论文阅读 - ANEMONE: Graph Anomaly Detection with Multi-Scale Contrastive Learning
目录
摘要
1 简介
2 问题陈述
3 PROPOSED ANEMONE FRAMEWORK
3.1 多尺度对比学习模型
3.1.1 增强的自我网络生成
3.1.2 补丁级对比网络
3.1.3 上下文级对比网络
3.1.4 联合训练
3.2 统计异常估计器
4 EXPERIMENTS
4.1 Experimental Setup
4.1.1 Datasets
4.1.2 Baselines
4.1.3 Metric
4.2 有效性评价
4.3 Ablation Study and Parameter Analysis
论文链接:https://shiruipan.github.io/publication/cikm-21-jin/cikm-21-jin.pdf
摘要
图的异常检测在网络安全、电子商务和金融欺诈检测等各个领域都发挥着重要作用。然而,现有的图异常检测方法通常考虑单一尺度的图视图,这导致它们从不同角度捕获异常模式的能力有限。为此,我们引入了一种新颖的图形异常检测框架,即 ANEMONE,以同时识别多个图尺度中的异常。
具体来说,ANEMONE 首先利用具有多尺度对比学习目标的图神经网络主干编码器,通过同时学习补丁和上下文级别的实例之间的协议来捕获图数据的模式分布。然后,我们的方法采用统计异常估计器从多个角度根据一致程度评估每个节点的异常。在三个基准数据集上的实验证明了我们方法的优越性。
异常检测,图形神经网络,对比学习
1 简介
近年来,由于图结构数据在现实系统建模中的广泛应用,包括电子商务和金融[16],图上的异常检测在数据挖掘社区[9]中受到越来越多的关注。以电子商务欺诈检测为例,异常检测算法可以通过分析用户的属性(即属性)和连接(即结构)来帮助识别欺诈卖家。
与仅考虑每个样本的属性信息而忽略其潜在相关性的传统异常检测方法不同,图异常检测另一方面将样本(即节点)属性以及拓扑信息(即节点邻接度)纳入同时考虑[5]。早期的方法利用自我网络分析 [11]、残差分析 [4] 或 CUR 分解 [10] 等浅层机制来检测异常节点,这些节点无法从高维属性中学习信息知识。最近提出的方法 [1、5] 利用深度图自动编码器进行异常检测并显着提高性能。最近,通过引入图自监督学习 [7],CoLA [6] 将对比学习集成到图神经网络 (GNN) [14] 中,以有效检测图异常。
尽管取得了成功,但这些方法主要从单一尺度的角度检测异常,忽略了图形中的节点异常经常出现在不同尺度上的事实。例如,一些电子商务作弊者可能直接与少量不相关的物品/用户进行交易(即本地异常),而其他作弊者则倾向于隐藏在地下行业的大型社区中(即全球异常)。这种尺度的异质性导致现有方法的性能欠佳。
为了弥合这一差距,我们提出了一个具有多尺度对比学习(缩写为 ANEMONE)的图异常检测框架来检测图中的异常节点。首先,为了捕获不同尺度的异常模式,我们提出的框架通过两个基于 GNN 的模型同时执行补丁级和上下文级对比学习。此外,ANEMONE 采用一种新颖的异常估计器,通过利用多轮对比分数的统计来预测每个节点的异常。这项工作的主要贡献总结如下:
我们提出了一个多尺度对比学习框架 ANEMONE,用于图形异常检测,它捕获不同尺度的异常模式。
我们设计了一种新颖的基于统计的算法,以使用所提出的对比模式来估计节点异常。
我们对三个基准数据集进行了广泛的实验,以证明 ANEMONE 在检测图上的节点级异常方面的优越性。
2 问题陈述
在本文中,我们关注属性图的异常检测问题。令 G = (A, X) 为节点集 V = {, · · · ,
} 的属性图。 A ∈
表示二元邻接矩阵,其中 Ai,j = 1 表示存在链接,否则 Ai,j = 0。X ∈
表示属性矩阵,其中第 i- 行 X[i, :] ∈ R 表示的属性向量。使用上述符号,我们将图形异常检测问题形式化如下:
定义 2.1(图形异常检测)。给定一个属性图 G = (A, X),目标是学习函数 Y (·) : →
,它将图作为输入数据并输出异常分数向量 y 来衡量每个节点的异常程度。具体来说,输出评分向量y中的第i-个元素
表示
的异常程度,评分越大表示异常程度越高.
