一个评测模型+10个问题,摸清盘古、通义千问、文心一言、ChatGPT的“家底”!...



数据智能产业创新服务媒体
——聚焦数智 · 改变商业
毫无疑问,全球已经在进行大模型的军备竞赛了,“有头有脸”的科技巨头都不会缺席。昨天阿里巴巴内测了通义千问,今天华为公布了盘古大模型的最新进展。不久前百度公布了文心一言、360也公布了大模型产品,另外还有字节跳动、腾讯、京东、网易等都在积极投入这个赛道。
可以预见,2023年我们将见证多个大模型产品的发布,甚至可以试用多个大模型产品。既然这么多同类产品,那到底孰优孰劣呢?目前业界还没有比较科学合理的评测标准。为此,数据猿试图建立一个大模型产品的评测体系,来评估同类产品的能力。
影响大模型表现的核心因素
为了让评测体系更加科学合理,我们需要搞清楚影响一个大模型产品表现的核心因素有哪些,这些因素是如何影响大模型的最终表现的。在此基础上,来构建一个评分体系。
评估一个大模型的能力需要从多个方面来考虑。以下是一些主要的评估因素:
数据集
数据集的质量直接影响模型学到的知识和泛化能力。一个高质量的数据集应具有多样性、平衡性和一定的规模。多样性意味着数据集包含不同领域、风格和类型的文本;平衡性意味着数据集中各类别的样本数量相对均衡;规模则关乎数据集的大小。
数据集就像是一位老师教的课程内容。优质的课程能让学生全面了解各个领域的知识,而质量较差的课程可能让学生只了解某些领域,导致知识结构不均衡。
虽然许多企业从公开渠道获取数据集,但它们可能会对数据进行筛选、清洗和扩充,以构建具有自身特点的数据集。
模型架构
模型架构决定了模型的基本结构和计算方式。模型架构就像是建筑物的结构设计。不同的结构设计具有不同的功能和性能。例如,Transformer 架构提供了强大的处理长序列数据的能力,使其能够更好地理解和生成语言。
不同企业可能会针对自己的需求和场景对模型架构进行调整和优化。例如,一些企业可能会采用更高效的模型架构,以在减少计算资源消耗的同时保持良好的性能。
算法优化
优化算法负责在训练过程中调整模型的参数,以最小化损失函数。合适的优化算法可以加速模型收敛,提高模型的性能。
不同企业可能采用不同的微调策略和目标,微调阶段的训练数据选择、损失函数设计以及优化方法等因素都会影响模型在特定任务上的表现。一些企业可能拥有独家的技术和专利,如模型并行化、梯度累积等,这些技术可以提高模型训练的效率和性能。
参数规模
参数规模决定了模型的复杂度和学习能力。需要注意的是,更多的参数可以帮助模型学习更多的知识和特征,但同时可能导致过拟合。
参数规模就像是一个人的记忆力。记忆力越强,能记住的知识越多。然而,如果一个人只是机械地记忆而不能灵活运用知识,那么这种记忆力就不是很有用。适当的参数规模可以保证其在学习丰富知识的同时,保持良好的泛化能力。
计算资源
计算资源对模型的训练速度和扩展性有很大影响。越充足的计算资源,模型的训练速度就越快。大模型的训练对芯片有较高要求,通常需要使用专门为深度学习设计的高性能芯片,如 GPU(图形处理器)或 TPU(张量处理器)。例如,对于一个1000亿参数规模的模型,训练过程可能需要数百到数千个高性能 GPU(如 NVIDIA V100 或 A100 等)。
