huggingface transformer模型介绍
总结:
模型提高性能:新的目标函数,mask策略等一系列tricks
Transformer 模型系列
自从2017,原始Transformer模型激励了大量新的模型,不止NLP任务,还包括预测蛋白质结构,时间序列预测。
有些模型只使用encoder,decoder,有些都用了。
计算机视觉
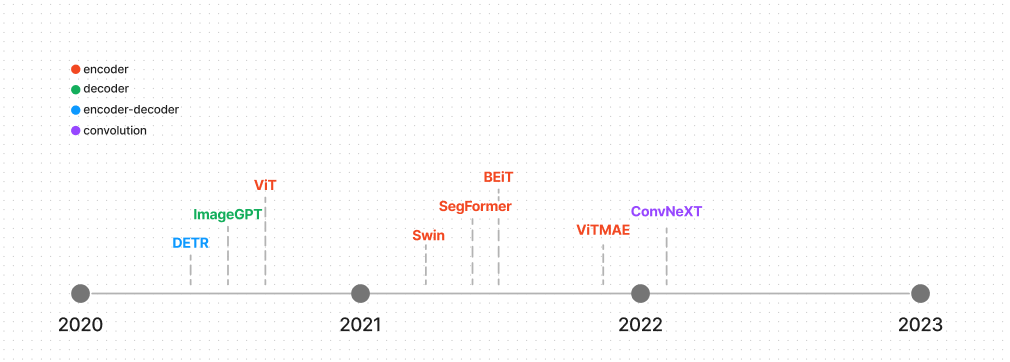
卷积网络
CNN主导了视觉任务,知道Vision Transformer证明了它的可扩展性和效率。CNN得平移不变性对于特定任务效果很棒,一些Transformer包含了这个架构,如ConvNeXt(使用了非展开滑动窗口将一张图片分块化,利用一个大的核增大全局视野。ConvNeXt也有几层被设计更有效提高性能)
Encoder
ViT(Vision Transformer)打开不使用卷积的计算机视觉任务大门,ViT使用了一个标准的Transformer encoder,不过它的主要突破在于处理图像的方法。它把一张图像分成固定大小的patch,并使用他们创建embedding,就像一个句子被切割成tokens。ViT利用了Transformers有效架构证明了使用比CNN更少资源获取有竞争力的结构。ViT不久出现了其他视觉模型,可以处理dense 视觉任务像分割,检测.
其中之一就是Swin Transformer.它建立了层次化特征映射(像CNN,而不像ViT),从小尺寸的patch ,到在更深的层把patch与相邻patch融合。注意力只在本地窗口计算,在注意力层的窗口翻转创建连接,有助于模型更好地学习。
其他视觉模型,BelT,ViTMAE,
ViT
参考:https://www.bilibili.com/video/BV15P4y137jb
卷积做不好 ViT 可以做好的:遮挡,偏移,Patch对抗,重新排列

AN IMAGE IS WORTH 16*16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
一张图片等价很多16*16大小的单词 Transformer做大规模识别
平方的复杂度
transformer 应用视觉任务难点:
像素点当输入太长,图片做patches,只对稀疏的点做注意力,知识全局注意力的一个近似全局注意力,, 等方法
论文理念:被transformer扩展性吸引。
CNN有归纳偏置(
locality,通过滑动窗口卷积,假设相邻区域有相邻特征。
平移不变形,无论先平移还是先卷积结果都一样)
有较多的先验信息,transformer可以取得很好结果,只要在很大数据集上与训练。
2242243
1616 patch大小
(196)
1616*768
加上结尾符号[CLS] 197*768
Decoder
解码器很少,因为大多数视觉模型依靠一个编码器学习图像表示。但是对于图像生成来说,解码器会自然用到,比如GPT-2,ImageGPT使用与GPT2相同的架构,只不过不是预测序列中下一个 token,而是下一个像素。ImageGPT也可以微调用来图像分类