值得注意的是,图形异常检测是在无监督的情况下进行的,这意味着在训练阶段无法访问groundtruth标签.
3 PROPOSED ANEMONE FRAMEWORK
我们提出了一个框架,即 ANEMONE,它基于多尺度对比学习 [2] 用于图形异常检测。我们方法的整体流程如图 1 所示。对于选定的目标节点,ANEMONE 通过利用两个主要组件计算该节点的异常分数:多尺度对比学习模型和统计异常估计器。
在多尺度对比学习模型中,两个基于 GNN 的对比网络分别学习补丁级别(即节点与节点)一致性和上下文级别(即节点与自我网络)一致性。之后,统计异常估计器聚合多个增强自我网络获得的补丁和上下文级别分数,并通过统计估计计算目标节点的最终异常分数。我们将在以下部分介绍这两个组件。
3.1 多尺度对比学习模型
3.1.1 增强的自我网络生成
在多尺度对比学习模型中,我们首先生成目标节点的两个自我网络,并将数据增强作为网络的输入。
ego-nets 生成背后的动机是捕获目标节点周围的子结构(这被证明与节点的异常 [6, 8] 高度相关),以及为模型训练提供足够多样性的输入数据和统计估计。
考虑到上述情况,我们采用基于随机游走的算法 RWR [12] 作为我们的数据扩充策略。具体来说,以目标节点为中心,我们采样两个具有固定大小的自我网络,表示为 ![]() 和
和 ![]() 。在每个自我网络中,我们将节点集中的第一个节点设置为中心(目标)节点。
。在每个自我网络中,我们将节点集中的第一个节点设置为中心(目标)节点。
为了防止在接下来的对比学习步骤中发生信息泄漏,在将自我网络馈送到对比网络之前,应该在自我网络中实施名为目标节点掩码的预处理。具体来说,我们将目标节点的属性向量替换为零向量:![]() 。
。
3.1.2 补丁级对比网络
patch-level contrastive network 的目标是学习掩蔽目标节点在 ego-net ![]() 中的嵌入与原始目标节点嵌入之间的一致性。首先,通过 GNN 模块获得 ego-net 的节点嵌入
中的嵌入与原始目标节点嵌入之间的一致性。首先,通过 GNN 模块获得 ego-net 的节点嵌入 ![]() :
:

其中 是 GNN 的参数集。为简单起见,这里我们直接采用一层GCN [3],其中
![]() 是加入自环的邻接矩阵,
是加入自环的邻接矩阵,![]() 是ego-net
是ego-net ![]() 的度矩阵 ,
的度矩阵 , ![]() 为GCN层的权重矩阵,为embedding的维数,