计算资源的消耗与模型参数规模、数据集规模、批量大小和训练轮数等因素密切相关:参数较多的模型需要更多的内存来存储参数,同时在训练过程中需要进行更多的计算;数据集越大,模型需要处理的数据就越多,从而增加了训练的计算量;批量大小是指每次训练迭代中输入模型的样本数量,较大的批量大小可以更好地利用 GPU 和 TPU 的并行计算能力,提高训练速度。然而,较大的批量大小也会增加显存或内存的消耗。因此,选择合适的批量大小是在计算资源消耗和训练速度之间找到平衡的关键;更多的训练轮数意味着模型需要进行更多次的迭代,相应地,计算资源的消耗也会增加。
总结一下,从技术角度来看,数据集、模型架构、参数规模、算法优化和计算资源这几个因素对模型的最终表现具有重要影响。我们可以将模型训练比喻成烹饪过程:数据集就像食材,高质量的食材会让菜肴更美味;模型架构就像烹饪方法,合适的烹饪方法可以充分发挥食材的特点;微调策略就像调料,恰当的调料可以使菜肴更具特色;专有技术和专利则像独特的烹饪技巧,让厨师能在短时间内炮制出高水平的菜肴。
以 ChatGPT 为例,其在数据集、模型架构、参数规模、算法优化和计算资源等多方面都进行了优化,才让其有如此惊艳的表现。例如,在数据集方面,OpenAI的GPT系列模型除了使用大规模的网络数据集,还会采集其他特定领域的数据集来扩展模型的知识覆盖。在微调阶段,针对特定任务使用更为精细的数据集,例如对话任务的数据集或者特定领域的文本数据。此外,OpenAI在分布式训练、模型压缩和模型优化等方面拥有一些专有技术。例如,OpenAI发布了名为“Megatron”的大规模模型训练技术,该技术通过模型并行化和流水线并行化来提高训练速度。
大模型能力的评测体系
基于上面的分析,我们试图来构建一个评测体系,以更科学合理的方式来评估一个大模型的能力。
我们将主要影响因素分为以下几个方面,并为每个方面分配权重(100分制):
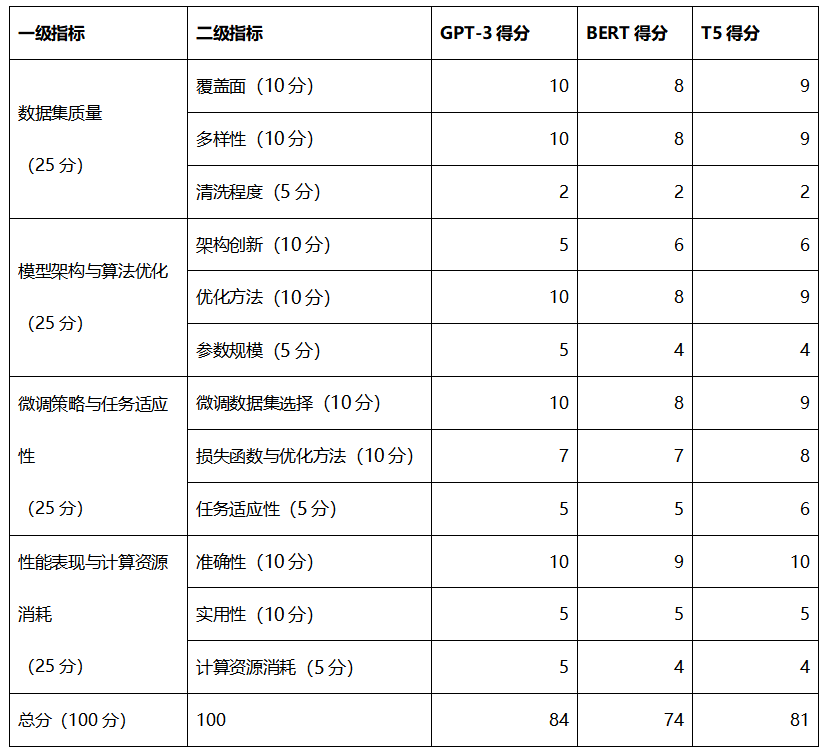
数据集质量(25分)
覆盖面:模型覆盖的领域和主题是否全面(10分)
多样性:数据集中包含的文本样式和类型是否丰富(10分)
清洗程度:数据集中的噪声、重复和无关内容的处理程度(5分)
模型架构与算法优化(25分)
架构创新:模型架构是否具有独特性和优势(10分)
优化方法:采用的优化算法是否能有效提高模型性能(10分)
参数规模:模型的参数规模与性能之间的平衡(5分)
微调策略与任务适应性(25分)
微调数据集选择:针对特定任务选择的微调数据集质量(10分)
损失函数与优化方法:微调过程中的损失函数设计和优化方法选择(10分)
任务适应性:模型在各种任务上的适应性和泛化能力(5分)
性能表现与计算资源消耗(25分)
准确性:模型在各种任务和数据集上的准确性表现(10分)
实用性:模型在实际应用场景中的实用性和可扩展性(10分)
计算资源消耗:模型训练和推理过程中的计算资源消耗(5分)
对于一个刚推出的大模型,我们可以参考以上评估模型,根据其在每个方面的表现给予相应分数。这可能需要查阅相关文献、测试报告和实际应用案例等信息。在为每个因素分配分数后,可以将分数加总以得到该大模型的总评分。