Encoder-decoder
视觉模型通常使用编码提提取重要图像特征,在送入解码器之前。DETR有一个预训练backbone,但是也可以使用完整的编码器解码器架构用于目标检测。编码器学习图像表示,并把他们与object queries结合(每一个object query是从图像的一个区域或者物体学到的).DETR预测bounding box坐标系,为每一个object query 分类标签
自然语言处理

编码器
bert.只使用了Transformer的编码器,对输入信息随机mask 固定token。预训练目标是根据上下文预测masked token。 RoBERTa提高了性能,使用更大的批次,训练更久,每一轮迭代中随机mask token(而不是预处理时一次mask)。并且移除了下一句子预测目标。
主要提高性能的策略是增大模型尺寸,但是训练大模型计算上很贵,解决办法是使用小模型,比如DistilBERT(使用了只是蒸馏,一种压缩计算,是BERT的一个小版本,保持差不多的语言理解能力)
然而,大部分transformer模型有越来越多的参数,引导新模型关注提高训练效率。ALBERT减少了内存消耗通过降低参数数量(把更大的词汇表embedding分成两个更小的矩阵,允许层共享参数)。 DeBERTa 增加了一个解开的注意力机制,词和词的位置分开编码为两个向量,attention从这些分开的向量计算。Longformer也致力于让注意力更有效,尤其是处理长文本序列的文档
,它使用本地窗口注意力 和 全局注意力创建一个稀疏矩阵,而不是一个完整的注意力矩阵
Decoder
GPT2只使用了Transformer的解码器,预测序列中下一个词。它对右边的词做掩码处理,所以模型无法通过朝前看作弊。GPT在一个超大的语料上训练,很擅长生成文本。与bert不同的是GPT缺乏双向上下文,所以它不适应特定的认为。XLNET结合了BERT和GPT-2预训练目标,通过使用一个permutation language modeling objective组合语言模型 (PLM),允许双向学习。
GPT2之后,语言模型越来越大,被称为大型语言模型(LLM) 。LLMs 阐述了few-shot,zero-shot学习,如果训练在一个足够大的数据集上
Encoder-decoder
BART保持了原始Transformer架构,但是它修改了预训练目标,使用text infilling corruption,一些文本片段被单独的mask token替代。编码器预测uncorrupted tokens,使用解码器隐藏层帮助预测。Pegasus跟BART很相似,但是Pegasus 对整个句子做掩码,不止文本段(text span). Pegasus 通过gap sentence generation(GSG)预训练。GSG 目标 对整个句子掩码,用一个mask token替代他们。解码器从剩下的句子中输出结果。T5是一个更特别的模型,把所有MLP任务映射到文本到文本问题,通过使用具体前缀。比如Summarize:代表一个总结任务
