CoDeF视频处理——视频风格转化部署使用与源码解析
一、算法简介与功能
CoDef是作为一种新型的视频表示形式,它包括一个规范内容场,聚合整个视频中的静态内容,以及一个时间变形场,记录了从规范图像(即从规范内容场渲染而成)到每个单独帧的变换过程。针对目标视频,这两个场共同优化以通过一个精心设计的渲染流程对其进行重建。我们特意在优化过程中引入了一些正则化项,促使规范内容场从视频中继承语义(例如,物体的形状)信息。
CoDeF 在视频处理中自然地支持图像算法的升级,这意味着可以将图像算法应用于规范图像,并借助时间变形场轻松地将结果传播到整个视频中。CoDeF 能够将图像到图像的转换提升为视频到视频的转换,将关键点检测提升为关键点跟踪,而无需任何训练。更重要的是,由于CoDef的升级策略仅在一个图像上部署算法,与现有的视频到视频转换方法相比,CoDef在处理的视频中实现了更优越的跨帧一致性,甚至成功地跟踪了水和烟雾等非刚性物体。

二、环境配置
Segment-and-Track-Anything
光线追踪、目标分割
conda create -n sta python==3.10
git clone https://github.com/z-x-yang/Segment-and-Track-Anything.git
cd Segment-and-Track-Anything
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
conda install m2-base
bash script/install.sh
