前端性能优化之HTTP缓存
前端缓存
前端缓存可分为两大类:HTTP 缓存和浏览器缓存。
我们今天重点是 HTTP 缓存,下面这张图是前端缓存的一个大致知识点:

HTTP 缓存
首先解决困扰绕人们的老大难问题:
一、什么是HTTP缓存?
HTTP 缓存会存储与请求关联的响应,并将存储的响应复用于后续请求。(MDN)
通俗的讲,HTTP 缓存指的是:当浏览器向服务器发起资源请求时,会首先抵达浏览器缓存,如果浏览器有当前请求资源的有效副本,就可以直接从浏览器缓存中取出资源并返回,不用再重新去服务器中获取了。
常见的 HTTP 缓存只能缓存 GET 请求的资源,对于其他类型的响应则无能为力,所以后续说的请求缓存都是指 GET 请求。
HTTP 缓存都是从第二次请求开始的,第一次请求资源时,服务器返回资源,并在 response headers 头中回传资源的缓存参数;第二次请求时,浏览器会判断这些参数,命中强缓存就直接返回 200,否则就把缓存相关参数添加到 request headers 中传给服务器,服务器判断是否命中协商缓存,命中则返回 304,否则服务器会返回 200 并返回新的资源。
浏览器第一次请求流程图:

注意: 官网文档上用词为 fresh 和 stale,国内的文档上大多都用词为强缓存和协商缓存,此文也如此。
1. HTTP 缓存分类
根据是否需要向服务器重新发起请求来分类,可以分为强缓存和协商缓存;
注意: MDN上一般按照私有缓存和共有缓存来分来,但以上分类更适合于我们初学者了解缓存相关知识,所以本文按以上方式对缓存进行分类!
下图是强缓存和协商缓存的一些对比:

1.1 强缓存
强缓存是指在缓存数据未失效的情况下(即 Cache-Control 的 max-age 没有过期或者 Expires 的缓存时间没有过期),那么就会直接使用浏览器的缓存数据,而不会请求服务器。
强缓存生效时,HTTP 状态码为 200。
优点:这种方式页面加载速度是最快的,性能也是很好的。
缺点:如果在这期间服务端资源有更新,页面上是拿不到更新后的数据的。 这种情况我们在开发中也是经常遇见的,比如我们修改了页面的某个样式,在页面上刷新了但没有生效,因为走的是强缓存,所以 Ctrl + F5 一顿操作过后就好了。
跟强缓存相关的 header 头属性有(Pragma / Cache-Control / Expires)

强缓存流程图:

1.2 协商缓存
当以下条件满足一个或多个时:
- 当第一次请求时,服务器返回的响应头中没有设置 Cache-Control 和 Expires 字段;
- Cache-Control 和 Expires 过期;
- Cache-Control 和 Pragma 设置为:no-cache;
那么浏览器第二次请求时,就会与服务器进行协商,与服务端对比判断资源是否进行了更新。
如果服务端资源未更新,则会返回 304 状态码,告诉浏览器当前缓存可继续使用;如果服务端资源有更新,则会返回 200 状态码,并同时返回更新后的资源和缓存信息字段。
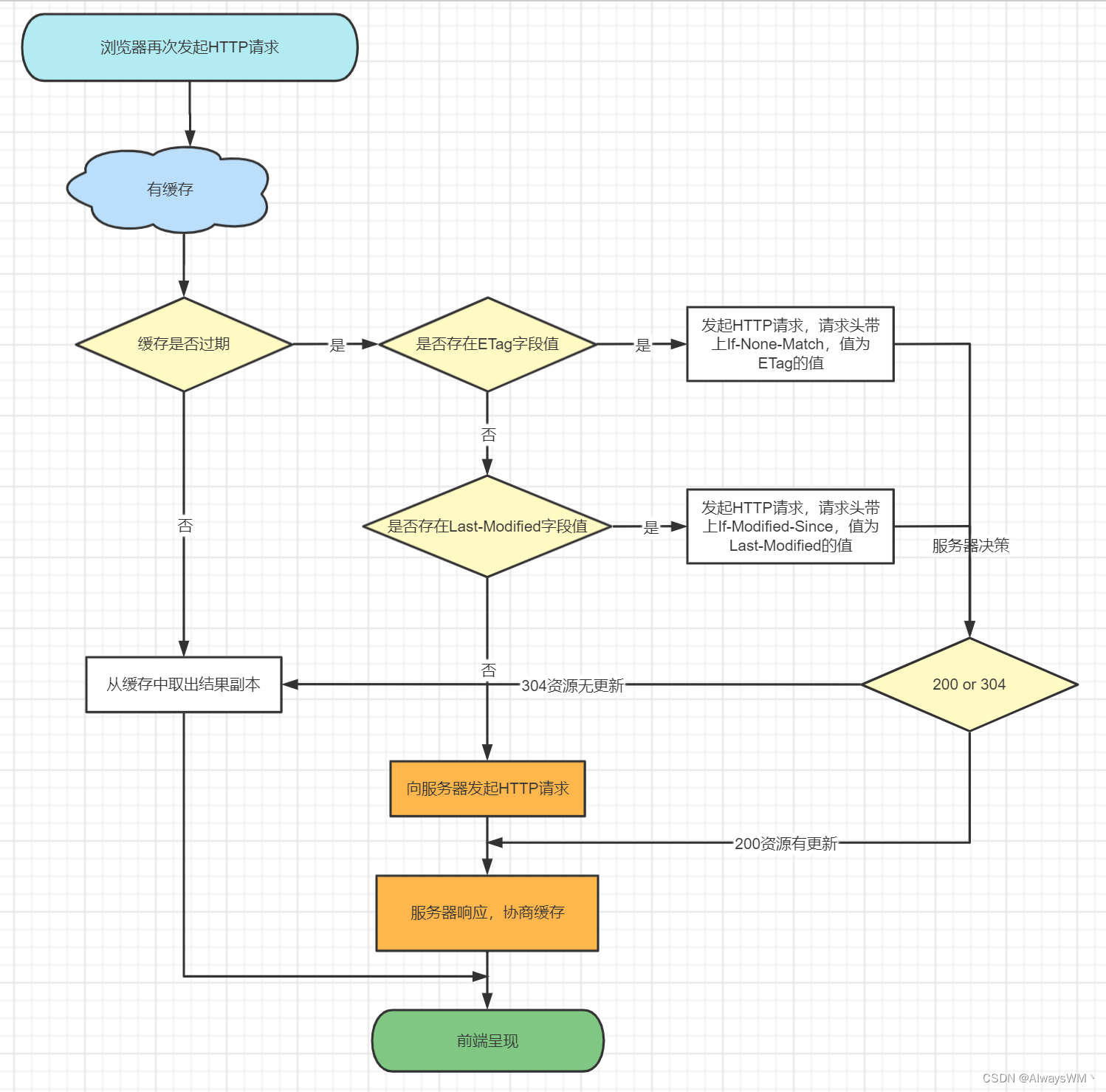
与协商缓存相关的字段有 ETag / If-None-Match、Last-Modified / If-Modified-Since,此时请求头与响应头需要成对出现。

