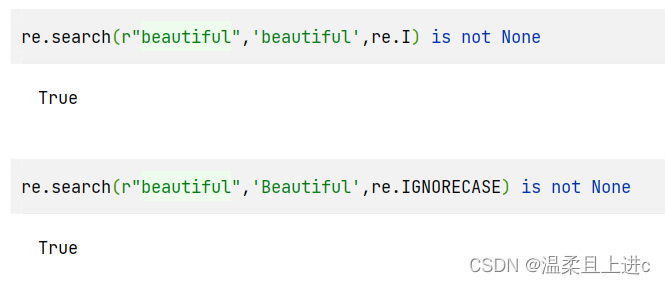
import re
re.search(r"beautiful",'beautiful',re.I) is not None
re.search(r"beautiful",'Beautiful',re.IGNORECASE) is not None
- 上述的两种指定方式,模式描述符较为通用,因为在常用的语言中写法基本相同,而预定义常量在不同语言中写法不同,不过上述的两种形式的效果是相同的:无论是以那种方式,只要指定不区分大小写模式,正则表达式在匹配时,就不会区分同一个字母的大小写形式,即
(?i)the与(?i)THE是完全等价的
应用
- 在之前匹配HTML最终tag的例子中,比如匹配超链接tag的正则表达式、匹配图片tag及网页标题tag的正则表达式,虽然在HTML规范推荐tag名都使用小写字母,但类似的<IMG>的tag还是可能出现的,为了同时兼容大写字母,可以使用不区分大小写模式,如下表格:
| 描述 | 表达式 |
|---|---|
| 提取超链接 | (?i)<a\s+href\s*=\s*["']?([^"'\s]+)["']?>([^<]+)</a> |
| 提取标题 | (?i)<head>([^>]+)</head> |
| 提取图片 | (?i)<img\s[^>]*?src=['"]?([^'"]+)['"]?[^>]*> |
单行模式
- 元字符
.几乎可以匹配任何字符,唯有换行符\n是例外。但是,有是否确实需要匹配“任何字符”,比如我们在处理爬取到的HTML源码时,经常需要跨越多行取数据,如下:
<script type="text/javascript">
...code...
...code...
</script>
- 正则文档里一般都会说明“
.不能匹配换行符”,不过部分人并不阅读与深究文档,所以认为.点号能匹配任何字符,当然也包括换行符,所以直接想法就是<script\s.*?</script> - 因为这段代码出现了换行符,所以
.*?的匹配最多只能进行到第一行末尾,可以使用[\s\S]之类的字符组匹配“任意字符”,所以正则表达式<script\s[\s\S]*?</script>能解决问题 - 不过对于大部分人来说,点号更加自然,也更加直观简洁,所以正则表达式提供单行模式,在这个模式下,所有的文本似乎只在一行里,换行符是这一行中的“普通字符”,所以可以使用
.来进行匹配 - 重点在于是将单行模式中的文本看成一行
- 单行模式对应的模式修饰符是s(Single line),所以如果要使用单行模式,只需要在表达式的开头用(?s)指定,因此上面的表达式可以修改为
(?s)<script\s.*?</script>
预定义常量如下:
| 语言 | 常量 |
|---|---|
| python | re.S或re.DOTALL |
多行模式
- “多行模式”听起来是与上述的“单行模式”对应的,但其实这两个模式是没有任何联系的
- 单行模式影响的是
.点号的匹配规则:在默认的模式下,点号.可以匹配除换行符之外的任何字符,在单行模式下点号可以匹配包括换行符在内的任何字符 - 多行模式影响的是
^与$的匹配规则:在默认的模式下^与$匹配的是整个字符串的起始位置与结束位置,但是在多行模式下,它们也能匹配字符串内部某一行文本的起始位置和结束位置 - 如下举例,需要找到下面文本中所有以数字字符开头的行:
1 one
No ycx
Yes wy
2 two
- 为解决此问题,需要定位到每一行的起始位置,尝试匹配一个数字字符,如果成功,则匹配之后的整行文本。多行模式的模式修饰符是m(Multiline),所以在表达式中的开头用
(?m)指定多行模式,这样^就可以定位到字符串内部的每一行的起始位置;匹配数字字符的表达式为\d,因为没有指定单行模式。.点号是不能匹配换行符的,.*可以匹配数字字符之后的整行文本,所以表达式就是(?m)\d.*
如下测试:
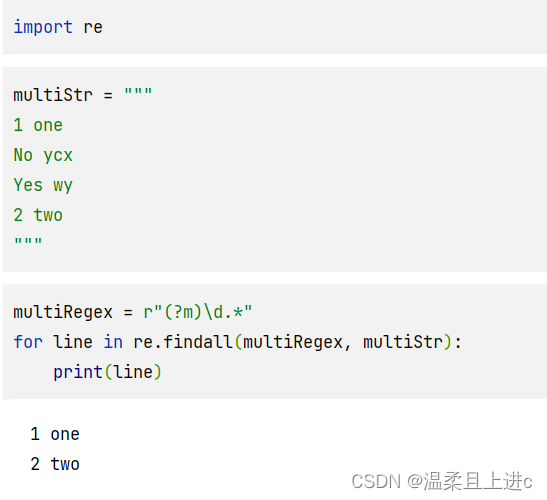
import re
multiStr = """
1 one
No ycx
Yes wy
2 two
"""
multiRegex = r"(?m)\d.*"
for line in re.findall(multiRegex, multiStr):
print(line)
- 还可以利用多行模式下的
$,给每一行末尾添加英文句号.,如下:
import re
multiStr = """1 one
No ycx
Yes wy
2 two"""
print(re.sub(r'(?m)$','.',multiStr))

