Redis 主从

目录
编辑一、构建主从架构
1、集群结构
2、准备实例和配置
(1)创建目录
(2)修改原始配置
(3)拷贝配置文件到每个实例目录
(4)修改每个实例的端口,工作目录
(5)修改每个实例的声明 IP
3、启动
4、开启主从关系
二、数据同步原理
1、全量同步
2、增量同步
3、主从同步的优化
一、构建主从架构
1、集群结构
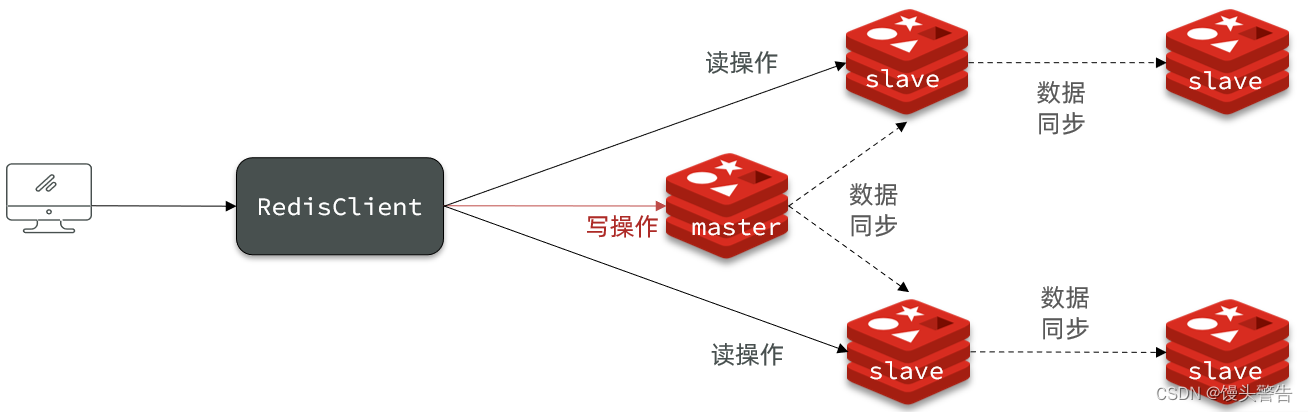
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
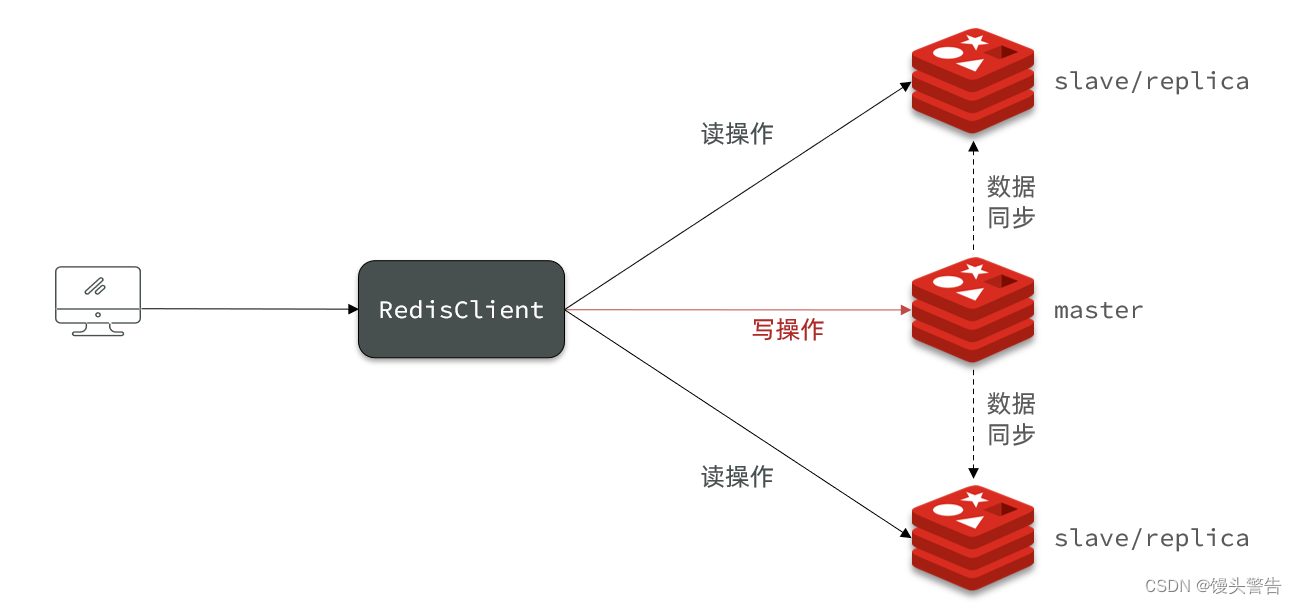
为什么 Redis 要做成主从集群而不是传统的负载型集群呢?
