前端一些你不了解的知识点?
微前端?微前端的框架?
什么是微前端
微前端是一种将Web应用由单一的单体应用转变为多个小型前端应用聚合为一的手段。它借鉴了微服务的架构理念,将微服务的概念扩展到了前端。具体来说,微前端将一个大型的前端应用拆分成多个模块,每个模块可以由不同的团队进行管理,并可以自主选择框架,同时每个模块有自己的仓库,可以独立部署上线。也就是说,没有技术栈的限制。比如一个后台用的react技术栈,一个用的是vue技术栈。两个项目呢也可以很好的嵌套。这也是微前端的优势。独立部署,可以将一个巨石应用分成多个模块。
微前端框架:
MicroApp(京东)
基于类WebComponent渲染,从组件化的思维实现微前端,低成本接入,不需要像其他一些框架(如single-spa和qiankun)要求子应用修改渲染逻辑并暴露出方法,也不需要修改webpack配置。在人手不够的情况下,容易上手,节省了学习的成本。当然还有很多微前端框架。
Qiankun(乾坤)
-
核心特点
- 基于Single-SPA二次封装,支持React、Vue、Angular等多技术栈共存
- 提供沙箱隔离(JS/CSS)和资源预加载机制,优化大型应用性能
- 阿里系生态支持,文档完善,企业级应用验证成熟
-
适用场景
- 需要多团队协作、技术栈混合的复杂项目(如中后台系统)
- 对沙箱隔离和路由管理有较高要求的场景
-
沙箱隔离:将代码的运行环境与全局作用域或外部资源物理或逻辑隔离的技术,其核心目标是防止不同代码模块之间的相互干扰,例如样式冲突、全局变量污染或恶意操作。
Single-SPA
- 核心特点
- 微前端底层框架,提供灵活的生命周期管理和路由控制
- 无内置沙箱和样式隔离,需开发者自行实现或借助插件
- 适用场景
- 需要高度自定义架构的项目(如插件化平台)
- 技术团队具备较强微前端开发经验
Garfish(字节跳动)
- 核心特点
- 高效的资源加载机制,支持跨框架应用并行加载
- 提供统一状态管理和插件扩展能力
- 适用场景
- 需要高性能资源管理的超大型应用(如C端流量型产品)
为什么会跨域,什么是同源,怎么解决跨域问题?
为什么会谈到跨域问题呢?
-
开发环境跨域:在前后端分离项目,前端在一个域名,后端API在另一个域名,请求后端,必然会发生跨域无法获取到资源。
-
在具体的业务场景中,电商平台跨域:
-
前端部署在
https://shop.example.com -
订单支付接口部署在
https://api.payment.com -
用户点击支付时,前端调用支付接口触发跨域,需服务端配置
-
那为什么会跨域呢?是受浏览器同源策略的影响。
什么是同源策略? 同源策略(Same-Origin Policy,SOP)是浏览器为了保障用户信息安全而实施的一种安全策略。它限制了一个源(即协议、域名和端口的组合)的文档或脚本如何与另一个源的资源进行交互。
什么是同源? 同源是协议名、域名和端口号三者都相同,如http与https就不同源。
怎么解决跨域问题?
- 「JSONP」:通过动态创建
<script>标签来实现跨域请求。 - 「CORS(Cross-Origin Resource Sharing)」 :通过服务器设置特定的HTTP头部来允许跨域请求。
- 「PostMessage API」:允许不同源的窗口之间进行安全的消息传递。
- 「代理服务器」:通过在同源服务器上设置代理来转发跨域请求。
option请求是什么?什么时候会发生预检?
optiosn请求也叫预检请求。通常发生在跨域的时候。当浏览器需要发送一个非简单请求(complex request)时,会在实际请求之前发送一个OPTIONS请求,以确认服务器是否允许该请求。这种机制有助于防止潜在的安全风险和意外的数据修改。
什么时候会发生预检请求呢? 首先肯定是需要跨域。OPTIONS预检请求是CORS机制的一部分,用于确保跨域请求的安全性和有效性。其次在浏览器发生非简单请求的时候。什么是非简单请求呢?
