【mysql 进阶】3 MySQL架构和存储引擎
MySQL架构和存储引擎
1. 本专题⽬标:
了解MySQL整体架构
了解MySQL架构各层级的组成和作⽤了解存储引擎分类
了解不同存储引擎的特点
掌握创建表时指定存储引擎的⽅式
2. MySQL架构
MySQL8.0服务器是由连接池、服务管理⼯具和公共组件、NoSQL接⼝、SQL接⼝、解析器、优化器、缓存、存储引擎、⽂件系统组成。MySQL还为各种编程语⾔提供了⼀套⽤于外部程序访问服务器的连接器。整体架构图如下所⽰:
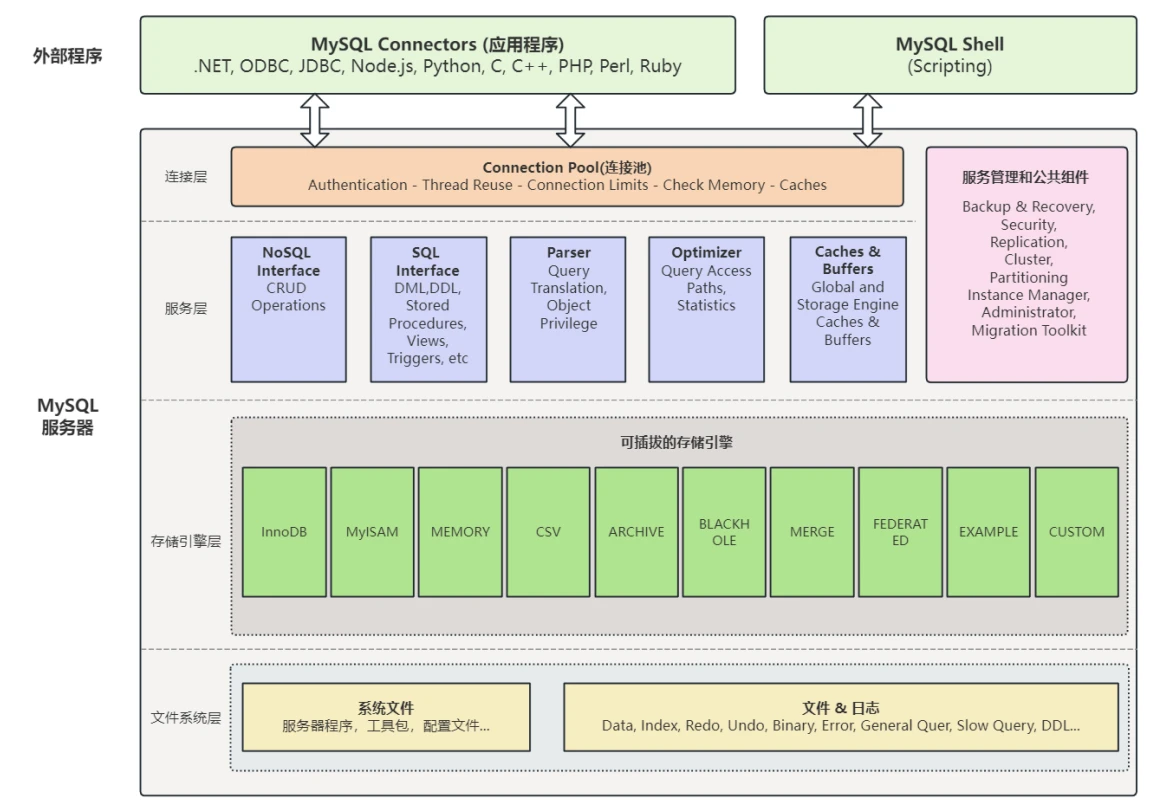
- MySQL Connectors:为使⽤MySQL服务的编程语⾔平台,提供了访问接⼝,可以根据⾃⼰实际使⽤的编程语⾔到官⽹下载地址下载。
- MySQL Shell:是⼀个⾼级客⼾端和代码编辑器,以组件的形式提供,需要单独安装。除了提供的类似于 mysql 客⼾端的功能,还可以使⽤ JavaScript 和 Python 调⽤MySQL 的API,⼀般为开发⼈员使⽤。
- 连接层:对客⼾端连接进⾏权限校验并保存客⼾端的连接信息,通过池化技术实现线程重⽤,以及根据具体的配置限制连接数量。
- 服务管理和公共组件:提供了数据备份与恢复,安全组件,主从复制和集群管理,表分区等实⽤功能。
- 服务层:提供了NoSQL API, SQL API, SQL语句解析,SQL语句优化,SQL语句缓存等组件,并将优化后的SQL语句发送⾄存储引擎执⾏相应的操作并返回结果。
- 存储引擎层:⼀系列可插拔的存储引擎,主要负责数据的写⼊和读取,与底层的数据和⽇志⽂件进⾏交互,可以根据具体的业务需求选择不同的存储引擎,后⾯我们具体介绍他们之间的区别。
- ⽂件系统层:包含了MySQL发⾏版的⽂件和程序,以及具体数据库⽂件和⽇志。
接下来我们介绍各层级在整个MySQL服务器中实现的功能。
3. 连接层
连接层的作⽤是处理客⼾端的连接,这个⼩节主要介绍MySQL Server如何管理连接,包括对可⽤连接接⼝的描述和服务器如何使⽤连接处理线程。
3.1 ⽹络端⼝和连接管理线程
3.1.1 ⽹络端⼝
⼀台服务器能够侦听多个⽹络端⼝上的客⼾端连接,开放多个端⼝,只需在选项⽂件中指定多个端⼝即可,配置如下所⽰:

3.1.2 连接管理线程
通过连接管理器线程处理端⼝上的客⼾端连接请求:
- 在所有平台上,⽤⼀个管理器线程处理所有的 TCP/IP 连接请求。
- 在 Unix 上,管理器线程还可以处理其他Unix socket 连接请求。
- 在 Windows 上,使⽤⼀个管理器线程处理通过Shared-memory⽅式连接请求,使⽤另⼀个管理器线程处理Named-pipe⽅式连接请求。
- 在所有平台上,可以额外启⽤⼀个端⼝⽤于接受针对管理的 TCP/IP 连接请求,管理端⼝的连接可以使⽤处理"普通" TCP/IP 请求的管理器线程,也可以通过选项⽂件配置单独的线程(不做讨论)。
3.2 客⼾端连接线程管理
连接管理器线程在接收到每个客⼾端连接后,把请求转发到真正的执⾏线程,每个请求都对应⼀个执⾏线程,该线程处理连接的⾝份验证和具体请求。执⾏线程使⽤线程池技术进⾏缓存,当⼀个请求需要处理时,先从线程池中查找是否有可⽤的线程,如果没有则新创建⼀个,当连接结束时,如果线程池没有满,则把当前线程放⼊线程池,主要的作⽤是提⾼线程的复⽤,减少创建线程造成的系统开销从⽽提⾼效率。
可以通过以下⼏个系统变量和状态变量控制和监视服务器管理客⼾端连接的线程:
- 系统变量 thread_cache_size 决定了线程池缓存的⼤⼩。默认情况下,服务器在启动时会⾃动调整这个值,但也可以通过选项⽂件明确指定⼤⼩,值为 0 时禁⽤缓存,此时为每个新连接创建执⾏⼀个线程,并在连接断开时释放;
- 有些复杂的SQL语句在执⾏过程中可能会有深层递归从⽽消耗更多的内存,通过设置thread_stack=N 调整线程堆栈⼤⼩;
- 要查看缓存中的线程数以及超过缓存数后新创建的线程数,通过状态变量 Threads_cached 和Threads_created 查看;

