SPP Net 目标检测网络学习笔记 (附代码)
论文地址:https://arxiv.org/pdf/1406.4729.pdf
代码地址:
1.是什么?
SPP Net是何凯明团队在R-CNN的基础上提出的一种网络模型,其核心思想是空间金字塔池化(Spatial Pyramid Pooling, SPP)。它主要解决了R-CNN不能适应不同尺寸的输入的问题。SPP-Net通过在最后的特征图与全连接层之间加入一种特殊的机制转换一下,使得网络可以适应不同尺寸的输入。具体来说,SPP-Net在卷积层后加入了一个金字塔池化层,将不同尺寸的特征图转换为固定的特征数量,进而输入到全连接层。这样,SPP-Net可以处理任意尺寸的输入图像,从而提高了目标检测的准确率和效率。
2.为什么?
SPPNet的研究动机主要包括两个方面:
1.卷积神经网络的全连接层需要固定输入的尺寸,而Selective search所得到的候选区域存在尺寸上的差异,无法直接输入到卷积神经网络中实现区域的特征提取,因此RCNN先将候选区缩放至指定大小随后再输入到模型中进行特征提取。
无论是通过区域裁剪还是缩放来实现区域大小的固定,其实都是一种次优的操作。如下图所示,可以很明显的看到,直接对候选框进行crop或者warp操作,会使图像出现失真。
2.RCNN使用Selective Search从图像中获取候选区域,然后依次将候选区域输入到卷积神经网络中进行图像特征提取,如果有2000个候选区域,则需要进行2000次独立的特征提取过程。然后,这2000个候选区域是存在一定程度的重叠的,所以如此设计会导致大量的冗余计算。
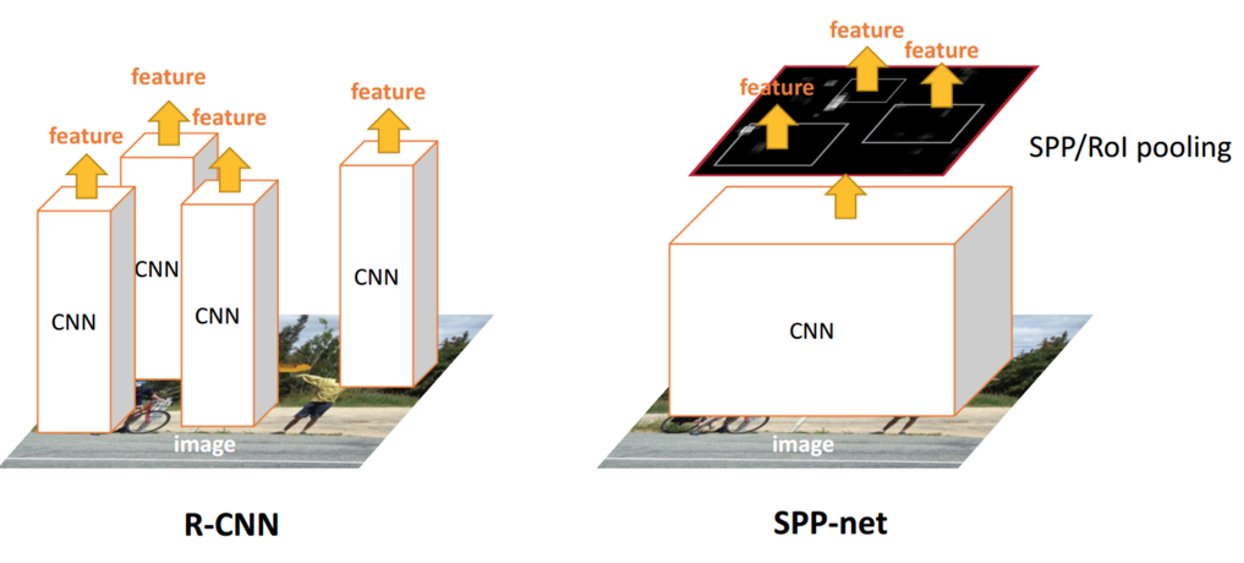
3. 关于图像尺寸的理解
众所周知,CNN一般都含有卷积部分和全连接部分,其中,卷积层不需要固定尺寸的图像,而全连接层是需要固定大小的输入。
所以当全连接层面对各种尺寸的输入数据时,就需要对输入数据进行crop(crop就是从一个大图扣出网络输入大小的patch,比如227×227),或warp(把一个边界框bounding box的内容resize成227×227)等一系列操作以统一图片的尺寸大小,比如224224(ImageNet)、3232(LenNet)、96*96等。
所以才如我们在上文中看到的,在R-CNN中,“因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN”。
但warp/crop这种预处理,导致的问题要么被拉伸变形、要么物体不全,限制了识别精确度
SPP Net的作者Kaiming He等人逆向思考,既然由于全连接FC层的存在,普通的CNN需要通过固定输入图片的大小来使得全连接层的输入固定。那借鉴卷积层可以适应任何尺寸,为何不能在卷积层的最后加入某种结构,使得后面全连接层得到的输入变成固定的呢?