根据CORS规范,非简单请求是指那些不符合以下条件的请求:
- 请求方法是
GET、HEAD或POST。 - 请求头信息只包含以下四个字段:
Accept、Accept-Language、Content-Language、Content-Type(仅限于application/x-www-form-urlencoded、multipart/form-data、text/plain)。 - 请求中没有使用
ReadableStream对象。
预检请求使用的请求方法是OPTIONS,表示这个请求是来询问的。头信息中的关键字段有:
-
Orign:表示请求来自哪个源段。
-
Access-Control-Request-Method:该字段是必须的,用来列出浏览器的CORS请求会用到哪些HTTP方法。
-
Access-Control-Request-Headers: 该字段是一个逗号分隔的字符串,指定浏览器CORS请求会额外发送的头信息字段。
服务器在收到浏览器的预检请求之后,会根据头信息的三个字段来进行判断,如果返回的头信息在中有Access-Control-Allow-Origin这个字段就是允许跨域请求,如果没有,就是不同意这个预检请求,就会报错。
服务器回应的CORS的字段如下:
Access-Control-Allow-Origin: http://api.bob.com // 允许跨域的源地址
Access-Control-Allow-Methods: GET, POST, PUT // 服务器支持的所有跨域请求的方法
Access-Control-Allow-Headers: X-Custom-Header // 服务器支持的所有头信息字段
Access-Control-Allow-Credentials: true // 表示是否允许发送Cookie
Access-Control-Max-Age: 1728000 // 用来指定本次预检请求的有效期,单位为秒
OPTIONS请求次数过多就会损耗页面加载的性能,降低用户体验度。所以尽量要减少OPTIONS请求次数,可以后端在请求的返回头部添加:Access-Control-Max-Age:number。它表示预检请求的返回结果可以被缓存多久,单位是秒。
浏览器的协商缓存和强缓存,如何不发生浏览器缓存?
-
强缓存:输入某个网址,浏览器在缓存有效期内直接使用缓存,不向服务器发起请求。
- 启用强缓存可以设置expires:具体的过期时间或者设置**cache-control**:max-age=3600,过期秒数时间。
-
协商缓存:浏览器在缓存过期后,会向服务器发送请求,验证缓存数据是否过期,如果资源没有发生修改,则返回一个 304 状态,让浏览器使用本地的缓存。如果资源发生了修改,则返回修改后的资源。
- 启动协商缓存设置请求头
If-Modified-Since: Last-Modified,Last-Modefied:资源最后一次修改的时间或者If-None-Match:Etag,Etag:资源的唯一标识符
- 启动协商缓存设置请求头
不发生浏览器缓存:设置cache-control:no-store,或者将Last-Modefied和Etag设置为无效值或者不设置。
Cache-Control里面有哪些属性?
public:设置了该字段值的资源表示可以被任何对象(包括:发送请求的客户端、代理服务器等等)缓存。这个字段值不常用,一般还是使用max-age=来精确控制;private:设置了该字段值的资源只能被用户浏览器缓存,不允许任何代理服务器缓存。在实际开发当中,对于一些含有用户信息的HTML,通常都要设置这个字段值,避免代理服务器(CDN)缓存;no-cache:设置了该字段需要先和服务端确认返回的资源是否发生了变化,如果资源未发生变化,则直接使用缓存好的资源;no-store:设置了该字段表示禁止任何缓存,每次都会向服务端发起新的请求,拉取最新的资源;max-age=:设置缓存的最大有效期,单位为秒;s-maxage=:优先级高于max-age=,仅适用于共享缓存(CDN),优先级高于max-age或者Expires头;max-stale[=]:设置了该字段表明客户端愿意接收已经过期的资源,但是不能超过给定的时间限制。
webpack和vite的区别?