这是因为 Redis 应用当中,大多数都是 读多写少 ,正因如此,更多的是面对 "读" 的压力,搭建主从集群可以实现读写分离,多个从节点共同承担 "读" 的请求,使 "读" 的并发能力大幅度提升
但是主从集群必须得保证:客户端不管是读的哪个从节点,都必须拿到的是相同的结果,那么如何保证呢?
就需要 master 把它上面的数据同步给每一个 slave / replica 节点
共包含三个节点,一个主节点,俩个从节点
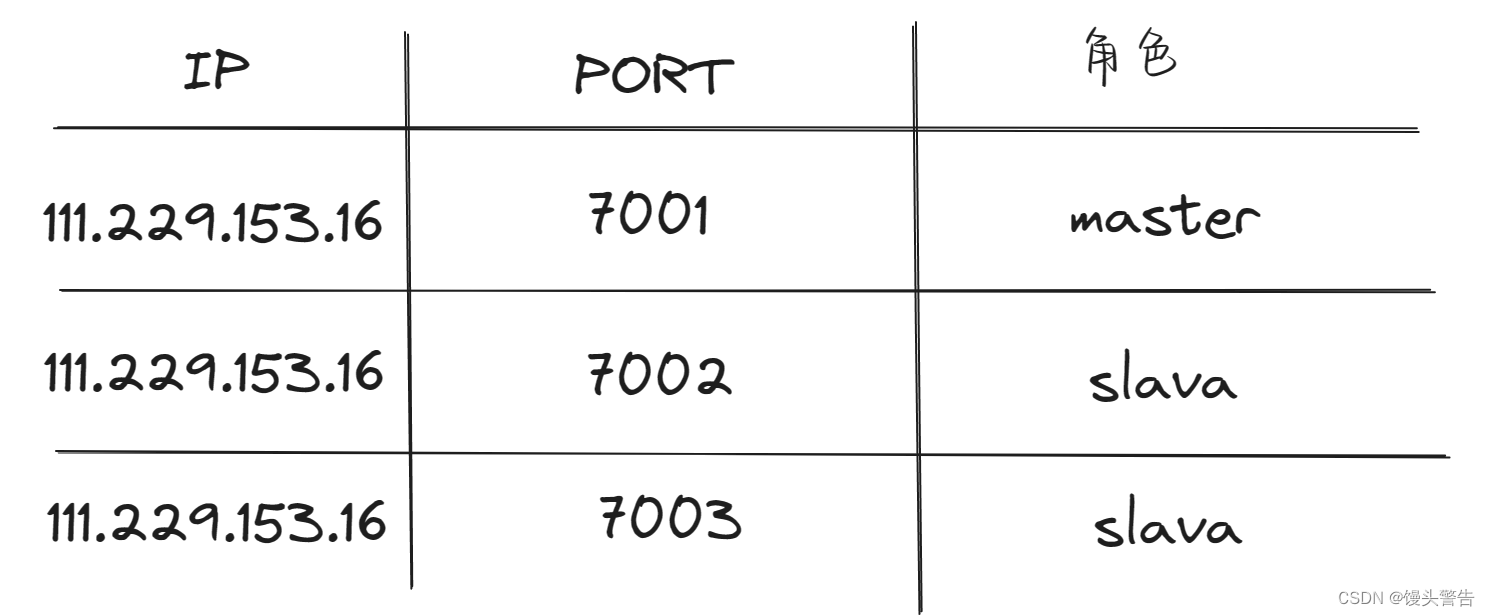
这里我在同一台服务器中开启 3 个 redis 实例,搭建主从集群,信息如下:
2、准备实例和配置
要在一台虚拟机开启 3 个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录
(1)创建目录
我们创建 3 个文件夹,名字分别叫:7001,7002,7003
# 进入到 tmp 目录
cd tmp
# 创建 7001,7002,7003
mkdir 7001 7002 7003(2)修改原始配置
修改 redis.conf 文件,将其中持久化模式改为默认的 RDB 模式,AOF 保持关闭


(3)拷贝配置文件到每个实例目录
然后将 redis.conf 文件拷贝到三个目录中(在 /tmp 目录下执行下列命令)
# 第一种:逐个拷贝
cp /usr/redis/redis.conf 7001
cp /usr/redis/redis.conf 7002
cp /usr/redis/redis.conf 7003
# 第二种:一键拷贝
echo 7001 7002 7003 | xargs -t -n 1 cp /usr/redis/redis.conf(4)修改每个实例的端口,工作目录
修改每个文件夹内的配置文件,将端口分别改为 7001,7002,7003,将 RDB 文件保存位置都改成自己所在的目录(这里的 7000 对应的是 redis 的端口,我之前修改过)
