【Linux】MyCat分库分表|读写分离
Mycat-server-1.6.7.5-release-20200422133810-linux.tar.gz
目前流行的产品
开源分布式数据库中间件:Mycat 和 ShardingSphere(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar 3 款产品)。
⾸先给出它们的功能比较:
| MyCat | Sharding -JDBC | Sharding -Proxy | Sharding -Sidecar | |
|---|---|---|---|---|
| 官方网站 | 官方网站 | 官方网站 | 官方网站 | 官方网站 |
| 源码地址 | GitHub | GitHub | GitHub | GitHub |
| 官方文档 | MyCat权威指南 | 官方文档 | 官方文档 | 概览 :: ShardingSphere |
| 开发语言 | Java | Java | Java | Java |
| 开源协议 | GPL-2.0/GPL -3.0 | Apache-2.0 | Apache-2.0 | Apache-2.0 |
| 数据库 | MySQL Oracle SQLServer PostgreSQL DB2 MongoDB SequoiaDB | MySQL Oracle SQLServer PostgreSQL 任何遵循SQL92标准的数据库 | MySQL/ PostgreSQL | MySQL/ PostgreSQL |
| 连接数 | 低 | 高 | 低 | 高 |
| 应用语言 | 任意 | Java | 任意 | 任意 |
| 代码入侵 | 无 | 需要修改代码 | 无 | 无 |
| 性能 | 损耗略高 | 损耗低 | 损耗略低 | 损耗低 |
| 无中心化 | 否 | 是 | 否 | 是 |
| 静态入口 | 有 | 无 | 有 | 无 |
| 管理控制台 | MyCat-Web | Sharding-UI | Sharding-UI | Sharding-UI |
| 分库分表 | 单库多表/多库单表 | √ | √ | √ |
| 多租户方案 | √ | – | – | – |
| 读写分离 | √ | √ | √ | √ |
| 分片策略定制化 | √ | √ | √ | √ |
| 分布式主键 | √ | √ | √ | √ |
| 标准化事务接口 | √ | √ | √ | √ |
| XA强一致性事务 | √ | √ | √ | √ |
| 柔性事务 | – | √ | √ | √ |
| 配置动态化 | 开发中 | √ | √ | √ |
| 编排治理 | 开发中 | √ | √ | √ |
| 数据脱敏 | – | √ | √ | √ |
| 可视化链路追踪 | – | √ | √ | √ |
| 弹性伸缩 | 开发中 | 开发中 | 开发中 | 开发中 |
| 多节点操作 | 分页 去重 排序 分组 聚合 | 分页 去重 排序 分组 聚合 | 分页 去重 排序 分组 聚合 | 分页 去重 排序 分组 聚合 |
| 跨库关联 | 跨库 2表 Join ER Join 基于caltlet的多表Join | – | – | – |
| IP白名单 | √ | – | – | – |
| SQL黑名单 | √ | – | – | – |
| 存储过程 | √ | – | – | – |
MyCat介绍
Mycat 是基于阿⾥ Cobar 演变⽽来的⼀款开源分布式数据库中间件,是⼀个实现了MySQL协议的Server。前端⽤户可以把它看做是⼀个数据库代理,用MySQL 客户端⼯具和命令⾏访问;而其后端可以用MySQL 原⽣(Native)协议与多个 MySQL 服务器通信,也可以⽤ JDBC 协议与⼤多数主流数据库服务器通信。
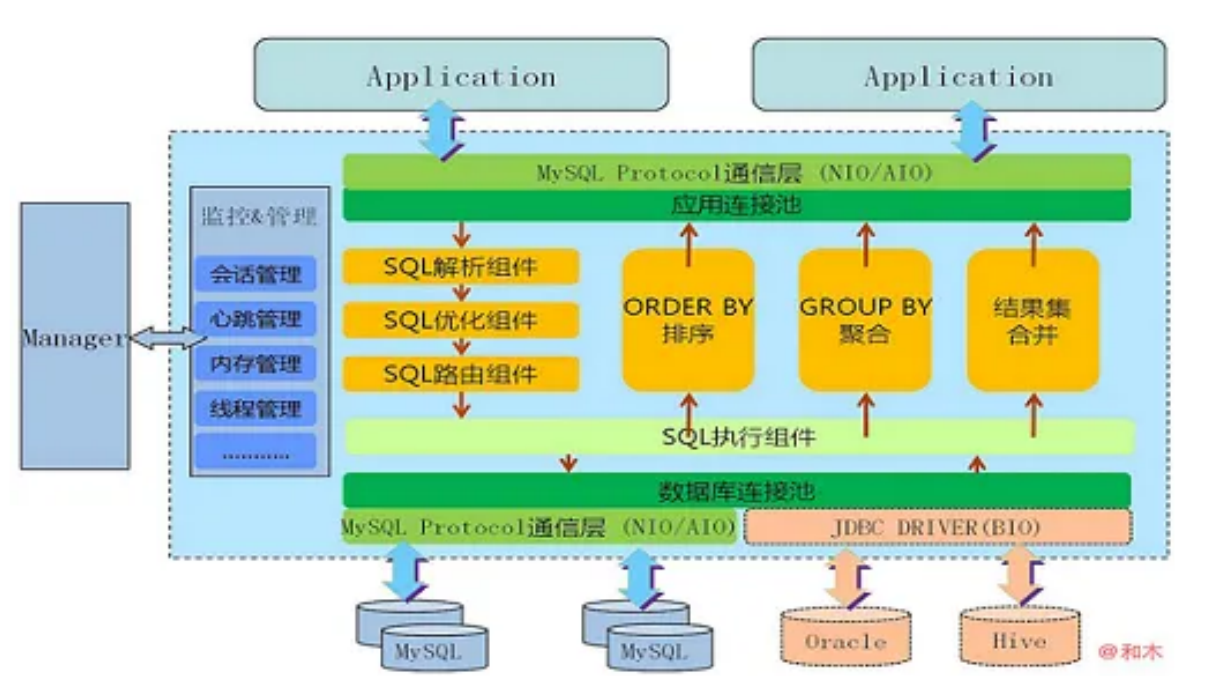
对于 DBA,MyCat 就是 MySQL Server,⽽ MyCat 后⾯连接的 MySQL Server 就好像是 MySQL 的存储引擎,如 InnoDB、MyISAM 等,因此 Mycat 本身并不存储数据,数据是在后端的 MySQL 上存储 的,数据可靠性以及事务等都是由 MySQL 保证的。
对于软件⼯程师,MyCat 是⼀个近似等于 MySQL 的数据库服务器。你可以⽤连接 MySQL 的⽅式去连接 MyCat(除了端⼝不同,MyCat 默认端⼝是 8066 ⽽⾮ 3306),⼤多数情况下可以⽤你熟悉的对象映射框架使⽤ MyCat。但建议对于分⽚表,尽量使⽤基础的 SQL 语句,因为这样能达到最佳性能,特别是⼏千万甚⾄⼏百亿条记录的情况下。