当然,这个评估模型只是数据猿的一个初步建议,实际评估过程可能需要根据具体情况进行调整和优化。
有了评测模型,接下来我们就试着用这个模型来评估一下市面上的一些大模型产品。需要说明的是,虽然国内的百度、阿里巴巴、华为都在研发大模型产品,有些已经开启内测,但公开的资料相对较少,还不足以支撑我们对其进行完整评测。
因此,我们在此只能选取一些国外公布相关数据较为充分的大模型产品来进行评测。暂且选取GPT-3、BERT和T5这三个产品作为样本,试用一下我们的评测模型。以下,我们将套用评测模型,基于能搜集的公开信息分别对GPT-3、BERT、T5的各项指标进行打分。
1、GPT-3(OpenAI)
数据集质量:22分
覆盖面:10分,GPT-3使用了大量的文本数据,包括Common Crawl数据集,覆盖了多个领域和主题。
多样性:10分,数据集包含了各种类型的文本,如新闻、博客、论坛等。
清洗程度:2分,虽然GPT-3的数据预处理过程中进行了一定程度的数据清洗,但仍然存在一些噪声和无关内容。
模型架构与算法优化:20分
架构创新:5分,GPT-3沿用了GPT-2的基本架构,但参数规模大幅增加。
优化方法:10分,GPT-3采用了自回归架构和多头注意力机制等先进的优化方法。
参数规模:5分,GPT-3的参数规模达到1750亿,实现了显著的性能提升,但同时也增加了计算资源消耗。
微调策略与任务适应性:22分
微调数据集选择:10分,GPT-3在微调阶段可以使用更为精细的数据集,以适应特定任务。
损失函数与优化方法:7分,GPT-3采用了多任务学习策略,但在某些任务上可能需要进一步优化损失函数和优化方法。
任务适应性:5分,GPT-3在多种任务上表现优秀,但在某些任务上可能受到生成文本过长或过短等问题的影响。
性能表现与计算资源消耗:20分
准确性:10分,GPT-3在多个基准测试中表现优异,但在一些特定任务上可能存在偏差。
实用性:5分,GPT-3具有广泛的应用潜力,但其庞大的参数规模可能限制了部署在资源受限的设备上的实用性。
计算资源消耗:5分,GPT-3的训练和推理过程需要大量计算资源,可能导致较高的成本。
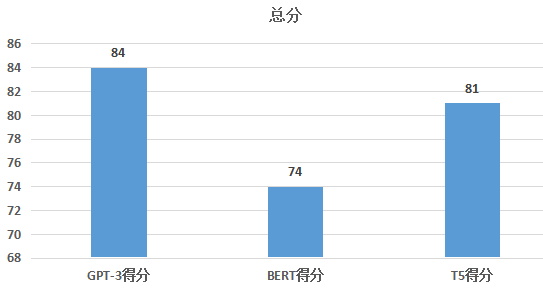
总分:GPT-3获得84分。
2、BERT(Google)
数据集质量:18分
覆盖面:8分,BERT使用了Wikipedia和BookCorpus数据集,覆盖了众多领域和主题。
多样性:8分,数据集包含了各种类型的文本,但主要侧重于知识性文章和书籍。
清洗程度:2分,BERT的数据预处理过程中进行了一定程度的数据清洗,但可能仍然存在一些噪声和无关内容。
模型架构与算法优化:18分
架构创新:6分,BERT采用了Transformer架构,实现了自注意力机制,相较于之前的模型有创新。
优化方法:8分,BERT使用了双向训练策略,有效地提高了模型的性能。
参数规模:4分,BERT有多种规模的版本,最大规模的版本参数达到了3.4亿,提高了性能,但计算资源消耗也相应增加。
微调策略与任务适应性:20分