sed -i -e 's/7000/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/7000/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/7000/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf(5)修改每个实例的声明 IP
虚拟机本身有多个 IP,为了避免混乱,我们将 redis.conf 文件中指定每一个实例的绑定 ip 信息
# redis 实例的声明 IP
replica-announce-ip 111.229.153.16每个目录都要改,我们一键完成修改
sed -i 'la replica-announce-ip 111.229.153.16' 7001/redis.conf
sed -i 'la replica-announce-ip 111.229.153.16' 7002/redis.conf
sed -i 'la replica-announce-ip 111.229.153.16' 7003/redis.conf3、启动
为了方便查看日志,我们打开三个窗口,分别启动 3 个 redis 实例,启动命令:
./redis-server /usr/tmp/7001/redis.conf
./redis-server /usr/tmp/7002/redis.conf
./redis-server /usr/tmp/7003/redis.conf

4、开启主从关系
现在这三个实例还没有任何的关系,要配置主从可以使用 replicaof 或者 slaveof(5.0之前)命令
一共有两种模式:
永久模式:
修改配置文件,在 redis.conf 中添加一行配置: slaveof <masterip> <masterport>
临时模式(重启后失效):
使用 redis-cli 客户端连接到 redis 服务,执行命令:slaveof <masterip> <masterport>

意义:让 7002 成为 7001 的从节点
我们可以通过 info replication 来查看集群状态信息

二、数据同步原理
1、全量同步
主从第一次同步是全量同步:
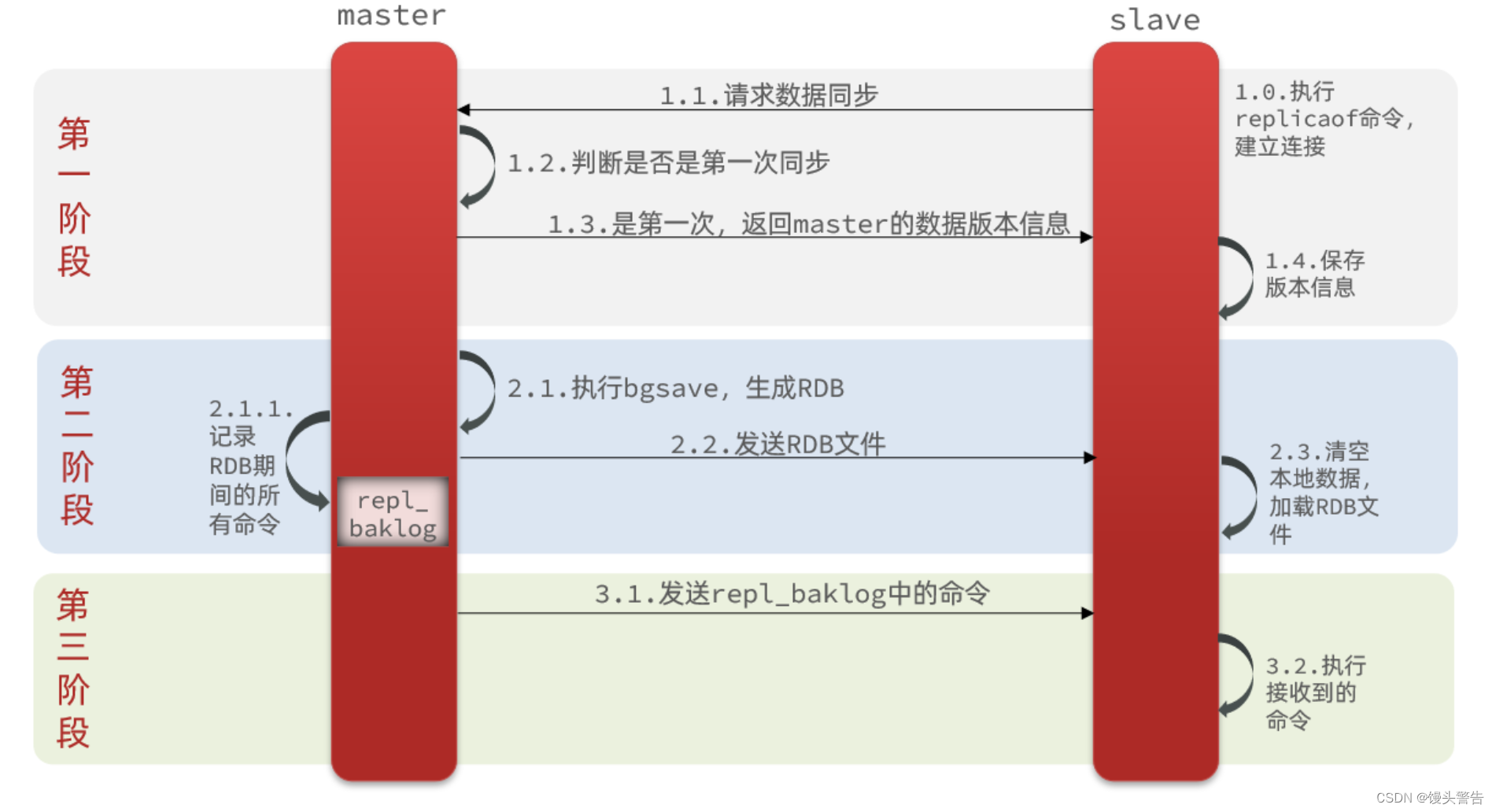