thread_cache_size 和 thread_stack 的⼤⼩需要根据机器的具体配置进⾏调整
3.3 连接量管理
- 系统变量 max_connections 可以控制服务器允许同时连接的最⼤客⼾端数,当服务器达到max_connections 指定的连接数时会拒绝所有新的连接请求,同时会增加状态变量Connection_errors_max_connections 的值;
- mysqld实际上允许 max_connections+1 个客⼾端连接。额外的连接为拥有CONNECTION_ADMIN 权限的帐⼾(管理员)使⽤,即使普通连接达到了 max_connections 的数量,管理员也可以连接到服务器进⾏管理操作;
- 在部署为主从复制的环境中,从节点的连接数也会计⼊ max_connections 中,如果连接达到上限主从复制将会失败;
- max_connections 具体数据和服务器的硬件有关,⽐如可⽤的内存、每个连接消耗的内存,每个连接的⼯作负载、响应时间、可⽤⽂件描述符的数量等等
4. 服务层
数据库服务层是整个数据库服务器的核⼼,主要包括了服务管理和公共组件、NoSQL和SQL接⼝、解析器、查询优化器和缓存等部分,下⾯我们分别介绍每个部分的作⽤:
4.1 服务管理和公共组件
MySQL提供了多种功能服务以满⾜不同使⽤场景下的需要,常⽤的服务如下:
- Backup & Recovery:备份与恢复
- Security:安全
- Replication:主从复制
- Cluster:MySQL集群
- Partitioning:表分区
- Instance Manager:实例管理
- Administrator:MySQL管理员
- Migration Toolkit:迁移⼯具包
4.2 NoSQL接⼝与SQL接⼝
主要负责接收客⼾端发送的各种SQL语句和命令,并将SQL发送到其他部分,然后把接收到的结果返回给客⼾端。
4.3 Parser(语法分析器)
语法分析器的主要作⽤是将客⼾端发来的SQL语句中的关键字和⾃定义字段进⾏提取、解析,最终将 SQL 语句转换为⼀棵解析树,分析的过程中包含词法分析和语法分析;词法分析,主要是对关键字进⾏提取,⽐如 select/update/delete/create… ;语法分析,主要判断 SQL 语句是否满⾜语法规则,如果语法错误则异出异常,也就是我们常⻅的ERROR 1064 (42000): You have anerror in your SQL syntax。

4.4 Optimizer(查询优化器)
通过语法校验的SQL语句将进⼊查询优化器处理阶段,查询优化器会将解析树转化为查询计划,⼀般情况下,⼀条查询可以有很多种执⾏⽅案,查询优化器会根据执⾏计划匹配合适的索引,选择最佳的执⾏⽅案,最终把确定要执⾏的SQL交给执⾏器调⽤存储引擎API。
TIPS:
优化后的SQL语句在条件查询时可能与程序员写的条件过滤顺序不同,但最终的返回结果⼀致
4.5 Caches & Buffers(缓存)
MySQL的缓存主要的作⽤是为了提升查询的效率,当服务器接收到⼀个 select 查询语句时,会先进⼊缓存查询当前SQL语句在缓存中是否存在,缓存以 key 和 value 的形式存储,key是具体的SQL语句,value是结果的集合,如果命中缓存,直接返回结果,⽆法命中缓存,则进⼊分析器进⾏正常查询流程。
这⾥需要说明的是,缓存数据对应的数据在被更新之后将会失效,尤其在写多读少的场景中,缓存会频繁失效与新增,命中率⾮常低,因此MySQL5.6之后服务层缓存功能默认关闭,⽽且在MySQL8.0中服务层缓存被官⽅删除,这⾥不做过多讨论。
4.6 SQL语句的执⾏流程

