AIDD-人工智能药物设计-知识引导图学习赋能表型与靶点融合的创新药物发现
Adv. Sci. | 知识引导图学习赋能表型与靶点融合的创新药物发现
本文介绍了浙江大学药学院侯廷军和谢昌谕团队、浙江大学控制科学与工程学院贺诗波团队和碳硅智慧联合发表的一篇论文。该研究提出了知识引导药物关系预测器(KGDRP),一种有效整合多模态生物医药数据的图表示学习方法。KGDRP通过异质图(HG)结构,融合了生物信息网络、基因表达数据和化学分子结构序列等多种数据。在真实筛选场景中,KGDRP在药物反应预测性能上较以往方法提高了12%。KGDRP生成的知识驱动的表征使药物靶标优先排序能力提高了26%。在COVID-19的零样本评估中,KGDRP在识别潜在药物方面表现出显著更高的成功率。

研究背景
在现代药物研发中,表型驱动药物发现和靶点驱动药物发现是两种核心策略。表型驱动的药物发现通过评估药物对细胞或动物模型生理和病理表型的综合影响来筛选候选化合物,而靶点驱动的药物发现则依赖于对特定分子靶点的作用机制、结合特性及信号通路调控的深入研究,以筛选能够特异性调控靶点功能的药物。然而,尽管表型驱动药物发现在发现新型疗法方面表现出色,其缺乏对药物作用机制的解释能力,而靶点驱动的药物发现策略则受限于对已知靶点的依赖,使得许多潜在疗法难以被挖掘。
近年来,研究表明,绝大多数FDA批准的“first class”药物仍是通过表型筛选发现的,尤其在癌症等复杂疾病领域,表型驱动药物发现的重要性日益凸显。然而,如何融合表型驱动的药物发现数据和靶点驱动的药物发现数据,以充分利用两者的优势,仍是药物研发领域的一大挑战。该研究提出了一种知识引导的图学习方法,通过生物医药异构图谱(BioHG)整合多模态数据,打破表型数据与靶点数据之间的壁垒,加速药物发现。
研究方法
BioHG构建
该研究通过BioHG融合表型和靶点数据,重点描述药物、蛋白质和细胞系之间的相互作用,节点和边的选择由任务相关性和数据可用性驱动。BioHG架构包括药物反应数据(捕捉药物与细胞的关系)、药物靶标数据(描述药物与蛋白质的相互作用)和细胞系的RNA表达谱(代表蛋白质与细胞系的关系)。然而,单靠这三类关系数据推断蛋白质的生物学功能,尤其在解码药物机制时,仍然具有挑战性。为此,BioHG整合了UniProt数据库中的蛋白质-蛋白质相互作用(PPI)信息,增强了蛋白质功能表征并提升了网络连接性。此外,BioHG还结合了UniProt的基因本体(GO)数据和Reactome的通路数据,丰富了基础和高层次的生物学信息。