git clone https://github.com/IDEA-Research/GroundingDINO.git
pip install weditor==0.6.4
https://huggingface.co/bert-base-uncased/tree/main
一、数据处理
1.剪切视频
把视频剪切成4秒以下的视频
2.拆分视频
使用ffmpeg拆分视频
ffmpeg -r 25 -i all_sequences/mm/mm.mp4 -start_number 0 -pix_fmt rgb24 all_sequences/mm/mm/%5d.png

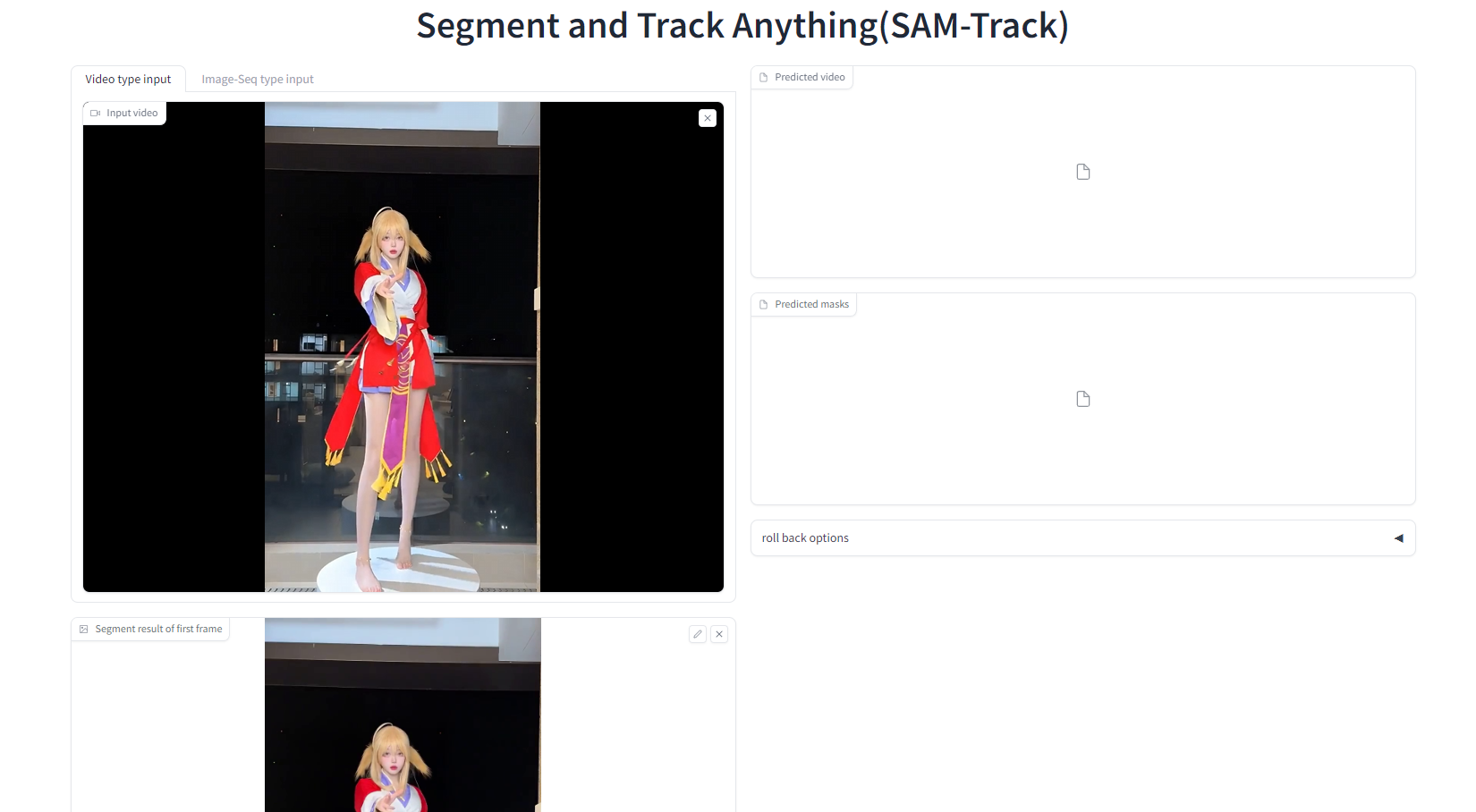
3.分割目标
使用 Segment-and-Track-Anything进行目标分割
activate sta
python app.py
然后打开http://127.0.0.1:7860

然后加载视频
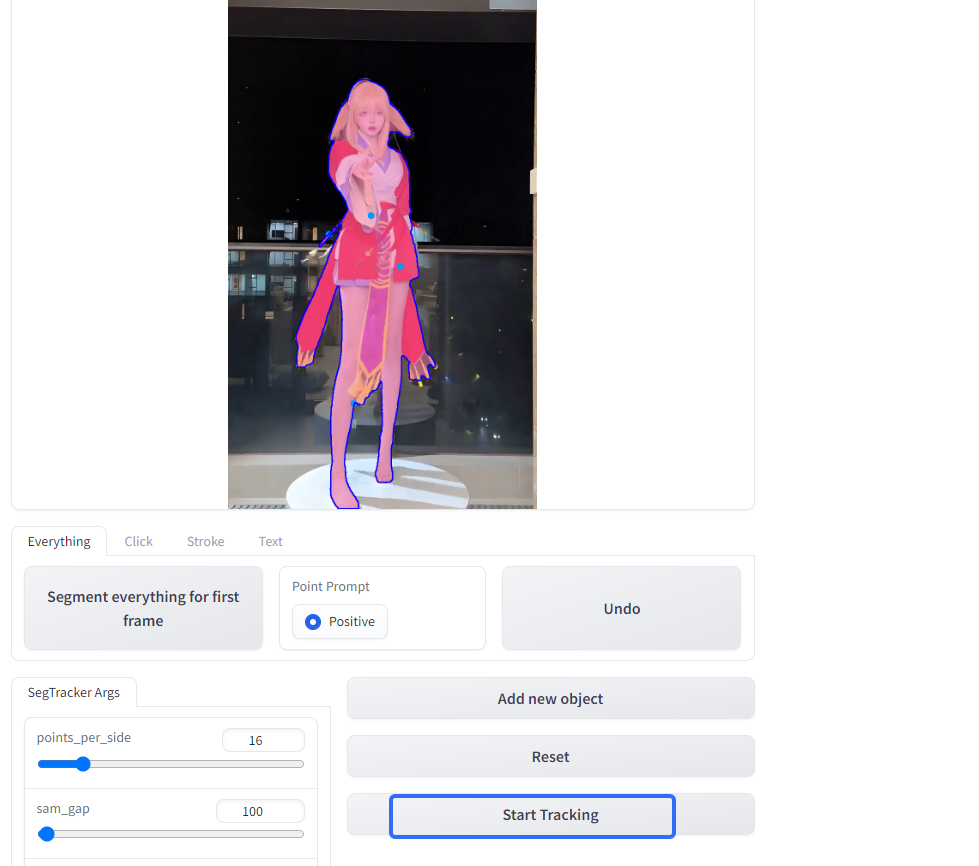

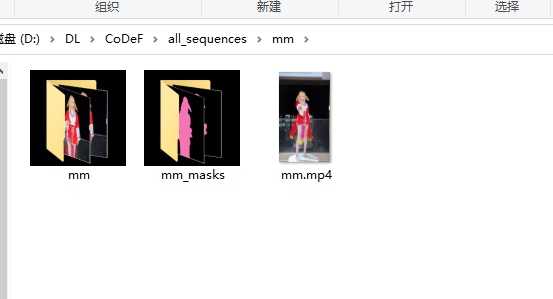
复制到数据目录
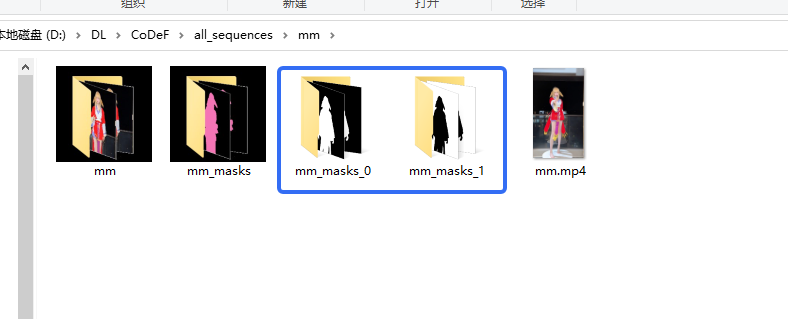
4.生成mask图
执行
python preproc_mask.py
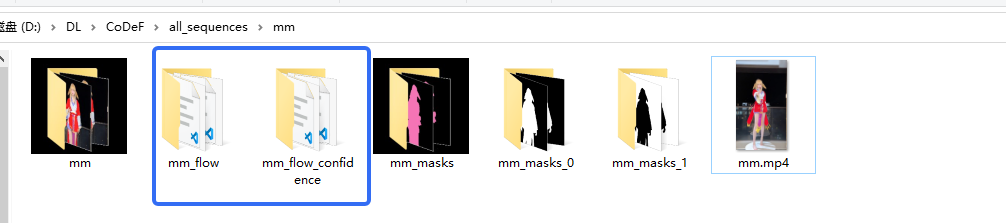
5.生成光线追踪数据
cd data_preprocessing/RAFT
bash run_raft.sh mm