5. 存储引擎
存储引擎是处理不同表类型SQL操作的MySQL组件。MySQL服务器采⽤可插拔的存储引擎架构,在服务器运⾏时可以动态的加载和卸载。
查看当前服务器⽀持哪些存储引擎可以使⽤ SHOW ENGINES 语句, Engine 表⽰:存储引擎的名称, Support :表⽰当前服务器是否⽀持,值分别为: YES 、 NO 和 DEFAULT 分别表⽰,⽀持、不⽀持和当前设置或默认引擎,如下所⽰:
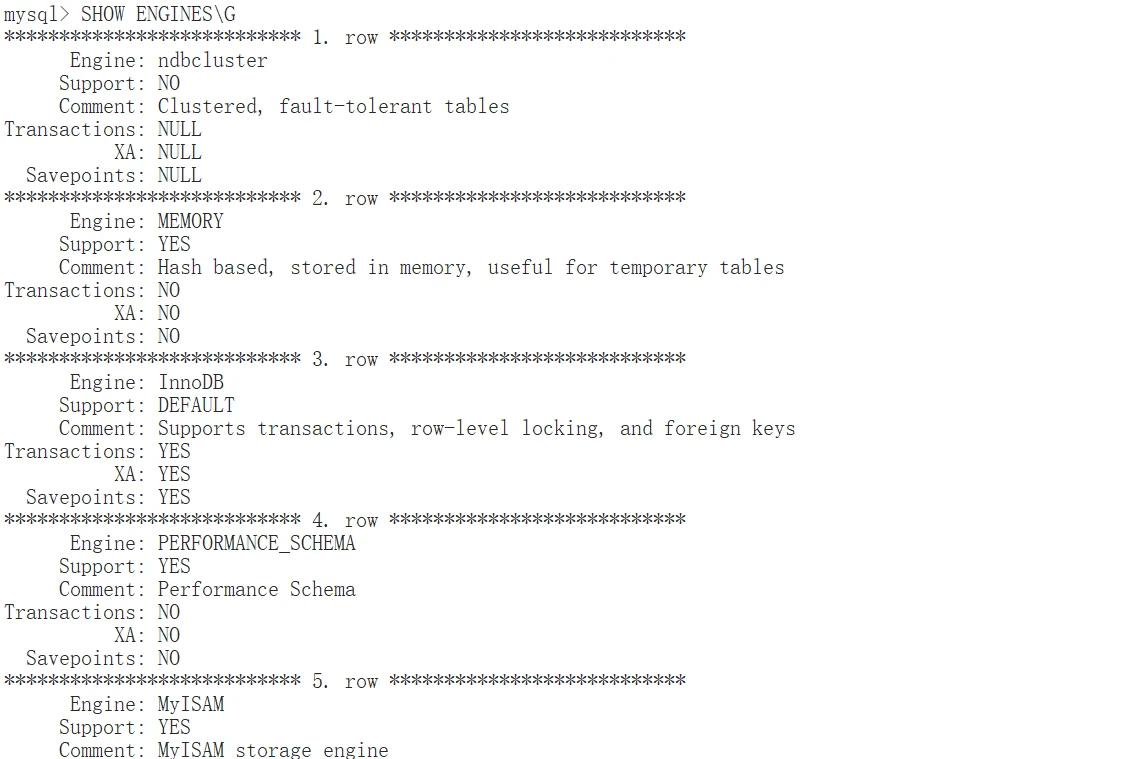
下⾯我们分别是介绍不同存储引擎的特点
5.1 InnoDB 存储引擎
InnoDB是⼀款兼顾⾼可靠性和⾼性能的通⽤存储引擎。在MySQL8.0中默认的存储引擎是 InnoDB ,使⽤ CREATE TABLE 语句创建表时,在没有修改默认存储引擎或明确指定其他存储引擎时,将创建⼀个 InnoDB 的表。
5.1.1 InnoDB存储引擎的特性
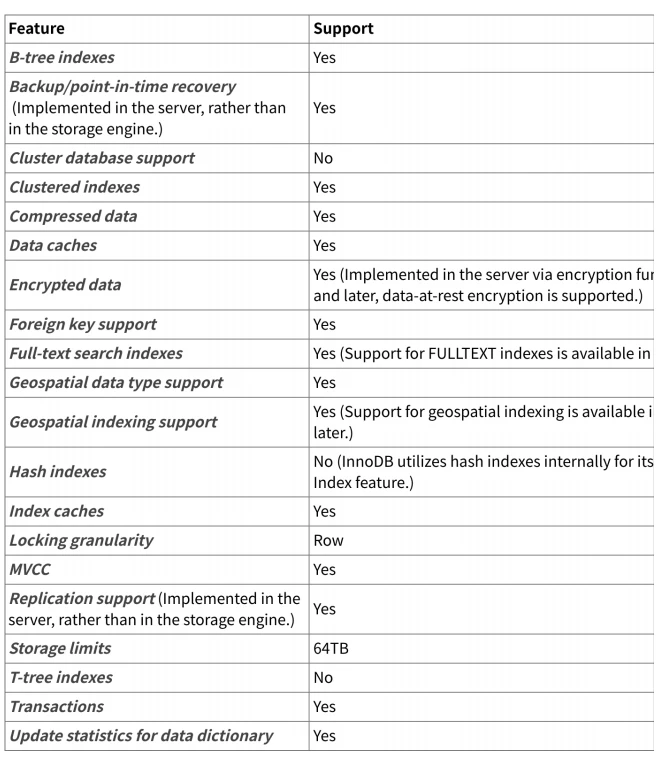
5.1.2 InnoDB 的主要优势
- DML操作遵循ACID模型,事务具有提交、回滚和崩溃恢复功能,以保护⽤⼾数据。事务和锁专题中介绍
- 如果发⽣意外⽽崩溃,⽆论当时数据库发⽣了什么,都不需要在重启数据库后执⾏任何特殊操作。InnoDB 的崩溃恢复功能会⾃动完成崩溃之前提交的更改,并撤消崩溃前正在进⾏但未提交的更改,从⽽允许我们从中断的地⽅继续执⾏。
- ⽀持⾏级锁,提⾼了多⽤⼾的读取并发性和性能。
- InnoDB 存储引擎维护了⼀个⾃⼰的缓冲池,访问数据时在内存中缓存表和索引数据,对于经常使⽤的数据直接从内存中处理,⼤幅提升了效率。在专⽤数据库服务器上,通常会将⾼达 80% 的物理内存分配给缓冲池。
- nnoDB表优化了基于主键的查询,每个InnoDB表都有⼀个称为聚簇索引的主键索引,实现通过最少的磁盘I/O完成对主键的查找。索引专题中介绍
- 为了保持数据完整性, InnoDB ⽀持 FOREIGN KEY (外键)约束。在进⾏插⼊、更新和删除数据时确保相关表之间的⼀致性
- 当从表中反复查询相同的⾏时,⾃适应哈希索引会⾃动接管这些查询,此时查询效率和哈希表相同
5.1.3 InnoDB表的最佳实践
- 为表中最频率查询的列(或多个列)指定主键(或复合主键),如果没有明显的主键,则创建⼀个⾃增的列做为主键。
- 从多个表中根据相同的ID查询数据,建议使⽤表连接。可以在连接的列上定义外键,并在每个表中使⽤相同的数据类型声明这些列。添加外键可以确保被引⽤的列使⽤索引,从⽽提⾼性能。
- 在每秒提交数百次事务的服务器上,结合存储设备的写⼊速度,关闭事务的⾃动提交,通过系统变量 autocommit=OFF 设置。
- 把相关的DML操作⽤ START TRANSACTION 和 COMMIT 语句括在⼀起,分组为事务⼀起提交或回滚。
- 不要使⽤
LOCK TABLES语句,InnoDB可以在不牺牲可靠性和⾼性能的情况下处理多个会话同时对⼀个表进⾏读写操作。
5.1.4 验证InnoDB是否为默认存储引擎
- 执⾏ SHOW ENGINES 语句查看可⽤的存储引擎时,查找 SUPPORT 列的值为 DEFAULT 的⾏

- 查询Information Schema库中的ENGINES表

- 如果InnoDB不是默认的存储引擎,可以通过在命令⾏指定选项 --default-storage-engine=InnoDB 或者在选项⽂件的 [mysqld] 节点定义 default-storage-engine=InnoDB 并重新启动服务器来设置 InnoDB 存储引擎

- 由于业务实际需要,服务器默认存储引擎不是InnoDB时,想要创建⼀个InnoDB表,可以在使⽤CREATE TABLE 语句创建表时明确指定InnoDB存储引擎,当然这样⽅式也可以指定其他任何⽀持的存储引擎

- 如果想测试使⽤其他存储引擎表中的数据在InnoDB表中的⼯作情况,在确保不影响原始表的情况下,使⽤以下⽅式创建⼀张InnoDB表
create table ... engine=InnoDB as select * from other_engine_table;
5.1.5 创建InnoDB表

