食品计算—MetaFood3D: 3D Food Dataset with Nutrition Values
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- 1. 背景介绍
- 2. 相关工作
- 3. 数据集
- 3.1 食物对象选择
- 3.2 数据采集
- 3.3 标注
- 4. 实验结果
- 4.1. 3D 食物感知
- 4.2. 新视角合成与三维重建
- 4.3. 食物场景合成与三维生成
- 4.4. 食物分量估计
- 5. 结论
1. 背景介绍
Chen Y, He J, Czarnecki C, et al. MetaFood3D: 3D Food Dataset with Nutrition Values[J].
🚀以上学术论文翻译由ChatGPT辅助。
食品计算在计算机视觉(CV)中既重要又具有挑战性。它因在各种应用中的频繁出现而显著推动了CV算法的发展,这些应用包括分类、实例分割到三维重建。
食品的多变形状和纹理,加上形式的高度变化以及包括语言描述和营养数据在内的大量多模态信息,使得食品计算对现代CV算法而言是一项复杂而艰巨的任务。
三维食品建模是解决与食品相关问题的新前沿,因为它具有处理随机相机视角的内在能力,并且为计算食品分量提供了直观的表示方式。
然而,食品对象分析算法发展的主要障碍是现有三维数据集中缺乏营养数值。
此外,在更广泛的三维研究领域中,迫切需要特定领域的测试数据集。
为了弥合通用三维视觉与食品计算研究之间的差距,我们引入了MetaFood3D。
该数据集由743个精细扫描和标注的三维食品对象组成,涵盖了131个类别,提供了详细的营养信息、重量以及与综合营养数据库关联的食品编码。
我们的MetaFood3D数据集强调类别内部的多样性,并包含丰富的模态,如带纹理的网格文件、RGB-D视频和分割掩码。
实验结果表明,我们的数据集在增强食品分量估计算法方面具有强大的能力,突出了视频捕捉与三维扫描数据之间的差距,并展示了MetaFood3D在生成合成进餐场景数据和三维食品对象方面的优势。
数据集可通过以下网址获取:
https://lorenz.ecn.purdue.edu/~food3d/
食物是我们生存的基本要素,不仅是生存的基本必需品,也是社会交往中至关重要的组成部分,例如我们常常会分享食物的图片、视频,甚至在电子游戏中体验虚拟食物。
与食物相关的图像分析对于监测和改善不同年龄群体的饮食习惯至关重要,因为它可以实现个性化的营养干预,支持对营养缺失的早期发现,并促进适应儿童、成年人和老年人具体需求的更健康的生活方式。
在计算机视觉领域,食物因在专用和通用数据集中频繁出现而在推动算法发展中发挥了重要作用,涉及的任务包括分类 [13, 18, 27, 63]、实例分割 [33] 和三维物体重建 [62]。
由于类别不平衡、纹理复杂、分层分类以及形状模糊,食物数据具有独特的复杂性。
食物图像通常在近距离拍摄,摄像头角度多变,导致视觉表现差异很大。
典型的单视角图像往往无法提供全面视图,从而遮蔽了有关食材和分量的关键信息。例如,一个三明治的俯拍图可能只能看到面包,而侧面视图则能显示出面包、肉和配料的更多细节,这突出了单视角图像分析的局限性。
准确测量在各种与食物相关的任务中至关重要,尤其是在精确饮食评估的背景下,它可以作为一种有价值的数字生物标志物,提供对个体营养摄入量及其对健康状态潜在影响的量化和客观衡量。
饮食评估中的一个重大挑战是如何从食物图像中准确估计分量大小 [76]。
为了解决这个问题,研究者提出了多种方法,包括基于图像的回归 [82]、基于分割掩码的回归 [22, 31]、映射到手工设计的三维形状模板 [26]、多视图三维重建 [30],以及利用深度信息 [17]。
然而,由于缺乏对单个食物对象的三维信息,这些方法往往不够准确且泛化能力不足。
即便有深度数据,准确表示食物物体下方的空隙仍是一大挑战,因为盘中食物可能具有各种各样的6D姿态和堆叠关系。