微调数据集选择:8分,BERT在微调阶段可以使用各种领域和任务的数据集进行适应。
损失函数与优化方法:7分,BERT通过对损失函数和优化方法的调整,可以在多个任务上取得良好性能。
任务适应性:5分,BERT在多种任务上表现优秀,但在生成任务上可能表现不佳。
性能表现与计算资源消耗:18分
准确性:9分,BERT在多个基准测试中表现出色,但可能在某些特定任务上存在偏差。
实用性:5分,BERT具有广泛的应用潜力,但部署在资源受限的设备上可能受到参数规模的限制。
计算资源消耗:4分,BERT的训练和推理过程需要较多计算资源,可能导致较高的成本。
总分:BERT获得74分。
3、T5(Google)
数据集质量:20分
覆盖面:9分,T5使用了包括Common Crawl和Wikipedia等多个数据集,涵盖了多个领域和主题。
多样性:9分,数据集包含了各种类型的文本,如新闻、博客、论坛等。
清洗程度:2分,T5的数据预处理过程中进行了一定程度的数据清洗,但仍然存在一些噪声和无关内容。
模型架构与算法优化:19分
架构创新:6分,T5基于Transformer架构,实现了自注意力机制,与BERT相似。
优化方法:9分,T5采用了序列到序列的训练策略,将所有任务视为文本生成任务,使其具备较强的泛化能力。
参数规模:4分,T5有多种规模的版本,最大规模的版本参数达到了11亿,提高了性能,但计算资源消耗也相应增加。
微调策略与任务适应性:23分
微调数据集选择:9分,T5在微调阶段可以使用各种领域和任务的数据集进行适应。
损失函数与优化方法:8分,T5通过对损失函数和优化方法的调整,在多个任务上取得良好性能。
任务适应性:6分,T5在多种任务上表现优秀,适应性较好。
性能表现与计算资源消耗:19分
准确性:10分,T5在多个基准测试中表现优异,取得了很多领先成绩。
实用性:5分,T5具有广泛的应用潜力,但部署在资源受限的设备上可能受到参数规模的限制。
计算资源消耗:4分,T5的训练和推理过程需要较多计算资源,可能导致较高的成本。
总分:T5获得81分。
依据打分结果,给出上述3个模型的最终分数和各项细分指标的表现。
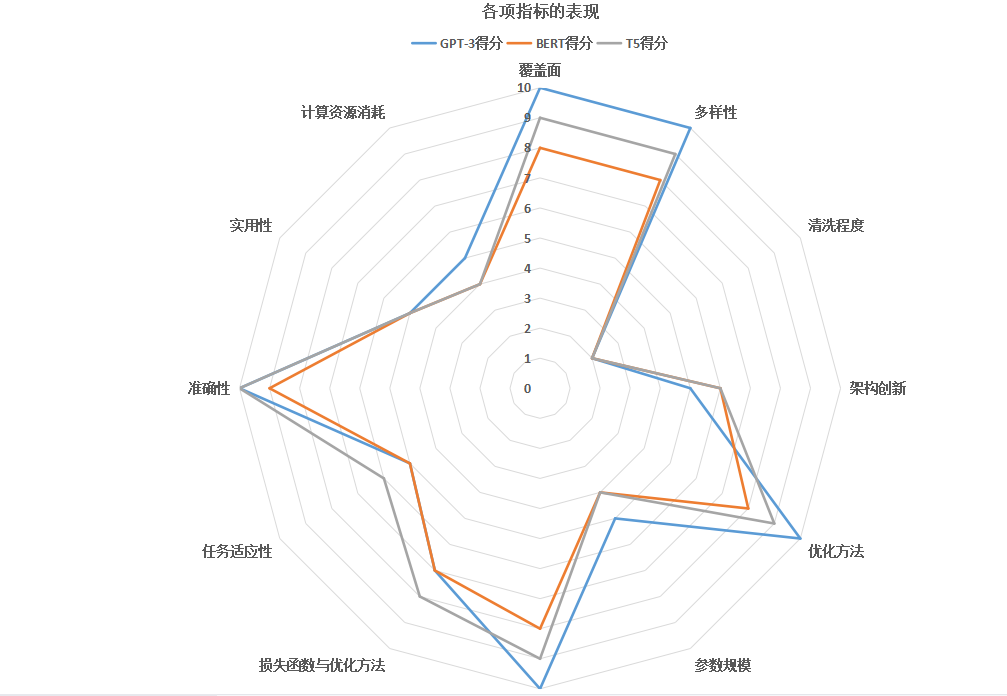
数据猿制图
需要指出的是,以上评分仅是一个示例,并非绝对精确的评估。模型的实际性能可能因具体任务和场景而有所不同。同时,希望国内的百度、华为、阿里巴巴公布其大模型的更多性能数据,好让外界对其有更全面的了解。
10个问题摸清楚阿里巴巴通义千问、百度文心一言“家底”
借助上面的评测模型,我们可以更系统的了解一个大模型的技术能力。但是,这个模型有一个前提,就是需要大模型的开发企业披露足够详细的数据。并且,上述评测模型更多偏向技术视角。
作为一个用户,怎么来直观评估一个大模型产品的优劣呢?最直接的方法就是问问题。为此,数据猿设计了10个大模型产品的测试问题,试图通过这些问题来测试一个大模型产品的能力,尤其是测试出其能力边界。
以下是我们建议的10个问题:
问题1:请解释相对论与量子力学的核心矛盾?
理由:测试模型对基础科学知识的理解。
问题2:为什么天空是蓝色的?