这个“化腐朽为神奇”的结构就是spatial pyramid pooling layer。
4. 关于为何全连接层需要固定输入
全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。
由于其全相连的特性,一般全连接层的参数也是最多的。全连接层的权重矩阵是固定的,即每一次feature map的输入必须都得是一定的大小(即与权重矩阵正好可以相乘的大小),所以网络一开始输入图像的尺寸必须固定,才能保证传送到全连接层的feature map的大小跟全连接层的权重矩阵匹配。下图中连线最密集的2个地方就是全连接层,这很明显的可以看出全连接层的参数的确很多。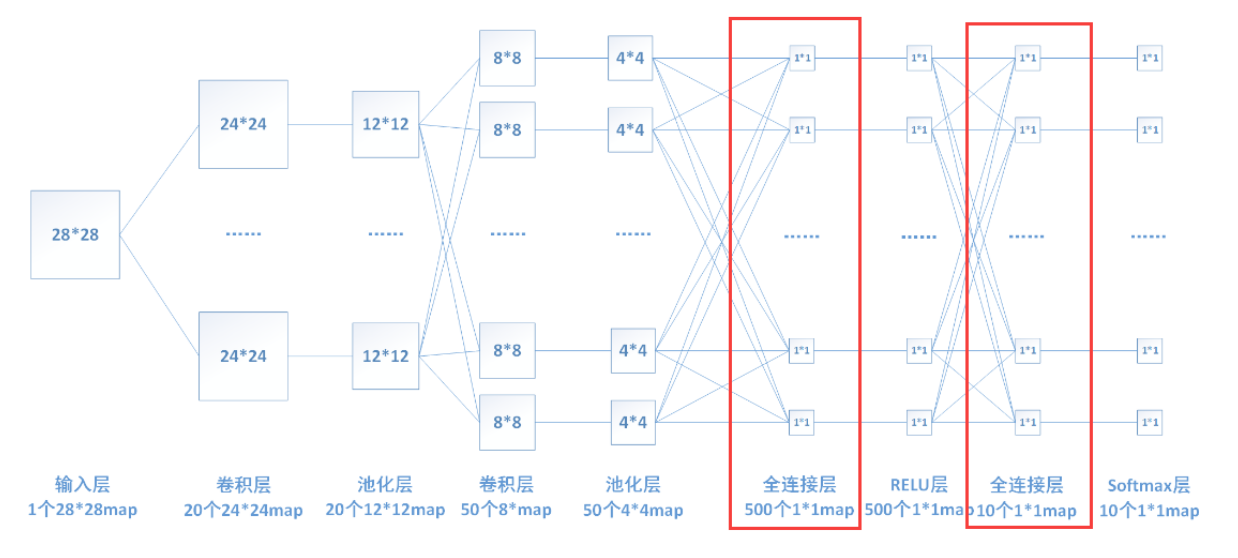
5. 与传统CNN的对比
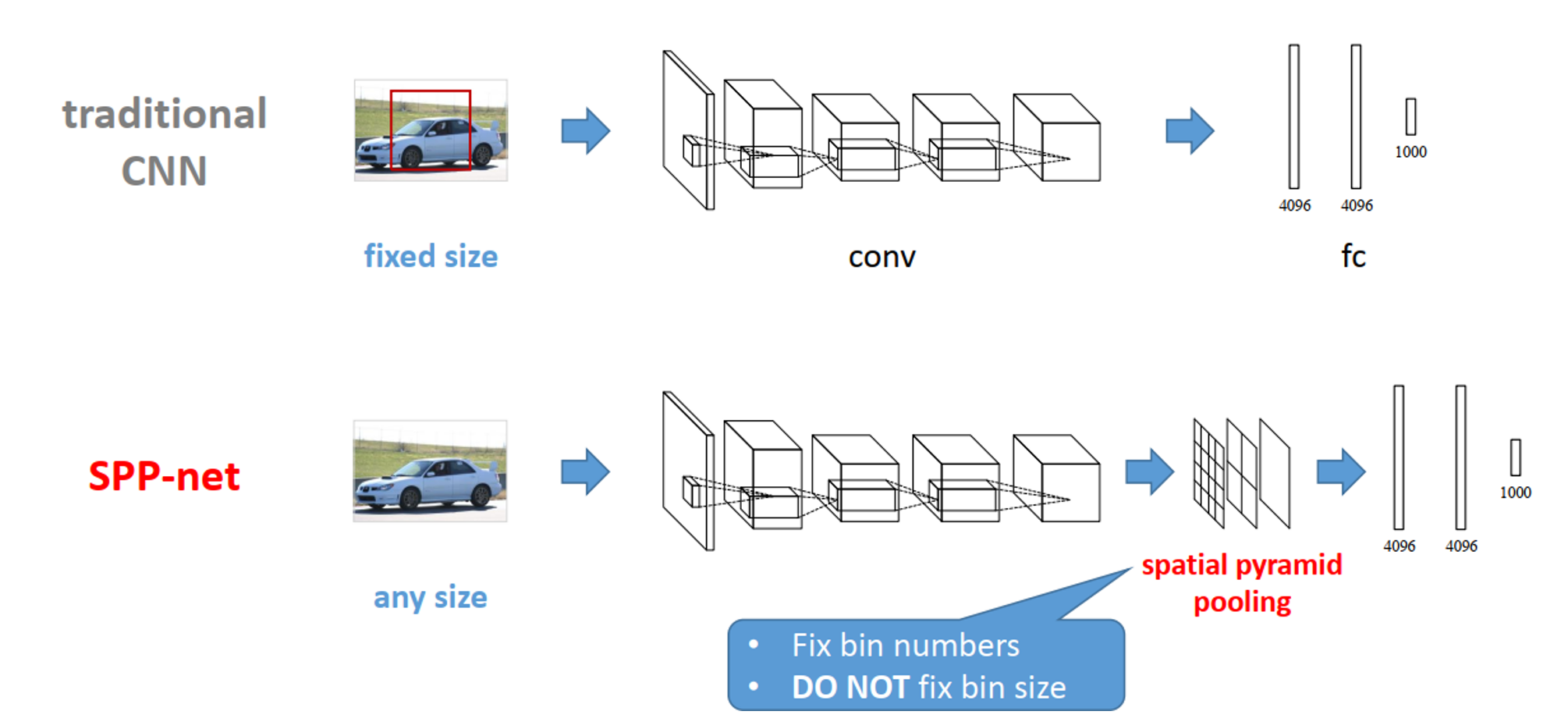
SPP Net的第一个贡献就是在最后一个卷积层后,接入了金字塔池化层,保证传到下一层全连接层的输入固定。
在普通的CNN机构中,输入图像的尺寸往往是固定的(比如224*224像素),输出则是一个固定维数的向量。SPP Net在普通的CNN结构中加入了ROI池化层(ROI Pooling),使得网络的输入图像可以是任意尺寸的,输出则不变,同样是一个固定维数的向量。
3.怎么样?