近期在三维视觉算法方面的进展,特别是在新视角合成 [50]、表面重建 [85] 和三维物体生成 [36] 方面,表明了克服这些问题的有希望的方向。
在与食物相关的研究中利用三维方法具有内在优势,例如通过新视角合成或从学习得到的几何体进行渲染,可缓解因相机角度变化带来的挑战。
这些方法可以直接计算每种食物的体积,从而使饮食研究过程比现有方法更加精确、直观和可解释。
然而,目前将这些三维算法应用于与食物相关任务的主要障碍是缺乏构建良好的食物数据集。
许多通用的大规模三维数据集 [10, 12, 88] 近年来已被发布,推动了三维视觉算法的发展 [42, 72]。
然而,用于训练和评估三维算法在食物相关任务上的专用数据集却明显不足。
现有的包含食物的三维数据集通常缺乏饮食标注信息,如重量、热量和其他营养数值,这对于开发基于三维或图像的饮食评估算法至关重要。
此外,缺少具有丰富类别内变异的三维食物基准数据集。例如,OmniObject3D 数据集 [88] 包含2837个食物对象,但其食物实例的选择未能强调每个食物类别中的外观变化。
OmniObject3D 中的许多食物项,如柠檬,在同一类别下具有相似的外观和几何形状。
为了弥合通用三维视觉与食品计算之间的差距,并为通用与食物特定的下游任务提供独特的基准,我们的数据集 MetaFood3D(如图1所示)旨在开发一个专用于食物的三维数据集,以将饮食分析从二维推进到三维。
MetaFood3D 包含总共743个属于131个食物类别的三维食物对象。
数据集中的每个食物对象都被精细标注了详细的营养信息、重量以及与综合营养数据库 [52] 相关联的食物编码。
我们通过收集外观和营养信息各异的食物,强调类别内的多样性。
除了营养数据,我们的数据集还包含丰富的模态信息,如带纹理的网格文件、RGB-D 视频和分割掩码。
此外,该数据集还包含分层关系,通过在通用食物类别中指定子类别(即具体的食物项),以支持细粒度分类相关的任务。
最后,我们为营养估计、感知、重建和生成任务建立了基准。
我们的实验表明,该数据集在提升模型性能方面具有巨大潜力,并凸显了视频捕捉与三维扫描数据之间的挑战性差距。
此外,我们通过呈现高质量的可视化结果展示了该数据集在高质量数据生成、模拟和增强方面的潜力。

2. 相关工作
本节我们详细回顾了与食物及三维物体数据集相关的研究,并简要综述了与之相关的下游任务。这些数据集的特点总结在表1中。
食物数据集主要用于回答食品计算中的关键问题:“图像中是什么食物?”、“食物的分量是多少?”、“食物的营养成分是什么?”虽然已有大量用于食物分类的数据集,从经典的Food-101数据集 [4] 到最新的Food2K数据集 [51],但用于分量估计或宏量营养素估计的数据集却显著较少。这种稀缺性源于采集带有物理食物参照的多模态数据所需的人力成本高、复杂度大。
为了减少采集真实物体数据的需求,已有许多尝试,包括利用菜谱网站上的图像和元数据 [68],或通过将图像纹理贴附到预定义几何体上合成数据 [94]。然而,这些方法存在根本性的缺陷,因为它们未能通过真实食物验证食物外观与重量之间的关系。
尽管已有文献提出了一些带有地面参照的食物分量估计数据集 [32, 44, 75, 86],但目前只有三个公开数据集包含营养数值:ECUSTFD [35]、Nutrition5K [82] 和 NutritionVerse3D [78]。
ECUSTFD 数据集不包含几何信息。Nutrition5K 中食物被混合在一起,且不带有分割掩码,因此无法对单个食物进行营养和几何建模。NutritionVerse3D 数据集包含了来自 FoodVerse [77] 的模型,但其规模较小,仅包含105个食物三维模型,覆盖42种独立食物类型。这些食物项在大小上未经过校准,且所选食物种类看起来是随机且不平衡的。