协商缓存流程示意图如下:
二、如何使用 HTTP 缓存?
一般需要缓存的资源有 HTML 页面和其他一些静态资源:
-
HTML 页面缓存的设置主要是在 <head> 标签中嵌入 <meta> 字段,这种方式只对页面有效,对页面上的资源无效。
1.1 HTML 页面禁用缓存的设置如下:
<meta http-equiv="pragma" content="no-cache"> <meta http-equiv="cache-control" content="no-cache"> <meta http-equiv="expires" content="0">2.2 HTML 设置使用缓存如下:
<meta http-equiv="Cache-Control" content="max-age=7200" /> <meta http-equiv="Expires" content="Mon, 20 Aug 2018 23:00:00 GMT" /> -
静态资源的缓存一般是在web服务器上配置的,常用的web服务器有:nginx、apache。具体的配置这里不做详细介绍,大家自行查阅。
三、HTTP 缓存的几个注意点
-
强缓存情况下,只要缓存还没过期,就会直接从缓存中读取数据,就算服务端有变化,也不会从服务端获取更新后的数据,这就就会导致无法获取到最新的数据。
解决的办法有:在修改后的资源加上随机数,确保不会从缓存中读取。
例如:
http://www.example.com/common.css?v=110
http://www.example.com/common.111.css -
尽量减少 304 的请求,因为我们知道,协商缓存每次都会与后台服务器进行交互,所以性能上不是很好,从性能上来看尽量多使用强缓存。
-
在 Firefox 浏览器上,使用 Cache-Control: no-cache 是不生效的,其识别的是 no-store。这样能达到其他浏览器使用 Cache-Control: no-cache 的效果,所以为了兼容 Firefox 浏览器,经常会写成 Cache-Control: no-cache, no-store。
-
与缓存相关的几个 header 属性:Vary、Date / Age。
Vary:
Vary 本身是“变化”的意思,而在 HTTP 报文中更趋于是“vary from”(与。。。不同)的含义,它表示服务端会以什么基准字段来区分、筛选缓存版本。在服务端有着这么一个地址,如果是 IE 用户则返回针对 IE 开发的内容,否则返回另一个主流浏览器版本的内容。
格式:Vary: User-Agent
知会代理服务器需要以 User-Agent 这个请求首部字段来区分缓存版本,防止传递给客户端的缓存不正确。
Date / Age:
响应报文中的 Date 和 Age 字段:区分其收到的资源是否命中了代理服务器的缓存。
Date 理所当然是原服务器发送该资源响应报文的时间(GMT格式),如果你发现 Date 的时间与“当前时间”差别较大,或者连续F5刷新发现 Date 的值都没变化,则说明你当前请求是命中了代理服务器的缓存。
Age 也是响应报文中的首部字段,它表示该文件在代理服务器中存在的时间(秒),如文件被修改或替换,Age会重新由0开始累计。