在确定数据源后,BioHG对边进行了特殊设计:首先,药物与细胞系之间不直接连接,迫使KGDRP通过蛋白质学习药物反应数据,从而更全面地利用网络信息;其次,关于蛋白质与细胞系的关系,BioHG通过选择表达值高于每个细胞系均值的蛋白质来建立蛋白质-细胞系关系。通过这种方式,转录组数据和生物学知识在图结构中得以互联。这些边的权重用于训练样本生成,但在图消息传递中并不使用。
KGDRP架构
为了促进更广泛化学分子表型筛选,KGDRP引入了一种线性函数,将化学分子的结构信息转化为生物学表示。为有效融合先验生物学知识,KGDRP不仅依赖于药物-细胞反应数据,还扩展了三个额外的预测器:RNA表达预测器、药物-靶标相互作用(DTI)预测器和生物过程预测器。这些辅助预测器使KGDRP能够通过同时学习多个任务,捕捉不同生物网络中的固有关联性和依赖关系。
在药物反应预测任务中,KGDRP将任务从反应性的数值预测(回归)转变为数值比较(分类)任务。此任务转化非常关键,因为它使得模型能够专注于区分药物之间的相对差异,而非预测绝对的反应值。此举降低了模型对特定实验数据的依赖,而这些数据往往在质量和可用性上有较大波动,增强了模型的鲁棒性。同时,通过利用比较数据,模型的预测性能得以提升,因为比较数据通常更可靠且不易过拟合。这一策略同样适用于蛋白质与肿瘤细胞系之间的关系,确保模型能够在不同生物学背景下保持较好的泛化能力。总而言之,在KGDRP中,BioHG作为包含生物医学数据的异质图结构,而RNA表达预测器、DTI预测器和生物过程预测器等辅助任务则旨在增强模型从BioHG中学习有意义表示的能力。
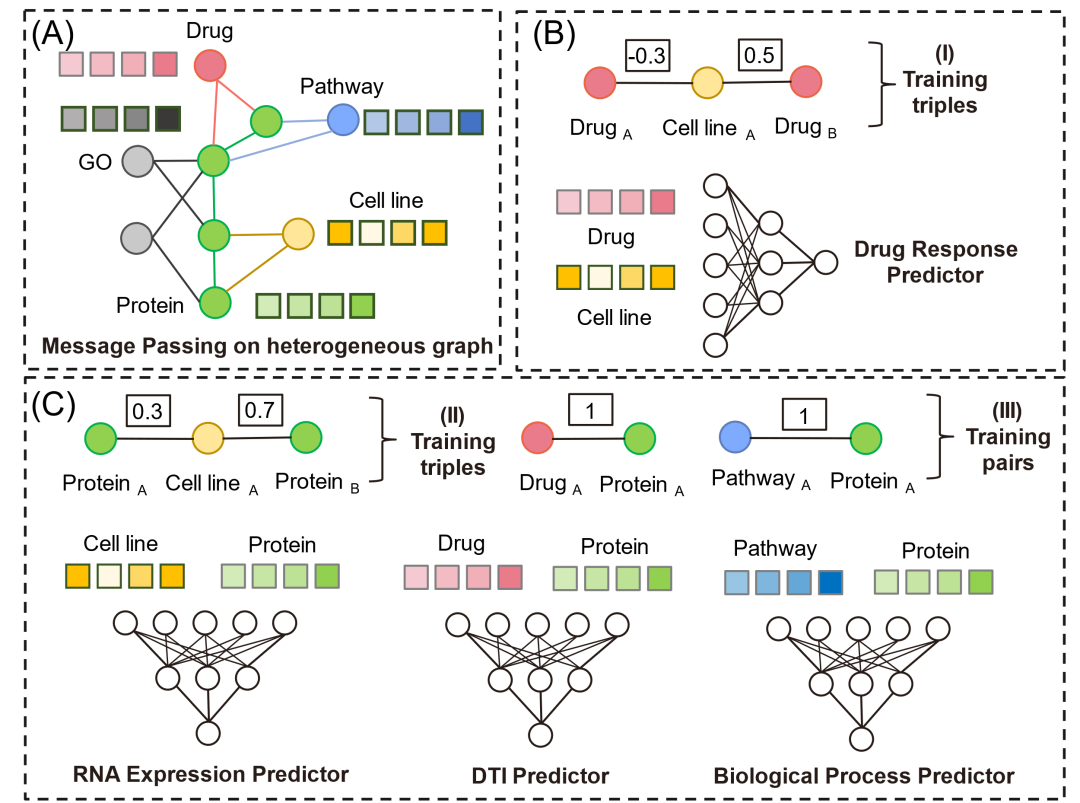
图 1. KGDRP架构示意图。(A) BioHG异构消息传递。(B) 训练样本生成和药物反应预测:药物反应性预测任务被定义为反应比较任务,而非值拟合任务。 © 三个辅助预测器:细胞系的RNA表达预测、药物-靶标相互作用预测和蛋白质-通路关联预测。
研究结果
细胞系药物反应性预测
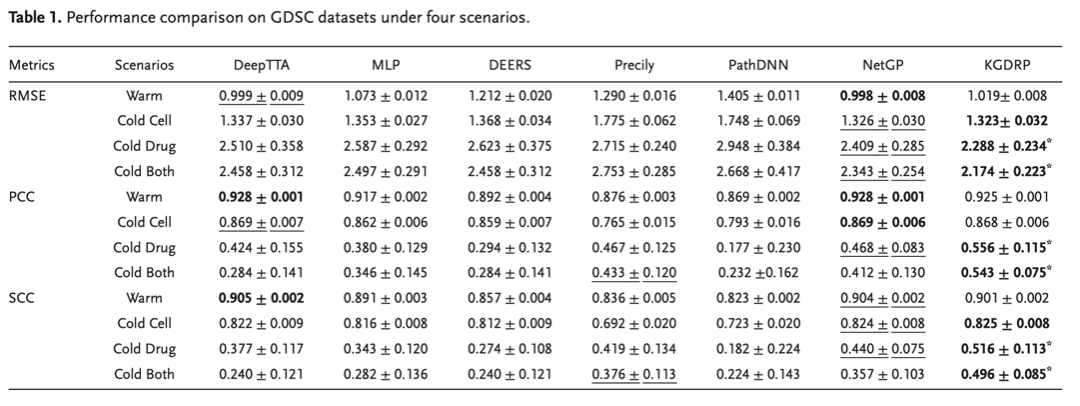
为评估KGDRP的性能,研究团队将KGDRP与六种先进药物反应预测方法在GDSC数据集上的表现进行了比较。药物反应预测模型分为三类:深度学习模型(如DeepTTA和MLP),主要利用基因表达谱和药物化学结构;知识引导模型(如DEERS、Precily和PathDNN),结合生物医学信息以增强模型可解释性和泛化能力;基于网络的模型(如NetGP),通过网络传播利用生物学知识(如PPI和DTI)。