三维物体数据集则主要关注由人类创建的合成物体或通过手动扫描获取的现实物体。合成物体数据集,如ShapeNet [6] 和 Objaverse [10],由于其艺术化的外观和无参照比例,不适用于饮食评估应用。现实扫描物体提供更真实的外观和几何,但大多数现实三维数据集主要集中于非易腐的日用商品,例如 Google Scanned Objects (GSO) [12]、CO3D [64]、YCB Objects [5]、AKB-48 [40] 和 MetaGraspNetV2 [15]。一些现实扫描数据集虽然包含食物项,但往往类别数量较少 [64]。此外,食物的选择往往是随机的,未能反映人们常见饮食的真实分布,从而导致饮食评估中的偏差 [88]。
用于饮食评估的食物数据分析。 现有的食物分量和营养价值估计方法可分为四大类:基于立体视觉 [9, 59],基于深度 [11, 43],基于模型 [25, 91],以及基于神经网络的方法 [19, 20, 46, 70, 71, 82, 83]。近期,基于三维模型的方法 [47, 84] 通过优于许多现有方法的表现,展示了三维模型在食物分量估计中的重要性。
三维点云感知。 此任务旨在对由一组三维坐标组成的点云数据进行分类。PointNet [60] 首次提出了可直接处理无序点云数据集的方法。PointNet 推动了众多新模型的发展 [48, 61, 87, 92]。由于真实世界点云数据的特点,鲁棒性在三维点云感知中尤为关键。此前的研究 [1, 65, 66, 74] 探讨了模型在来自不同领域的点云数据以及标准化干扰数据集上的鲁棒性表现。
新视角合成与三维网格重建。 新视角合成旨在给定少量训练图像的前提下,从新角度生成高质量图像。Neural Radiance Fields (NeRF) [50] 通过训练多层感知机(MLP)网络来预测空间中位置的颜色值和密度,从而解决了这一问题。近期的研究已解决了别名、质量和效率等问题 [2, 28, 53, 79]。
三维网格重建旨在重建物体的网格结构。传统方法如 SfM(结构光重建)[69] 通过确定与每张图像相关的相机姿态来完成重建。近期方法则利用新视角合成中的体渲染技术 [24, 34, 85] 或采用神经符号距离场(Neural Signed Distance Fields)[54]。
三维生成。 随着新视角合成和生成模型的进展 [67],过去一年中涌现出大量文本到三维生成的方法 [39]。典型流程包括利用扩散模型生成一个物体的多视图图像,再利用三维重建方法创建三维模型 [45, 72]。其他方法则集中于学习神经符号距离场以实现三维生成 [14]。

3. 数据集
MetaFood3D 数据集中食物对象的选择与多模态标注旨在支持饮食评估应用,包括识别图像中的各种食物、估计分量及其营养价值,这些任务通常结合 RGB 和/或深度传感器,并涉及来自不同角度的摄像头视角。为准确反映这些使用场景,我们首先根据现实世界的饮食消费模式精心选择了食物种类和其多样性(详见“食物对象选择”段落)。其次,我们设计了多模态数据及其标注,以捕捉真实饮食评估数据的关键特征(详见“数据采集与标注”段落)。图2展示了 MetaFood3D 的整体情况,包括不同食物对象在数量和能量上的分布,以及类内多样性。

3.1 食物对象选择
确定采集哪些食物对象是一个挑战,因为食物种类繁多,即使同一种食物内部也存在显著的外观差异。例如,“苹果”可以广义归类为水果,但它们存在品种、颜色、形状、大小等差异,还可以作为苹果派等不同形式出现。此外,分类粒度的设定也是一项挑战——应按“水果”分类,还是更具体的“苹果”,甚至是“富士苹果”?为解决这些问题,我们咨询了营养专家,并参考了 VIPER-FoodNet(VFN)数据集中建立的食物清单 [49]。VFN 数据集源自 What We Eat in America(WWEIA)数据库,提供了关于美国饮食的全面视图,被广泛应用于食品计算任务中,例如长尾学习 [21]、持续学习 [63]、个性化分类 [56] 和多模态学习 [57]。
为了提升类别多样性,我们在 VFN 原有的 74 类食物的基础上,参考国家健康与营养检查调查(NHANES)[37] 数据,扩展了 57 个食物类别,从而使 MetaFood3D 总共包含 131 个食物类别。这种扩展不仅增加了覆盖范围,还提升了文化多样性,因为 NHANES 包含了来自多种文化背景的食物(如亚洲料理中的寿司),使数据集更具代表性。