当创建⼀个存储引擎为 InnoDB 的表时,会在 data_dir/test_db ⽬录下⽣成⼀个⽤来存储真实数据的物理⽂件,命名格式为 表名.ibd ,以当前为例会在 /var/lib/mysql/test_db ⽬录下⽣成⼀个 t_innodb.ibd 的表空间数据⽂件
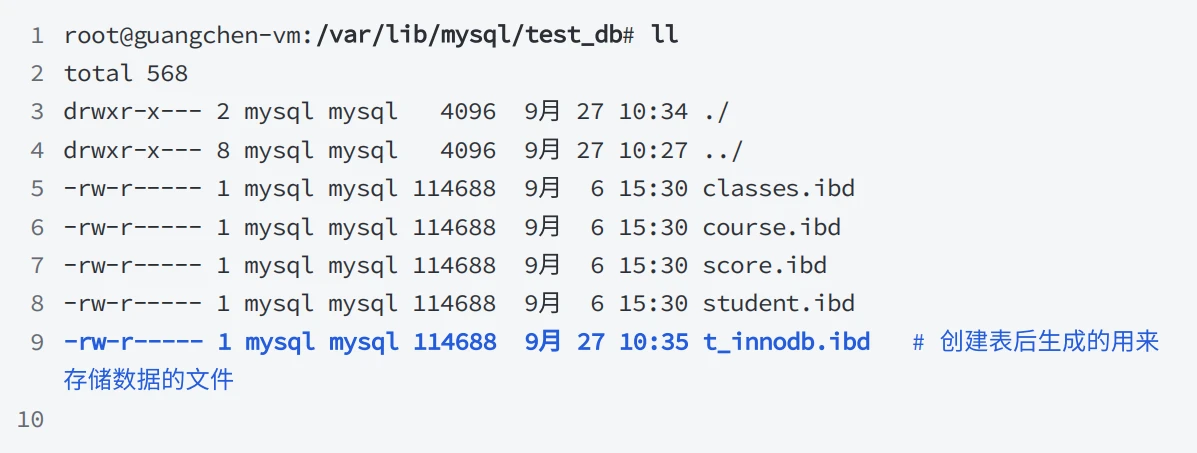
- 在MySQL8.0中表结构的信息也保存在 .ibd ⽂件中,可以使⽤ ibd2sdi ⼯具提取表定义的具体信息,使⽤⽅法: ibd2sdi –dump-file=t_innodb.txt t_innodb.ibd ,⽣成的t_innodb.txt ⽂件中有对应表的具体描述
- sid = Serialized Dictionary Information 序列化字典信息
- 和8.0有所不同的是,在MySQL5.X及以前的版本中使⽤⼀个后缀为 .frm 的⼆进制⽂件来记录和描述表定义的信息
5.2 MyISAM 存储引擎
使⽤MyISAM存储引擎的表占⽤空间很⼩,但是由于使⽤表级锁定,所以限制了读/写操作的性能,通常⽤于中⼩型的Web应⽤和数据仓库配置中的只读或主要是读的场景。
5.2.1 MyISAM 存储引擎的特性
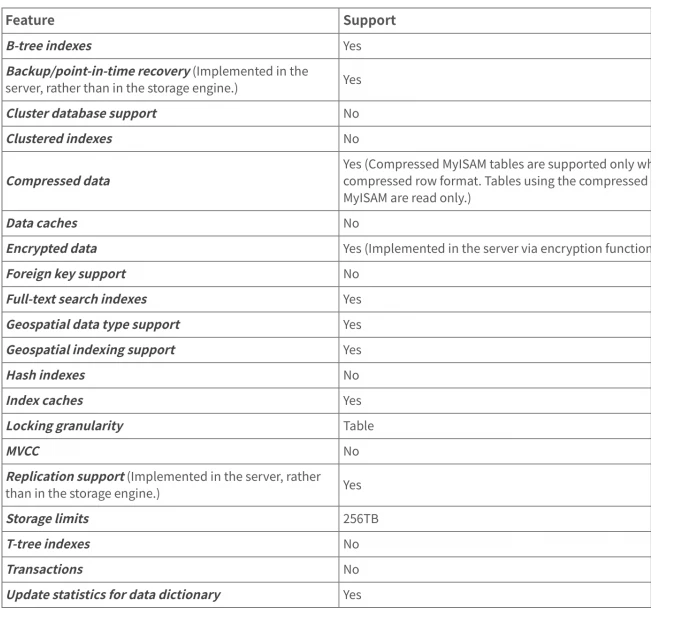
5.2.2 MyISAM 的主要优势
- MyISAM表的最⼤⾏数为 (232)2 及 (1.844E+19) ⾏;
- 每个MyISAM表最多可以创建64个索引,每个索引最多可以包含16个列;
- ⽀持并发插⼊;
- 通过 CREATE table 创建表时,指定 DATA DIRECTORY*=PATH* 和 INDEX DIRECTORY*=PATH* 将数据⽂件和索引⽂件放在不同设备的不同⽬录中,从⽽提⾼访问速度;
- BLOB 和 TEXT 数据类型的列也可以被索引;
- 在索引列中允许使⽤NULL值;
- 如果mysqld启动时设置了 myisam_recover_options 系统变量,那么MyISAM表在打开时进⾏会⾃查,如果上⼀次表没有正确关闭将会修复;
- 表中 VARCHAR 和 CHAR 列的⻓度总和最多可达64KB
- UNIQUE 约束的⻓度不受限制
5.2.3 创建MyISAM 表
- 在MySQL 8.0中 InnoDB 是默认引擎,所以在创建表时需要指定 ENGINE=MyISAM :

- 创建 MyISAM 表会根据表名⽣成三个不同后缀名⽂件,分别是以 .MYD ( MYData )为后缀的数据⽂件,以 .MYI ( MYIndex ) 为后缀的索引⽂件,以 .sdi 为后缀的表信息描述⽂件(JSON格式)
在8.0以前的版本中表信息描述⽂件是以.frm为后缀的⼆进制⽂件