为GCN层的权重矩阵,为embedding的维数,(·)为ReLU激活函数。这里 GCN 可以替换为其他类型的 GNN。
对于补丁级对比学习,我们通过让 ![]() 来选择掩码目标节点的嵌入。值得注意的是,虽然相应的输入
来选择掩码目标节点的嵌入。值得注意的是,虽然相应的输入 ![]() 是零向量,但嵌入
是零向量,但嵌入![]() 通过 GNN 聚合 ego-net 中其他节点的属性来提供信息。
通过 GNN 聚合 ego-net 中其他节点的属性来提供信息。
然后,ANEMONE 通过 MLP 模块计算目标节点的嵌入。我们将 的属性向量表示为
![]() ,目标节点嵌入
,目标节点嵌入 ![]() 给出如下
给出如下
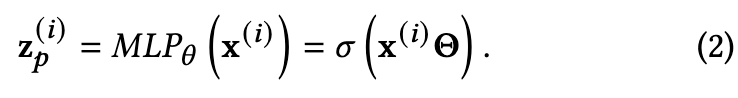
这里的权重与等式 (1)中的 GNN 共享,这确保 ![]() 和
和 ![]() 被投影到相同的嵌入空间中。
被投影到相同的嵌入空间中。
之后,构建了一个对比学习模块来学习 ![]() 和
和 ![]() 之间的一致性。具体来说,我们利用双线性层来计算它们的相似度分数:
之间的一致性。具体来说,我们利用双线性层来计算它们的相似度分数:
![]()
其中 Wp 是可训练矩阵,(·) 是 Sigmoid 函数。
为了学习一个有区别的对比网络,我们引入了一种用于模型训练的负采样策略。也就是说,对于给定的分数 ![]() (为了区分,我们将其表示为“正分数”),我们通过以下方式计算负分数
(为了区分,我们将其表示为“正分数”),我们通过以下方式计算负分数 ![]()
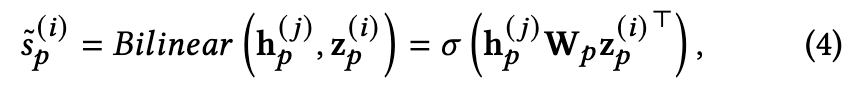
其中 ![]() 是从以另一个节点为中心的自我网络获取的,确保 i≠j 。在实践中,我们的对比学习模型以小批量方式进行训练。因此,可以很容易地从同一批次的其他目标节点中获取
是从以另一个节点为中心的自我网络获取的,确保 i≠j 。在实践中,我们的对比学习模型以小批量方式进行训练。因此,可以很容易地从同一批次的其他目标节点中获取 ![]() 。使用
。使用 ![]() 和
和![]() ,补丁级对比网络使用 Jensen-Shannon 散度 [13] 目标函数进行训练:
,补丁级对比网络使用 Jensen-Shannon 散度 [13] 目标函数进行训练:

3.1.3 上下文级对比网络
对称地,上下文级对比网络与补丁级对比网络具有相似的架构。首先,类似于Eq (1),带有参数集的孪生 GNN 模块从输入的自我网络 ![]() 生成节点嵌入
生成节点嵌入 ![]() ,其公式为:
,其公式为:

请注意,上下文级对比网络与补丁级对比网络具有不同的参数集,因为两个尺度的对比应该在不同的嵌入空间中进行 。
补丁级和上下文级对比的主要区别在于,后者试图学习目标节点嵌入和自我网络嵌入之间的一致性,这是通过读出模块获得的:

在本文中,我们采用平均池化作为我们的读出函数。
为了将目标节点的属性投影到相同的嵌入空间,利用带有参数的 MLP 模块(类似于等式(2))来计算![]() 。随后,上下文级别的分数
。随后,上下文级别的分数 ![]() 由具有评分矩阵 W 的双线性函数估计。最后,上下文级网络由目标函数训练:
由具有评分矩阵 W 的双线性函数估计。最后,上下文级网络由目标函数训练:
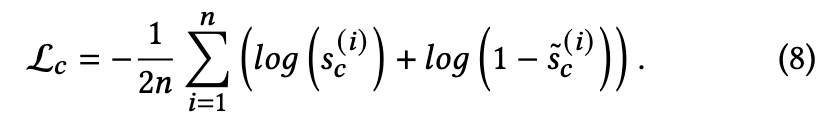
3.1.4 联合训练
在训练阶段,我们共同学习两个对比网络。总体目标函数为:
![]()
其中 ∈ [0, 1] 是一个权衡参数,用于平衡两个组件之间的重要性
3.2 统计异常估计器
在多尺度对比学习模型训练好后,ANEMONE 利用统计异常估计器计算推理阶段每个节点的异常分数。
首先,对于一个给定目标节点,我们分别为补丁级和上下文级对比网络生成R个自我网络。同时,对负样本进行数量相等的采样。将它们送入对应的对比网络,我们一共得到4个分数,分别是:![]() 。
。
我们假设异常节点与其相邻结构和上下文的一致性较小。因此,我们将基本分数表示为负分数和正分数之间的差值:
![]()
其中下标“view”表示“p”或“c”,并且j∈[1,····,R]。
然后,我们考虑一种用于异常估计的统计方法。背后的直觉是:1)异常节点具有相对较大的基础分数; 2)异常节点在多次自我网络采样下基础分数不稳定。因此,我们将统计异常分数 ![]() 和
和 ![]() 定义为基本分数的均值和标准差之和:
定义为基本分数的均值和标准差之和:
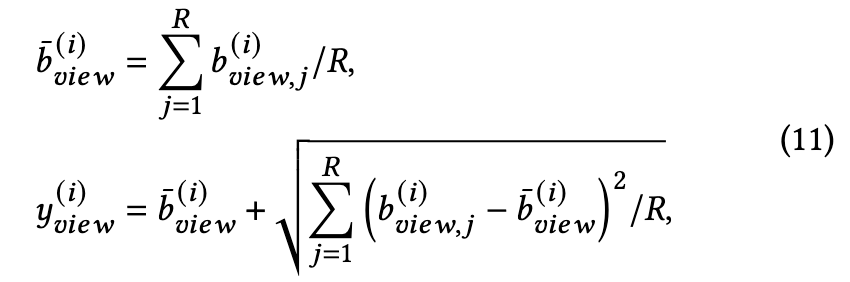
其中下标“view”代表“p”或“c”。最后,我们将 ![]() 和
和 ![]() 组合成最终的
组合成最终的![]() 异常分数
异常分数 ,其中方程式(9) 中的参数 作为权衡项:
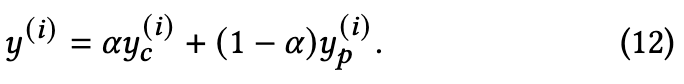
4 EXPERIMENTS
4.1 Experimental Setup
4.1.1 Datasets
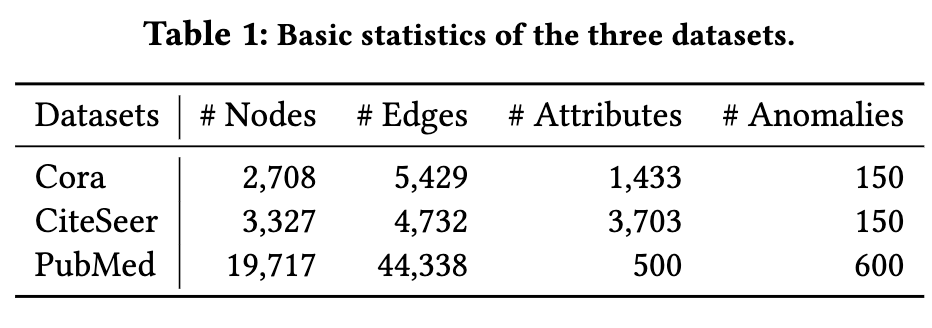