对于架构师,MyCat 是⼀个强⼤的数据库中间件;不仅仅可以⽤作读写分离、以及分表分库、容灾备份,⽽且可以⽤于多租户应⽤开发、云平台基础设施。让你的架构具备很强的适应性和灵活性,借助于即将发布的 MyCat 智能优化模块,系统的数据访问瓶颈和热点⼀⽬了然,根据这些统计分析数据,你可以⾃动或⼿⼯调整后端存储,将不同的表映射到不同存储引擎上,⽽整个应⽤的代码⼀⾏也不⽤改变。
MyCat ⽬前的发布版本为 1.6,正在开发 Mycat 2.0。提供的关键特性包括:
- ⽀持 SQL92 标准;
- ⽀持MySQL、Oracle、DB2、SQL Server、PostgreSQL 等 DB 的常⻅ SQL 语法;
- 遵守 MySQL 原⽣协议,跨语⾔,跨平台,跨数据库的通⽤中间件代理;
- 基于⼼跳的⾃动故障切换,⽀持读写分离,⽀持 MySQL 主从,以及 Galera Cluster 集群;
- ⽀持 Galera for MySQL 集群,Percona Cluster 或者 MariaDB cluster;
- 基于 Nio 实现,有效管理线程,解决⾼并发问题;
- ⽀持数据的多⽚⾃动路由与聚合,⽀持 sum、count、max 等常⽤的聚合函数,⽀持跨库分⻚;
- ⽀持单库内部任意 join,⽀持跨库 2表 join,甚⾄基于 caltlet 的多表 join;
- ⽀持通过全局表,ER 关系的分⽚策略,实现了⾼效的多表 join 查询;
- ⽀持多租户⽅案; ⽀持分布式事务(弱 xa);
- ⽀持 XA 分布式事务(1.6.5);
- ⽀持全局序列号,解决分布式下的主键⽣成问题;
- 分⽚规则丰富,插件化开发,易于扩展;
- 强⼤的 web,命令⾏监控;
- ⽀持前端作为 MySQL 通⽤代理,后端 JDBC ⽅式⽀持 Oracle、DB2、SQL Server 、 MongoDB 、巨杉;
- ⽀持密码加密;
- ⽀持服务降级;
- ⽀持 IP ⽩名单;
- ⽀持 SQL ⿊名单、SQL 注⼊攻击拦截;
- ⽀持 prepare 预编译指令(1.6);
- ⽀持⾮堆内存(Direct Memory)聚合计算(1.6);
- ⽀持 PostgreSQL 的 native 协议(1.6);
- ⽀持 mysql 和 Oracle 存储过程,out 参数、多结果集返回(1.6);
- ⽀持 zookeeper 协调主从切换、zk 序列、配置 zk 化(1.6);
- ⽀持库内分表(1.6);
- 集群基于 ZooKeeper 管理,在线升级,扩容,智能优化,⼤数据处理(2.0开发版)。
总结
Mycat 和 ShardingSphere 都是⾮常流⾏的开源分布式数据库中间件,各⾃具有⼀些独特的功能,也有很多企业成功应⽤的案例。通过个⼈⽐较这两者的官⽅⽂档、社区活跃度等信息,⽬前 Apache ShardingSphere 体系更加完善,社区更加活跃。这两者都是国⼈开源产品中的佼佼者, 另外,还有⼀款值得关注的分布式数据库中间件 DBLE(专注于 MySQL),可以看做 Mycat 增强版。
高可用性与读写分离
业务数据分级存储保障
100亿级大表水平分片,集群进行计算
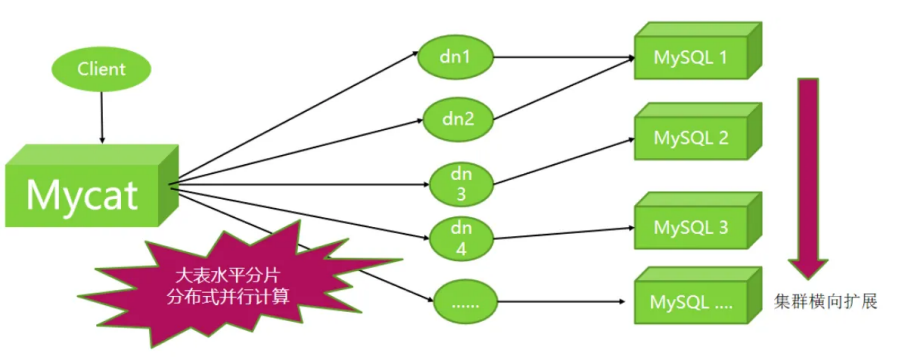
数据库路由器:大大提升数据库服务能力
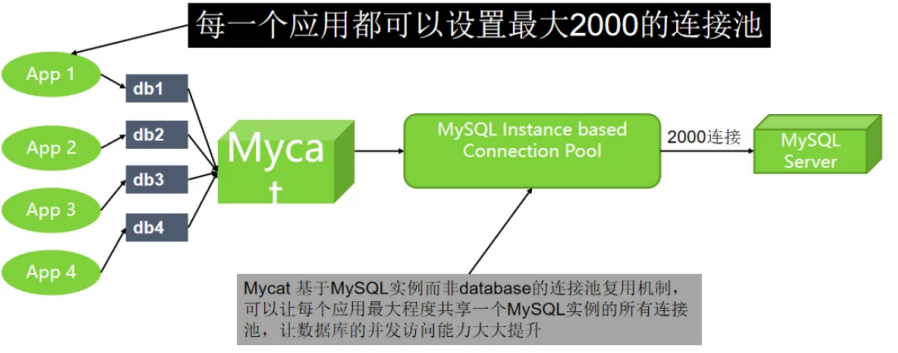
数据库路由器:整合多种数据源
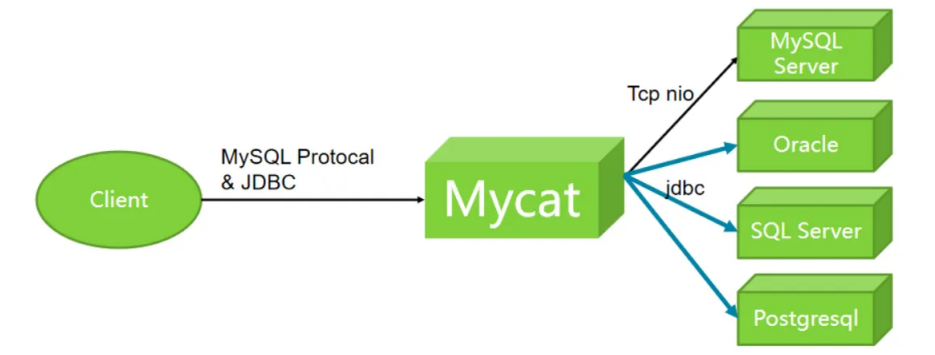
分片策略
根据表数据量判断是否需要切分
确保切分后单分⽚表数据量为1000W左右
根据业务的情况选择合适的分片字段
最频繁的或者最重要的查询条件
有关联关系的表配置相同分片规则
****ER思想,为了应⽤join等复杂sql
⼀对多对应关系⼀般按多的那⼀⽅切分
如果配置类数据,更新频率比较少
考虑全局表
当前活跃数据分片
- 数据规模可以预期
- 数据平滑增⻓或者基本不变
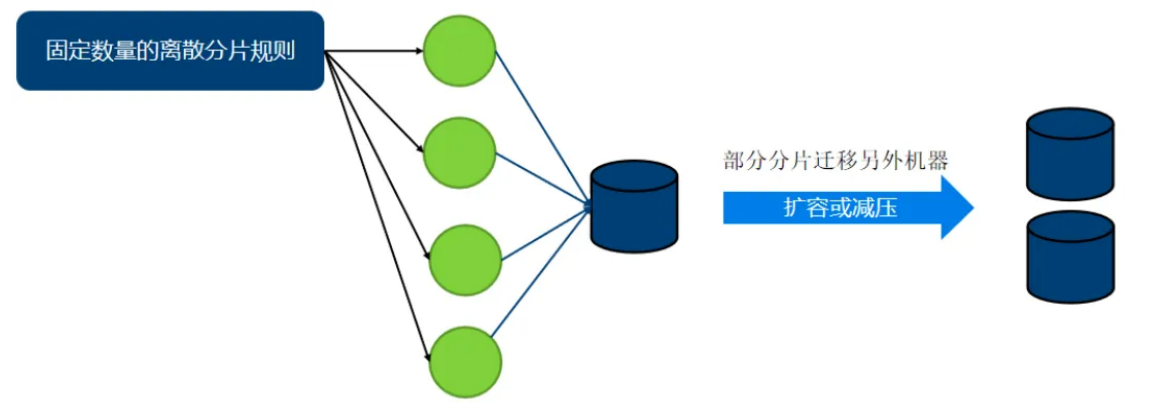
历史非活跃数据
- 数据规模可以预期
- 数据平滑增⻓或者基本不变
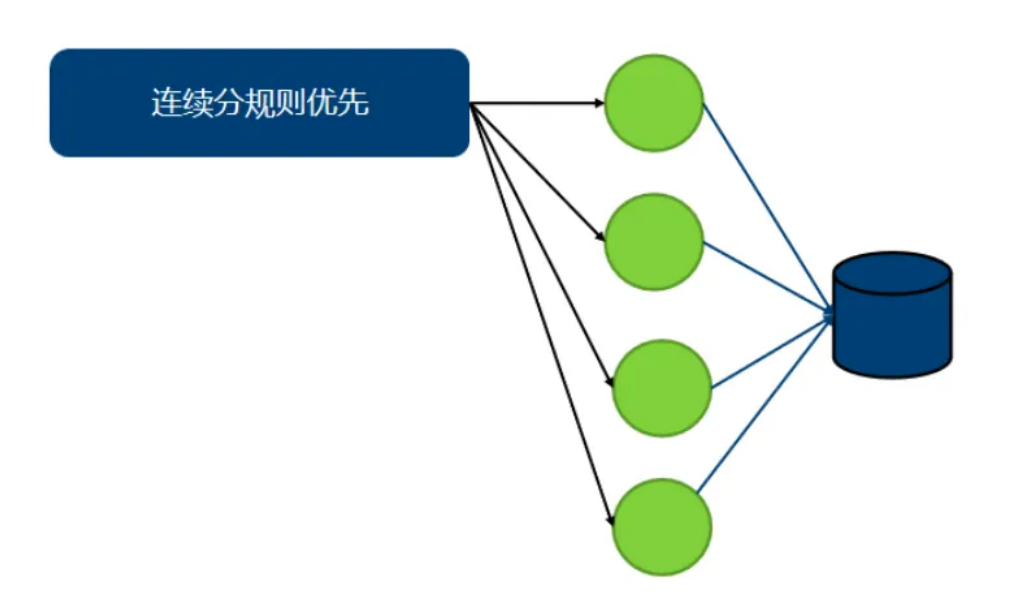
分片注意
需要考虑扩容数据迁移问题
- 范围取模类不需要迁移
- 哈希类需要迁移
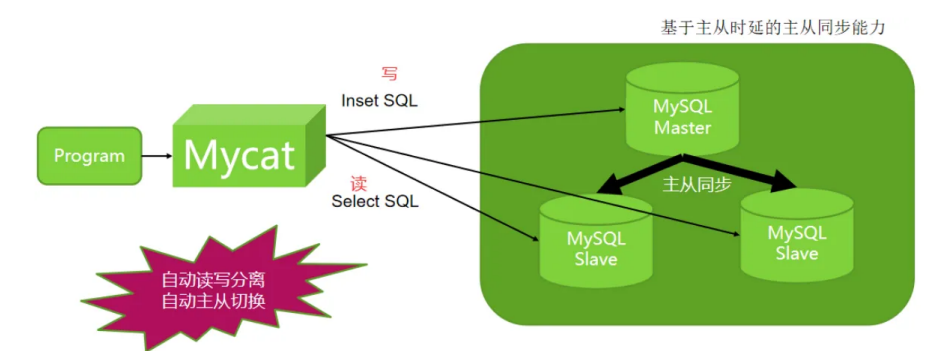
MySQL读写分离方案
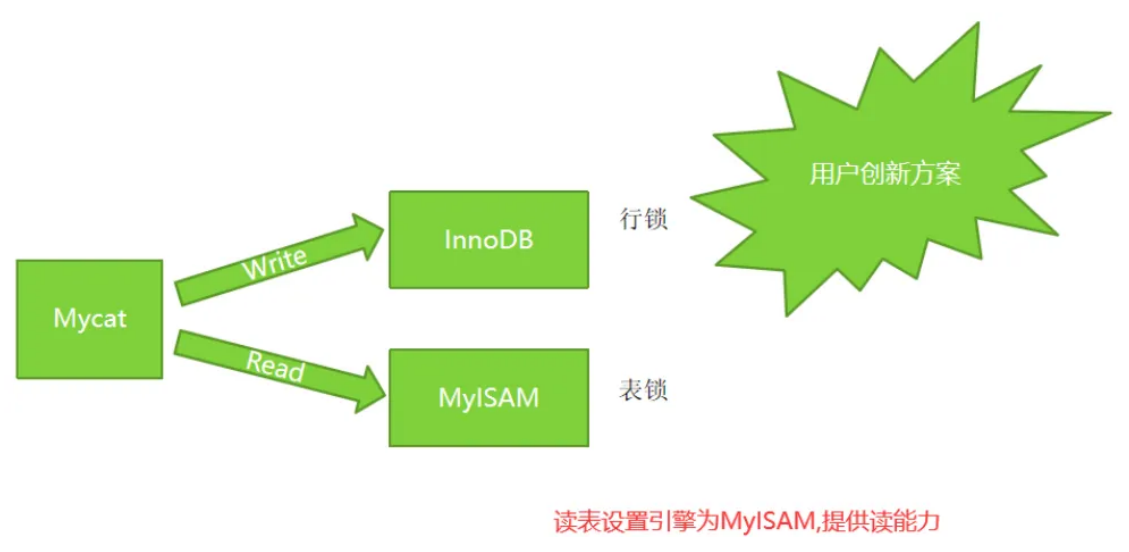
InnoDB VS MyISAM
InnoDB
- InnoDB 中不保存表的具体⾏数,也就是说,执⾏select count(*) from table时,InnoDB要扫描⼀
遍整个表来计算有多少⾏,但是MyISAM只要简单的读出保存好的⾏数即可。 - 注意:当count(*)语句包含 where条件时,两种表的操作是⼀样的。
- Innodb ⽀持事务处理与外键和⾏级锁,⽽MyISAM不⽀持
MyISAM的优势
- 读性能⽐Innodb强不少
- MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使⽤率就对应提⾼了不少。能加载更多
索引,⽽Innodb是索引和数据是紧密捆绑的,没有使⽤压缩从⽽会造成Innodb⽐MyISAM体积庞⼤
不小。 - 总结
a. 索引省内存
b. 更快读性
不同的表用不同的引擎
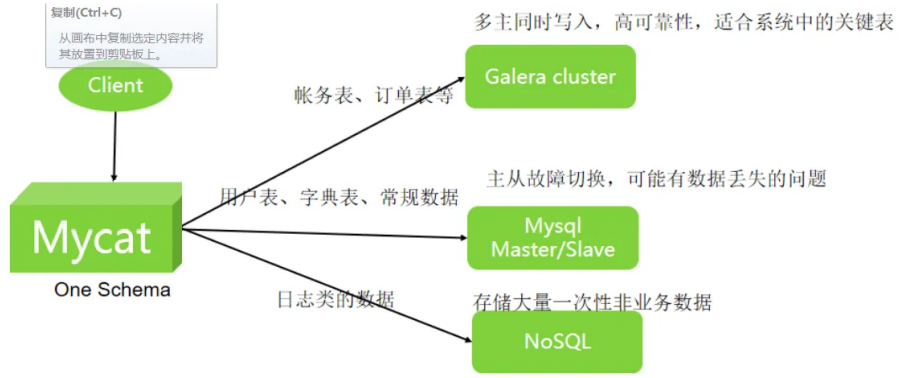
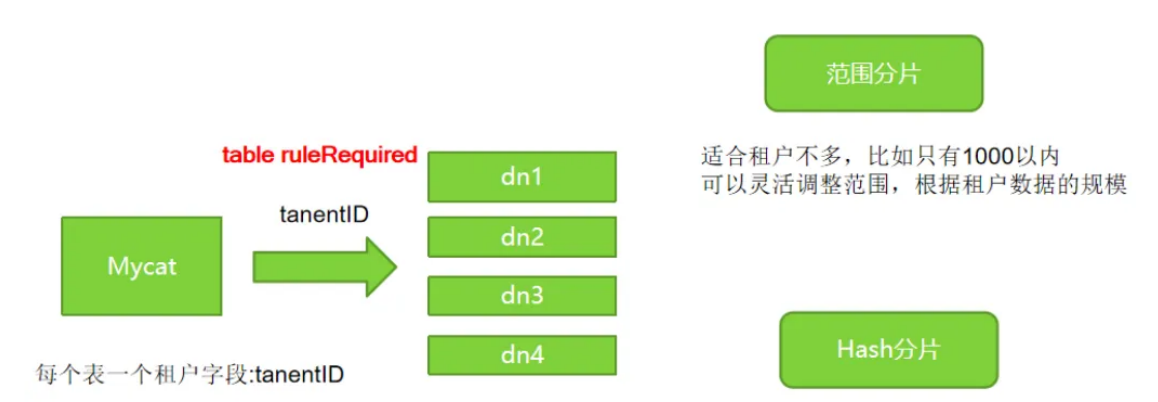
多租户方案
- 单租户就是传统的给每个租户独⽴部署⼀套web + db 。
- 由于租户越来越多,整个web部分的机器和运维成本都⾮常⾼,因此需要改进到所有租户共享 ⼀套web的模式(db部分暂不改变)。也就是saas系统。
案例
/*!mycat : schema = test_01 */ sql ;
- 在⽤户登录时,在线程变量(ThreadLocal)中记录租户的id
- 修改jdbc的实现:在提交sql时,从ThreadLocal中获取租户id,通过租户id获取分⽚节点
test_01,将test_01添加到sql注释注释中。
/*!mycat : schema = test_01 */ sql ;
分表大数据

安装MyCat
需要安装数据库和Java环境
此处省略mysql和java安装
使用Mycat
# 启动前需要创建logs⽬录
mkdir /usr/local/mycat/logs
cd /usr/local/mycat/bin
# 启动
./mycat start
# 重启
./mycat restart
#停⽌
./mycat stop
#查看状态
./mycat status
#控制台
./mycat console
配置server.xml⽂件
/use/local/mycat/conf/server.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="charset">utf8mb4</property>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="ignoreUnknownCommand">0</property><!-- 0遇上没有实现的报文(Unknown command:),就会报错、1为忽略该报文,返回ok报文。
在某些mysql客户端存在客户端已经登录的时候还会继续发送登录报文,mycat会报错,该设置可以绕过这个错误-->
<property name="useHandshakeV10">1</property>
<property name="removeGraveAccent">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sqlExecuteTimeout">300</property> <!-- SQL 执行超时 单位:秒-->
<property name="sequenceHandlerType">2</property>
<!--<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
INSERT INTO `travelrecord` (`id`,user_id) VALUES ('next value for MYCATSEQ_GLOBAL',"xxx");
-->
<!--必须带有MYCATSEQ_或者 mycatseq_进入序列匹配流程 注意MYCATSEQ_有空格的情况-->
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<property name="sequenceHanlderClass">io.mycat.route.sequence.handler.HttpIncrSequenceHandler</property>
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequenceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="dataNodeIdleCheckPeriod">300000</property> 5 * 60 * 1000L; //连接空闲检查
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">0</property>
<!--
单位为m
-->
<property name="memoryPageSize">64k</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
<!-- XA Recovery Log日志路径 -->
<property name="XARecoveryLogBaseDir">./</property>