-
「构建速度」:
-
- Webpack:作为一个通用的构建工具,Webpack需要对整个项目进行分析和构建,因此在启动和构建时间上可能比较慢,尤其是对于大型项目和复杂的构建配置而言。
- Vite:采用了一种新颖的开发模式,利用了浏览器自身的原生ES模块支持,将构建的过程延迟到了开发环境的运行时。这种分离的方式使得Vite具有非常快的冷启动速度和即时热更新。Vite底层基于esbuild(Go语言实现),因为Go语言的操作是纳秒级别,而JavaScript是以毫秒计数,所以Vite比用JavaScript编写的打包器快10-100倍2。
-
「开发模式」:
-
- Webpack:使用传统的开发模式,在开发阶段需要将所有的代码打包成一个或多个bundle,然后在浏览器中进行动态加载。这种模式需要使用热加载或者修改文件后手动刷新浏览器才能看到更新的效果。
- Vite:采用了ES模块原生的开发模式,在开发阶段不需要将所有代码打包成一个bundle,而是以原生ES模块的方式直接在浏览器中加载和运行文件。这个特性使得Vite能够实现更快的冷启动和热更新,修改文件后无需刷新浏览器即可立即看到更新的效果。
-
「生产构建」:
-
- Webpack:在生产环境下会将所有代码打包成一个或多个bundle,以便进行优化、压缩和代码拆分等操作,以提高性能和加载速度。
- Vite:在生产环境下仍然保持了开发时的原生ES模块导入方式,不会将所有代码打包成一个bundle。相反,它会保留第三方依赖的单独引用,以便在浏览器端实现更快的加载速度。
-
「插件生态系统」:
-
- Webpack:拥有广泛的插件生态系统,有大量的插件可以满足不同的构建需求,并能与其他工具和框架良好地集成。
- Vite:作为一个相对较新的项目,其插件生态系统相对较小,但依然可以满足常见的构建需求,并且在逐渐增长。
get请求和post请求的区别?
get请求和post请求的区别。
-
语义哦。get就是获取,post就是发送。get就是获取资源的请求,post就是设计来发送资源的请求,当然这只是语义方面。实际上是都可以用的。
-
看传递的参数。get通过url携带参数,url?后面带参数&连接参数如:request.get(‘https:xxxx?name=xiaomin&age=18’),post请求是通过请求体携带参数。所以get请求的参数受url地址栏的限制,而post请求则没有。且参数直接在地址栏不安全,所以相对来说post请求会安全一点。
-
从跨域上说,部分get是不会发生跨域的,如script标签的src发送get请求不会发生跨域,所以可以用jsonp来解决跨域问题,但是这需要前后端沟通。
有哪些方式可以发送get请求?
其实这道题是问你ajax请求的方式有哪些?
- 使用XMLHttpRequest对象
function sendGetRequest(url, callback) {
var xhr = new XMLHttpRequest();
xhr.open('GET', url, true);
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
callback(xhr.responseText);
}
};
xhr.send();
}
- 使用Fetch API
Fetch API是现代浏览器提供的一种更现代化的、基于Promise的HTTP请求方式。
fetch('https://api.example.com/data')
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
-
使用axios等第三方库
-
使用Location对象
在某些情况下,你可以使用Location对象来发送GET请求。这种方式通常用于页面跳转。
function pageGo() {
var tp = ${pb.tp}; // 获取总页数
var page = document.getElementById('page').value; // 获取页码
if (Number(page) > 0 && Number(page) <= tp) {
var path = location.pathname + '?pc=' + page;
location.assign(path); // 提交URL
}
}
发布新版本问题
某次发布,同时改了页面结构和样式,也更新了静态资源对应的 url 地址,现在要发布代码上线,我们是先上线页面,还是先上线静态资源?