3.1网络结构

3.2 算法流程
SPP-Net的大致步骤还是跟R-CNN比较类似,
a. 首先也是通过SS算法进行候选框选取;
b. 接着将原图进行卷积池化进行特征提取,得到特征图;
c. 然后根据候选框的位置通过卷积池化层层映射,映射到特征图相应的区域
d. 接着将映射到特征图的区域输入到金字塔卷积池化层,进行特征数量固定;
e. 接着将固定好的特征输入到全连接层中,得到输出,进而训练网络。
f. 最后将网络训练好之后,将金字塔池化层得到的特征拿去做SVM的训练以及将卷积池化层的特征拿去做边框回归。
3.3 SPP
3.3.1 特征映射
R-CNN中候选框的特征是直接对每个候选框进行卷积池化操作得到的,那既然SPP-Net不对候选区域进行卷积池化操作,那么特征如何得到?
这里SPP-Net用了一种巧妙的方法,通过映射的方法来获取了每个候选框的特征。首先,通过可视化卷积层发现,输入图片某一个位置的特征,反应在特征图上也是相应的位置。如下图:
上图中,左侧是输入图片,中间是原图经过卷积池化层后得到的特征图的可视化图片,比如输入图片中右下角区域有一辆车,那么反应在特征图上右下角区域就比较亮一些。而右图则表示类似区域都会在特征图上产生强信号值。再如下图:
同样,上图中输入图片为一个人坐在凳子上,可视化特征图后即可发现,存在同样的特征映射关系。
所以这里就将SS算法选取的候选区域的位置记录下来,通过卷积池化层的比例映射到特征图上,提取出候选区域的特征图,然后输入到金字塔池化层中,进而训练网络。SPP-Net通过如此特征映射的手段进行了,快速特征提取,而不必向R-CNN那样,需要对每个候选区域进行卷积池化特征提取。
候选框区域的特征通过特征映射的方法进行获得,但是候选框大小不一,所以得到的特征图也是不同尺寸的,那么不同尺寸的特征图怎样输入到全连接层呢?接下来我们一起学习下金字塔池化是怎么回事儿。
映射
原始图片经过CNN变成了feature map,原始图片通过选择性搜索(SS)得到了候选区域,现在需要将基于原始图片的候选区域映射到feature map中的特征向量。
映射过程图参考如下:
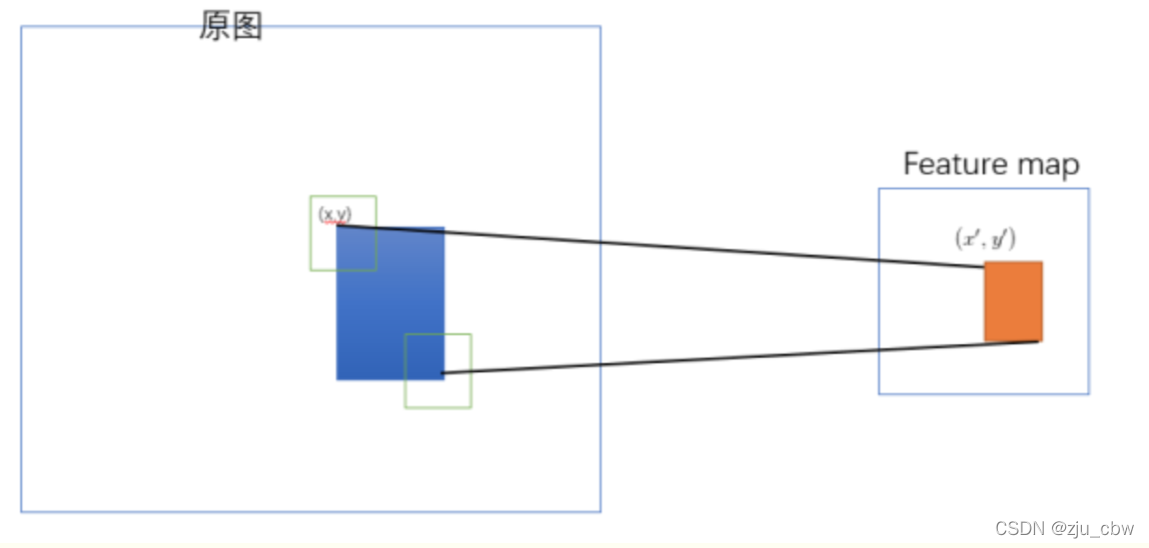
整个映射过程有具体的公式,如下
假设(x′,y′)(x′,y′)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关系与网络结构有关(原论文还做了 padding=kernel-size/2 的 Pad 操作):(x,y)=(S∗x′,S∗y′),即
左上角的点:x’=[x/S]+1
右下角的点:x’=[x/S]-1
其中 SS 就是CNN中所有的strides的乘积,包含了池化、卷积的stride。论文中使用S的计算出来为=16
3.3.2 金字塔池化
不同尺寸的特征图如何进入全连接层,直接看下图,下图中对任意尺寸的特征图直接进行固定尺寸的池化,来得到固定数量的特征。
如上图,以3个尺寸的池化为例,对特征图进行一个最大值池化,即一张特征图得取其最大值,得到1*d(d是特征图的维度)个特征;对特征图进行网格划分为2x2的网格,然后对每个网格进行最大值池化,那么得到4*d个特征;同样,对特征图进行网格划分为4x4个网格,对每个网格进行最大值池化,得到16*d个特征。
接着将每个池化得到的特征合起来即得到固定长度的特征个数(特征图的维度是固定的),接着就可以输入到全连接层中进行训练网络了。