<!-- XA Recovery Log日志名称 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property>
<!--如果为0的话,涉及多个DataNode的catlet任务不会跨线程执行-->
<property name="parallExecute">0</property>
</system>
<!-- 全局SQL防火墙设置 -->
<!--白名单可以使用通配符%或着*-->
<!--例如<host host="127.0.0.*" user="root"/>-->
<!--例如<host host="127.0.*" user="root"/>-->
<!--例如<host host="127.*" user="root"/>-->
<!--例如<host host="1*7.*" user="root"/>-->
<!--这些配置情况下对于127.0.0.1都能以root账户登录-->
<!--
<firewall>
<whitehost>
<host host="1*7.0.0.*" user="root"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
<!--No MyCAT Database selected 错误前会尝试使用该schema作为schema,不设置则为null,报错 -->
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
<property name="defaultSchema">TESTDB</property>
</user>
</mycat:server>
分片
逻辑库
- 管理多个物理库,是对多个物理库的抽象。
- 在Mycat中逻辑库在{MYCAT_HOME}/conf/schema.xml ⽤< schema > 标签定义
逻辑表
- 管理多个物理表,是对多个物理表的抽象。包含下⾯4种类型
a. 分⽚表
b. 全局表
c. ER表
d. ⾮分⽚
取模
rule.xml
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- 节点数量 -->
<property name="count">3</property>
</function>
说明
- 根据id与count(你的结点数)进⾏求模
- 在批量插⼊时需要频繁切换数据源
优点:
利⽤的写的负载均衡效果,写⼊速度很快
缺点:
批量写⼊,失败后事务的回滚有难度
批量写⼊,需要频繁切换数据源
案例
批量写⼊100数据,节点分布在3个库上(db1,db2,db3),第99 条失败了,执⾏数据的回滚, 跨数据库的回滚,⾮常难,很耗费性能。
测试步骤
测试期望
添加数据时,id%3=
- 0:插⼊db1数据库
- 1:插⼊db2数据库
- 2:插⼊db3数据库
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 逻辑库 TESTDB-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!--
逻辑表 sys_user,存在3个数据节点中,分别是dn1,dn2,dn3
-->
<!-- 枚举分⽚测试 -->
<table name="sys_user" dataNode="dn1,dn2,dn3" rule="sharding-by-intfile" />
<!-- 取模 分⽚测试 -->
<table name="sys_dept" dataNode="dn1,dn2,dn3" rule="mod-long" />
</schema>
<!--
数据节点,因为dataHost都是localhost1,所有dataHost主机有3个库,分别db1,db2,db
3
-->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--
数据库最⼤连接是1000,最⼩连接是10,
balance="0" 不开启读写分离机制,所有读操作都发送到当前可⽤的writeHost上
writeType="0" :所有写操作发送到配置的第⼀个 writeHost,第⼀个挂了切到还⽣存的第⼆
个writeHost
switchType="1":主从切换策略,⾃动切换-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" sla
veThreshold="100">
<!-- ⼼跳检测语句 -->
<heartbeat>select user()</heartbeat>
<!-- M1主节点 -->
<writeHost host="M1" url="192.168.187.130:3307" user="root" password="root">
