WeakTr阅读笔记
WeakTr: Exploring Plain Vision Transformer for Weakly-supervised Semantic Segmentation
论文链接
代码链接
- 本文研究了用于弱监督语义分割(WSSS)的普通ViT的特性。
- 观察到不同的ViT注意头对不同的图像区域的关注:提出了一种基于权重的端到端估计注意头重要性的新方法,同时自适应融合自注意图,以获得具有更完整对象的高质量CAM结果
- 提出了一种基于vit的梯度剪裁解码器,用于在线再训练CAM结果
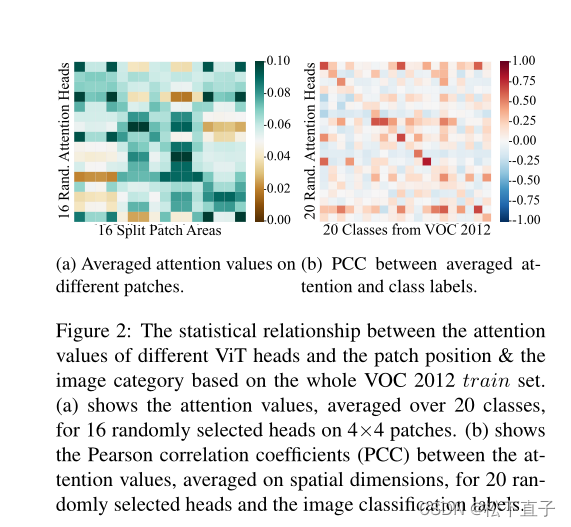
图a表示注意力图
图b表示类与类之间的皮特森相关系数
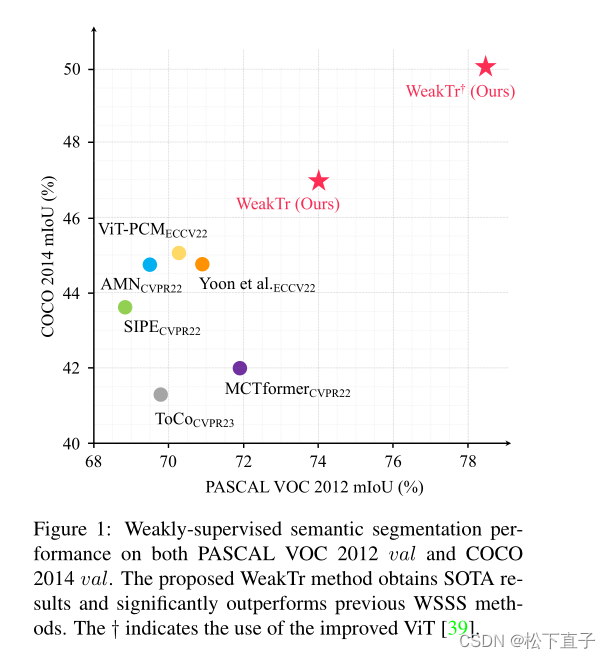
本文方法
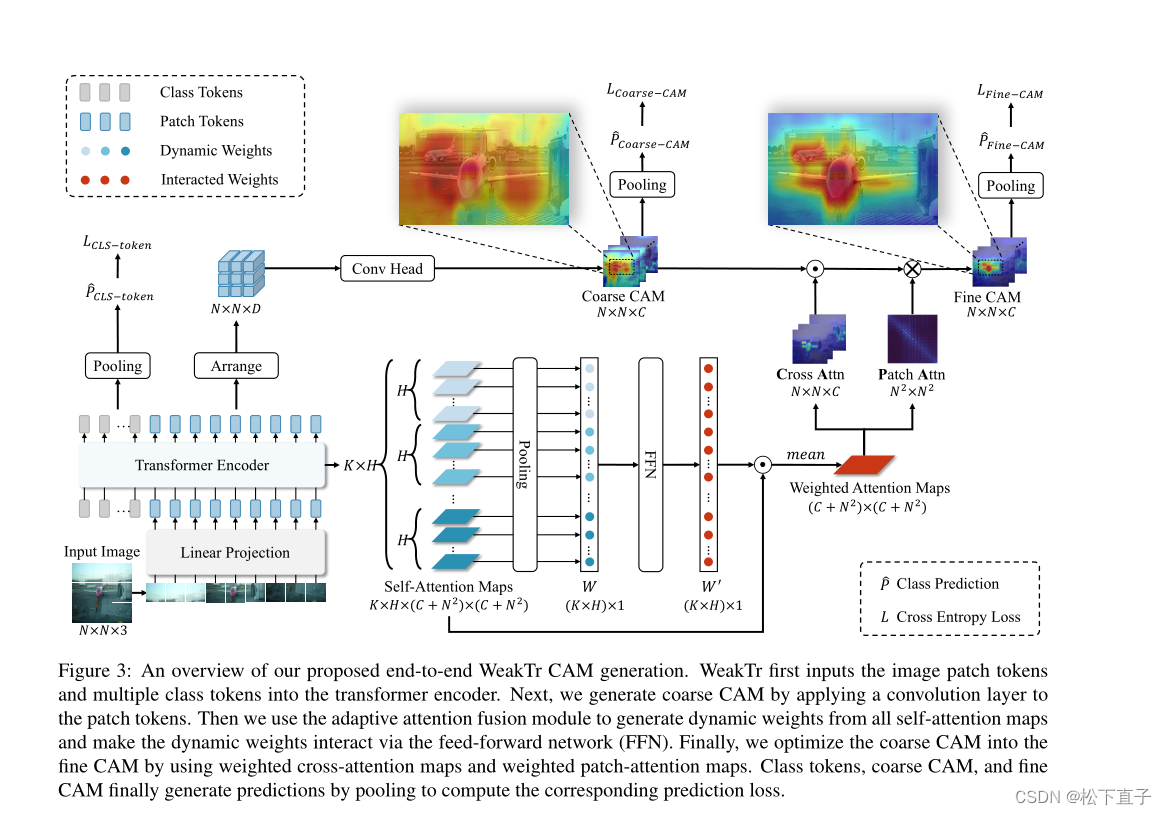
首先将图像patch token和多个class token输入到transformer编码器中
通过对patch token应用卷积层来生成粗CAM
使用自适应注意融合模块从所有自注意映射中生成动态权重,并通过前馈网络使动态权重相互作用。
最后,利用加权cross注意映射和加权patch注意映射,将粗CAM优化为精CAM。类token、粗CAM和细CAM最后通过池化生成预测,计算相应的预测损失。
详细看下面内容
Plain ViT Backbone
详细请看vit这篇论文
编码器内部由K个编码层组成。每一层由两个子层组成:多头自注意(MSA)和多层感知器(MLP)