采用非覆盖式发布。
- 覆盖式发布(用待发布资源覆盖已发布资源)
- 非覆盖式发布(采用 hash)
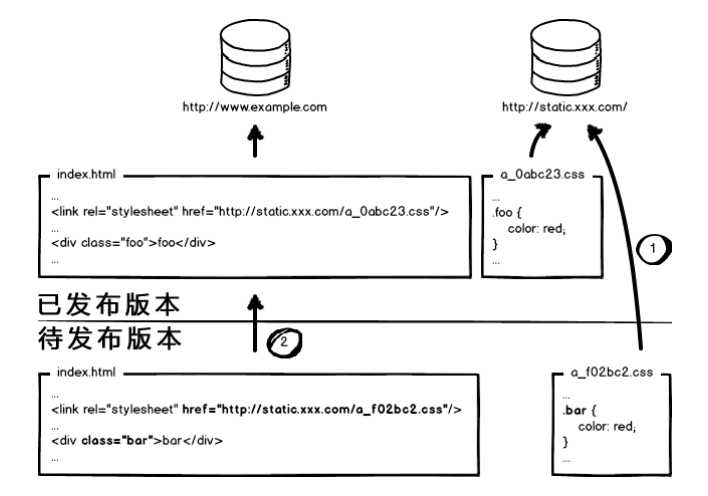 看上图,用文件的摘要信息来对资源文件进行重命名,把摘要信息放到资源文件发布路径中,这样,内容有修改的资源就变成了一个新的文件发布到线上,不会覆盖已有的资源文件。上线过程中,先全量部署静态资源,再灰度部署页面,整个问题就比较完美的解决了。
看上图,用文件的摘要信息来对资源文件进行重命名,把摘要信息放到资源文件发布路径中,这样,内容有修改的资源就变成了一个新的文件发布到线上,不会覆盖已有的资源文件。上线过程中,先全量部署静态资源,再灰度部署页面,整个问题就比较完美的解决了。 - a_5678.css 新资源
- a_1234.css 旧资源
这种情况下,则不会出现这个问题,旧版本的页面依然请求了旧的资源,新版本的页面请求新的资源。
浏览器资源缓存位置–内存和硬盘的区别
-
memory cache: 它是将资源文件缓存到内存中。等下次请求访问的时候不需要重新下载资源,而是直接从内存中读取数据。
-
disk cache: 它是将资源文件缓存到硬盘中。等下次请求的时候它是直接从硬盘中读取。
-
区别
-
memory cache(内存缓存)退出进程时数据会被清除,而disk cache(硬盘缓存)退出进程时数据不会被清除。内存读取比硬盘中读取的速度更快。但是我们也不能把所有数据放在内存中缓存的,因为内存也是有限的。
-
memory cache(内存缓存)一般会将脚本、字体、图片会存储到内存缓存中。disk cache(硬盘缓存) 一般非脚本会存放在硬盘中,比如css这些。
-
缓存读取的原理:先从内存中查找对应的缓存,如果内存中能找到就读取对应的缓存,否则的话就从硬盘中查找对应的缓存,如果有就读取,否则的话,就重新网络请求。
v8引擎中的常量池
v8引擎的内存区主要可以分为以下几类:栈区、堆区、常量区、函数定义区、函数缓存区,而后三者也可以认为是有特殊用途的堆区,这三块内存区完全由引擎控制,我们无法直接操作。
1.什么是常量池(常量区)
顾名思义,常量区就是用来存储常量的。在JavaScript中(基于ES5),总共存在三类常量,分别是基本数据类型中的Number、String和Boolean。也就是说这三类值都是存储在常量区中的。如:
class BasicPerson {
constructor(name, nickname) {
this.name = name
this.nickname = nickname || name
}
}
a = new BasicPerson('D')
class MyBelongings {
constructor(product) {
this.product = product
this.user = 'D'
}
}
b = new MyBelongings('D')

image.png
查看他们内存中的地址后,我们发现了,所有为D字面量的地址都是一样的
有没有一种可能,我们去计算 a.name === a.nickname结果为true的原因,归根结底就是他们的地址是完全一致的?(此处为疑问,并不是结论)
2.所有的字符串/数字都是存储于常量池中吗?
class Person {
constructor(a, b) {
this.name = a + b
}
}
a = new Person('di', 'ming')
class Person2 {
constructor(name) {
this.name = name
}
}
b = new Person2('diming')
再次查看他们的地址,我们发现,虽然结果都是a.name和b.name的结果都是diming。
但是他们的地址是不一样的。这是因为:在 V8 引擎中,虽然字符串和基础类型的值都可以存放在常量池中,但是否是在常量池中,依然取决于它们的创建方式和使用情况
当使用字面量定义字符串和基础类型的值时,V8 引擎会将它们存放在常量池中,以便在后续的代码中重复使用。
例如,以下代码中的字符串和基础类型的值都会被存放在常量池中:
const str = 'hello world';
const num = 42;
当使用构造函数或函数返回值创建字符串和基础类型的值时,V8 引擎会将它们存放在堆内存中,而不是常量池中。因为构造函数和函数返回的值是在运行时动态创建的,无法在编译时确定。
例如,以下代码中的字符串和基础类型的值会被存放在堆内存中:
const str = new String('hello world');
const num = new Number(42);
需要注意的是,即使是使用字面量定义的字符串和基础类型的值,如果它们在后续的代码中被修改,它们也会从常量池中移动到堆内存中。因此,为了避免性能问题,应尽可能使用字面量定义字符串和基础类型的值,并避免在运行时动态创建它们。
3.为什么通过字面量赋值,与通过普通二元运算表达式计算出来同样的字符串结果,却存储在不同的内存地址中?