比较场景包括热启动(warm)、细胞系冷启动(cold cell)、药物冷启动(cold drug)和细胞系药物冷启动(cold both)场景。在cold both场景中,KGDRP的性能显著提升(SCC提升12%),表明其在利用生物医学信息改进表型筛选方面的有效性。研究还分析了不同生物医学图谱对预测性能的影响,结果表明,KGDRP中构建的图谱优于其他BioKG,证明了数据质量优先于数量,能够提供更具生物学意义和计算效率的模型。
PDTX药物反应性预测
该研究探索了将基于细胞系训练的药物反应模型转移到临床前疾病模型中的潜力。患者源性肿瘤异种移植(PDTX)已成为癌症研究的重要工具,能够弥补传统临床前模型与临床应用之间的差距。PDTX模型通过将患者来源的肿瘤组织移植到免疫缺陷小鼠中,保留了人类疾病的关键特征。研究评估了这些模型的可转移性,使用了来自Project Biobank的乳腺癌PDTX样本。外部测试数据集包含1,595个药物反应数据点,涉及20个PDTX乳腺癌模型和101种药物。在评估每个PDTX模型药物敏感性的场景中(图二),KGDRP的表现优于其他模型,平均皮尔逊相关系数(PCC)为32.9%,斯皮尔曼等级相关系数(SCC)为36.4%。与DeepTTA相比,KGDRP在11个PDTX模型中表现提升超过10%。
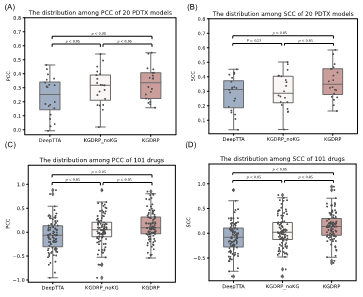
图 2. PDTX药物反应性预测结果。
药物靶点预测
该研究构建了一个针对每种药物的蛋白靶标数据集,以评估靶标优先排序的性能。数据集来自PubChem,包含9,141个正向药物-靶标相互作用(DTI)对,独立于BioHG中的DTI数据集。训练集和验证集通过随机划分BioHG中的DTI及采样的负向DTI数据生成。评估数据集中的负向DTI对考虑了两种场景:一是限制靶标为已知的DTI蛋白质,二是考虑所有已整理的蛋白质作为候选靶标。在靶标优先排序评估中,首先计算涉及所有药物和人类蛋白的DTI对的分数。为比较模型,重点关注训练数据类型和表示算法。研究考虑了两种方法:(1) 基于描述符的方法,如MLP,它依赖于预计算的药物(Morgan Fingerprint)和蛋白质(ProteinBERT嵌入)表示;(2) 基于序列的方法,如TransformerCPI和DrugBAN,通过端到端模型训练直接学习药物和蛋白质的表示。由于部分通过PDD方法识别的药物在BioHG中没有连接,研究排除了基于BioHG的方法作为基准模型。最终,选择MLP、TransformerCPI和DrugBAN作为基准模型。此外,研究还评估了去除药物反应数据的KGDRP变体(KGDRP_nop),以评估表型数据对KGDRP的影响。