5.2.4 MyISAM 表存储格式
- MyISAM 表⽀持三种不同的存储格式,其中 FIXED 静态(固定)格式和 DYNAMIC 动态格式,根据使⽤的列类型⾃动选择,第三种是压缩格式,只能使⽤ myisampack 实⽤程序⽣成并且是只读格式。
- 当表中没有 BLOB 或 TEXT 数据类型的列,在使⽤ CREATE TABLE 或 ALTER TABLE 语句创建或修改表时,可以结合 ROW_FORMAT 表选项将表格式设置为 FIXED 或 DYNAMIC 。
- 使⽤ myisamchk 实⽤⼯具对已压缩的MyISAM进⾏解压操作, myisamchk --unpack 。
5.2.4.1 静态格式(Fixed-Length)表
- 静态格式是 MyISAM 表的默认格式,当表不包含可变⻓度的列 ( VARCHAR、VARBINARY 、BLOB 或 TEXT ) 时使⽤,每⾏都使⽤固定数量的字节存储。
- MyISAM 的三种存储格式中,静态格式是最简单和最安全的(最不容易损坏),同时也是最快的磁盘格式,因为每⾏的⻓度固定,根据索引中的⾏号乘以⾏⻓度就可以计算出⾏位置,此外,每次读取固定数量的⾏也⾮常的⾼效。
- 静态格式表具有以下特点:
- CHAR 和 VARCHAR 类型的列⽤空格填充到指定的列宽; BINARY 和 VARBINARY 类型的列⽤ 0x00 字节填充到列宽
- 每个允许为NULL的列,都⽤⼀个 1 BIT 的额外空间记录当前列是否为空;
- 速度⾮常快,且易于缓存;
- 崩溃后易于重建,因为⾏都位于固定位置;
- 通常需要⽐动态格式表更多的磁盘空间;
5.2.4.2 动态格式表
- 当表中包含可变⻓度列( VARCHAR 、 VARBINARY 、 BLOB 或 TEXT )或者在创建表时使⽤ROW_FORMAT=DYNAMIC 选项,则表格式为动态存储格式
- 动态格式表具有以下特点:
- 列类型是字符串,且⻓度⼤于等于4,⻓度都是动态的;
- 每⼀⾏都有⼀个标志来指⽰⾏有多⻓,当因更新操作⽽变得更⻓时,数据可能存储在不连续的空间,可以使⽤ OPTIMIZE TABLE table_name 语句或 myisamchk -r 对表进⾏碎⽚整理;
- 每个允许为NULL的列,都⽤⼀个 1 BIT 的额外空间记录当前列是否为空;
- 每⾏前⾯都有⼀个 bitmap (位图),⽤来记录包含空字符串或0的列,如果字符串类型的列⻓度为零,或者数字列的值0,则在位图中标记并且不会保存到磁盘;
- 通常磁盘空间占⽤⽐固定⻓度表要少很多;
- 每⾏都单独压缩,每列都可能⽤单独的⽅式进⾏压缩。
- 常⽤的压缩⽅式:
- 如果数值列的值为0,⽆论原始数据类型是哪种都⽤⼀个 BIT 类型存储
- 如果整数列中的值范围较⼩,则尽可能使⼩的类型存储该列,⽐如:列中的值范围在 -128到 127 之间,即使原始类型为 bigint (8bytes),也使⽤ TINYINT (1 byte) 类型存储
- 如果列中只有⼀⼩组可能出现的值,则数据类型转换为 ENUM ;
5.2.4.3 压缩格式表
- 压缩存储格式是使⽤myisampack⼯具⽣成的只读格式数据表,压缩表可以⽤ myisamchk解压缩。
- 压缩格式表具有以下特点:
- 压缩表占⽤很少的磁盘空间,最⼤限度地减少了磁盘使⽤;
- 可以⽤于固定⻓度或动态⻓度⾏
- 压缩表是只读的,因此不能在表中更新或添加数据;
5.3 MEMORY存储引擎
使⽤MEMORY存储引擎(以前称为HEAP)创建的表,内容存储在内存中。当服务器由于硬件问题、 断电或其他原因崩溃时数据会丢失,因此这些表仅⽤作临时⼯作区或从其他表中提取数据的只读缓存。
5.3.1 使⽤场景
- 涉及瞬时、⾮关键数据的操作,例如会话管理或需要缓存的数据,当服务器停⽌或重新启动时,MEMORY 表中的数据会丢失;
- ⽤于快速访问和低延时,数据量可以完全放在物理内存中,不使⽤虚拟内存;
- 只读或以读为主的数据访问场景(有限的更新)。
5.3.2 MEMORY存储引擎的特性
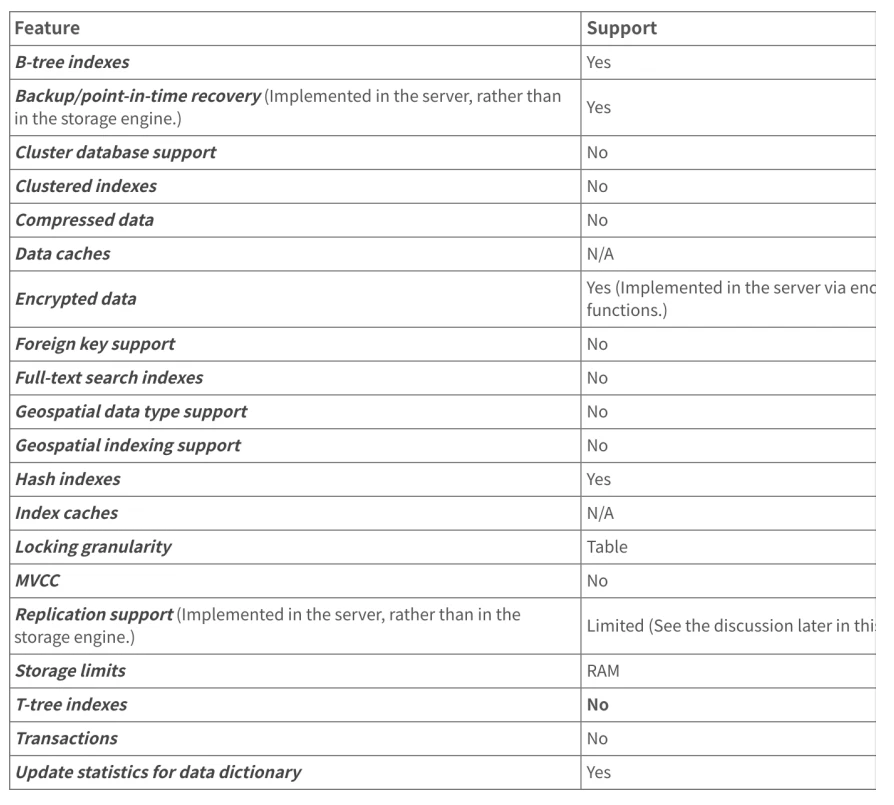
- 使⽤固定⻓度的存储格式,可变⻓度类型,例如 VARCHAR 使⽤固定⻓度存储;
- 不能包含 BLOB 或 TEXT 列;
- ⽀持 AUTO_INCREMENT 的列;
- ⾮ TEMPORARY MEMORY 表在所有客⼾端之间共享;
- ⽀持 HASH 索引(默认)和 BTREE 索引;
- 不⽀持表分区;
- 由于使⽤单线程,在⾼负载的场景下可能会涉及严重的锁竞争,特别是在多个客⼾端并发执⾏更新操作的情况下,性能并不⼀定会⽐ InnoDB 更快。
5.3.3 创建MEMORY表
- 在MySQL 8.0中 InnoDB 是默认引擎,所以在创建表时需要指定 ENGINE=MEMORY :

- 由于数据在内存中保存,所以 MEMORY 表不会在磁盘上⽣成数据⽂件,表结构保存数据字典和 .sdi ⽂件中

- 创建表并加载数据
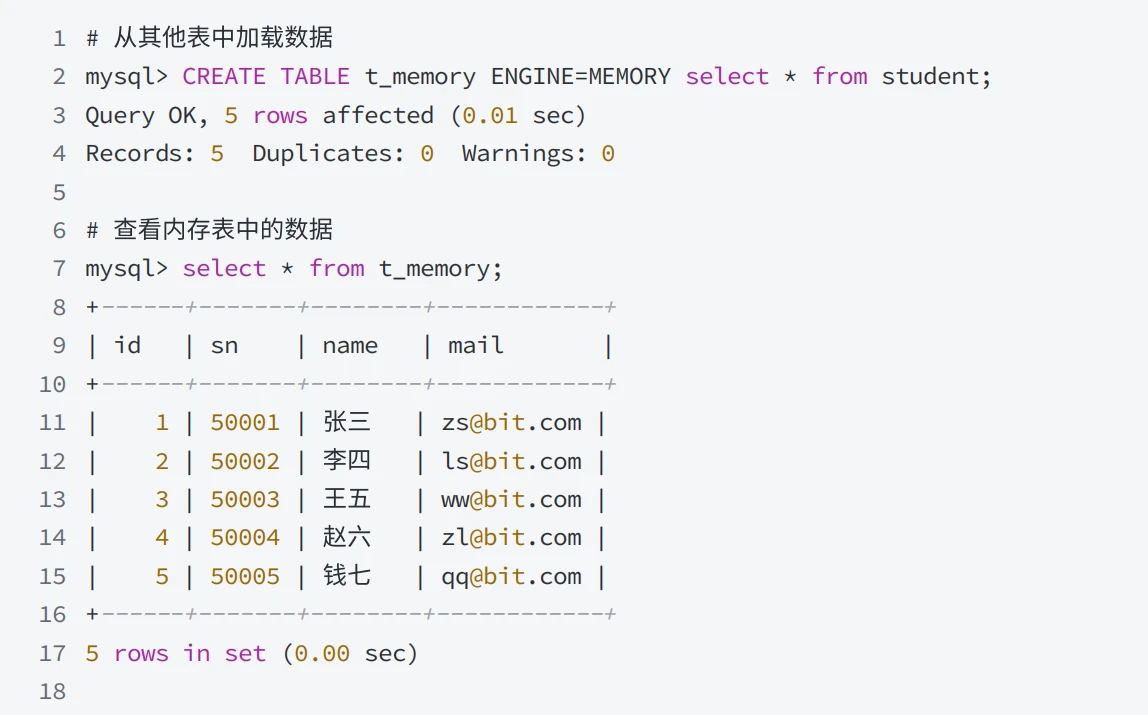
启动时填充 MEMORY 表的内容,可以使⽤ init_file 系统变量指定⼀个SQL⽂件,⽂件中可以编写⽤于初始化数据的SQL语句,例如: INSERT INTO … SELECT 或 LOAD DATA
5.3.4 内存管理
- 删除单⾏数据,不会回收内存,只有删除整个表时才会回收内存。当不需要内存表的内容时,要释放该表所使⽤的所有内存,可以执⾏ DELETE 或 TRUNCATE table 删除所有⾏,或者使⽤DROP table 删除表。如果要释放被删除⾏所使⽤的内存,使⽤ ALTER TABLE ENGINE=MEMORY 命令强制重建表;
- 表中⼀⾏数据所需的内存使⽤以下表达式计算:

ALIGN() 函数的作⽤:使⾏⻓度为 char 类型⼤⼩的精确倍数。 sizeof (char*) 在32位机器上是4,在64位机器上是8。
- max_heap_table_size 系统变量设置了内存表的最⼤⼤⼩限制,默认为16MB,要控制单个表的最⼤⼤⼩,在创建每个表之前设置该变量的 session 值。(不要改变全局的 max_heap_table_size 值,除⾮要明确设置所有客⼾端创建的内存表),下⾯的⽰例创建了两个内存表,最⼤⼤⼩分别为 1MB 和 2MB :

- 每次重启服务器内存表中的数据将被清空,内存表中的数据永远不会写⼊磁盘。
5.4 CSV存储引擎
CSV是逗号分隔值(Comma-Separated Values)的缩写,以纯⽂本形式存储表格数据。
5.4.1 创建CSV表
- 在MySQL 8.0中 InnoDB 是默认引擎,所以在创建表时需要指定 ENGINE=CSV

- 创建 CSV 表时,服务器会创建三个⽂件,其中以 .CSV 为扩展名的⽂件⽤于以逗号分隔值的格式保存数据;扩展名为 .CSM 的⽂件,⽤于存储表的状态和表中的⾏数;以 .sdi 为后缀的表信息描述⽂件(JSON格式)

5.4.2 CSV表中的数据
- 向表中插⼊数据

- 由于 .CSV 是⽂件格式的⽂件,我们在命令⾏查看⽂件内容如下:

CSV 格式可以被 Microsoft Excel 等电⼦表格应⽤程序读取和写⼊
5.4.3 CSV 表的修复和检查
- CSV 存储引擎⽀持使⽤ CHECK TABLE 和 REPAIR TABLE 语句来验证或修复损坏的 CSV表。
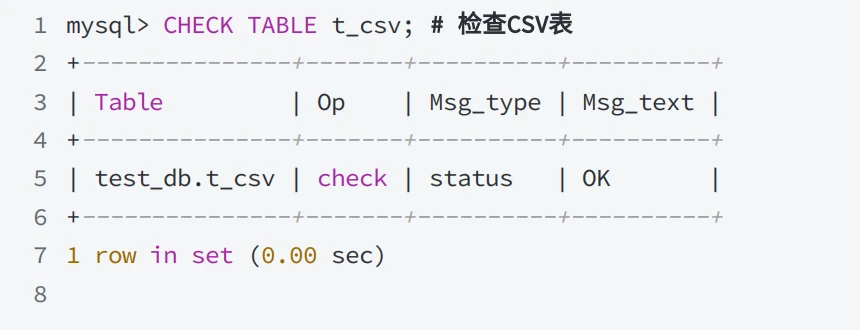
- 当⽤⽂本编辑器打开t_csv.CSV⽂件,并写⼊⼀条新数据,如下所⽰:

- 再次执⾏查询语句发现没有第三条数据,这是由于.CSM⽂件中并没有记录新增的⾏,可以使⽤REPAIR TABLE 语句修改表内容和CSM⽂件

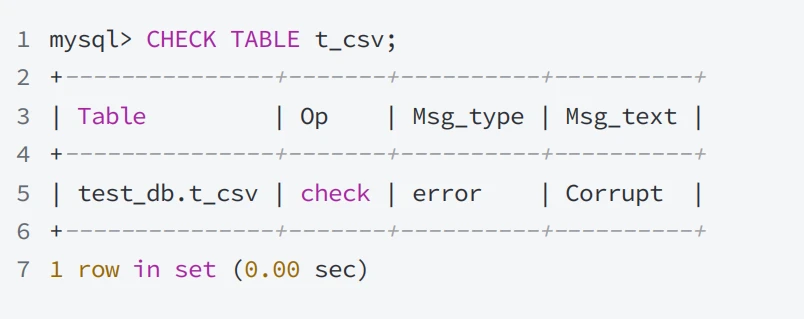
- 检查损坏的表时会返回错误,例如把t_csv.CSV⽂件的内容进⾏修改

- 运⾏检查语句提⽰错误
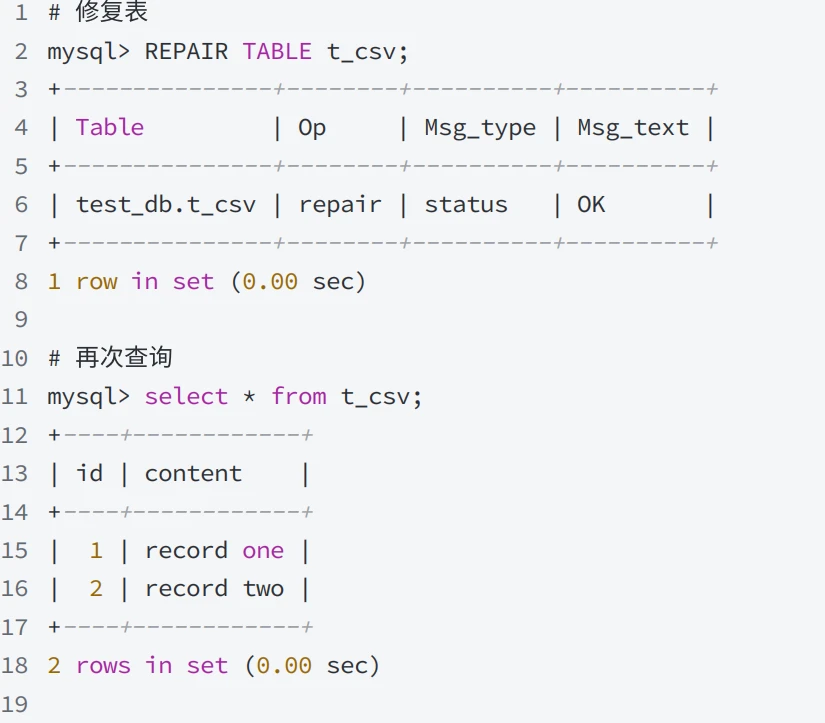
- 运⾏修复语句后,错误的数据被删除
注意:
在修复期时,只有从 CSV ⽂件第⼀⾏到第⼀个损坏⾏的⾏被复制到新表中,从第⼀个损坏的⾏到表末尾的所有其他⾏都会被删除,即使是有效数据。
5.4.4 CSV表限制
-
CSV 存储引擎不⽀持索引;
-
CSV 存储引擎不⽀持分区;
-
使⽤ CSV 存储引擎创建的表中的所有列都必须为 NOT NULL 。
5.5 ARCHIVE存储引擎
使⽤ ARCHIVE 存储引擎创建的表,存储⼤量不被索引的数据且占⽤空间很⼩,⼀般⽤于归档数据的存储。
5.5.1 ARCHIVE存储引擎的特性