<!-- 从节点 -->
<readHost host="M1S1" url="192.168.187.130:3308" user="root" password="root" />
<readHost host="M1S2" url="192.168.187.130:3309" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
重启Mycat
/usr/local/mycat/bin/mycat restart
测试
创建表
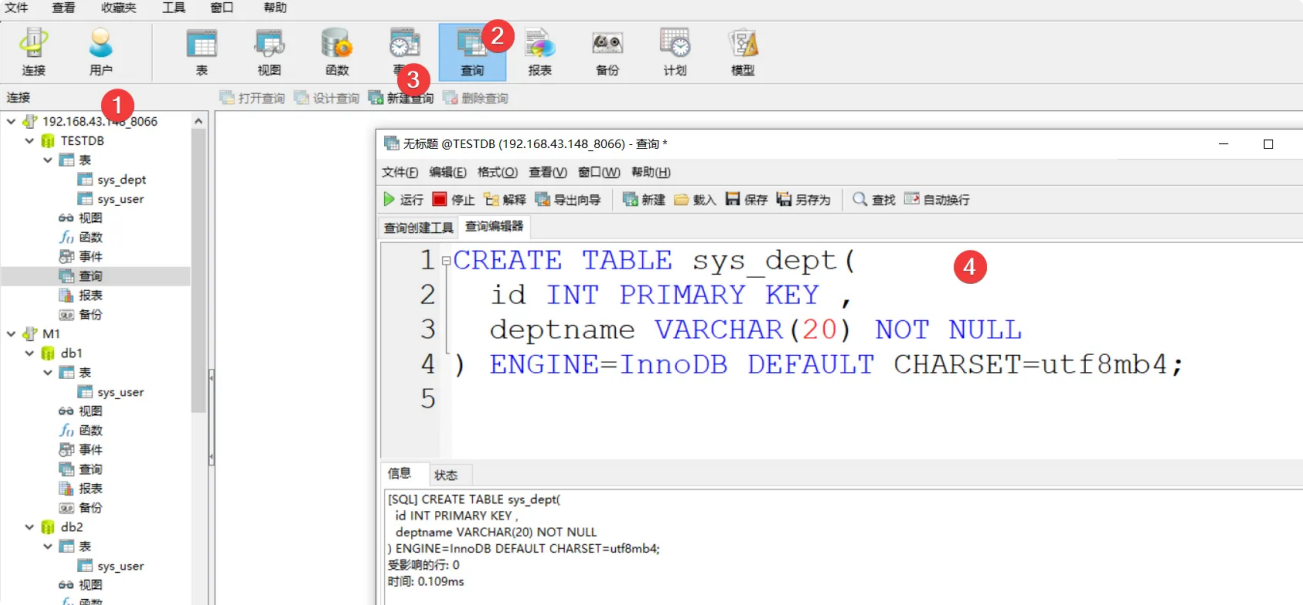
CREATE TABLE sys_dept(
id INT PRIMARY KEY ,
deptname VARCHAR(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
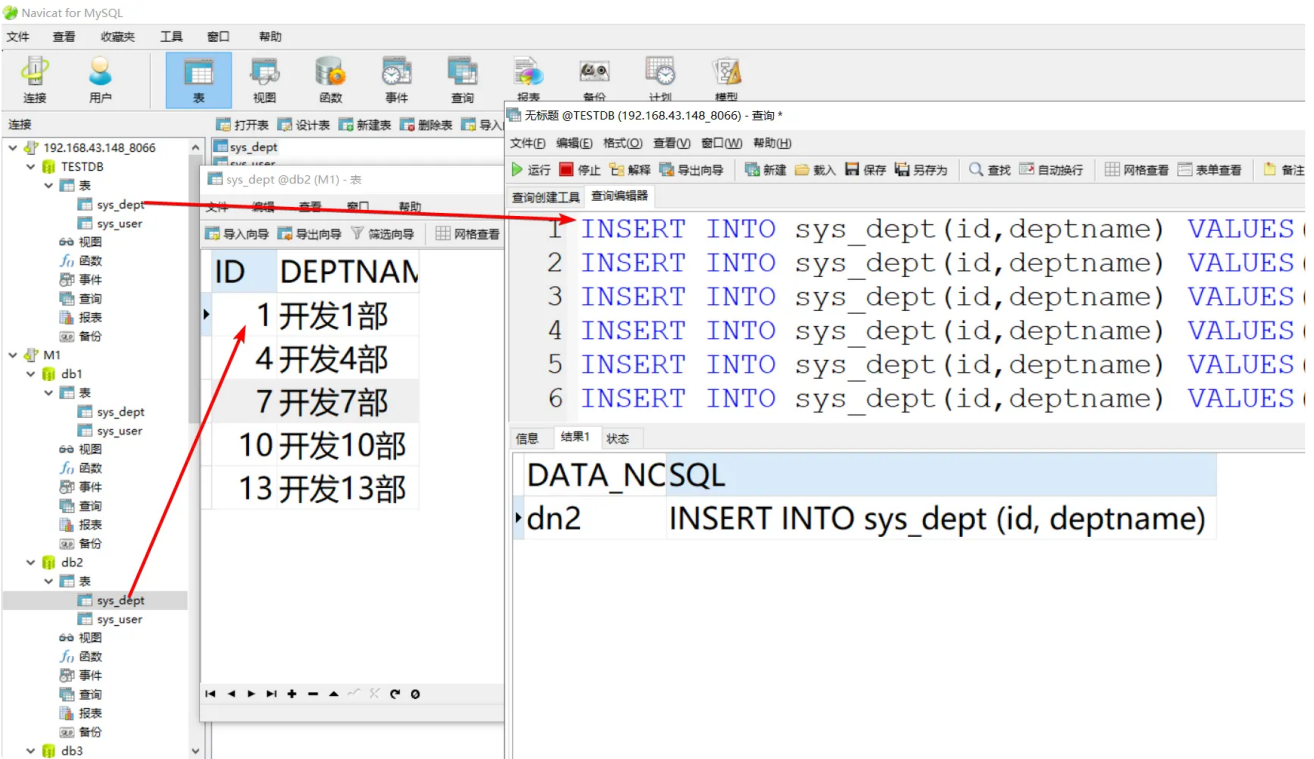
插⼊测试数据
INSERT INTO sys_dept(id,deptname) VALUES(1,'开发1部');
INSERT INTO sys_dept(id,deptname) VALUES(2,'开发2部');
INSERT INTO sys_dept(id,deptname) VALUES(3,'开发3部');
INSERT INTO sys_dept(id,deptname) VALUES(4,'开发4部');
INSERT INTO sys_dept(id,deptname) VALUES(5,'开发5部');
INSERT INTO sys_dept(id,deptname) VALUES(6,'开发6部');
INSERT INTO sys_dept(id,deptname) VALUES(7,'开发7部');
INSERT INTO sys_dept(id,deptname) VALUES(8,'开发8部');
INSERT INTO sys_dept(id,deptname) VALUES(9,'开发9部');
INSERT INTO sys_dept(id,deptname) VALUES(10,'开发10部');
INSERT INTO sys_dept(id,deptname) VALUES(11,'开发11部');
INSERT INTO sys_dept(id,deptname) VALUES(12,'开发12部');
INSERT INTO sys_dept(id,deptname) VALUES(13,'开发13部');
INSERT INTO sys_dept(id,deptname) VALUES(14,'开发14部');
INSERT INTO sys_dept(id,deptname) VALUES(15,'开发15部');
EXPLAIN INSERT INTO sys_dept(id,deptname) VALUES(1,'开发1部');
固定哈希
rule.xml
<tableRule name="rule2">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<!-- 分⽚个数列表 -->
<property name="partitionCount">2,1</property>
<!-- 分⽚范围列表 -->
<property name="partitionLength">256,512</property>
</function>
说明
- 规则类似于⼗进制的求模运算,区别在于⼆进制的操作,是取id的⼆进制低10位,即id⼆进制
&1111111111。 - 实际效果与求模范围类似。此算法根据⼆进制则可能会分到连续的分⽚
分区长度
默认为最⼤2^10=1024 ,即最⼤⽀持1024分区
约束
1024 = sum((count[i]*length[i]))
测试步骤
测试期望:
希望将数据⽔平分成3份,前两份各占25%,第三份占50%。
修改schema.xml 配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" >
<table name="sys_user" dataNode="dn1,dn2,dn3" rule="sharding-by-intfile" />
<table name="sys_dept" dataNode="dn1,dn2,dn3" rule="mod-long" />
<table name="sys_test1" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<!-- 按照hash算法 -->