slave 在和 master 第一次建立连接的时候,需要执行 replicaof 命令,然后 slave 就可以向 master 发起请求了,与此同时,master 会判断是否是第一次同步,如果是第一次,就会返回 master 的版本信息
然后 master 执行 bgsave 生成 RDB,RDB 里面记录了完整的内存信息,master 将这个 RDB 发送给 slave,slave 清空本地数据,并加载 RDB 文件,这样就能确保 slave 与 master 的数据基本一致
为什么说是 slave 和 master 的数据基本一致,而不是完全一致呢?
这是因为 bgsave 是异步执行的,在执行 bgsave 的时候,主进程还会去处理用户的请求,也就是说会有新数据的写入,而新数据是并没有同步给 slave 的
此时主进程除了处理新的命令以外,还会把这些 RDB 期间的命令记录在 repl_baklog 缓冲区中
repl_baklog + RDB 里面的数据,加载一起,就是 master 的数据
随后,master 将 repl_baklog 中的命令发送给 slave
这个过程为什么叫全量同步呢?
因为这里面有一个 RDB 的过程,会把内存形成快照,整体发送给 slave ,所以叫全量同步,但是这种同步实际上是比较消耗性能的,因为生成 RDB 文件的速度是比较慢的,所以只有在第一次建立连接的时候才会进行全量同步
那么 master 如何判断 slave 是不是第一次进行同步数据呢?
先来了解几个概念:
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的
replid offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
由此,可以根据 replid 来判断是否是第一次同步,replid 只要不一致,就是第一次同步
完整

2、增量同步
slave重启后同步,则执行增量同步
 offset 是记录在了 repl_baklog 的哪个部分呢?如何找到之后的那些命令呢?
offset 是记录在了 repl_baklog 的哪个部分呢?如何找到之后的那些命令呢?