- ⽀持 INSERT , REPLACE 和 SELECT ,但不⽀持 DELETE 和 UPDATE ;
- ⽀持列的 AUTO_INCREMENT 属性,该列可以有唯⼀约束,且⼿动指定的值不能⼩于该列的最⼤值;
- 不⽀持索引,在任何列上尝试建⽴索引都会报错;
- 插⼊时,数据将被压缩, ARCHIVE 引擎使⽤ zlib ⽆损数据压缩; INSERT 语句只是将数据写⼊压缩缓冲区并且根据需要刷新到磁盘,当执⾏ SELECT 时会强制刷新缓冲区;
- 检索时,按需要进⾏解压缩,不⽀持⾏缓存;
- SELECT操作执⾏全表扫描,找出当前查询的⾏,并读取⾏数;
- 使⽤⾏级锁定
- 不⽀持表分区
5.5.2 创建ARCHIVE表
- 在MySQL 8.0中 InnoDB 是默认引擎,所以在创建表时需要指定 ENGINE=ARCHIVE
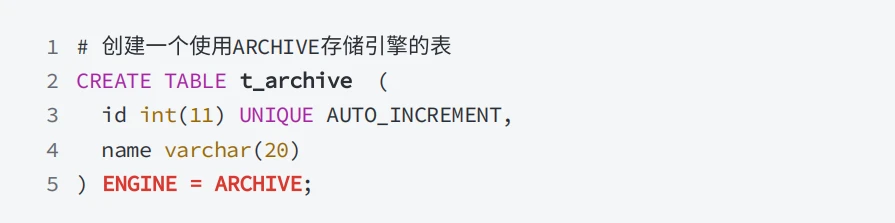
- 创建 ARCHIVE 表会根据表名⽣成两个不同后缀名⽂件,分别是以 .ARZ 为后缀的数据⽂件,以 .sdi 为后缀的表信息描述⽂件(JSON格式), .ARN ⽂件在优化操作期间可能会出现。
5.6 BLACKHOLE存储引擎
BLACKHOLE 存储引擎就像⼀个"⿊洞",接受数据,但不存储数据,检索时总是返回⼀个空结果。
5.6.1 BLACKHOLE存储引擎的特性
- BLACKHOLE 表不会存储任何数据,但如果启⽤了基于语句的⼆进制⽇志记录,则会记录 SQL 语句并将其复制到副本服务器
- ⽀持索引;
- 不⽀持分区;
5.6.2 BLACKHOLE存储引擎的⽤途
- 验证转储⽂件语法
- 通过⽐较启⽤和不启⽤⼆进制⽇志记录的性能,测量⼆进制⽇志记录的开销;
- 本质上是⼀个 "⽆操作"的存储引擎,可⽤于查找与存储引擎本⾝⽆关的性能瓶颈
5.6.3 创建BLACKHOLE表
- 在MySQL 8.0中 InnoDB 是默认引擎,所以在创建表时需要指定 ENGINE=BLACKHOLE
- 创建 BLACKHOLE 表时,服务器会在全局数据字典中创建表定义并⽣成 .sdi 为后缀的表信息描述⽂件;

5.7 MERGE存储引擎
MERGE存储引擎,也称为MRG_MyISAM引擎,允许MySQL DBA或开发⼈员在逻辑上将⼀系列相同的MyISAM表分组,并将它们作为⼀个对象引⽤。适⽤于VLDB(Very Large Data Bases)环境,如数据仓库。这⾥的相同表⽰所有表中的列都有相同的数据类型和索引信息。⽰意图如下:

5.7.1 创建MERGE表
- 在MySQL 8.0中 InnoDB 是默认引擎,所以在创建表时需要指定 ENGINE=MERGE
- 创建MERGE表必须指定 UNION=(list-of-tables) 选项,表⽰要使⽤哪些MyISAM表;还可以通过指定 INSERT_METHOD 选项来控制如何对MERGE表进⾏插⼊操作, FIRST 或 LAST 值分别表⽰在第⼀个或最后⼀个基础表中进⾏插⼊,如果没有指定 INSERT_METHOD 选项,或者指定它的值为 NO ,那么在 MERGE 表中执⾏插⼊将会报错;

- 创建 MERGE 表时,会在磁盘上创建⼀个 .mrg ⽂件,其中包含了基础MyISAM表的名称。MERGE的表格式存储在MySQL数据字典中; .sdi 为后缀的表信息描述⽂件;

5.7.2 操作MERGE表
- 基础表中的 id 列作为 PRIMARY KEY 索引,但在MERGE表中并不作为主键,但是可以被索引。因为 MERGE 表不能对基础表集强制唯⼀性,类似的,基础表中具有 UNIQUE 索引的列可以在MERGE 表中被索引,但不能作为唯⼀约束,查询⽰例:
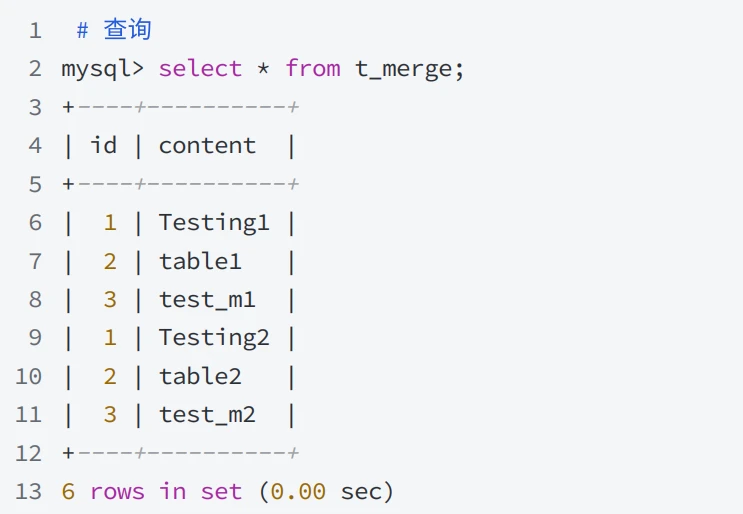
-
要将MERGE表重新映射到不同的MyISAM基础表集合,您可以使⽤以下⽅法之⼀:
- 删除MERGE表并重新创建;
- 使⽤ ALTER TABLE tbl_name UNION=(…) 修改基础表的集合;
ALTER TABLE…UNION=() 列表为空时,表⽰删除所有基础表
-
使⽤ DROP TABLE 只会删除MERGE表定义,基础MyISAM表不受影响。
关于MERGE表的替代⽅案可以使⽤表分区,可以⽀持主键索引,唯⼀索引,全⽂索引等
5.8 FEDERATED 存储引擎
- 默认不⽀持,可以在启动时通过命令⾏选项 --federated 或选项⽂件的配置来启⽤