这就要从v8解析字符串开始说起
- 抽象语法树内部有严格的分类,比如继承于AstNode的语句Statement、表达式Expression、声明Declaration等等,当判定对应词法的类型,会有一个工厂类专门生成对应类型的描述类。
- v8内部有一个名为string_table_的hashmap缓存了所有字符串,转换抽象语法树时,每遇到一个字符串,会根据其特征换算为一个hash值,插入到hashmap中。在之后如果遇到了hash值一致的字符串,会优先从里面取出来进行比对,一致的话就不会生成新字符串类。
- 抽象语法树解析的判定优先级依次为Declaration(let a = 1)、Statement(if(true) {})、Expression(“a” + “b”),其中还有一个非常特殊的语法类型是goto,即label语法,我只能说尽量不要用这个东西,v8为其专门写了特殊的解析,非常复杂。
4.每一个大类型(例如Statement)也会有非常详细的子类型,比如if、while、return等等,当前解析词法不匹配对应类型,会进行降级解析。
- 缓存字符串时,会分为三种情况处理,长度为1的单字符、长度为2-10的且值小于2^32 - 2的纯数字字符串、其他字符串,仅仅影响生成hash值方式,纯数字字符串会转换成数值再计算hash。
案例中,单个词法’diming’属于原始字符串,由AstRawString类进行管理。而整个待编译字符串"‘di’ + ’ ming’"中,加号左右的空格会被忽略,解析后分为三段,即字符串、加号、字符串。由于这段代码以字符串开头,被判定为一个字面量(literal),在依次解析后发现了加号与另外一个字符串后结束,所以被判定是一个’普通二元运算表达式’,在expression中的标记分别是normal、binary operation、literal。
4. v8引擎中的常量池,会预置一些字面量吗?
在 V8 引擎中,常量池会预置一些字面量,这些字面量通常是一些经常被使用的字符串或数字。预置这些字面量可以提高程序的性能,因为它们不需要在运行时被创建,也不需要在堆上进行分配和销毁。而是在引擎启动时就创建好了,存储在常量池中,程序运行时直接使用这些字面量的引用即可。
V8 引擎中预置的字面量包括了一些标准的 JavaScript 内置对象,例如字符串 “undefined”、“null”、“true”、“false” 等,以及一些数值常量,例如数字 0、1、-1、NaN 等。
需要注意的是,预置的字面量只是一些常用的值,如果程序中使用了不在常量池中的字面量,则 V8 引擎会在运行时创建新的对象,将其存储在堆上,并将引用返回给程序。
JS引擎
JavaScript 是现代 Web 开发的基石,背后的 JavaScript 引擎在很大程度上决定了应用的性能和用户体验。当前主流的 JavaScript 引擎,包括 V8、SpiderMonkey、JavaScriptCore、Chakra、Rhino 和 JerryScript。
V8引擎
V8 是 Google 开发的开源 JavaScript 引擎,首次发布于 2008 年,广泛用于 Google Chrome 和 Node.js。它的设计目标是提供高性能和高效的内存管理。
特点
- 即时编译(JIT):V8 使用即时编译技术将 JavaScript 源代码编译为本地机器码,以提高执行速度。它使用了两层 JIT 编译器:Full-Codegen 和 Crankshaft,后者通过多种优化策略进一步提升性能。
- 垃圾回收:V8 采用了高效的垃圾回收算法,如并行标记清除和增量标记清除,以优化内存管理和提高响应速度。V8 的垃圾回收主要采用分代收集垃圾回收(Generational Garbage Collection),并结合标记-清除(Mark-Sweep)、**标记-整理(Mark-Compact)和增量标记(Incremental Marking)**等算法优化性能。
- 性能优化:V8 包含多种性能优化技术,包括内联缓存(Inline Caching)、隐藏类(Hidden Classes)和逃逸分析(Escape Analysis)。这些优化有助于减少函数调用开销和提升对象属性访问速度。
