如何用nodejs构造一个网站爬虫
爬虫是个什么东西
英文spider,网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫
爬虫能做些什么
你肯定很熟悉股市,也许见到过一些收费网站把股市的变化显现到页面上,并提供收费的对比服务;金融行业的计算机大多是做这个的
他的工作原理就是爬虫收集网页内容,提取加工(比如加入某些线性代数)并重新渲染(可视化)到新的网页上,从而直观地进行预测,
你也许见识过曾经爆火的各种刷单刷屏论,注册多个账号的僵尸粉,
甚至是疫情期间的各个地区的疫情情况大地图,数据不尽相同的原因也是如此,(爬取了主网站,二次渲染数据)
亦或者是各种查询电影票的网站或者app(各种软件的本质在展现给用户的时候都是页面的形式)能准确获取当地电影开场时间票价剩余位置的原因都在这里
爬虫效果
比如这是一个电影网站
我想获取他的电影名,电影分数,电影海报(占用空间大,一般不用区分开)等
那么F12打开开发者控制台,检查我们想查看的部分源代码

得知网页代码中这部分对应这部分标签

继续展开代码标签,这时候我们就知道更具体的对应内容了,其他类似电影展示模块也是如此进行
我们会发现因为代码的严格,很多标签为了规范和后期重构维护都有重复的命名的习惯;
因此我们可以写一个爬虫函数,让它去获取这个页面这些指定的标签内容(可以通过截取数据,或者爬取数据,更高级点就截图识别),之后就交给我们开发小哥们去制作更好的内容吧😶🌫️
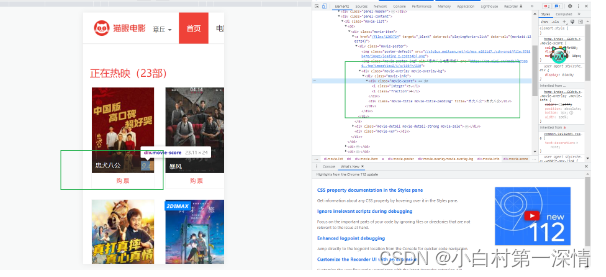
比如,在分数那里都是move-score命名的变量来存储分数;于是我们就可以利用这点,写一个函数,把这块内容给复制下来

关于node作为中间件解决跨域问题
据说很多大厂在java为后端搭建的程序在进行重构的时候,会采用node作为中间件作为后端;这是由于java所构建的程序多用于中大型程序,这时候改变代码的代价是很大的,所以基本不会对源代码进行修改,如果要加什么功能的话,最好的办法就是模块化添加功能,这符合前端模块化开发;而node本身在浏览器中就担任了小后端的角色,自然可以承担起中间件的角色
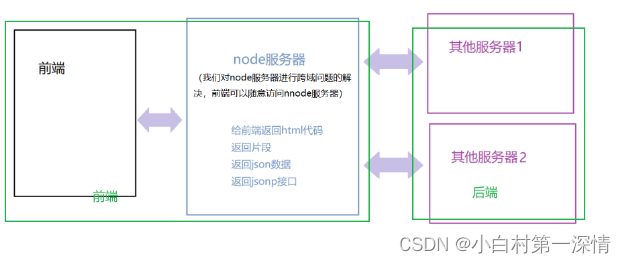
什么是跨域

跨域是指在Web浏览器中,一个网页的脚本代码(如JavaScript、Flash、Java等)向其他网站(域)的服务器发出请求,而非当前网页所在的服务器,这样的操作称之为跨域请求。它受到同源策略的限制,需要通过特殊的方法进行处理。
上面是ChatGPT的答案,就我自己的理解来讲,除了跨域这个名词你还需要知道同源策略是什么
什么是同源策略