我们相较于 VFN 数据集的一项关键提升,是在食物编码匹配上的粒度更高。VFN 将每类食物与一条来自 FNDDS(Food and Nutrient Database for Dietary Studies)[52] 的 8 位编码相对应,导致 74 类仅有 74 个食物编码;而我们的方法则采用两级结构,即既有类别级的编码,也有具体食物项的编码,最终构建了 131 个类别编码与 743 个独立食物项编码。例如,在“派(Pie)”类别中,我们包含“巧克力奶油派”、“胡桃派”、“苹果派”、“柠檬派”等子项,每项都对应其 FNDDS 编码。这种细粒度标注使我们能够更准确地反映食物的成分与营养结构,为计算机视觉算法区分类内食物提供数据基础。
最终,我们定义了 220 个独立的食物项(每项对应唯一的 FNDDS 编码),作为我们三维数据采集的基础。通过为每个类别采集多个食物项,数据集可以捕捉类内视觉和几何多样性,从而提升算法对饮食评估的准确性。在类间和类内多样性的权衡上,我们更重视类别扩展,因为我们认为生成式模型在数据增强方面具有潜力,可以在人工数据采集之外进行可扩展的扩展。如果仅聚焦于类内差异,反而会限制模型的泛化能力。
3.2 数据采集
我们优先从餐馆和超市中采集真实食物样本,包括即食和冷冻食品。对于难以采购的食物,我们从原材料开始自行制作,例如花生酱果酱三明治。在采集过程中,我们结合类别级和项级的食物分类方式,并通过多种策略增强类内多样性:包括从不同餐馆、商店、地域采购;选择不同口味、品牌、品种或加工形式;切割、去皮或拆包装;使用不同配料制作等。
三维数据采集过程类似于 OmniObject3D [88] 和 NutritionVerse3D [78]。我们将食物置于转盘上,使用 3D 扫描仪 Revopoint POP 2†,固定安装在三脚架上进行扫描。随后记录该食物的重量与营养值。大多数对象通过 RevoScan 软件 [81] 提供的关键点追踪功能,可以顺利完成360度点云采集。如果无法一次完成,则手动旋转物体进行补采。
与 OmniObject3D 的 360° 捕捉不同,我们采用 720° RGBD 视频捕捉方式,将物体进行两圈螺旋式旋转,并以俯拍收尾。这种方式更贴近智能手机用户的实际拍摄视角。若食物可翻转(如牛肉炖菜不能翻转),我们会翻面再重复一次视频采集。深度图使用 iPhone App Record3D [73] 获取。为保证尺度与颜色精度,我们采用 fiducial markers [90] 进行相机角度与颜色标定。更多采集流程细节见附录材料。
3.3 标注
采集完成后,我们进行后处理并为每个食物对象进行标注。其中一项关键创新,是为每个食物对象标注重量与营养成分,这是食品数据和饮食评估任务的基础。
在数据采集时,我们记录每个食物对象 i i i 的重量 w i w_i wi(单位:克)。通过该对象所关联的食物编码,我们获取其营养密度向量 d i d_i di,表示每 100 克食物中的营养值。该向量形式为 d i = [ e i , p i , c i , f i ] d_i = [e_i, p_i, c_i, f_i] di=[ei,pi,ci,fi],分别表示单位质量下的能量(千卡)、蛋白质(克)、碳水化合物(克)与脂肪(克)。根据 [21, 38],我们可以计算该对象实际重量下的总营养值为:
n i = w i 100 ⋅ d i n_i = \frac{w_i}{100} \cdot d_i ni=100wi⋅di
这些重量与营养值的加入,使得研究者可以发展与评估精准饮食评估与营养估计算法。
此外,如 [88] 所示,我们还生成了支持通用 3D 视觉研究的数据,包括点云分析、神经辐射场、三维生成等任务。具体包括使用 Blender [80] 渲染具备准确相机姿态的多视角写实图像,生成深度图和法线图,并从每个三维模型中采样多分辨率点云。