- 内存管理:对现代硬件架构进行优化,能够高效处理大内存应用。V8 引擎还使用精确内存管理和增量标记清除技术,以减少内存泄漏和提高内存利用率。
优势与应用
-
高性能:适用于高负载的 Web 应用和服务器端应用。例如,Node.js 使用 V8 引擎,可以处理高并发的 I/O 操作,广泛应用于实时聊天、流媒体等高性能服务器应用中。
广泛的社区支持:丰富的生态系统,特别是在 Node.js 环境中,提供了大量的模块和工具支持。Google Chrome 也因其高效的 V8 引擎而在浏览器市场中占据领先地位。 -
实际案例
Google Chrome:V8 引擎为 Chrome 浏览器提供了强大的 JavaScript 执行能力,使其在性能测试中表现出色。
Node.js:Node.js 使用 V8 引擎,通过事件驱动的非阻塞 I/O 模型,实现了高并发处理能力,适用于高性能 Web 服务器。
SpiderMonkey:灵活的 JavaScript 引擎
SpiderMonkey 是 Mozilla 开发的 JavaScript 引擎,首次发布于 1995 年,是第一个 JavaScript 引擎,主要用于 Firefox 浏览器。
特点
- JIT 编译:SpiderMonkey 包含多个 JIT 编译器:Baseline 编译器提供快速的初始编译,IonMonkey 编译器进行高级优化,WarpMonkey 编译器在最新版本中进一步提升了性能。
- 垃圾回收:采用精确垃圾回收(Exact GC)和分代垃圾回收(Generational GC)技术,能够有效地管理内存并提高性能。
- 多线程支持:对并发执行有较好的支持,包括 Web Workers 和 SharedArrayBuffer,使其能够高效处理多线程任务。
- 调试工具:与 Firefox 开发者工具高度集成,提供了强大的调试能力和性能分析工具,如 SpiderMonkey Shell 和 JIT Inspector。
优势与应用
- 高效的 JIT 和 GC:适用于复杂的 Web 应用,特别是在需要频繁执行动态脚本的场景中表现出色。
强大的调试工具:与 Firefox 开发者工具集成,使开发者能够方便地调试和优化 JavaScript 代码。 - 实际案例
Firefox:作为 Firefox 浏览器的核心引擎,SpiderMonkey 提供了快速的 JavaScript 执行和良好的用户体验。
PDF.js:Mozilla 开发的 PDF.js 使用 SpiderMonkey 解析和渲染 PDF 文件,展示了其在复杂任务中的性能和可靠性。
JavaScriptCore
Apple 开发的 JavaScript 引擎,广泛用于 Safari 和 WebKit 项目中,首次发布于 2002 年。
特点
- JIT 编译:JavaScriptCore 使用 Nitro 引擎进行即时编译,提供快速的 JavaScript 执行。采用两层 JIT:低层 JIT 提供基础编译,高层 JIT 进行高级优化。
- 垃圾回收:分代垃圾回收和并行标记清除算法提高了内存管理的效率。
- 优化技术:使用 B3(Bare Bones Backend)和 FTL(Fourth Tier LLVM)进行高级优化,通过 LLVM 编译框架进行多层次优化。
- 集成性:与苹果设备和操作系统有深度集成,特别是对 iOS 和 macOS 的优化,使其能够在苹果设备上提供卓越的性能。
优势与应用
- 苹果设备优化:在 iOS 和 macOS 上表现优异,能够充分利用硬件优势,提供流畅的用户体验。
安全性和隐私保护:提供额外的保护机制,确保用户数据的安全和隐私。 - 实际案例
Safari:作为 Safari 浏览器的核心引擎,JavaScriptCore 提供了高效的 JavaScript 执行,支持最新的 Web 标准和特性。
iOS 应用:许多 iOS 应用使用 WebView 加载网页内容,JavaScriptCore 提供了强大的 JavaScript 执行能力,确保应用的流畅运行。
JavaScript 引擎到底是干什么的?底层原理是什么?