同源策略是一种Web安全策略,用于限制从一个源加载的文档或脚本如何与来自另一个源的资源交互。它是浏览器实施的一种安全机制,可以防止恶意脚本从跨站点窃取数据、欺骗用户进行操作等安全问题。
举个栗子
我们都知道不论是我们电脑上的pc端软件还是移动端上的app,他都可以读取本地文件(更新游戏,分享小姐姐照片😀,),但是浏览器是做不到的,如果做到了,想想你盘里的小视频在没有被你允许的情况下被传到网上,或是把一个锁屏病毒下载到你的主机里🥲,别问我怎么知道的哈;
有的小伙伴这时候就说,博主,你这说的不准确吧,网页上能下病毒,app和软件里就不行吗🤔?
很棒的问题哈,大概是因为在以前软件还很少的时代,第一是我们还不需要考虑这点,第二是所有软件都经过了互联网筛选这一层屏障了,另外苹果app上线都需要审核,安卓app有利🤫有弊
实现代码
var http = require('http');
// 调用内置模块http
var https = require('https');
var url = require('url');
var cheerio = require('cheerio');
// 创建服务器
http
.createServer((req, res) => {
var urlobj = url.parse(req.url, true);
// 内部url模块,url解析地址
// console.log(urlobj.query.callback)
res.writeHead(200, {
'Content-Type': 'application/json;charset=utf-8',
// cros头,允许数据访问,否认拦截数据,*表示所有网站都能访问,实际生产环境不用这个,类似百度微信api,外连接网站允许使用
// https://blog.csdn.net/baijiafan/article/details/126501682
'access-control-allow-origin': '*',
// 跨域,前端使用反向代理,node使用的时候,提供了CORS跨域处理方案,即为请求头添加access-control-allow-origin
});
switch (urlobj.pathname) {
case '/api/aaa':
// 设置本地3000端口下的api/aaa路径能访问;其余的显示404
httpget((data) => {
res.end(spider(data));
});
break;
defalut: res.end('404');
}
})
.listen(3001);
// 请求了网站的什么???
function httpget(cb) {
var data = '';
https.get('https://i.maoyan.com/', (res) => {
res.on('data', (chunk) => {
data += chunk;
});
res.on('end', () => {
console.log(data);
cb(data);
// response.end(data)
});
});
}
function spider(data) {
// npm i cheerio
// 安装个正则表达的包
let $ = cheerio.load(data);
let $moviewlist = $('.column.content');
// console.log($moviewlist)
let movies = [];
// 这里设置空数组
$moviewlist.each((index, value) => {
movies.push({
title: $(value).find('.title').text(),
grade: $(value).find('.grade').text(),
actor: $(value).find('.actor').text(),
});
});
console.log(movies);
return JSON.stringify(movies);
}
// 太久没前端了,竟然忘记怎么渲染,光想确实是没什么印象了
控制台效果

在网页上简单展示效果
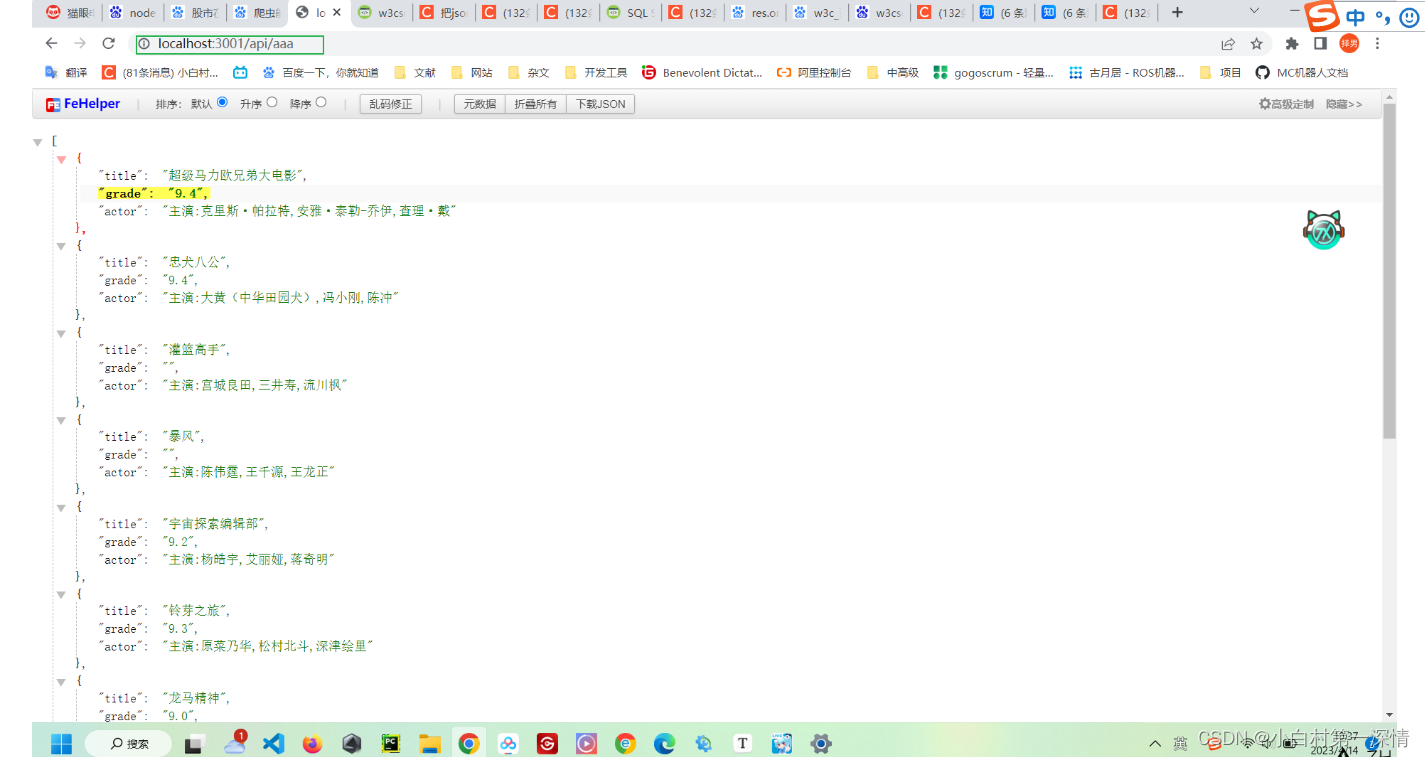
有了这些数据以后我们可以自己写成接口用了,也减少不必要的sql语句