音频
参考:https://huggingface.co/docs/transformers/model_summary]
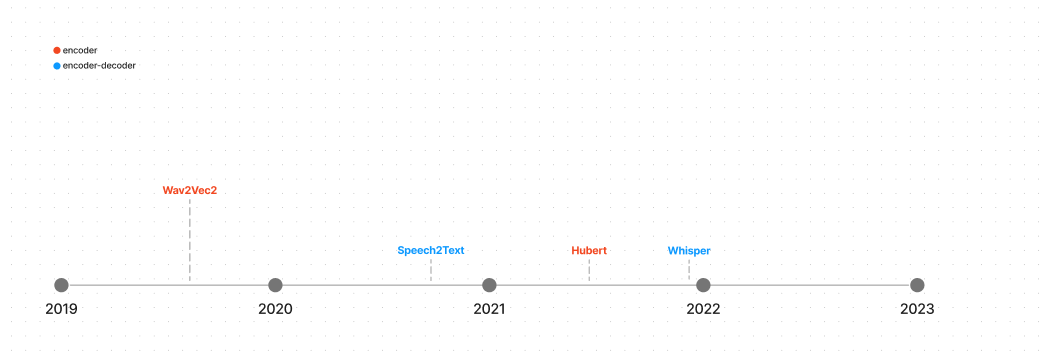
Encoder
Wav2Vec2使用了一个Transformer编码器从音频波形直接学习speech 表示,它是从对话任务中预训练区别真的音频表示和一系列假的表示
HuBERT类似于Wav2Vec2,但具有不同的训练过程。目标标签是通过聚类步骤创建的,在该步骤中,相似音频的片段被分配到一个簇,变成一个隐藏单元。隐藏单元映射到mebedding以进行预测。
Encoder-decoder
Speech2Text 被设计用于自动化语音识别(ASR automatic speech recognition) 和 翻译。模型接受从音频波形和预训练自回归生成脚本或者翻译提取的log mel-filter bank features。
Whisper也是一个ASR模型,它在一个巨大,有标签的音频转录数据集预训练,拥有zero-shot表现。数据集很大一部分包含非英语,意味着whisper可以用于低资源语言。结构上,Whisper跟Speech2Text相似,音频信号转换成log-mel 频谱图被编码器编码。解码器从编码器隐藏状态和过去token,自回归自回归生成转录
多模态
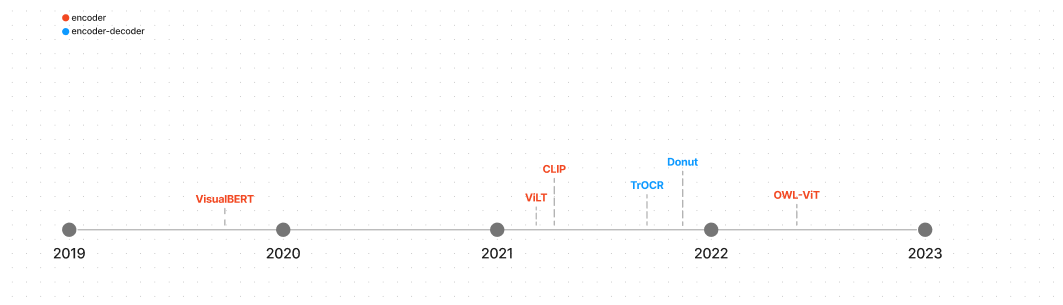
Encoder
VisualBERT是一个多模态模型,用于视觉-语言任务,BERT发布不久后,就发布了VisualBERT。它将BERT和一个预训练的目标检测系统结合,提取视觉的embedding,传递文本embedding给BERT。 VisualBert 预测masked text基于unmasked文本和视觉embedding,它也不得不预测是否文本跟图像时对齐的。
ViT发布后,ViLT采用ViT在它的架构中,因为这样更太容易获取图像embedding.图像embedding和文本embedding共同处理。ViLT 被图像文本,masked 语言建模,整个word masking 作为预训练模型。
CLIP 采用了不同的方法,做了图像,文本的配对预测。一个图像解码器ViT和一个文本编码器(Transformer)共同训练在一个4亿对数据集上,最大化图像和文本embedding的相似性。预训练后,可以使用自然语言知道CLIP 给图片预测文本,或者文本预测图片。
OWL-ViT 在CLIP之上建立,使用CLIP作为backbone,用于zero-shot目标检测,与训练后,一个目标检测head被加入在很多组中做一组成对(class,bounding box)预测
Encoder-decoder
OCR是一个长期存在的文本识别任务,包括几个组件理解图像和生成文本。TrOCR 使用了一个端到端的transformer简化了过程,编码器是一个ViT风格的模型用于图像理解,预处理图像成固定大小的patches.解码器接受编码器的隐藏状态,自回归生成文本。
