python实验16_网络爬虫
实验16:网络爬虫
1.实验目标及要求
(1)掌握简单爬虫方法。
2. 实验主要内容
爬取中国票房网
① 爬取中国票房网(www.cbooo.cn)2019年票房排行榜前20名的电影相关数据
代码部分:
import time
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
web=Edge()
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
# 定位下拉列表
sel_el=web.find_element(By.XPATH,'//*[@id="OptionDate"]')
sel=Select(sel_el)
sel.select_by_value("2019")
time.sleep(2)
# 输出标头信息
thead=web.find_element(By.XPATH,'//*[@id="TableList"]/table/thead/tr')
print(thead.text)
# 查询前二十个电影
for i in range(1,21):
tr=web.find_element(By.XPATH,'//*[@id="TableList"]/table/tbody/tr['+str(i)+
']')
print(tr.text.replace('\n',' '))
web.close()
输出结果:
影片名称 类型 总票房(万) 平均票价 场均人次 国家及地区 上映日期
1 哪吒之魔童降世 动画 500,359 36 24 中国 2019-07-26
2 流浪地球 科幻 468,150 45 29 中国 2019-02-05
3 复仇者联盟4:终局之战 动作 424,922 49 23 美国 2019-04-24
4 我和我的祖国 剧情 312,366 39 36 中国/中国香港 2019-09-30
5 中国机长 剧情 290,354 38 27 中国 2019-09-30
6 疯狂的外星人 喜剧 221,275 42 30 中国 2019-02-05
7 飞驰人生 喜剧 172,733 42 25 中国 2019-02-05
8 烈火英雄 灾难 170,339 36 19 中国 2019-08-01
9 少年的你 剧情 155,623 36 16 中国 2019-10-25
10 速度与激情:特别行动 动作 143,430 36 15 美国 2019-08-23
11 蜘蛛侠:英雄远征 动作 141,751 36 17 美国 2019-06-28
12 扫毒2:天地对决 剧情 131,143 36 17 中国/中国香港 2019-07-05
13 大黄蜂 动作 114,956 36 11 美国 2019-01-04
14 攀登者 剧情 109,501 37 22 中国 2019-09-30
15 惊奇队长 动作 103,518 37 14 美国 2019-03-08
16 比悲伤更悲伤的故事 爱情 95,792 31 15 中国台湾 2019-03-14
17 哥斯拉2:怪兽之王 科幻 93,737 37 15 美国 2019-05-31
18 阿丽塔:战斗天使 动作 89,698 38 14 美国/加拿大/阿根廷 2019-02-22
19 银河补习班 剧情 87,772 34 16 中国 2019-07-18
20 误杀 剧情 83,173 34 15 中国 2019-12-13
综合爬虫统计数据
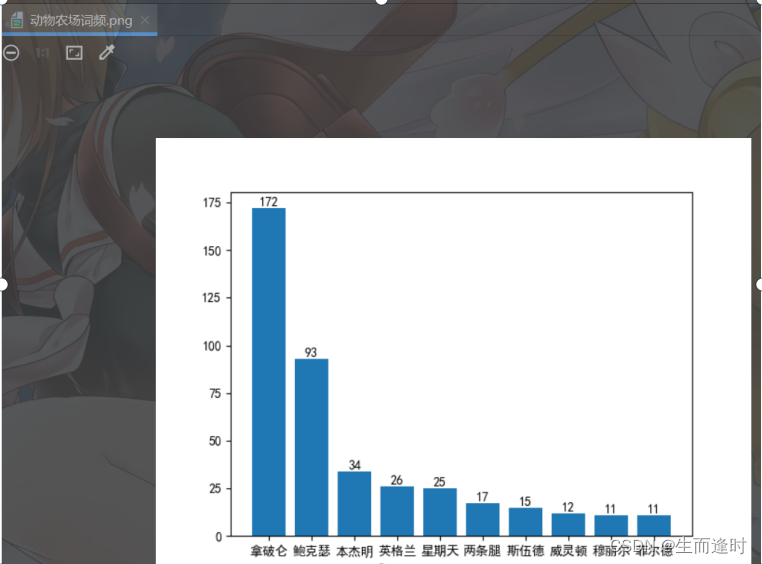
② 请编程实现如下操作:从网址http://www.kanunu8.com/book3/6879/上爬取小说《动物农场》的所有章节;分析小说《动物农场》,按词频输出三个字的词汇前 10 项;根据词频画出这10个词汇的直方图,并另存为文件“动物农场词频.png”。
代码部分:爬虫部分
import time
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
web=Edge()
web.get("https://www.kanunu8.com/book3/6879/131779.html")
text=open('动物农场.txt', 'a', encoding='gbk')
# 循环十章
for _ in range(10):
# 定位到文章内容
p=web.find_element(By.XPATH,'/html/body/div/table[5]/tbody/tr/td[2]/p')
text.write(p.text.replace('\n',''))
time.sleep(2)
# 点击下一页
click=web.find_element(By.XPATH,'/html/body/div/table[7]/tbody/tr/td/table/
tbody/tr/td[3]/strong/a').click()
time.sleep(20)
输出结果:
代码部分:词频分析部分
import jieba
import matplotlib.pyplot as plt
s=open('动物农场.txt', 'r', encoding='utf-8',errors='ignore').read()
jieba.load_userdict('动物农场.txt')
words=jieba.lcut(s) # 进行分词操作
stopwords_list=[] # 创建中文停用词列表
with open('./作业十二/stopword.txt','r',encoding='utf-8') as f:
for line in f:
line = line[:-1]
stopwords_list.append(line)
words_dict={}
for word in words:
# 长度大于1和不在停用词中的词 保存到字典并记录词频
if word not in stopwords_list and len(word)!=1:
words_dict[word]=words_dict.get(word,0)+1
words_list=list(words_dict.items())
words_list.sort(key=lambda x:x[1],reverse=True) #按词频大小排序
# 分别记录三个字词和词频
three_words=[]
three_words_num=[]
num=0
for three_word in words_list:
if len(three_word[0])==3 and num<10 and three_word[0]!='实际上' and three_word[0]!='第一次':
three_words.append(three_word[0])
three_words_num.append(three_word[1])
num+=1
# 画图
plt.bar(three_words,three_words_num)
# 写上高度
for i in range(len(three_words)):
plt.text(three_words[i],three_words_num[i],three_words_num[i],va="bottom",
ha="center")
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.savefig('动物农场词频.png')
plt.show()