狮子座大数据分析(python爬虫版)
十二星座爱情性格 - 星座屋
首先找到一个星座网站,作为基础内容,来获取信息

网页爬取与信息提取
我们首先利用爬虫技术(如 Python 中的 requests 与 BeautifulSoup 库)获取页面内容。该页面(xzw.com/astro/leo/)中,除了狮子座基本属性外,还有两个重点部分:
- 狮子座女生:摘要中提到“特点:心地善良、爱心丰富”,“弱点:喜欢引人注目”,“爱情:不太懂得疼爱对方”。
- 狮子座男生:摘要中提到“特点:热情、组织能力、正义感”,“弱点:高傲、虚荣心”,“爱情:追求轰轰烈烈的爱情”。
通过解析这些文字,我们可以归纳:
- 狮子座男生:性格热情、具备较强的组织能力和正义感,但有时表现出高傲和虚荣,热衷于追求激情四溢的爱情。
- 狮子座女生:性格温暖、心地善良且富有爱心,但喜欢吸引他人注意,在爱情中可能表现得不够细腻体贴。
import requests
from bs4 import BeautifulSoup
import time
base_url = "https://www.xzw.com/astro/leo/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
}
collected_texts = []
visited_urls = set()
def scrape_page(url):
global collected_texts
if url in visited_urls:
return
try:
response = requests.get(url, headers=headers, timeout=10)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
page_text = soup.get_text(separator="\n", strip=True)
collected_texts.append(page_text)
visited_urls.add(url) # 标记该 URL 已访问
print(f"已爬取: {url} (当前累计 {len(collected_texts)} 条文本)")
for link in soup.find_all('a', href=True):
full_link = link['href']
if full_link.startswith("/"):
full_link = "https://www.xzw.com" + full_link
if full_link.startswith(base_url) and full_link not in visited_urls:
if len(collected_texts) >= 1000:
return
time.sleep(1)
scrape_page(full_link)
except Exception as e:
print(f"爬取 {url} 失败: {e}")
scrape_page(base_url)
with open("test.txt", "w", encoding="utf-8") as file:
file.write("\n\n".join(collected_texts))
print("🎉 爬取完成,数据已保存到 test.txt 文件!")
将爬取到的数据存入test.txt中后,进行分析
import jieba
import re
from collections import Counter
def read_file(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
return text
def clean_text(text):
text = re.sub(r'\s+', '', text)
text = re.sub(r'[^\u4e00-\u9fa5]', '', text)
return text
def tokenize(text):
words = jieba.lcut(text)
return words
def count_words(words):
return Counter(words)
POSITIVE_WORDS = {"自信", "阳光", "大方", "慷慨", "勇敢", "领导", "果断", "豪爽", "热情", "友善","善良"}
NEGATIVE_WORDS = {"自负", "霸道", "固执", "急躁", "冲动", "强势", "高傲", "爱面子", "争强好胜", "以自我为中心"}
def analyze_personality(word_counts):
total_words = sum(word_counts.values())
pos_count = sum(word_counts[word] for word in POSITIVE_WORDS if word in word_counts)
neg_count = sum(word_counts[word] for word in NEGATIVE_WORDS if word in word_counts)
pos_percent = (pos_count / total_words) * 100 if total_words > 0 else 0
neg_percent = (neg_count / total_words) * 100 if total_words > 0 else 0
neutral_percent = 100 - pos_percent - neg_percent
return pos_percent, neg_percent, neutral_percent
def evaluate_personality(pos_percent, neg_percent):
if pos_percent > neg_percent:
conclusion = "狮子座整体评价较好,正面特质占比更高。"
elif neg_percent > pos_percent:
conclusion = "狮子座评价存在较多负面特质,但也有正面评价。"
else:
conclusion = "狮子座评价较为中立,正负面评价相当。"
return conclusion
def main():
text = read_file("test.txt")
text = clean_text(text)
words = tokenize(text)
word_counts = count_words(words)
pos_percent, neg_percent, neutral_percent = analyze_personality(word_counts)
conclusion = evaluate_personality(pos_percent, neg_percent)
print("🔍 狮子座性格评价分析:")
print(f"✅ 正面评价占比:{pos_percent:.2f}%")
print(f"❌ 负面评价占比:{neg_percent:.2f}%")
print(f"⚖ 中立评价占比:{neutral_percent:.2f}%")
print(f"📢 结论:{conclusion}")
if __name__ == "__main__":
main()

进行评价:
import jieba
import jieba.posseg as pseg
import re
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def read_file(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
return text
def clean_text(text):
text = re.sub(r'\s+', '', text) # 去除空格和换行符
text = re.sub(r'[^\u4e00-\u9fa5]', '', text) # 只保留中文
return text
def tokenize(text):
words = pseg.lcut(text) # 使用 jieba 进行分词并标注词性
adjectives = [word for word, flag in words if flag == 'a'] # 只保留形容词
return adjectives
def count_words(words):
return Counter(words)
def generate_wordcloud(word_counts):
wordcloud = WordCloud(font_path='msyh.ttc', width=800, height=600, background_color='white').generate_from_frequencies(word_counts)
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
def top_words(word_counts, top_n=10):
return dict(word_counts.most_common(top_n))
def main():
text = read_file("test.txt")
text = clean_text(text)
words = tokenize(text)
word_counts = count_words(words)
top_n_words = top_words(word_counts, top_n=10)
generate_wordcloud(top_n_words)
if __name__ == "__main__":
main()