二、模型训练
1. 更改配置文件
在configs目录下创建一个和视频数据一个的目录,在目录下添加一个base.yaml文件

文件内容如下,注意img_wh和canonical_wh这两个参数:
mask_dir: null
flow_dir: null
img_wh: [720, 1280] #视频尺寸
canonical_wh: [720, 1280] #输出尺寸
lr: 0.001
bg_loss: 0.003
ref_idx: null # 0
N_xyz_w: [8,8,]
flow_loss: 0
flow_step: -1
self_bg: True
deform_hash: True
vid_hash: True
num_steps: 10000
decay_step: [2500, 5000, 7500]
annealed_begin_step: 4000
annealed_step: 4000
save_model_iters: 2000
2. 训练模型
新建一个mm_train_multi.sh文件
GPUS=0
NAME="$1"
EXP_NAME="$2"
ROOT_DIRECTORY="all_sequences/$NAME/$NAME"
MODEL_SAVE_PATH="ckpts/all_sequences/$NAME"
LOG_SAVE_PATH="logs/all_sequences/$NAME"
MASK_DIRECTORY="all_sequences/$NAME/${NAME}_masks_0 all_sequences/$NAME/${NAME}_masks_1"
FLOW_DIRECTORY="all_sequences/$NAME/${NAME}_flow"
python train.py --root_dir $ROOT_DIRECTORY \
--model_save_path $MODEL_SAVE_PATH \
--log_save_path $LOG_SAVE_PATH \
--mask_dir $MASK_DIRECTORY \
--flow_dir $FLOW_DIRECTORY \
--gpus $GPUS \
--encode_w --annealed \
--config configs/${NAME}/${EXP_NAME}.yaml \
--exp_name ${EXP_NAME}
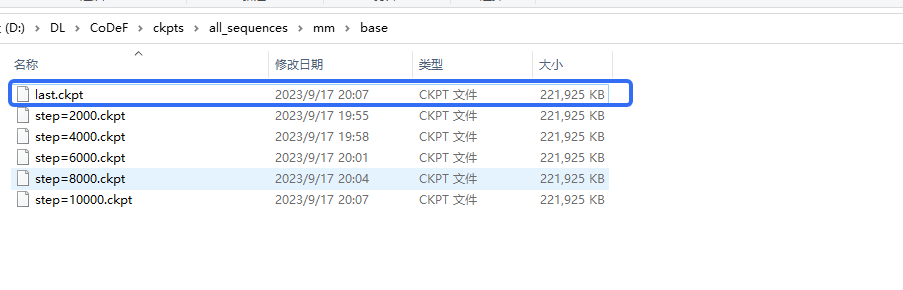
运行训练脚本,训练时间大概就几分钟,看GPU的大小:
bash scripts/mm_train_multi.sh mm base
三、测试模型
1.测试数据
在scripts目录下创建一个新的mm_test_multi.sh,文件内容如下:
GPUS=0
NAME="$1"
EXP_NAME="$2"
ROOT_DIRECTORY="all_sequences/$NAME/$NAME"
LOG_SAVE_PATH="logs/test_all_sequences/$NAME"
MASK_DIRECTORY="all_sequences/$NAME/${NAME}_masks_0 all_sequences/$NAME/${NAME}_masks_1"