对于采集的 RGBD 视频,我们提供均匀采样的视频帧及对应的分割掩码与深度图。分割掩码基于 GroundingDINO [41]、Segment Anything Model (SAM) [29] 和 Cutie [8] 生成。
总体而言,我们共采集了 743 个食物对象,覆盖 131 个食物类别。每个样本包含如下标注信息:
- 带纹理的三维扫描网格;
- 标准姿态和翻转拍摄的 RGBD 视频;
- 视频帧对应的深度图与分割掩码;
- FNDDS 食物编码;
- 营养信息(能量、蛋白质、碳水、脂肪);
- 重量信息;
- 使用 Blender 渲染的多视角图像(含法线和深度图);
- 渲染时使用的相机参数;
- 视频中使用的已知尺寸的标定 fiducial marker。
4. 实验结果
在本节中,我们展示了 MetaFood3D 数据集在四个下游任务中的应用:3D 食物感知(4.1节)、新视角合成与三维重建(4.2节)、3D 食物生成与渲染(4.3节)、以及食物分量估计(4.4节)。所有实验的具体实现细节可见补充材料。
4.1. 3D 食物感知
类内形状多样性: 现实生活中的食物对象经常被处理为各种不同形状,例如完整水果与切片水果,或是一个坚果与一碗坚果。为了展示形状多样性对 3D 感知算法的影响,我们选用 OmniObject3D 上训练好的10种方法,并在 OmniObject3D(OAUniform)与 MetaFood3D(OADiverse)中进行测试,类别相同。我们使用总体准确率(Overall Accuracy, OA)衡量模型对不同点云形状的鲁棒性。表2显示,相较于 OAUniform,OADiverse 通常低了约70%,这表明在统一形状上训练的模型在面对多样形状测试集时表现明显下降。这一发现强调了在 3D 食物数据集中引入形状多样性的必要性,这也是 MetaFood3D 的一大优势,可提升 3D 感知算法在实际应用中的鲁棒性与泛化能力。

点云损坏情况: 现实中的3D点云数据常受多种干扰影响,例如噪声、点丢失或缩放问题,通常由于传感器限制或扫描条件变化引起。为评估模型在这些损坏条件下的鲁棒性,我们构建了 MetaFood3D-C,通过 [66] 中定义的常见点云损坏方式对 MetaFood3D 进行扰动。OAClean 表示干净测试集上的准确率,平均损坏误差(mCE)衡量模型在带有损坏的 MetaFood3D-C 上的表现。表2中,PointNet++ 和 GDANet 在各种损坏条件下整体表现最优。完整结果详见补充材料。
4.2. 新视角合成与三维重建
在饮食评估应用中,参与者通常仅需拍摄一小段视频,包含有限的食物视角范围。这些应用为新视角合成与三维重建算法提供了理想的测试场景。本节中,我们展示了这两个任务的初步结果,分别基于视频捕捉数据与 Blender 渲染图像。
在新视角合成任务中,我们从每个类别中选取一个对象,并使用 Nerfacto [79] 和 Gaussian Splatting (GS) [28] 进行测试,采用官方默认配置。在训练数据中使用 90%,剩余 10% 用于测试。我们遵循 [50] 的做法,报告 PSNR、SSIM 与 LPIPS 得分。结果如表3所示。可视化结果显示,Nerfacto 在部分视频场景中无法识别前景,仅生成纯背景,而 GS 则成功合成所有对象。我们还尝试为 Nerfacto 提供前景掩码,前景可以成功学习,但背景中出现伪影,导致定量结果较差(见表3)。因此,在视频数据中,掩码对 Nerfacto 等基于 NeRF 的方法至关重要,而在渲染图像中影响较小。这表明我们数据集中存在视角稀疏、目标尺度变化等挑战。
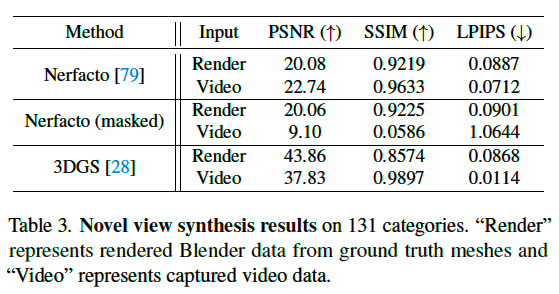
在 3D 网格重建任务中,我们基于 Nerfacto 的表面法线预测进行训练,并使用泊松重建算法获得三维网格。我们使用 Chamfer 距离(CD)将渲染图像生成的网格与原始网格进行对比。结果显示,131个对象中有5个无法成功重建,其余的平均 Chamfer 距离为 848.54。对于视频数据,由于姿态对齐较复杂,我们仅在图3中展示一个定性结果,进一步凸显了数据集的挑战性。