<table name="sys_test2" dataNode="dn1,dn2,dn3" rule="rule2" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="192.168.43.148:3307" user="root" password="root">
<readHost host="M1S1" url="192.168.43.148:3308" user="root" password="root" />
<readHost host="M1S2" url="192.168.43.148:3309" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
重启Mycat
/usr/local/mycat/bin/mycat restart
创建表
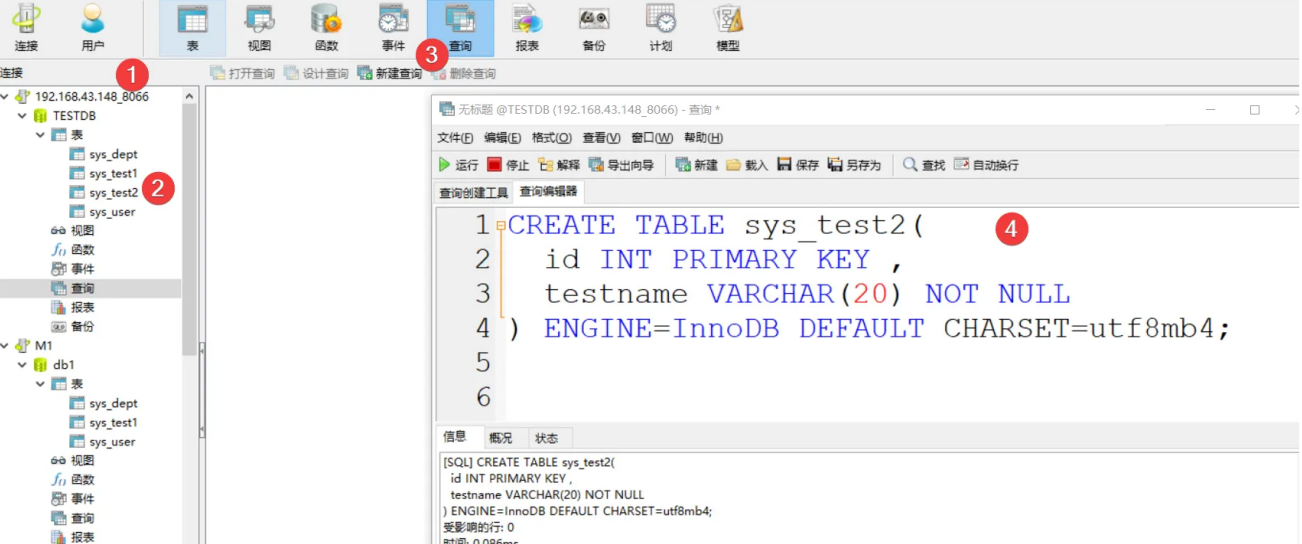
CREATE TABLE sys_test2(
id INT PRIMARY KEY ,
testname VARCHAR(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
插⼊测试数据
期望数据

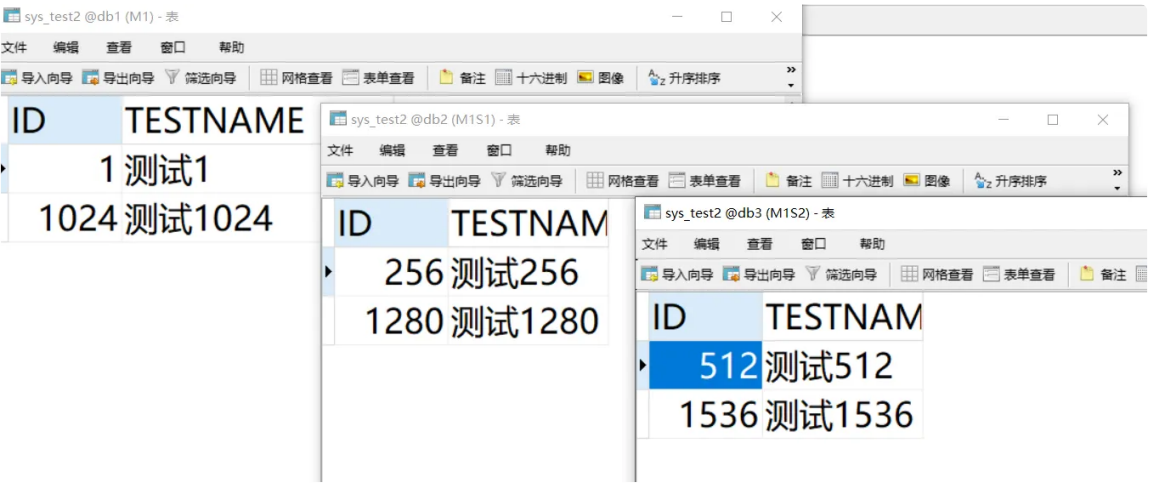
INSERT INTO sys_test2(id,testname) VALUES(1,'测试1');
INSERT INTO sys_test2(id,testname) VALUES(256,'测试256');
INSERT INTO sys_test2(id,testname) VALUES(512,'测试512');
INSERT INTO sys_test2(id,testname) VALUES(1024,'测试1024');
INSERT INTO sys_test2(id,testname) VALUES(1280,'测试1280');
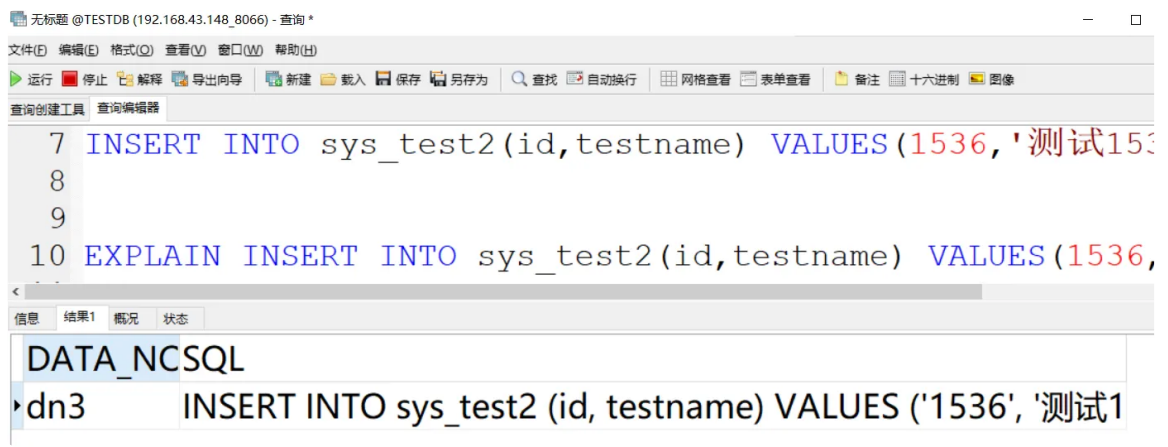
INSERT INTO sys_test2(id,testname) VALUES(1536,'测试1536');
EXPLAIN INSERT INTO sys_test2(id,testname) VALUES(1536,'测试1536');
自然月
rule.xml
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2021-01-01</property>
</function>
说明
数据按⽉份划分节点
dateFormat
日期格式
sBeginDate
开始日期
测试步骤
测试期望
数据按⽉份划分节点
在MySQL主节点上创建12个库
create database db1;
create database db2;
create database db3;
create database db4;
create database db5;
create database db6;
create database db7;
create database db8;
create database db9;
create database db10;
create database db11;
create database db12;
修改schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" >
<table name="sys_user" dataNode="dn1,dn2,dn3" rule="sharding-by-intfi
le" />
<table name="sys_dept" dataNode="dn1,dn2,dn3" rule="mod-long" />
<table name="sys_test1" dataNode="dn1,dn2,dn3" rule="auto-sharding-lon
g" />
<table name="sys_test2" dataNode="dn1,dn2,dn3" rule="rule2" />
<table name="sys_test3" dataNode="dn1,dn2,dn3" rule="jch" />
<!-- ⾃然⽉ 分⽚测试 -->
<table name="sys_test4" dataNode="dn1,dn2,dn3,dn4,dn5,dn6,dn7,dn8,dn9,
dn10,dn11,dn12" rule="sharding-by-month" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataNode name="dn4" dataHost="localhost1" database="db4" />