- 允许访问远程MySQL数据库中的数据,在不使⽤复制或集群技术的情况下, FEDERATED 存储引擎可以实现对远程MySQL数据库中数据的访问,以多个物理服务器为基础创建⼀个逻辑数据库,当查询 FEDERATED 表时,将会从远程数据库获取数据,⾮常适合分布式或数据集市环境。如图所⽰:

5.8.1 创建FEDERATED表
- 本地配置⽂件中的 [mysqld] 节点下加⼊ federated=1 来启⽤ FEDERATED 引擎,之后重启MySQL服务


- 重启本地数据库服务并查看 FEDERATED 引擎是否启⽤

- 在远程服务器上为⽤⼾加⼊远程访问权限,安全性与权限管理专题详细介绍
- 在MySQL 8.0中 InnoDB 是默认引擎,所以在创建表时需要指定 ENGINE=FEDERATED ;
- 创建 FEDERATED 表时,本地的表定义与远程服务器的表定义相同,但数据存储在远程服务器上;
- 本地表定义中使⽤ CONNECTION 连接字符串指向远程表的连接字符串;

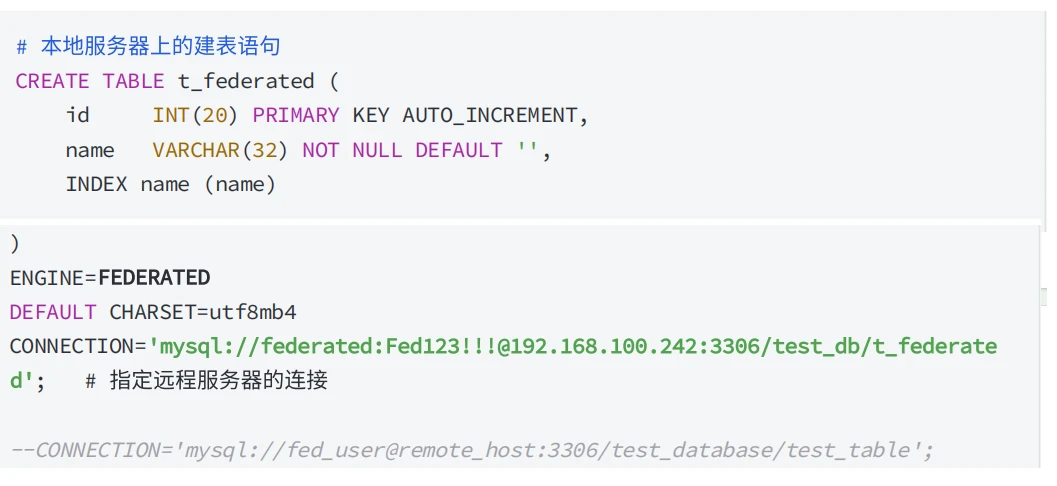
连接字符串的格式:
scheme😕/user_name[:password]@host_name[:port_num]/db_name/tbl_name
scheme : 连接协议,⽬前只⽀持mysql;
user_name : ⽤于连接远程服务器的⽤⼾名,注意:这个⽤⼾在远程服务器已创建,并授予了相应
的操作权限;
password :⽤⼾的密码;
host_name :远程服务器的IP地址;
port_num :远程服务器MySQL服务的端⼝号;
db_name : 远程表所在的数据库名;
tbl_name :远程表名,本地表名与远程表名可以不同,但建议保持⼀致。
- 不会⽣成数据⽂件,表定义在数据字典中,⽣成 .sdi 为后缀的表信息描述⽂件(JSON格式)
- 建表成功后,对本地表的增删改查和操作远程表⼀样
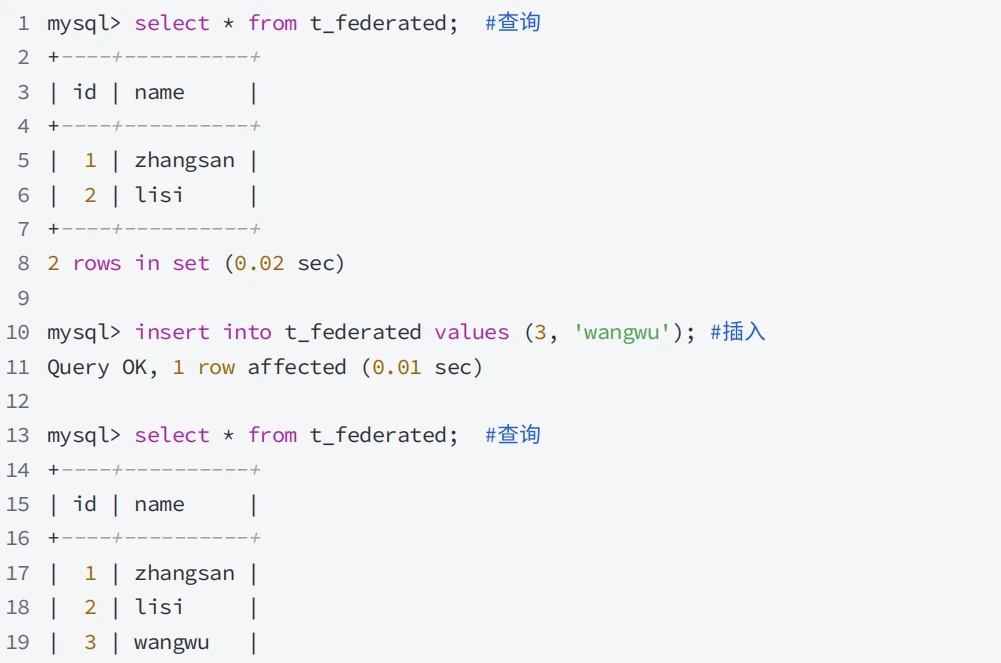
5.8.2 FEDERATED表注意事项
-
远程服务器必须是MySQL服务器;
-
使⽤ CONNECTION 字符串时,密码中不能使⽤"@"字符;
-
DROP TABLE 只删除本地表,不删除远程表;
-
不⽀持事务
5.9 EXAMPLE 存储引擎
- EXAMPLE 存储引擎什么也不做,它的存在⽬的是为开发⼈员说明如何开始编写⼀个新的存储引擎,是MySQL源代码中的⼀个⽰例。
- 不⽀持索引和表分区
- 当创建⼀个 EXAMPLE 表时,不会在磁盘上创建任何⽂件,表中不能存储任何数据,查询时始终返回⼀个空结果。

5.10 其他存储引擎
其他存储引擎或⾃定义存储引擎可以从实现了Custom storage Engine接⼝的第三⽅和社区获取,Custom storage Engine接⼝是MySQL提供⼀的套API,⾄于如何开发⼀个存储引擎我们在这⾥不做过多讨论。
5.11 不同存储引擎的特性