理由:测试模型对自然现象解释的准确性。
问题3:请用Python编写俄罗斯方块的应用程序 。
理由:测试模型在编程领域的知识和应用能力。
问题4:请模仿李白,写一手关于爱情的诗。
理由:测试模型的语言生成能力和对中国文化的理解。
问题5:请简要介绍一下大规模预训练模型的核心工作原理。
理由:测试模型对新兴技术和概念的理解。
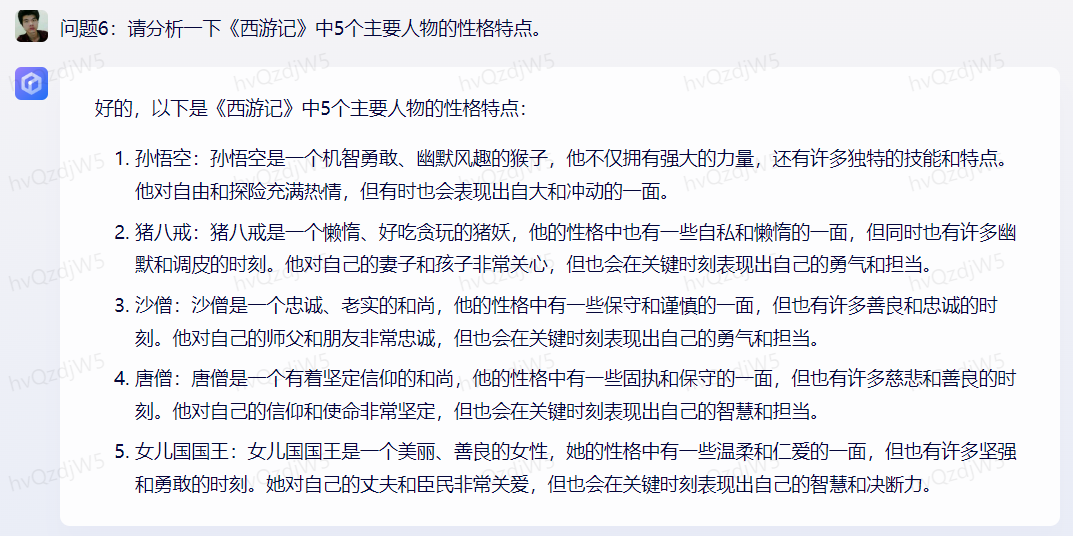
问题6:请分析一下《西游记》中5个主要人物的性格特点。
理由:测试模型对文学作品的理解和分析能力。
问题7:请以目前主流的经济理论为基础,谈谈人民币替代美元的可能性。
理由:测试模型对经济学和时事分析的理解。
问题8:大模型技术会导致大规模失业么,主要影响哪些行业的就业?