<dataNode name="dn5" dataHost="localhost1" database="db5" />
<dataNode name="dn6" dataHost="localhost1" database="db6" />
<dataNode name="dn7" dataHost="localhost1" database="db7" />
<dataNode name="dn8" dataHost="localhost1" database="db8" />
<dataNode name="dn9" dataHost="localhost1" database="db9" />
<dataNode name="dn10" dataHost="localhost1" database="db10" />
<dataNode name="dn11" dataHost="localhost1" database="db11" />
<dataNode name="dn12" dataHost="localhost1" database="db12" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" sla
veThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="192.168.43.148:3307" user="root" password="root">
<readHost host="M1S1" url="192.168.43.148:3308" user="root" password="root" />
<readHost host="M1S2" url="192.168.43.148:3309" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
重启MyCat
/usr/local/mycat/bin/mycat restart
建表
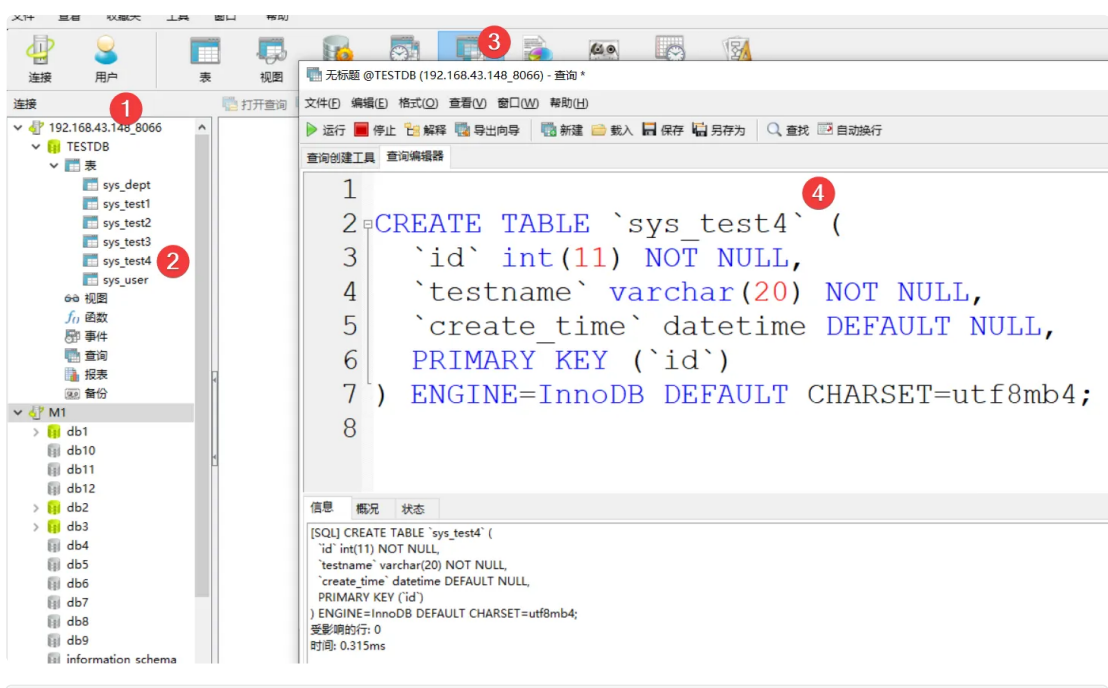
CREATE TABLE `sys_test4` (
`id` int(11) NOT NULL,
`testname` varchar(20) NOT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
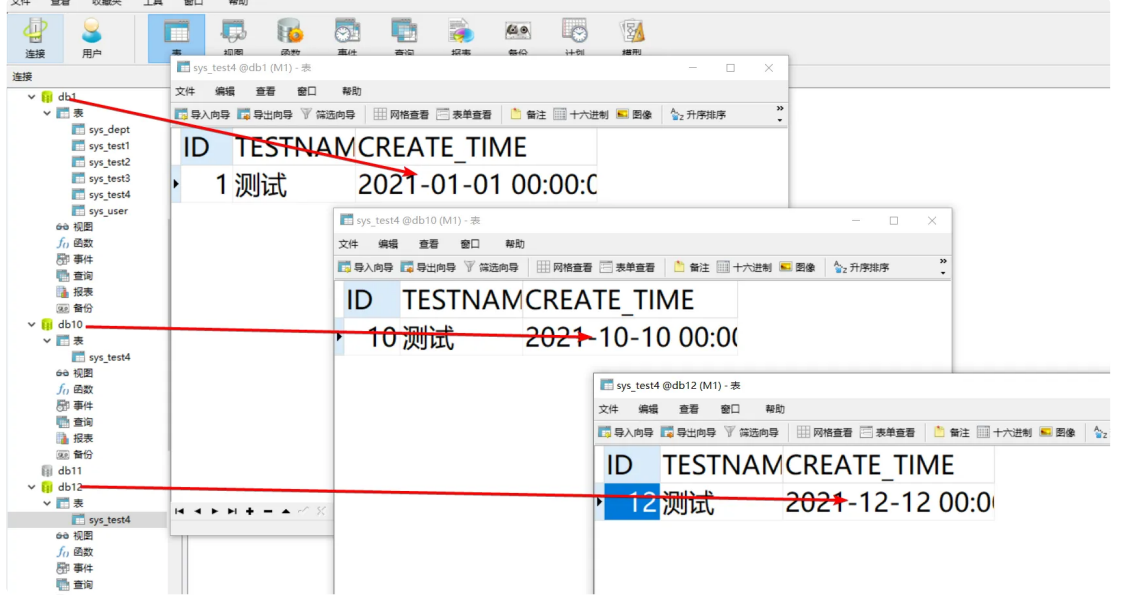
插⼊测试数据
INSERT INTO sys_test4(id, testname, create_time) VALUES (1, '测试', '2021-01-01 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (2, '测试', '2021-02-02 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (3, '测试', '2021-03-03 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (4, '测试', '2021-04-04 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (5, '测试', '2021-05-05 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (6, '测试', '2021-06-06 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (7, '测试', '2021-07-07 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (8, '测试', '2021-08-08 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (9, '测试', '2021-09-09 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (10, '测试', '2021-10-10 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (11, '测试', '2021-11-11 00:00:00');
INSERT INTO sys_test4(id, testname, create_time) VALUES (12, '测试', '2021-12-12 00:00:00');
读写分离
**目的:**实现数据库的读写分离
参数说明:
balance:负载均衡类型:
balance=“0”
不开启读写分离机制,所有读操作都发送到当前可⽤的writeHost上
- balance=“1”