4.3. 食物场景合成与三维生成
食物计算领域的一大挑战,尤其是在分量估计与营养评估中,是缺乏包含准确体积与营养信息的真实数据集 [4, 51]。已有数据集如 [35, 82] 虽包含营养数据,但摄像头视角与食物组合多样性不足,限制了模型鲁棒性训练。由于食材采购成本高、称重与多视角采集耗时且复杂,导致大规模数据采集难以扩展。
受机器人 [15] 与自动驾驶 [58] 中 sim-to-real 方法成功经验启发,MetaFood3D 提供了多样的三维食物对象,用于模拟真实的饮食场景,生成多样化图像及对应的地面真实数据,包括精确的营养值与分量。这种方式有助于开发大规模、真实、可扩展的数据集。同时,结合先进的纹理与 3D 食物生成方法,还可进一步增强模拟数据的多样性。

食物场景合成: MetaFood3D 可用于创建具有可调参数(如食物放置、分量、营养成分)的合成饮食场景。如图5(a)(b)©,我们在 NVIDIA Omniverse 模拟引擎 [55] 中构建了早餐场景,包含营养值、分割掩码与深度图等标注信息。同时可提取边界框与6D姿态等标注。还可借助纹理生成技术 [7] 增强食物外观(如图5(d)(e))。


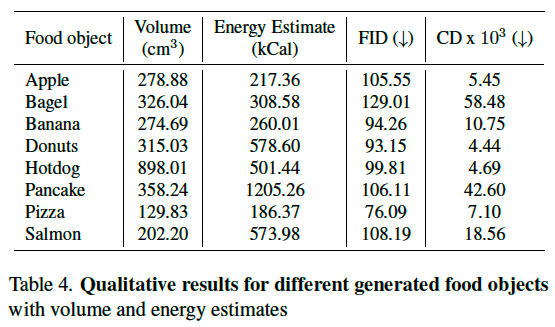
3D 食物生成: 我们使用 GET3D [14] 对各类食物进行纹理化 3D 网格生成。每类食物单独训练 GET3D 模型,训练 3500 个 epoch,每个对象平均使用 750 张分辨率为 512 的渲染图像。由于初始样本数较少,我们将 gamma 设置为 3000,以增强判别器训练,生成更真实的网格。我们通过 FID [23] 与 Chamfer 距离(CD)[3] 评估生成质量(表4)。一大亮点是我们对每个生成食物对象加入体积与能量估计,通过 Blender 获取体积,并结合营养数据库中 FNDDS 编码进行能量计算。此方法增强了生成对象的真实性,提升了营养评估功能。图4展示了我们生成的自然纹理、几何细节丰富的 3D 食物模型。
4.4. 食物分量估计
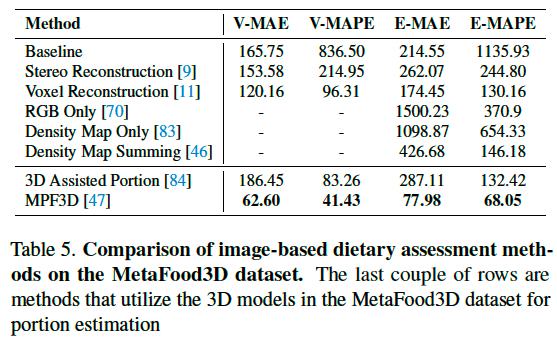
食物分量估计是一项挑战性强但至关重要的图像分析任务。基于 MetaFood3D 中丰富的营养标注与三维信息,我们比较了四种主流方法(基于立体视觉、深度、模板与神经网络)在该任务中的表现。具体地,我们为数据集中每个食物项从视频中采样 2 帧图像,将所有食物划分为训练集与测试集,每类选取一个食物作为测试集,其余为训练集。最终训练集含 1036 张图像,测试集 216 张图像。
所有方法在相同测试集上评估,比较指标包括:体积估计的平均绝对误差(V-MAE)与平均绝对百分比误差(V-MAPE),以及能量估计的 E-MAE 与 E-MAPE。对于神经网络方法,因其直接回归能量值,V-MAE 与 V-MAPE 不适用。
表5展示了各类方法在 MetaFood3D 上的性能。MPF3D [47] 展现了 3D 信息在分量估计中的重要性,优于所有其他方法。3D Assisted Portion Estimation 方法 [84] 的 V-MAPE 与 E-MAPE 也表现出色。这些结果表明,借助 MetaFood3D 提供的 3D 信息能显著提升分量估计性能,从而证实该数据集在饮食评估技术发展中的重要价值。
5. 结论
本文提出了 MetaFood3D,这是一个专为食品计算和 3D 视觉任务构建的三维食物对象数据集。该数据集为现实场景中的 3D 视觉算法提供了可靠的基准平台,具备类内多样性、详细营养标注和丰富多模态特征。实验结果表明,MetaFood3D 在食物分量估计、合成饮食场景模拟和 3D 食物生成等任务中具备强大能力。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.kler.cn/a/612631.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!