Direct CAM Generation with Adaptive Attention Fusion
接下来,我们使用卷积层得到粗CAM∈R(N×N×C),如下所示:
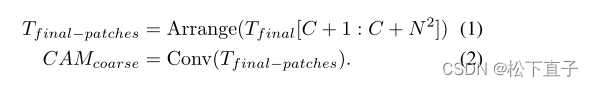
在得到粗CAM后,利用transformer编码器的自注意映射对粗CAM进行细化。
单个自注意图的形状为(C + n2)2,这使得我们可以得到C个class token对于n2个patch token的交叉注意map,以及n2个patch token相对于它们自身的patch attention map
考虑到vit编码器有K个编码层,每个编码层有H个注意头,我们可以得到交叉注意映射为CA∈R(K×H)×N×N×C, patch-注意映射为P A∈R(K×H)×N 2×N 2
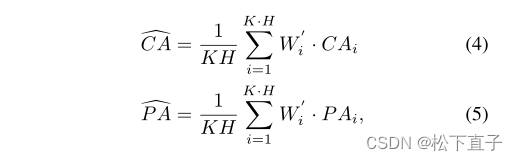
我们采用与MCTformer和TransCAM相同的方法将粗CAM、CA和PA结合起来:R代表reshape
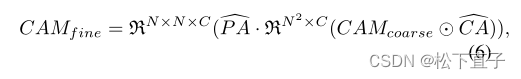
总损失:
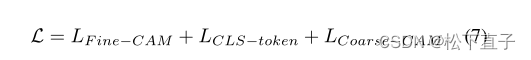
WeakTr Online Retraining with Gradient Clipping Decoder
对CAM进行再训练从而达到精调
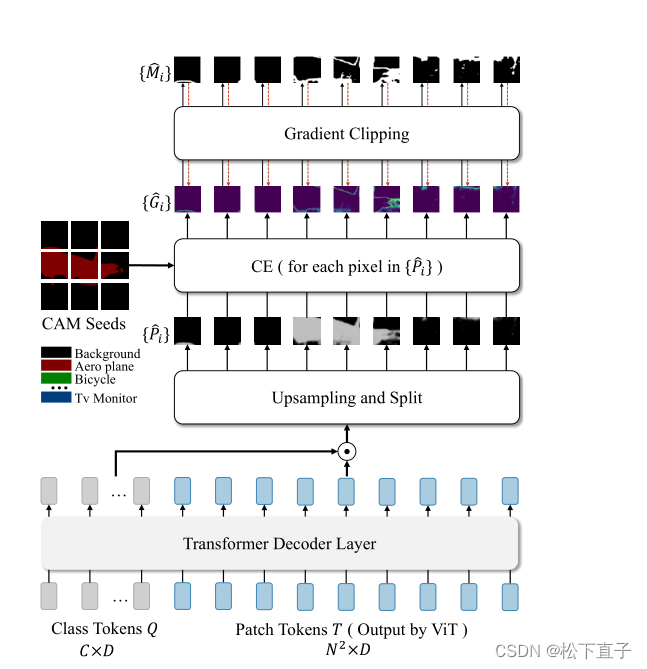