多种图:
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import jieba
import jieba.posseg as pseg
import re
from collections import Counter
from wordcloud import WordCloud
# 设置支持中文的字体(以黑体为例)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 防止负号显示为方块
plt.rcParams['axes.unicode_minus'] = False
def read_file(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
return text
def clean_text(text):
text = re.sub(r'\s+', '', text)
text = re.sub(r'[^\u4e00-\u9fa5]', '', text)
return text
def tokenize(text):
# 使用 jieba 对文本进行分词和词性标注
words = pseg.lcut(text)
# 仅保留形容词相关词性(例如 'a' 表示形容词),过滤掉名词等其它词性
adjectives = [word for word, flag in words if flag in ['a', 'ad', 'an', 'ag']]
return adjectives
def count_words(words):
return Counter(words)
def generate_wordcloud(word_counts):
wordcloud = WordCloud(font_path='msyh.ttc', width=800, height=600, background_color='white').generate_from_frequencies(word_counts)
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title("狮子座相关评价词云", fontsize=20, fontweight='bold', family='Microsoft YaHei')
plt.show()
def plot_bar_chart(word_counts, top_n=10):
top_words = dict(word_counts.most_common(top_n))
plt.figure(figsize=(10, 6))
plt.bar(top_words.keys(), top_words.values(), color='skyblue')
plt.title("狮子座最常见形容词柱状图", fontsize=18, fontweight='bold', family='Microsoft YaHei')
plt.xlabel("形容词", fontsize=14, family='Microsoft YaHei')
plt.ylabel("频率", fontsize=14, family='Microsoft YaHei')
plt.xticks(rotation=45)
plt.show()
def plot_horizontal_bar_chart(word_counts, top_n=10):
top_words = dict(word_counts.most_common(top_n))
plt.figure(figsize=(10, 6))
plt.barh(list(top_words.keys()), list(top_words.values()), color='lightcoral')
plt.title("狮子座最常见形容词条形图", fontsize=18, fontweight='bold', family='Microsoft YaHei')
plt.xlabel("频率", fontsize=14, family='Microsoft YaHei')
plt.ylabel("形容词", fontsize=14, family='Microsoft YaHei')
plt.show()
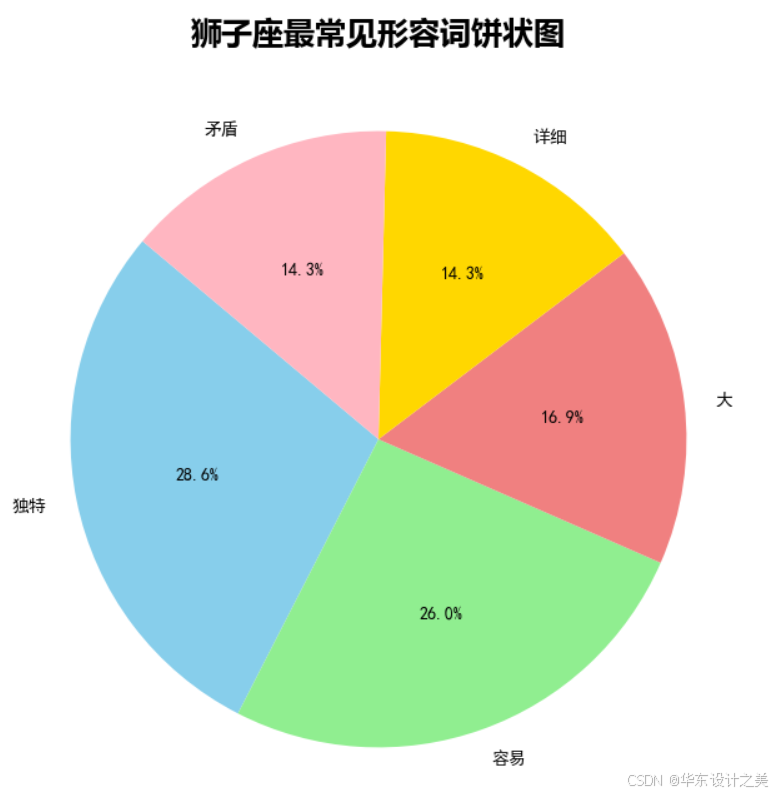
def plot_pie_chart(word_counts, top_n=5):
top_words = dict(word_counts.most_common(top_n))
plt.figure(figsize=(8, 8))
plt.pie(top_words.values(), labels=top_words.keys(), autopct='%1.1f%%', startangle=140,
colors=['skyblue', 'lightgreen', 'lightcoral', 'gold', 'lightpink'])
plt.title("狮子座最常见形容词饼状图", fontsize=18, fontweight='bold', family='Microsoft YaHei')
plt.show()
def main():
text = read_file("test.txt")
text = clean_text(text)
words = tokenize(text)
word_counts = count_words(words)
generate_wordcloud(word_counts)
plot_bar_chart(word_counts)
plot_horizontal_bar_chart(word_counts)
plot_pie_chart(word_counts)
if __name__ == "__main__":
main()