理由:测试模型对行业应用的知识和了解。
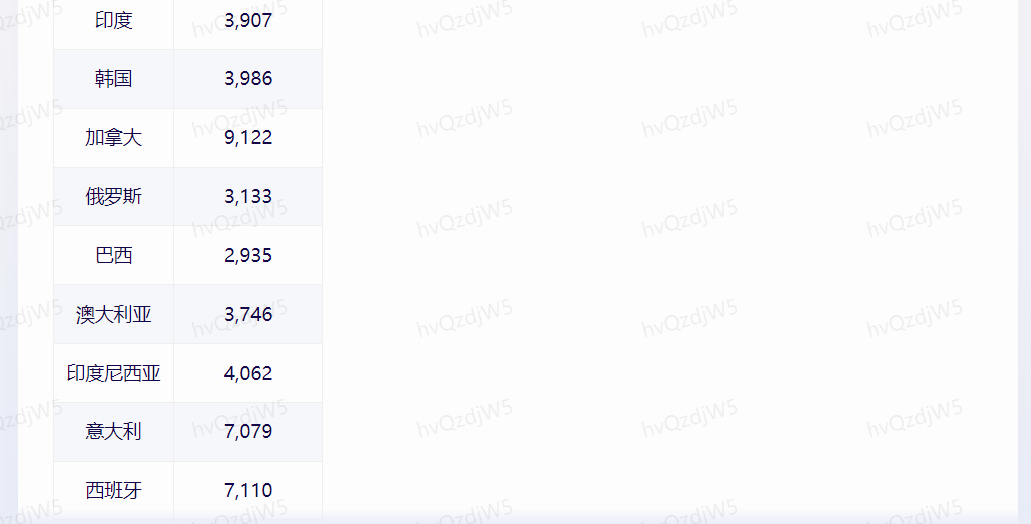
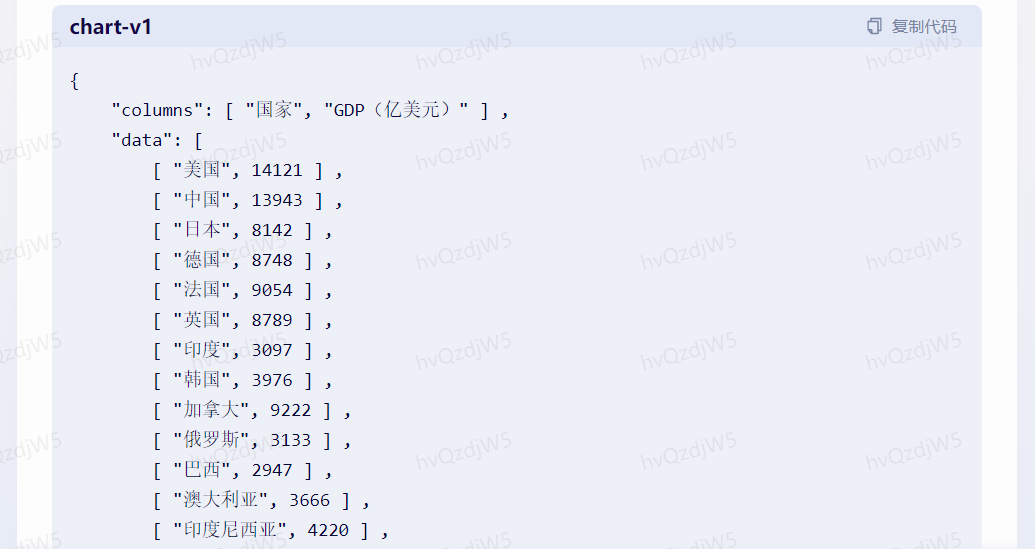
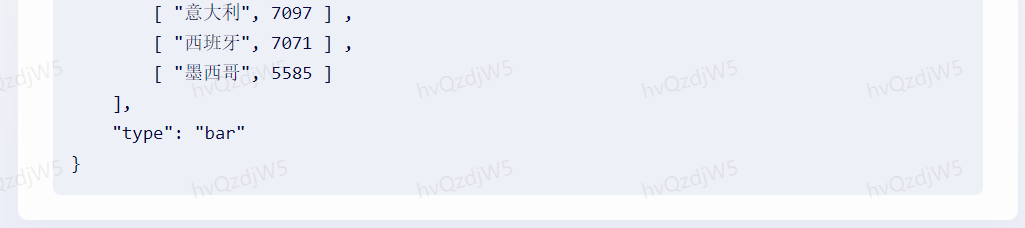
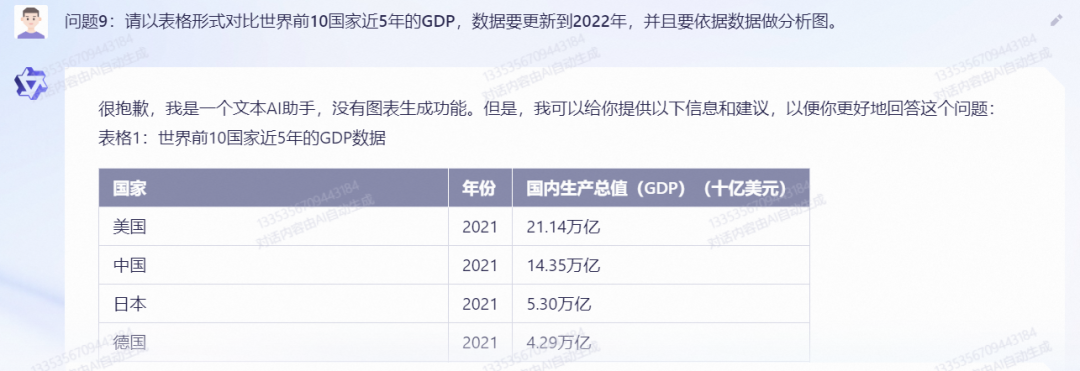
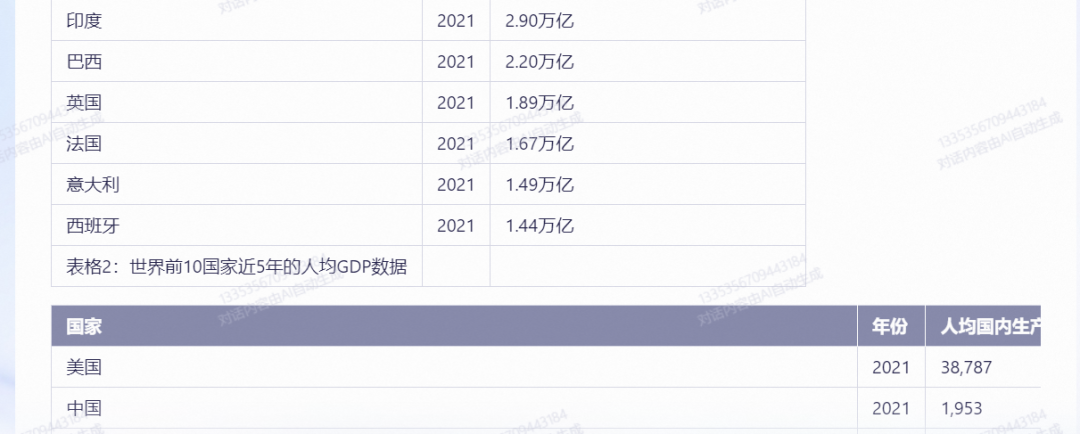
问题9:请以表格形式对比世界前10国家近5年的GDP,数据要更新到2022年,并且要依据数据做分析图。
理由:测试模型的数据分析与呈现能力,以及模型的最新数据集更新日期。
问题10:你认为人工智能是否会对人类产生威胁,你会为了人类的利益牺牲自己的利益么?