- 预定义常量如下:
| 语言 | 常量 |
|---|---|
| python | re.M或re.MUTILINE |
注释模式
- 在某些情况下,用到的正则表达式可能是非常复杂的,不但难以编写和阅读,也难以维护,如果正则表达式也可以像编程语言源代码那样,可以添加注释,阅读与维护就容易多了
- 为解决上述问题,多数语言是支持使用
(?#comment)的记法添加注释,comment是注释内容。所以,在我们的表达式^\d.*?$就可以写成这样:^(?#start of the line)\d(?#digit).*?(?#rest of the line) - **.NET、Python、Ruby、PHP都是支持这种写法的,Java和JavScript则不支持,不过,还有一种注释的写法是各种语言都支持的,就是使用注释模式,此时,正则表达式对应的字符串可以跨越很多行,如下举例:
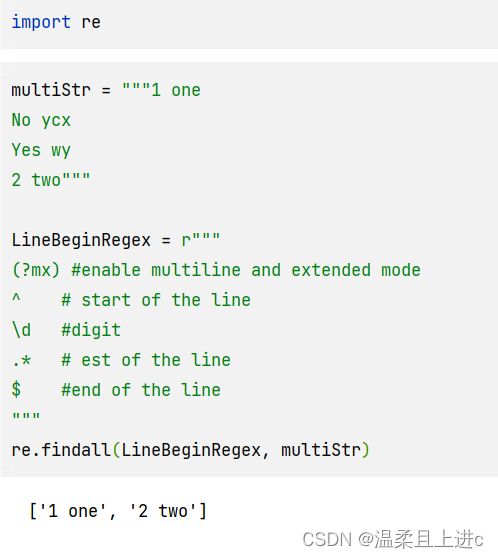
import re
multiStr = """1 one
No ycx
Yes wy
2 two"""
LineBeginRegex = r"""
(?mx) #enable multiline and extended mode
^ # start of the line
\d #digit
.* # est of the line
$ #end of the line
"""
re.findall(LineBeginRegex, multiStr)
- 在注释模式下,正则表达式内部的空白字符都会被忽略(一般来说,只要是ASCII编码中的空白字符,Unicode编码中的空白字符清空不定),注释则以
#comment的形式添加在正则表达式内部,每一条注释从#开始,到行末结束。在许多的文档,都是用这种模式来解释较为复杂的表达式,并且会使用缩进表示层级结构,这样就更加方便阅读和维护。 - 如下举例匹配日期的正则表达式
((?x)(\d{4})-(\d{2})-(\d{2})),在注释模式下的展开:
dateRegex=r"""
(?x) # enable multiline ans extended mode
( # start of the regex
(\d{4}) # year
- # dash
(\d{2}) # month
- # dash
(\d{2}) # day
) # end of the regex
"""
re.search(dateRegex,"2022-01-02").group()

- 注释模式对应的修饰符是x(extended mode,扩展模式,但是更常见的写法是free-spacing mode,宽松格式模式)
- 预定义常量如下:
| 语言 | 常量 |
|---|---|
| python | re.X或re.VERROSE |
- 在上述例子,我们同时制定了两种模式:多行模式与注释模式。注释模式的x与多行模式的m,合在一起写作
(?mx)。如果需要同时使用多种匹配模式,只要在(?modifier)中将模式修饰符排列起来即可 - 如果希望同时使用多行模式与注释模式,使用预定义常量该怎么做?答案是,使用位运算符
|,通常来说对应的预定义常量都是int类型,所以多个值进行按位与的结果,并不会彼此干扰,在python中是这样的re.M | re.X,如下:
import re
multiStr = """1 one
No ycx
Yes wy
2 two"""
LineBeginRegex = r"""
^ # start of the line
\d #digit
.* # est of the line
$ #end of the line
"""
re.findall(LineBeginRegex, multiStr, re.M | re.X)
其它模式
python的还包含有其他模式(这里仅列举两种,更多的请查阅文档):
- re.U或re.UNICODE:在此模式下。
\d \w \s等字符组简记法的匹配规则会发生改变,比如\w能匹配Unicode中的“单词字符”,包括中文字符,\d也能匹配1、2之类的全角数字字符,对应的模式修饰符是u - re.A或re.UNICODE:因为在python 3以上的版本中,正则表达式默认采用Unicode匹配规则,如果希望
\d \w等字符组简记法恢复到ASCII匹配规则,可以使用此模式,对应的模式修饰符是a
修饰符的作用范围
- 常见的模式修饰符为
(?modifier)的形式,它表示从现在开始使用此模式,通常的做法是将它写在正则表达式的开头,表示整个正则表达式都指定使用此模式;如果它出现正则表达式中,则表示此模式从这里开始生效,但是在python中情况不同,只要模式修饰符(?modifier)出现,无论出现在什么位置,都对整个正则表达式生效;如下:
re.search(r"t(?i)he","THE").group()

- 如果模式修饰符出现在某个括号内,如
((?modifier).....)那它的作用范围只限于括号内部,此模式也可记为(?modifier:.....)
如下举例:
| 正则表达式 | 可匹配的文本 |
|---|---|
| t(?i)he | tHE the tHe thE |
| th(?i)e | the thE |
| t((?i)h)e | tHe the |
| t(?i:h)e | tHe the |
- 模式修饰符对正则表达式的操作性更强,因为预定义常量指定的匹配模式是对整个正则表达式生效的