我们对三个著名的引文网络数据集进行了广泛的实验,即 Cora、CiteSeer 和 PubMed。表 1 总结了数据集的统计数据。由于默认情况下这些引文数据集没有异常,并且为了评估我们检测不同类型异常的方法,我们按照之前的工作 [1、6] 手动注入相同数量的属性和结构异常节点。
4.1.2 Baselines
我们将 ANEMONE 与以下方法进行比较:AMEN [11]、Radar [4]、ANOMALOUS [10]、DOMINANT [1] 和 CoLA [6]。我们添加了 CoLA 的一个变体,CoLA,它将所提出的统计异常估计器集成到 CoLA 中。我们的代码在 GitHub 1 上可用,包括超参数设置。
4.1.3 Metric
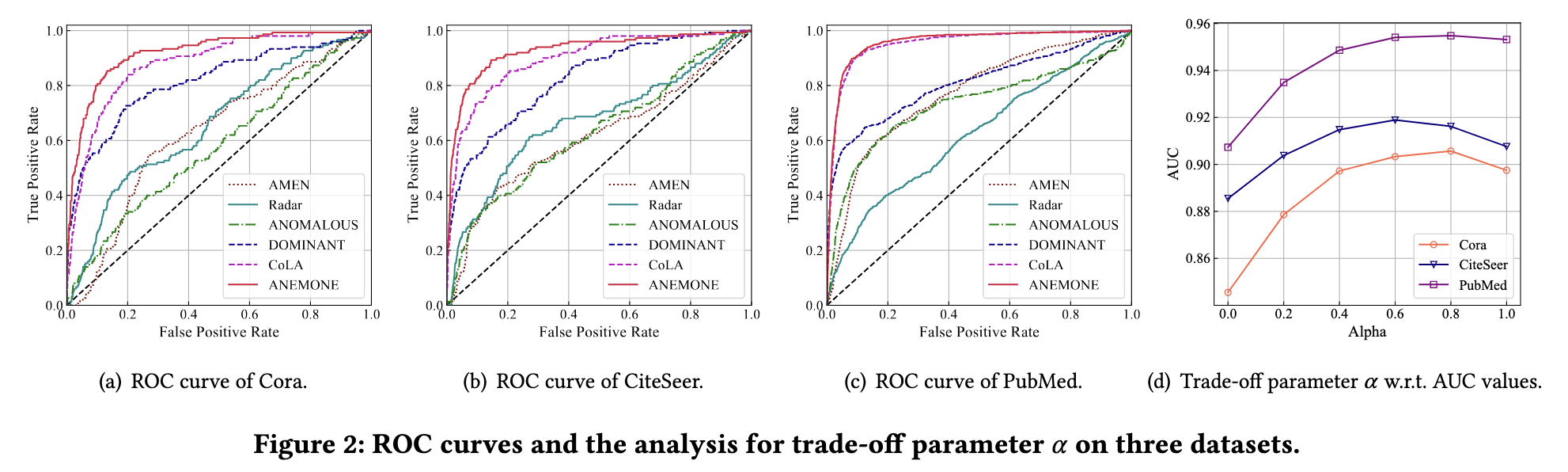
采用广泛应用的指标 ROC-AUC 来评估异常检测的性能。 ROC 曲线表示真阳性率与假阳性率的关系图,而 AUC 是 ROC 曲线下的面积。 AUC的值在[0, 1]之间,越大表示性能越好
4.2 有效性评价
ROC 曲线如图 2(a)-(c) 所示,而 AUC 的比较在表 2 中给出。我们做出以下观察:
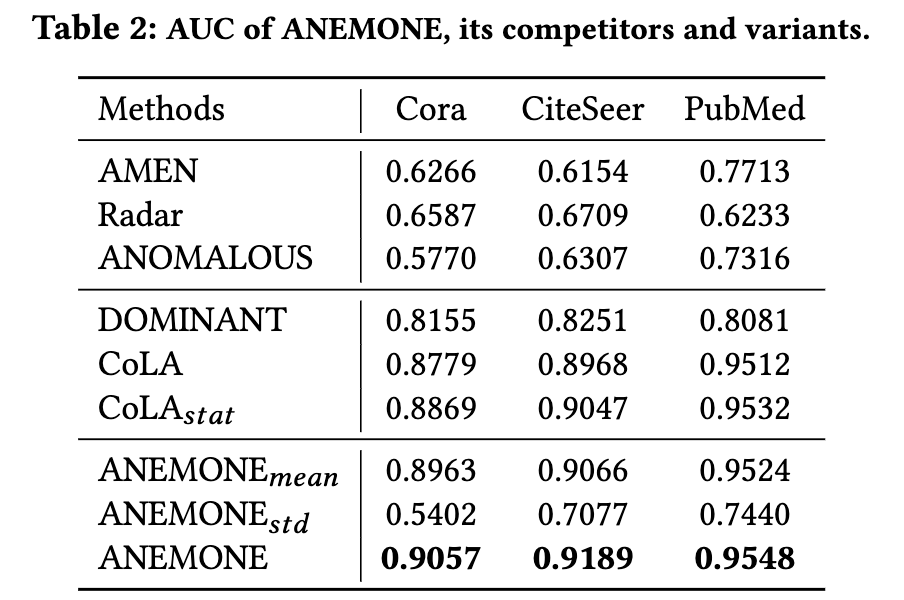
一般来说,ANEMONE 在三个基准数据集上总是优于所有基线方法,这说明多尺度对比学习技术和统计异常估计器的结合显着有利于节点级异常检测。
基于深度学习的方法,即 DOMINANT、CoLA 和 ANEMONE,明显优于浅层方法,表明浅层机制无法从高维属性和复杂的底层图结构中捕获异常模式。
CoLA 显示出优于 CoLA 的性能增益,验证了所提议的统计异常估计器的有效性。
4.3 Ablation Study and Parameter Analysis
我们进一步比较了 ANEMONE 及其变体的结果,即 ANEMONE_mean 和 ANEMONE_std,它们在估计异常分数时仅考虑平均值或标准差。
正如我们在表 2 中看到的那样,异常估计器中的两个组件都对检测异常做出了贡献,并且基本分数的平均值与节点级异常具有更大的相关性。此外,将这两个术语结合在一起的 ANEMONE 实现了最佳性能。两个对比量表的有效性分析结果如图 2(d) 所示。我们观察到,当 Cora 等于 0.8,CiteSeer 等于 0.6,PubMed 等于 0.8 时,可以获得最佳性能。较大或较小的值都会导致性能下降。我们得出结论,补丁级别和上下文级别的对比性都可以暴露相应规模的排他性异常。综合考虑两个角度,我们可以获得最好的结果。