【C语言】整形数据的存储和读取过程
文章目录
- 一. 问题引入
- 二. 存储过程
- 三. 读取过程
一. 问题引入
观察下面一段代码:
#include <iostream>
using namespace std;
int main()
{
unsigned int a = -10;
printf("%d\n", a);// -10
printf("%u\n", a);// 4294967286
return 0;
}
最终程序编译运行通过,没有任何的报错或警告。按理来说 -10 是不能被存入一个无符号类型的变量里的,我们可以说C语言对类型的检查不严格,那么这个 -10 究竟是怎么被存进去的呢?
二. 存储过程
存储的过程可以分为以下三步:
- 看变量的类型,决定开多大的空间
- 把要存入的数值转化成二进制补码形式
- 把转化好的二进制补码按大小端规则存入到先前开辟好的空间当中(注意是以字节为单位把数据存入到空间当中)
具体回到上面的例子,看看 -10 是怎么被存到 a 这个变量里去的。
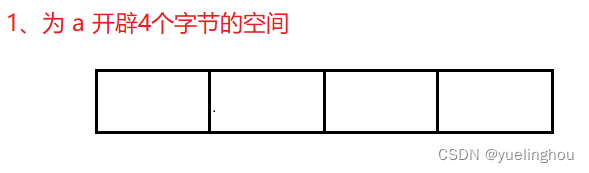
第一步:首先操作系统看到 a 这个变量的类型是 int,所以会为其在栈中开辟出 4 字节的空间。注意开空间的时候不会考虑这个变量到底是有符号还是无符号,操作系统只关心到底要开出多少的空间。
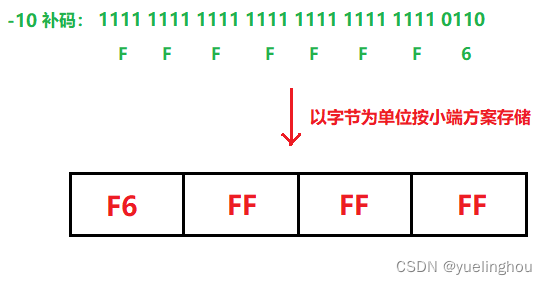
第二步:空间有了之后,就要把数据放入到空间中,需要放入的数据是 -10,不论是正数还是负数,我们都要把它转化成补码,之后才能存入到空间中。

第三步:最后一步把数据放入空间时要考虑大小端的问题,现在的电脑大部分都是小端存储,即低权值数据存到高地址,高权值数据存到低地址。
PS:大小端存储方案的本质是数据和空间按照字节为单位的一种映射关系
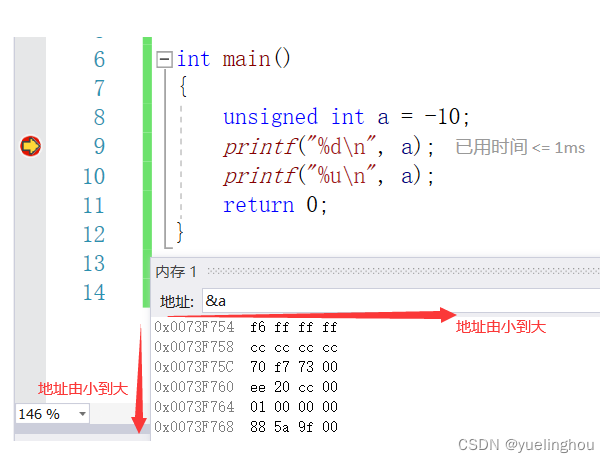
我们在程序中打开内存串口,可以看到 a 的数据存放确实是按照小端来存的
三. 读取过程
读取过程分为以下两步:
- 按照大小端规则,以字节为单位拿出空间中的二进制补码数据
- 根据变量的类型,去解释拿出来的二进制补码数据
- 无符号类型:补码 = 源码
- 有符号类型:
- 最高位为0说明是正数,此时补码 = 源码
- 最高位为1说明是负数,需要把补码转化成源码
第一步:根据小端方案把数据从空间中逐个字节地拿出来
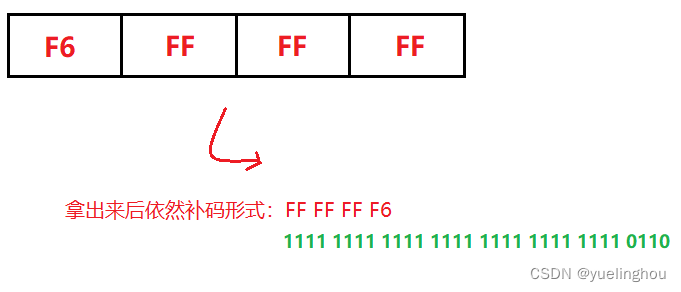
第二步:根据变量类型解释从空间中取出来的二进制补码序列