WEIGHT_PATH=ckpts/all_sequences/$NAME/${EXP_NAME}/${NAME}.ckpt
python train.py --test --encode_w \
--root_dir $ROOT_DIRECTORY \
--log_save_path $LOG_SAVE_PATH \
--mask_dir $MASK_DIRECTORY \
--weight_path $WEIGHT_PATH \
--gpus $GPUS \
--config configs/${NAME}/${EXP_NAME}.yaml \
--exp_name ${EXP_NAME} \
--save_deform False
运行脚本文件:
bash scripts/mm_test_multi.sh mm base
四、错误处理
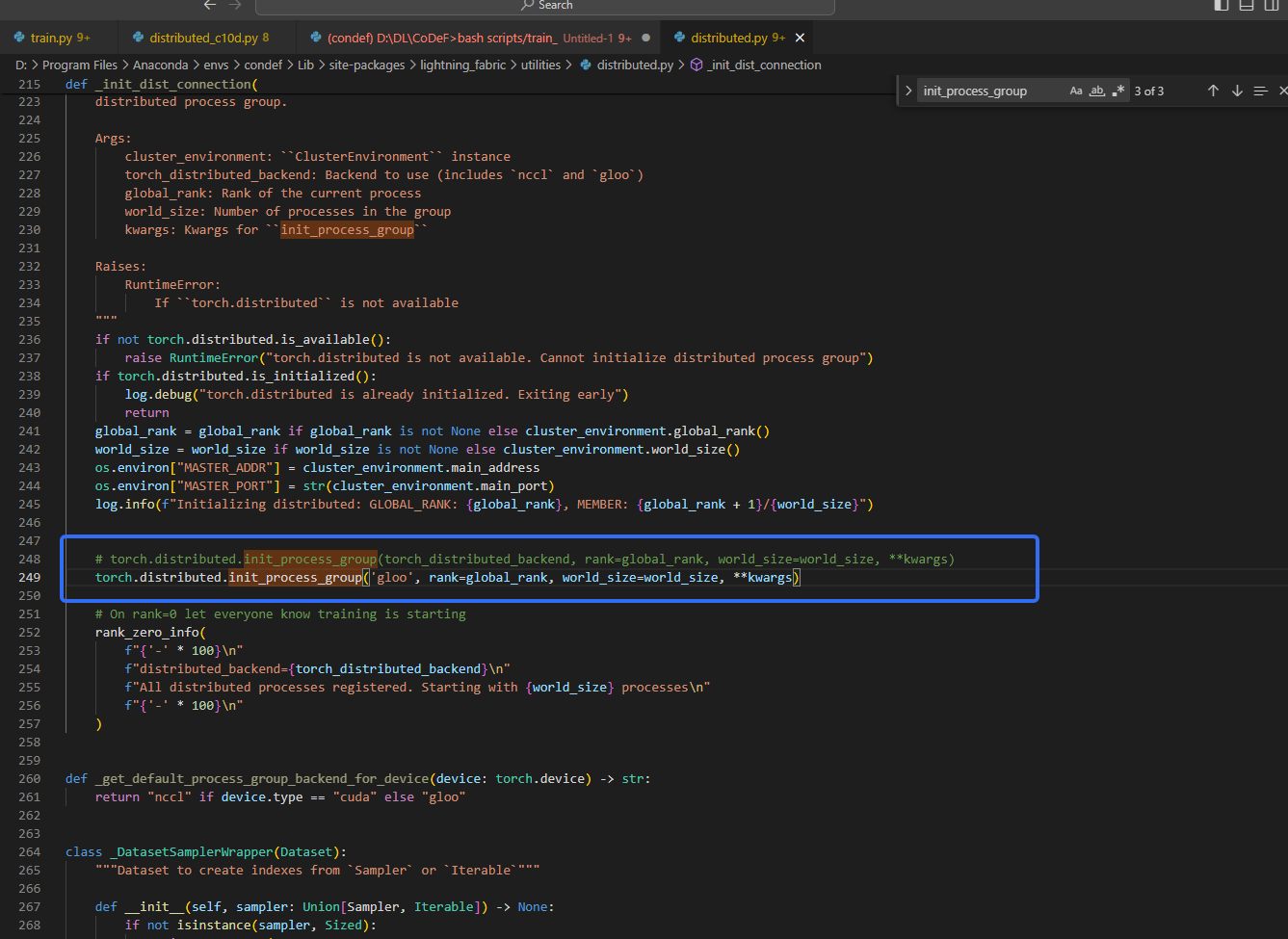
1. windows不支持NCCL backend
Windows RuntimeError: Distributed package doesn‘t have NCCL built in
2. wsgiref-0.1.2
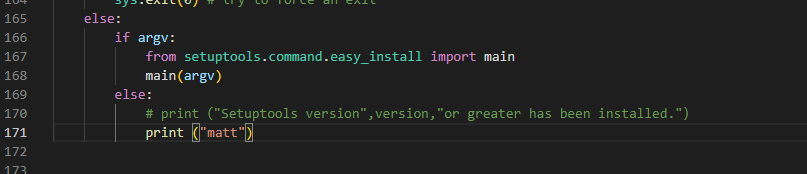
SyntaxError: Missing parentheses in call to ‘print’. Did you mean print(…)?
pip install ./wsgiref-0.1.2