本文所提出的梯度剪切解码器的架构。梯度剪切解码器的输入由两部分组成:ViT编码器输出的class token和patch token。
在解码层操作之后,我们首先结合class token和patch token得到相应的patch预测。
接下来,我们对获得的预测进行上采样,并将预测分割为预测补丁{Pi}。然后利用CAM种子计算梯度patch{Gi}。最后,我们动态生成梯度剪切mask{Mi},并将梯度剪切mask与原始梯度图相乘。
请注意,在这个图中,我们只展示了梯度剪切解码器的结构。在训练过程中,ViT编码器和梯度剪切解码器一起更新。
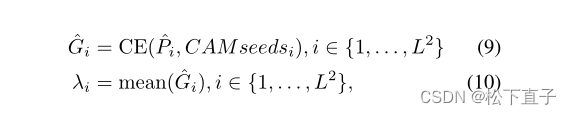
CE是为每个像素计算的交叉熵损失
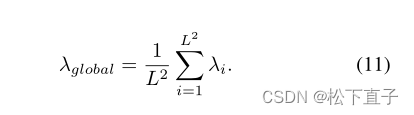
局部和全局梯度约束,实现对梯度较大的patch区域的丢弃:
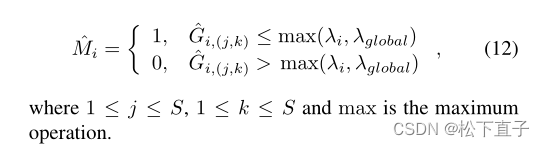
clip the gradient:
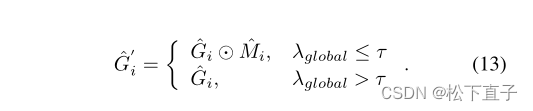
最后,得到了mask梯度patch,并反向传播它们的平均值。通过这样做,我们动态地选择具有较小梯度的区域作为自信的CAM区域,以优先学习分割网络。在推理过程中,应用条件随机场(CRF)来提高分割质量
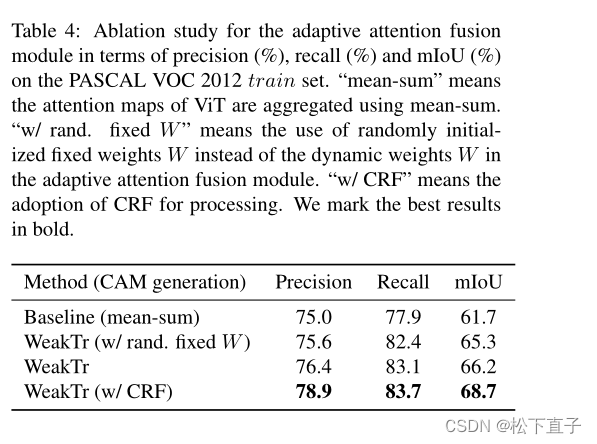
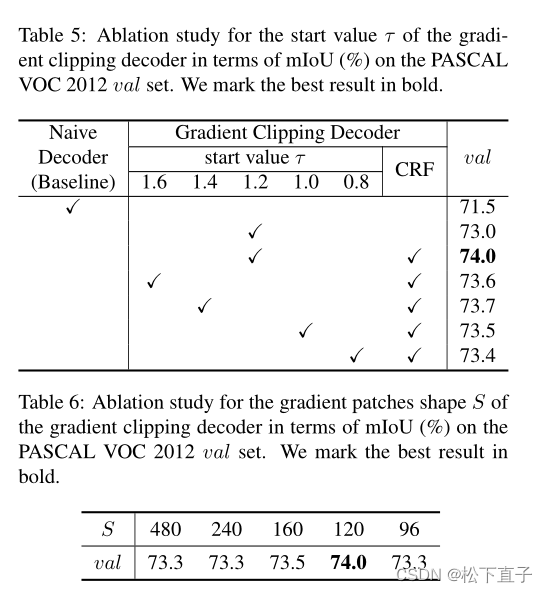
消融实验