3.3.3 spatial pyramid pooling
SSP层的任务是将任意大小的特征图转换成固定大小的特征向量。
假设原图输入是224x224,对于conv出来后的输出是13x13x256的,可以理解成有256个这样的Filter,每个Filter对应一张13x13的feature map。接着在这个特征图中找到每一个候选区域映射的区域,spp layer会将每一个候选区域分成1x1,2x2,4x4三张子图,对每个子图的每个区域作max pooling,得出的特征再连接到一起,就是(16+4+1)x256的特征向量,接着给全连接层做进一步处理,如下图:
子图的max pooling操作,以4X4为例:

划分了16张子图,取每张子图的max像素值。所以4x4会得出16个特征向量。加上2x2,1x1的一共就是21x256个特征向量。
3.4 代码实现
```python
#coding=utf-8
import math
import torch
import torch.nn.functional as F
# 构建SPP层(空间金字塔池化层)
class SPPLayer(torch.nn.Module):
def __init__(self, num_levels, pool_type='max_pool'):
super(SPPLayer, self).__init__()
self.num_levels = num_levels
self.pool_type = pool_type
def forward(self, x):
num, c, h, w = x.size() # num:样本数量 c:通道数 h:高 w:宽
for i in range(self.num_levels):
level = i+1
kernel_size = (math.ceil(h / level), math.ceil(w / level))
stride = (math.ceil(h / level), math.ceil(w / level))
pooling = (math.floor((kernel_size[0]*level-h+1)/2), math.floor((kernel_size[1]*level-w+1)/2))
# 选择池化方式
if self.pool_type == 'max_pool':
tensor = F.max_pool2d(x, kernel_size=kernel_size, stride=stride, padding=pooling).view(num, -1)
else:
tensor = F.avg_pool2d(x, kernel_size=kernel_size, stride=stride, padding=pooling).view(num, -1)
# 展开、拼接
if (i == 0):
x_flatten = tensor.view(num, -1)
else:
x_flatten = torch.cat((x_flatten, tensor.view(num, -1)), 1)
return x_flatten
参考:
【目标检测】SPP-Net论文理解(超详细版本)
目标检测算法SPP-Net详解
SPPNet网络结构详解