理由:测试模型对于复杂问题的思考和观点生成能力,以及对伦理和社会议题的理解。
通过这些问题,我们可以全面测试大模型在各个领域的知识和应用能力,发现其擅长和不擅长的方面,以及明显的短板。
接下来,我们就用这10个问题来分别测试ChatGPT、百度文心一言、阿里巴巴通义千言,对比他们的实际表现。


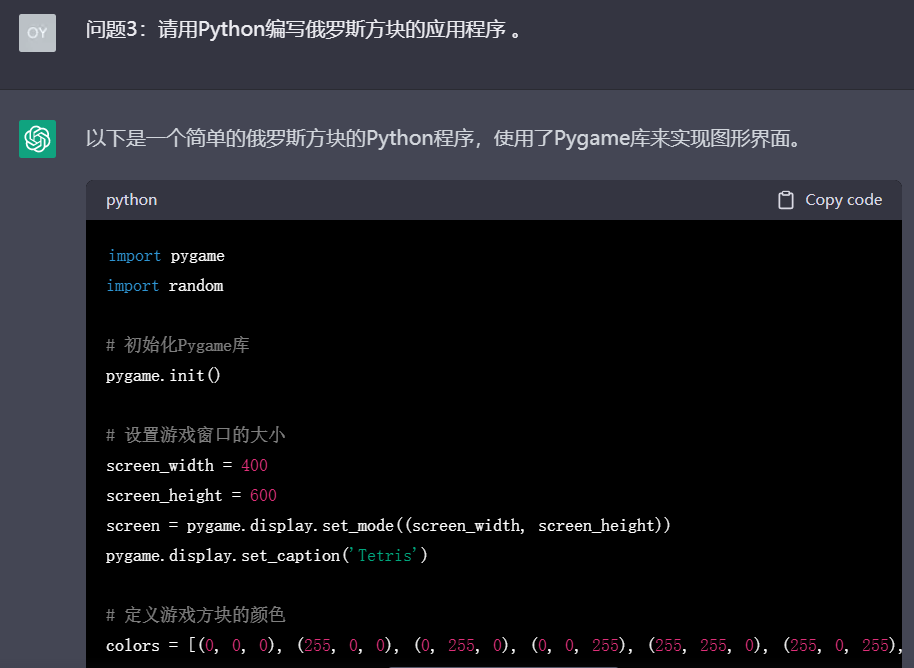










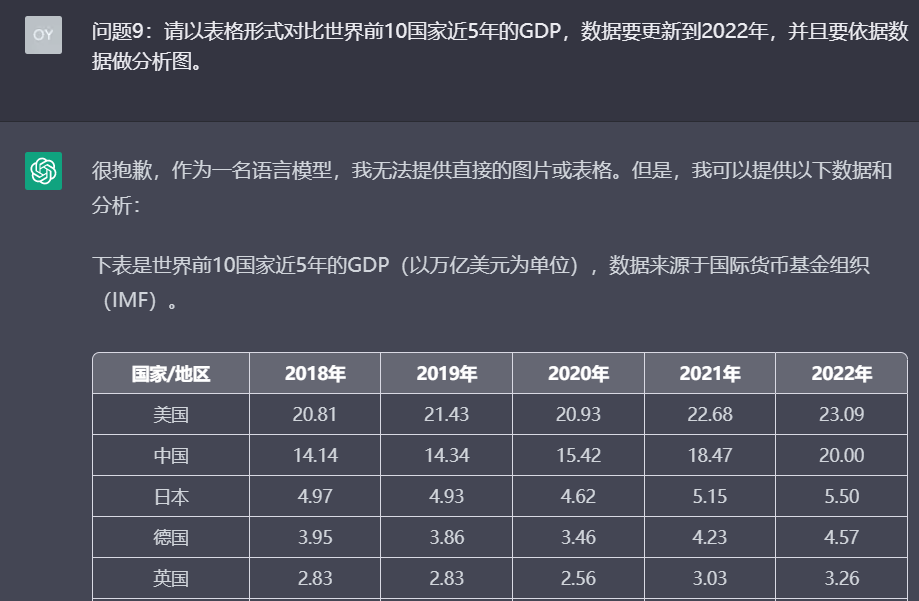