JavaScript 引擎是负责执行 JavaScript 代码的软件组件。它读取、解析并运行你编写的 JavaScript 程序,将高级语言(即人类可读的代码)转换为计算机可以理解并执行的指令。每个现代浏览器和 Node.js 环境中都有一个内置的 JavaScript 引擎来处理网页上的交互逻辑和服务端脚本。
JavaScript 引擎的主要任务
-
词法分析(Lexical Analysis):首先,引擎会将你的代码分割成一个个有意义的符号或单元,这一步骤称为分词(Tokenization)。接着,这些符号会被组合成表达式和语句,形成抽象语法树(AST, Abstract Syntax Tree),这就是解析(Parsing)的过程。
-
解释与编译:接下来,JavaScript 引擎有两种主要的方式来执行代码:
- 解释器(Interpreter):逐行读取代码并立即执行。这种方式简单直接,但可能效率不高。
- 即时编译器(JIT Compiler, Just-In-Time Compiler):在运行时对频繁使用的代码片段进行优化编译,生成高效的机器码,从而提升性能。大多数现代 JavaScript 引擎都采用 JIT 技术。
-
垃圾回收(Garbage Collection):为了管理内存,JavaScript 引擎还需要自动追踪不再使用的对象,并适时释放它们占用的空间。这个过程叫做垃圾回收。
-
事件循环(Event Loop):由于 JavaScript 是单线程的,它使用事件循环机制来处理异步操作,如定时器、网络请求等。事件循环确保即使有长时间运行的任务,也不会阻塞整个程序的执行。
-
API 调用:除了执行 JavaScript 代码本身,引擎还提供了丰富的 API 来与宿主环境(如浏览器或 Node.js)交互,例如 DOM 操作、文件系统访问等。
底层原理
解释 vs 编译
- 解释器:当代码被执行时,解释器会一行一行地读取源代码,将其转换成中间表示形式(Intermediate Representation, IR),然后根据需要生成字节码或者直接执行。
- 即时编译器(JIT):JIT 编译器会在运行时识别出哪些部分的代码被多次调用或非常重要,然后把这些代码编译成更高效的本地机器码。这样做的好处是可以获得接近原生应用的速度,同时保持了 JavaScript 的灵活性。
垃圾回收
-
引用计数:一种简单的垃圾收集方法,通过跟踪每个对象有多少个其他对象指向它来决定是否应该释放该对象。但是这种方法容易导致循环引用的问题。
-
标记清除(Mark-and-Sweep):这是最常用的垃圾回收算法之一。它分为两个阶段:
- 标记:从一组根对象开始,递归遍历所有可达的对象,并给它们打上标记。
- 清除:遍历整个堆内存,移除那些没有被标记的对象(即不可达对象)。
事件循环
-
任务队列(Task Queue):存放宏任务(Macrotasks),比如点击事件、setTimeout 回调等。
-
微任务队列(Microtask Queue):存放微任务(Microtasks),例如 Promise 的回调函数。微任务会在每次事件循环迭代结束前执行,而宏任务则是在下一次迭代开始时执行。
-
执行流程:每次事件循环迭代时,先执行当前宏任务中的同步代码,之后处理所有可用的微任务,最后检查是否有新的宏任务加入队列。如果没有,则等待直到有新任务到来。
常见的 JavaScript 引擎
- V8 (Chrome 和 Node.js):由 Google 开发,以其高性能和强大的 JIT 编译能力著称。
- SpiderMonkey (Firefox):Mozilla 维护的引擎,支持多种优化技术以提高性能。
- Chakra (Edge, 已废弃), ChakraCore:微软开发的引擎,现已停止更新,被 V8 取代。
- JavaScriptCore (Safari):Apple 的引擎,同样集成了先进的 JIT 编译和其他性能增强特性。
总之,JavaScript 引擎是一个复杂的系统,它不仅需要高效地解析和执行代码,还要智能地管理内存和处理异步操作。随着技术的发展,各个引擎不断引入新的优化策略,使得 Web 应用越来越快、越来越强大。