Donut是一个更通用的视觉文档理解模型,不依赖基于OCR方法,而是使用一个Swin Transformer作为编码器和多语言 BART作为解码器。Donut基于图像和文本批注预测下一个词 来做预训练 ,解码器生成token序列, 给一个prompt.prompt对于每一个下游任务 通过一个特殊token表示。文档解析有一个特殊“parsing"token,它和编码器的隐藏状态,解析文档 为一个结构化输出格式(JSON)
增强学习

encoder
The Decision ,Trajectory Transformer将状态、动作和奖励转换为序列建模问题。决策转换器生成一系列操作,这些操作基于返回、过去状态和操作导致未来期望的回报。对于最后 K 个时间步长,三种模态中的每一种都转换为令牌嵌入,并由类似 GPT 的模型进行处理,以预测未来的操作令牌。轨迹转换器还标记状态、动作和奖励,并使用 GPT 架构处理它们。与专注于奖励条件反射的决策转换器不同,轨迹转换器通过光束搜索生成未来的动作。
其他系列模型
YOLOS
没什么实感
You Only Look at One Sequence
https://huggingface.co/docs/transformers/model_doc/yolos#transformers.YolosFeatureExtractor
tips:
可以使用YolosImageProcessor做预处理,与DETR对比,YOLOS不需要像素级别的掩码
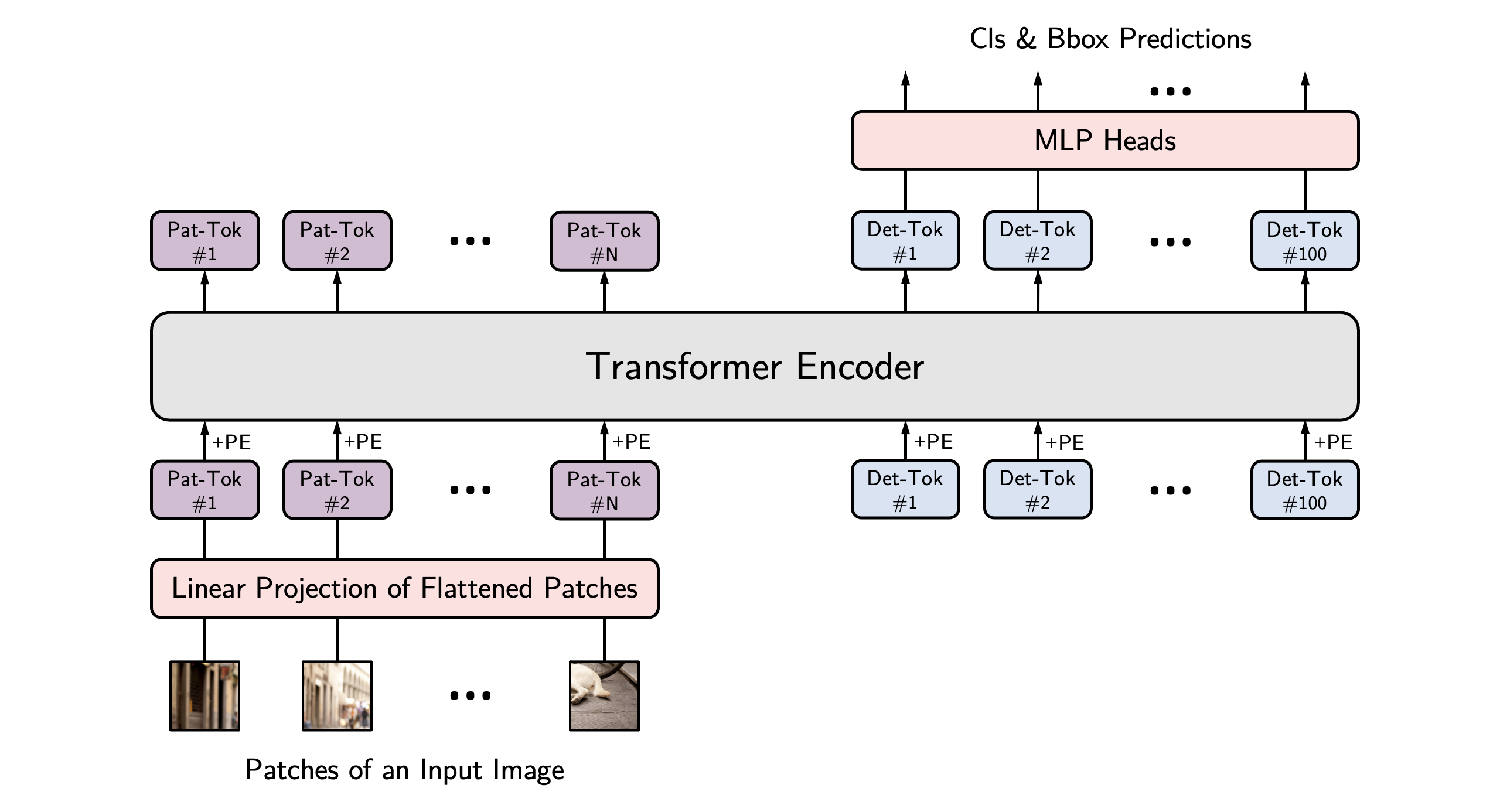
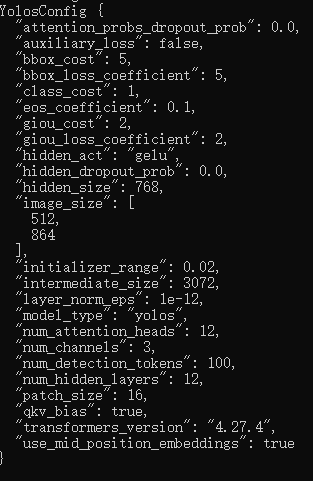
YolosConfig
( hidden_size = 768num_hidden_layers = 12num_attention_heads = 12intermediate_size = 3072hidden_act = 'gelu'hidden_dropout_prob = 0.0attention_probs_dropout_prob = 0.0initializer_range = 0.02layer_norm_eps = 1e-12image_size = [512, 864]patch_size = 16num_channels = 3qkv_bias = Truenum_detection_tokens = 100use_mid_position_embeddings = Trueauxiliary_loss = Falseclass_cost = 1bbox_cost = 5giou_cost = 2bbox_loss_coefficient = 5giou_loss_coefficient = 2eos_coefficient = 0.1**kwargs )
参数
- hidden_size (int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer.