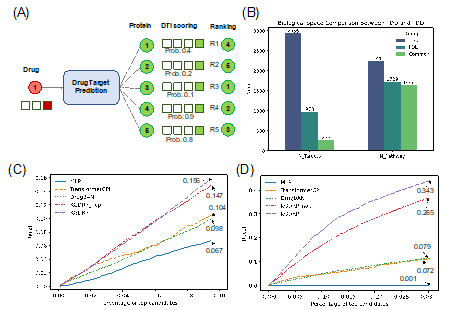
图 3. 药物靶点预测结果。
在药物再利用场景中(图三C),KGDRP在前10%的候选靶点中取得了最佳召回率0.156;在新型治疗靶标发现场景中(图三D),KGDRP在前3%的候选靶点中取得了最佳召回率0.343,比KGDRP_nop提高了8%。这些结果表明,表型数据的整合显著提升了靶点发现的效果。与基于描述符的MLP和基于序列的TransformerCPI与DrugBAN相比,KGDRP在这两个场景中均表现出显著改进。例如,在药物再利用场景中,KGDRP超越了最好的基于序列的方法TransformerCPI,提升了5%;在靶点发现场景中,KGDRP超越了最好的基于序列的方法DrugBAN,提升了26%。这一结果进一步验证了知识引导的DTI预测方法在药物靶点发现中的优势。
药物表型筛选
该研究利用GDSC数据集训练药物反应预测器,对四个肺部样本(包括两种健康样本和两种SARS-CoV-2感染样本)进行了药物重定位实验。基于KGDRP和BioHG的表达谱,研究使用MLP模型预测了7070种药物的反应得分,并筛选出在SARS-CoV-2感染样本中得分较高、健康样本中得分较低的药物。与MLP和DeepTTA方法相比,KGDRP筛选出29种潜在药物,其中10种(34.5%)得到了文献和数据库的支持证据,而MLP和DeepTTA的成功验证率分别为18.8%(6/32)和13.8%(4/29)。这些结果表明,KGDRP在表型药物筛选中表现出显著更高的成功率,证明了其利用BioHG的有效性。
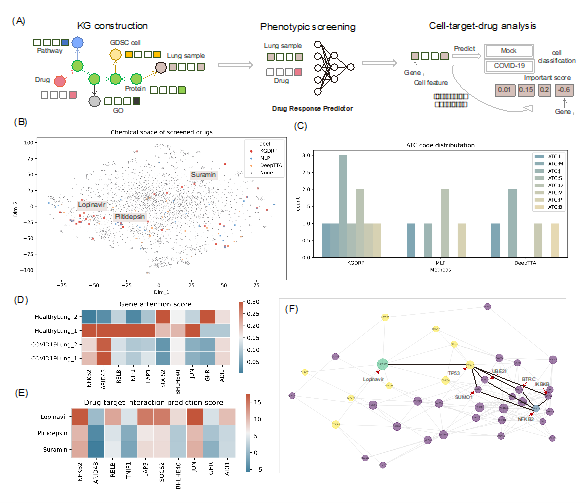
图4. 药物表型筛选结果。
参考资料
Ye, Q., Zeng, Y., Jiang, L., Kang, Y., Pan, P., Chen, J., Deng, Y., Zhao, H., He, S., Hou, T. and Hsieh, C.Y., 2025. A Knowledge‐Guided Graph Learning Approach Bridging Phenotype‐and Target‐Based Drug Discovery. Advanced Science, p.2412402.