面试总结之消息中间件
RabbitMQ的消息如何实现路由
-
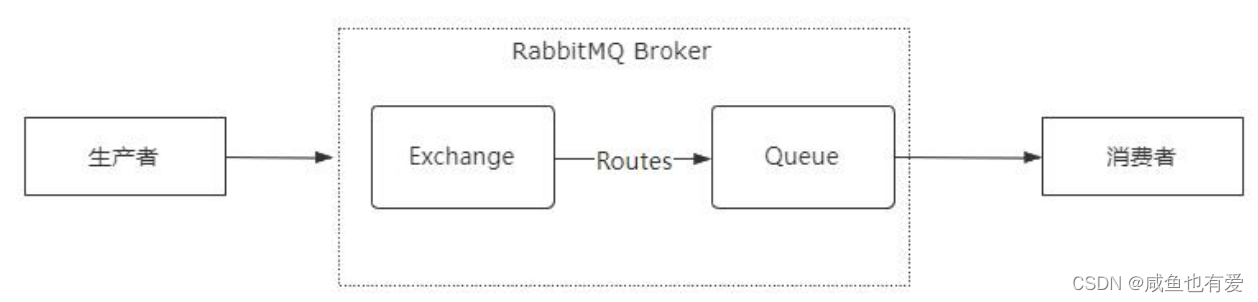
RabbitMQ是一个基于AMQP协议实现的分布式消息中间件,AMQP具体的工作机制是生产者将消息发送到RabbitMQ Broker上的Exchange交换机上,Exchange交换机将收到的消息根据路由规则发给绑定的队列(Queue),然后再将消息投递给订阅了该队列的消费者,从而完成消息的异步通讯
-
Exchange是一个消息交换机(消息路由规则的核心组件),可定义消息路由规则(即消息应该路由到哪个队列);Queue表示消息的载体,每个消息可以根据路由规则路由到一个或多个队列中
-
Exchange负责接收生产者的消息,并将消息路由到消息队列,而消息的路由规则由ExchangeType和Binding决定
-
Binding表示Queue和Exchange之间的绑定关系,每个绑定关系存在一个BindingKey,通过这种方式相当于在Exchange中建立一个路由关系表
-
生产者发送消息时,需要声明一个routingKey(路由键),Exchange获取到routingKey之后,根据routingKey和路由表中的BindingKey进行匹配,而匹配的规则是通过交换机类型ExchangeType来决定的
-
在RabbitMQ中,有三种类型的交换机:Direct 、Fanout 、Topic
1)Direct Exchange(直连交换机):具有路由功能的交换机,绑定到此交换机时需要指定一个routingKey,交换机发送消息时需要routingKey,会将消息发送到对应的队列,即 routingKey 和 BindingKey完全一致,相当于点对点的发送
2)Fanout Exchange(扇形交换机):广播机制,这种方式不会基于routingKey来匹配,而是将消息广播给绑定到当前Exchange上的所有队列上,速度最快,即在直连交换机的基础上增加模式匹配,即对routingKey进行模式匹配,* 代表一个单词,# 代表多个单词
3)Topic Exchange(主题交换机):正则表达式匹配,根据routingKey使用正则表达式进行匹配,符合匹配规则的Queue都会收到该消息
4)首部交换机(Headers Exchange):忽略routingKey,使用Headers信息(一个Hash的数据结构)进行匹配,优势在于可以有更多更灵活的匹配规则
如何保证RabbitMQ中的消息可靠传输
- 在RabbitMQ的整个消息传递过程中,有三种情况会存在消息丢失:
1)生产者将消息发送到RabbitMQ Server的过程中
从生产者发送消息的角度来说,RabbitMQ提供了一个Confirm(消息确认)机制,生产者发送消息到Server端以后,如果消息处理成功,Server端会返回一个ack消息。客户端可以根据消息的处理结果来决定是否要做消息的重新发送,从而确保消息一定到达RabbitMQ Server上
2)RabbitMQ Server收到消息后在持久化之前宕机,从而导致数据丢失
从RabbitMQ Server端来说,可以开启消息的持久化机制,即收到消息之后持久化到磁盘中
设置消息的持久化有两个步骤: - 创建Queue的时候设置为持久化
- 发送消息的时候,将消息投递模式设置为持久化投递
即便设置了持久化消息,但是仍有可能会出现,消息刷新到磁盘之前,RabbitMQ Server宕机导致消息丢失的问题,为了确保万无一失,需要结合Confirm消息确认机制一起使用
3)消费端收到消息还没来得及处理就宕机,导致RabbitMQ Server认为该消息已经签收
从消费端的角度来说,我们可以将消息的自动确认机制修改为手动确认,即消费端只有手动调用,消息确认方法才表示消息已经被签收,这可能会造成重复消费的问题,所以这里需要考虑幂等性的设计
如:为避免MQ重复消费导致数据多次被修改的问题,可以在接受到MQ消息时,将消息通过setnx命令写入到Redis中,一旦消息被消费过,就不会在消费
RabbitMQ如何实现高可用
RabbitMQ高可用实现方式有两种:
- 第一种:普通集群,在这种模式下,一个Queue的消息只会存在集群的一个节点上,集群中的其他节点会同步Queue所在节点的元数据,消息在生产和消费时,不管请求发送到集群的哪个节点,最终都会路由到Queue所在节点上去存储和拉取消息,这种方式并不能保证Queue的高可用性,但可以提升RabbitMQ消息的吞吐能力
- 第二种:镜像集群,即集群中的每个节点都会存储Queue的数据副本,在每次生产消息时,都需要将消息内容同步给集群中的其他节点,这种方式能够保证Queue的高可用性,但集群副本之间的同步会带来性能的损耗
另外,由于每个节点都保存了副本,我们还可以通过HAProxy实现负载均衡
多线程异步和MQ有什么区别