- num_hidden_layers (int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder.
- num_attention_heads (int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder.
- intermediate_size (int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder.?
- hidden_act (str or function, optional, defaults to “gelu”) — The non-linear activation function (function or string) in the encoder and pooler. If string, “gelu”, “relu”, “selu” and “gelu_new” are supported.
- hidden_dropout_prob (float, optional, defaults to 0.1) — The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
- attention_probs_dropout_prob (float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities.
- initializer_range (float, optional, defaults to 0.02) — The standard deviation of the - truncated_normal_initializer for initializing all weight matrices.
- layer_norm_eps (float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers.
- image_size (List[int], optional, defaults to [512, 864]) — The size (resolution) of each image.
- patch_size (int, optional, defaults to 16) — The size (resolution) of each patch.
- num_channels (int, optional, defaults to 3) — The number of input channels.
- qkv_bias (bool, optional, defaults to True) — Whether to add a bias to the queries, keys and values.
- num_detection_tokens (int, optional, defaults to 100) — The number of detection tokens.
- use_mid_position_embeddings (bool, optional, defaults to True) — Whether to use the mid-layer position encodings.
- auxiliary_loss (bool, optional, defaults to False) — Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
- class_cost (float, optional, defaults to 1) — Relative weight of the classification error in the Hungarian matching cost.
- bbox_cost (float, optional, defaults to 5) — Relative weight of the L1 error of the bounding box coordinates in the Hungarian matching cost.
- giou_cost (float, optional, defaults to 2) — Relative weight of the generalized IoU loss of the bounding box in the Hungarian matching cost.
- bbox_loss_coefficient (float, optional, defaults to 5) — Relative weight of the L1 bounding box loss in the object detection loss.
- giou_loss_coefficient (float, optional, defaults to 2) — Relative weight of the generalized IoU loss in the object detection loss.
- eos_coefficient (float, optional, defaults to 0.1) — Relative classification weight of the ‘no-object’ class in the object detection loss.
from transformers import YolosConfig, YolosModel
# Initializing a YOLOS hustvl/yolos-base style configuration
configuration = YolosConfig()
# Initializing a model (with random weights) from the hustvl/yolos-base style configuration
model = YolosModel(configuration)
# Accessing the model configuration
configuration = model.config
报错'ChannelDimension' from 'transformers.image_utils',退出命令行再试一次成功

YolosImageProcessor
YolosFeatureExtractor
YolosModel
from transformers import AutoImageProcessor, YolosModel
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
image_processor = AutoImageProcessor.from_pretrained("hustvl/yolos-small")
model = YolosModel.from_pretrained("hustvl/yolos-small")
inputs = image_processor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
list(last_hidden_states.shape)

YolosForObjectDetection
from transformers import AutoImageProcessor, AutoModelForObjectDetection
import torch
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("hustvl/yolos-tiny")
model = AutoModelForObjectDetection.from_pretrained("hustvl/yolos-tiny")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to COCO API
target_sizes = torch.tensor([image.size[::-1]])
results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
0
]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