repl_baklog 本质是一个数组,而这个数组比较特殊,它的大小是固定的,但是当数组内数据记满了之后,还会接着记录数据,会从 0 开始将原来的数据进行覆盖,形成了一种环形的记录方式
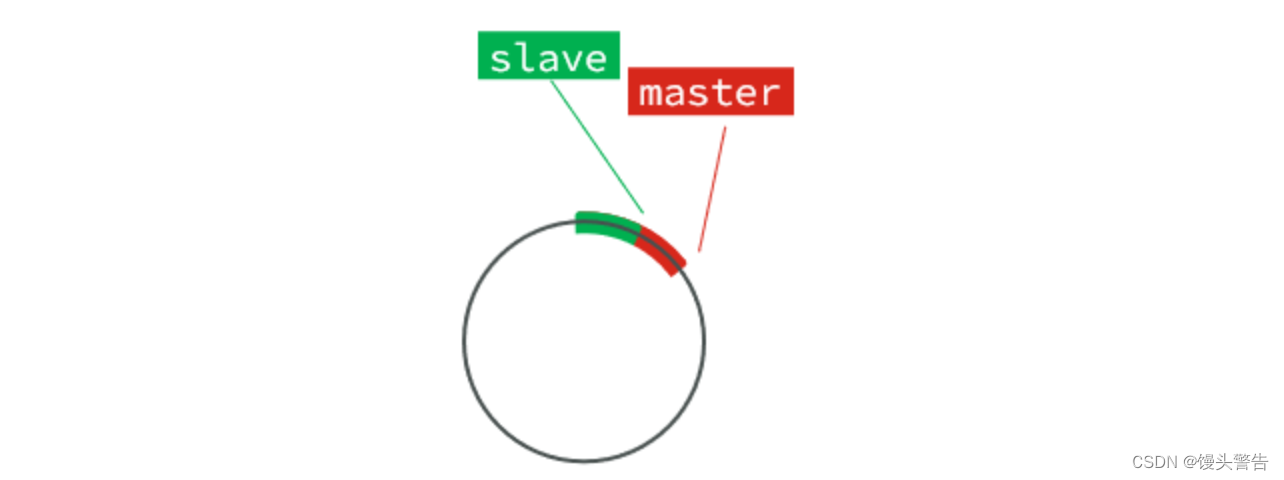
要同步的内容就是从 slave 的 offset 到 master 的 offset 之间的这部分数据
只要 slave 和 master 的存储差距不超过这个环的上限,那么永远可以从这个环里面找到所需要的数据,就可以进行增量同步
那么什么情况下会出现无法进行增量同步呢?
假设 slave 出现了宕机,它宕机之后,我们的 master 还在持续的做数据的记录,此时因为 slave 宕机了,就无法进行数据同步,因此欠的债就越来越多,所需要同步的数据也就越来越多,逐渐的挤满了整个数组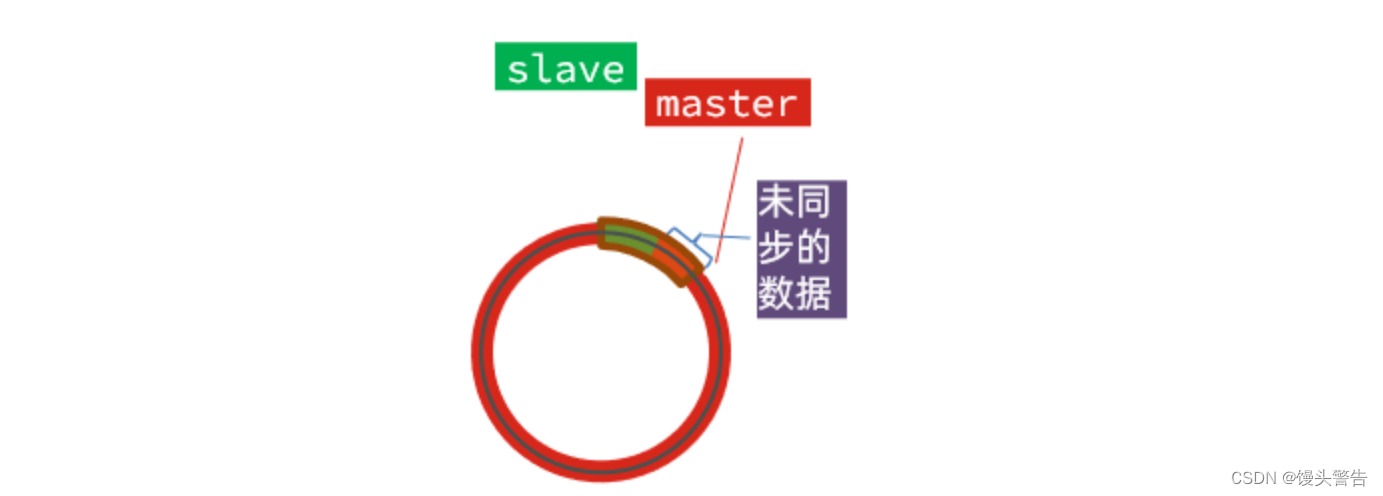
当所需要同步的数据达到一定数量的时候,master 新记录的数据就会将 slave 的 offset 覆盖掉,那么此时我们的 slave 恢复运行之后就无法进行增量同步,也就只能进行全量同步了
也就是说: repl_baklog 大小有限,写满后会覆盖最早的数据,如果 slave 断开时间过久,导致尚未备份的数据被覆盖,则无法基于 log 做增量同步,只能再次全量同步
3、主从同步的优化
我们可以从下面几个方面来对 Redis 主从就集群进行优化:
提高全量同步的性能:
1、在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
2、Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
减少全量同步:
3、适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
4、限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力