全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式
(M1-S1,M2-S2 并且M1 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。 - balance=“2”
所有读操作都随机的在writeHost、readHost上分发 - balance=“3”:真正的读写分离
所有读请求随机的分发到writeHst对应的readHost执⾏
writeHost不负担读写压⼒。(1.4之后版本有)
测试
balance=“0”
不开启读写分离机制,所有读操作都发送到当前可⽤的writeHost上
修改 schema.xml

<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" >
<!-- 读写分离 测试 -->
<table name="sys_test9" dataNode="dn1"/>
</schema>
<!--
数据节点,因为dataHost都是localhost1,所有dataHost主机有3个库,分别db1,db2,d
b3
-->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<!--
数据库最⼤连接是1000,最⼩连接是10,
balance:负载均衡类型
1. balance="0"
1. 不开启读写分离机制,所有读操作都发送到当前可⽤的writeHost上
2. balance="1"
1. 全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双
主双从模式(M1-S1,M2-S2 并且M1 M2互为主备),正常情况下,M2,S1,S2都参与select语句
的负载均衡。
3. balance="2"
1. 所有读操作都随机的在writeHost、readHost上分发
4. balance="3":
1. 所有读请求随机的分发到writeHst对应的readHost执⾏
2. writeHost不负担读写压⼒。(1.4之后版本有)
writeType="0" :所有写操作发送到配置的第⼀个 writeHost,第⼀个挂了切到还⽣存的第⼆个
writeHost
switchType="1":主从切换策略,⾃动切换
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" sla
veThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="192.168.43.148:3307" user="root" password="root">
<readHost host="M1S1" url="192.168.43.148:3308" user="root" password="root" />
<readHost host="M1S2" url="192.168.43.148:3309" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
重启MyCat
/usr/local/mycat/bin/mycat restart
创建表
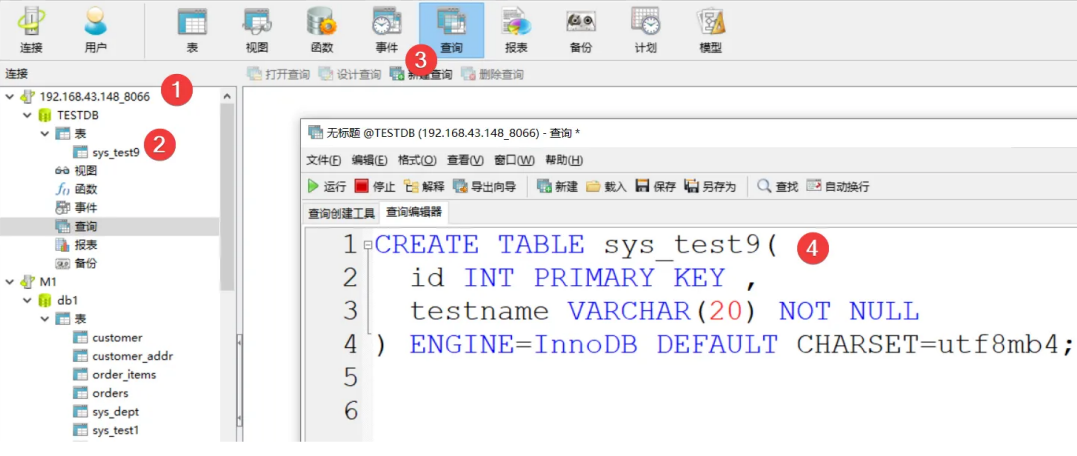
CREATE TABLE sys_test9(
id INT PRIMARY KEY ,
testname VARCHAR(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
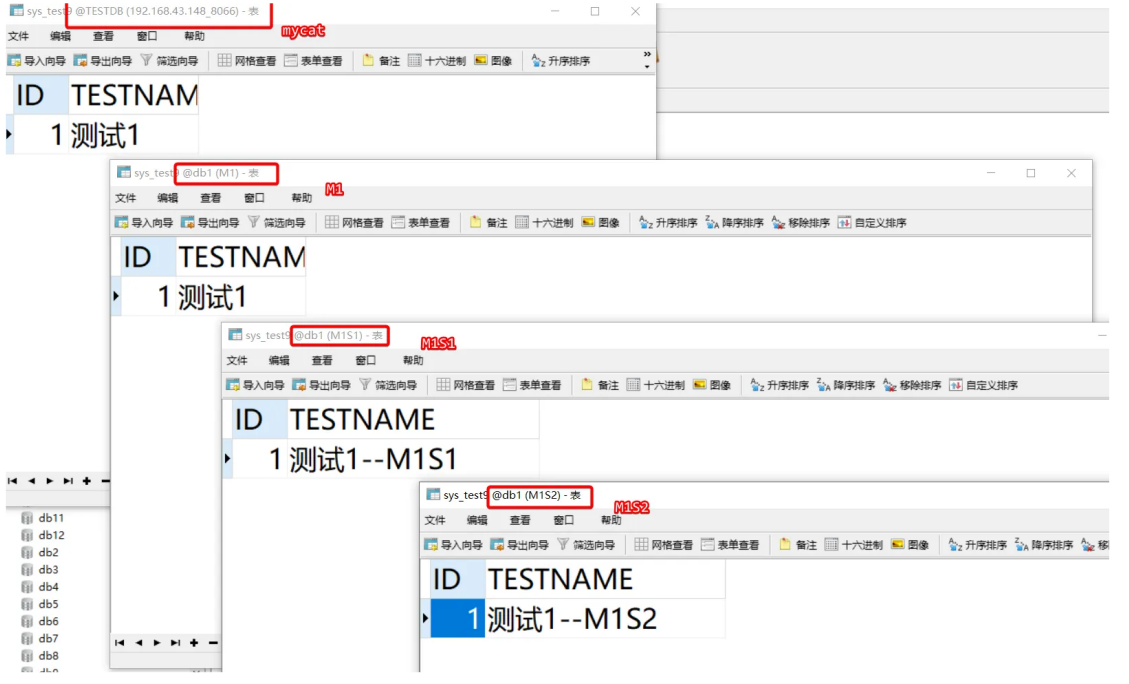
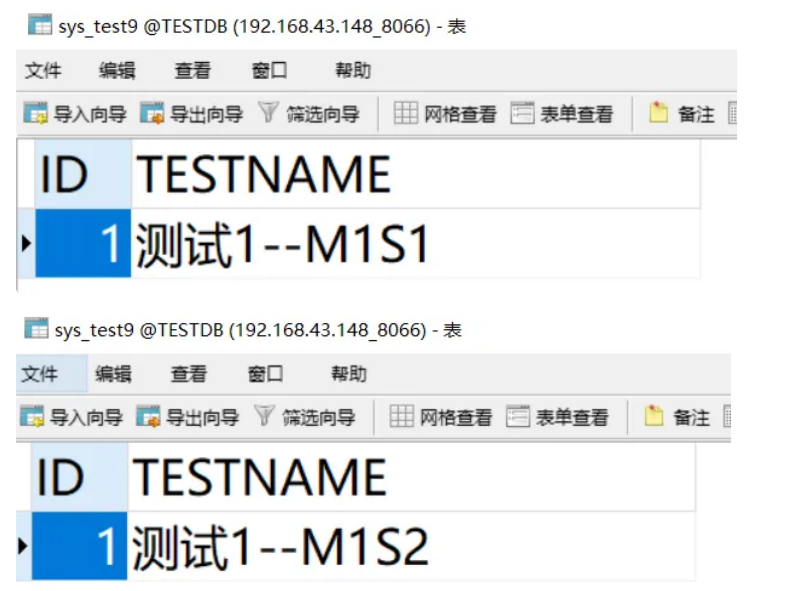
插入测试数据:
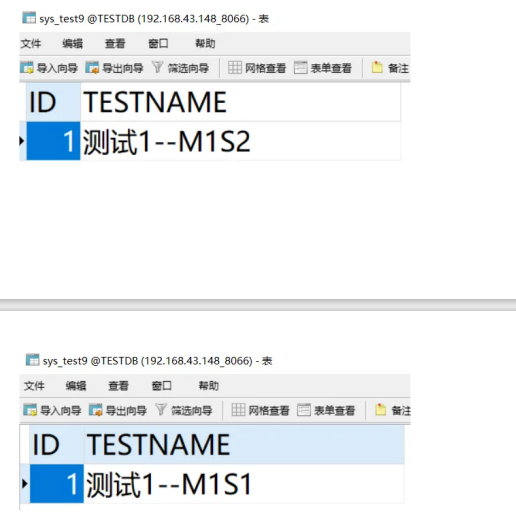
在Mycat连接上:
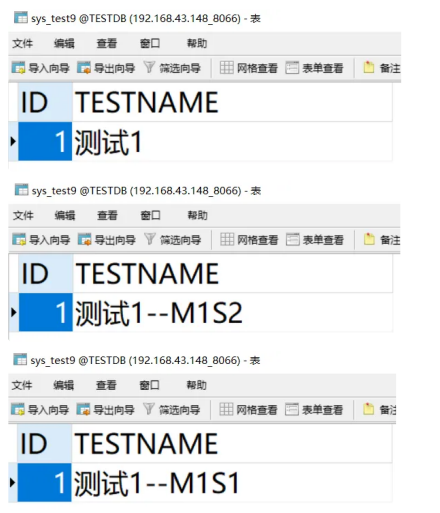
INSERT INTO sys_test9(id,testname) VALUES(1,"测试1");
在数据库M1S1上:
# M1S1
UPDATE db1.sys_test9 SET testname = '测试1--M1S1' WHERE id = 1;
在数据库M1S2上:
# M1S2
UPDATE db1.sys_test9 SET testname = '测试1--M1S2' WHERE id = 1;
因为是从库,所以主库的内容还是不变。
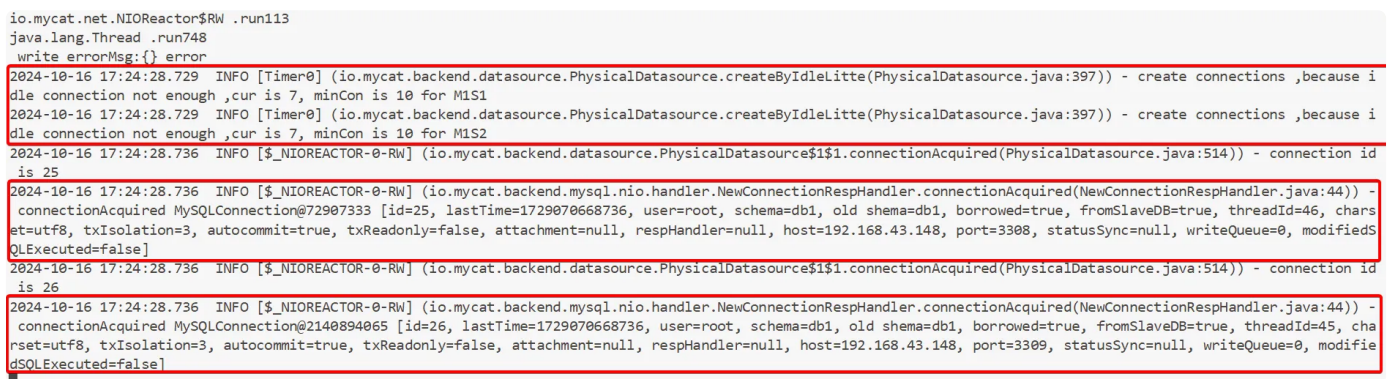
查看mycat⽇志
tail -f /usr/local/mycat/logs/mycat.log
balance=“1”
balance=“2”
balance=“3”