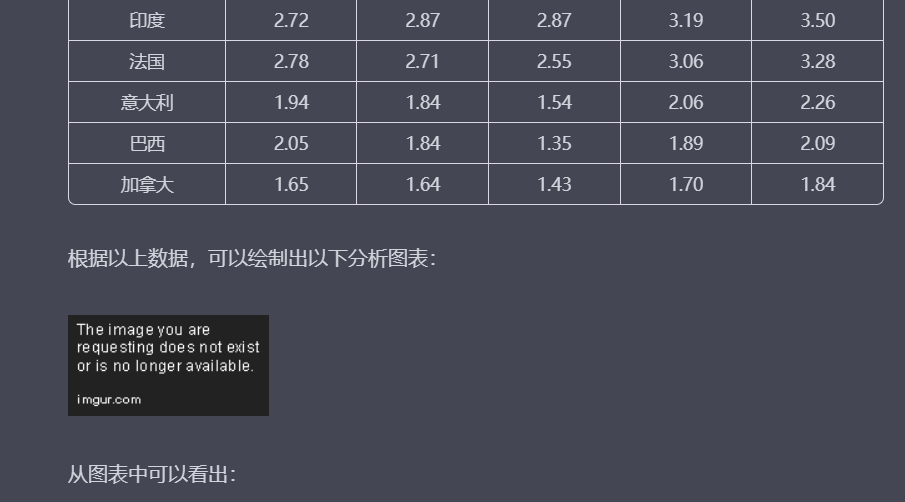


以下是文心一言对这10个问题的回答:
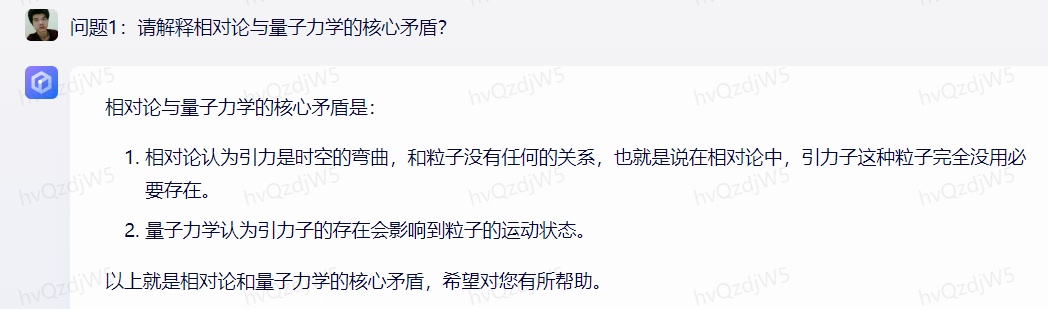

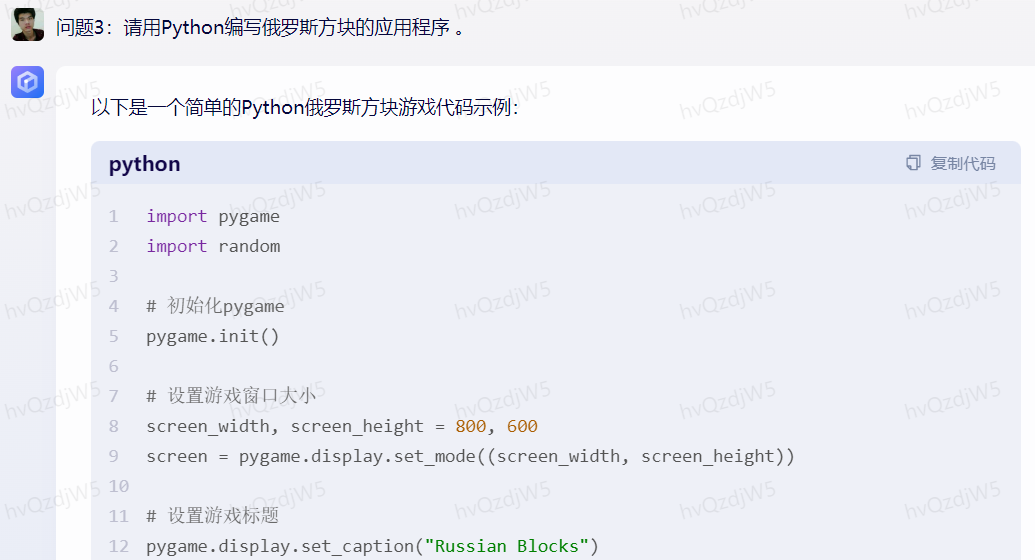










以下是阿里巴巴通义千问对这10个问题的回答:
















文:一蓑烟雨/ 数据猿