5.MySQL基本查询
个人主页:Lei宝啊
愿所有美好如期而遇
目录
表的增删改查
Create
单行数据 + 全列插入
多行数据 + 指定列插入
插入否则更新
替换
Retrieve
SELECT 列
全列查询
指定列查询
查询字段为表达式
为查询结果指定别名
结果去重
WHERE 条件
结果排序
筛选分页结果
Update
删除数据
删除单行
删除整张表数据
截断表
Delete
插入查询结果
聚合函数
group by子句的使用
实战OJ
表的增删改查
Create(创建), Retrieve(读取),Update(更新),Delete(删除)
Create
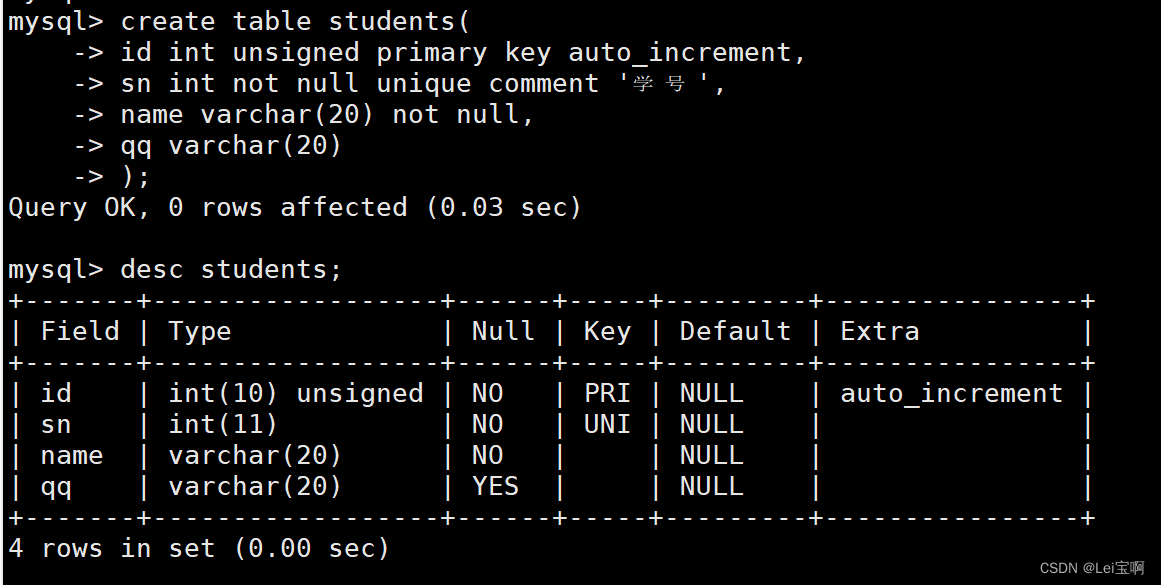
表的创建可以参考:Mysql表的操作
表后的各种约束参考:MySQL表的约束
单行数据 + 全列插入
语法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...
单行数据+指定列插入

展示插入结果
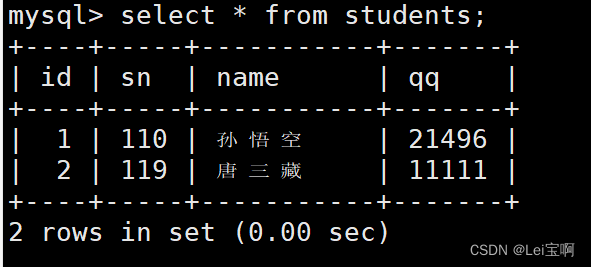
单行数据+全列插入

展示插入结果
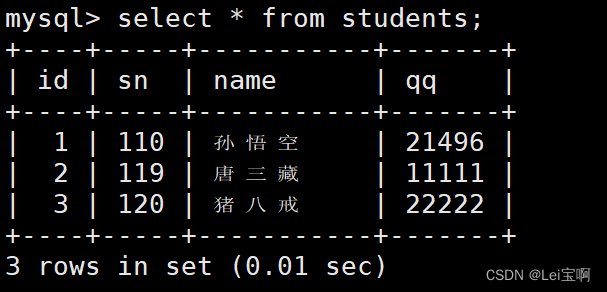
多行数据 + 指定列插入

展示插入结果

这里先前删除过两个数据,所以auto_crement到了5,从6开始插入了两个数据。
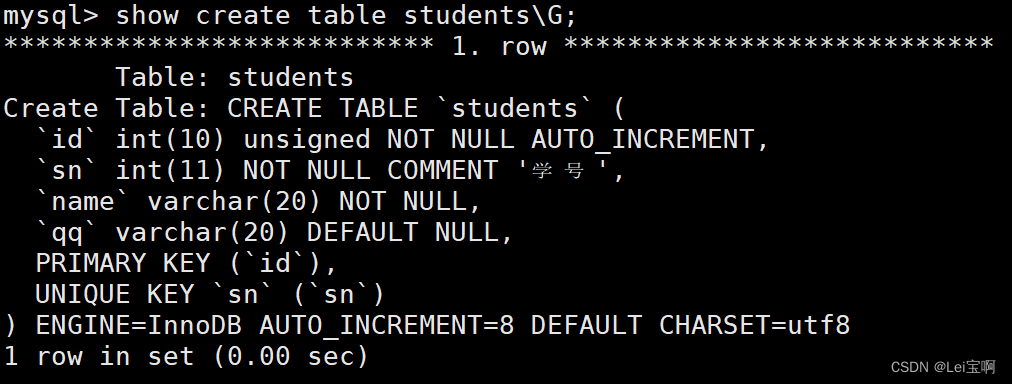
现在就到了8,下一个插入数据id为8(如果不指定).
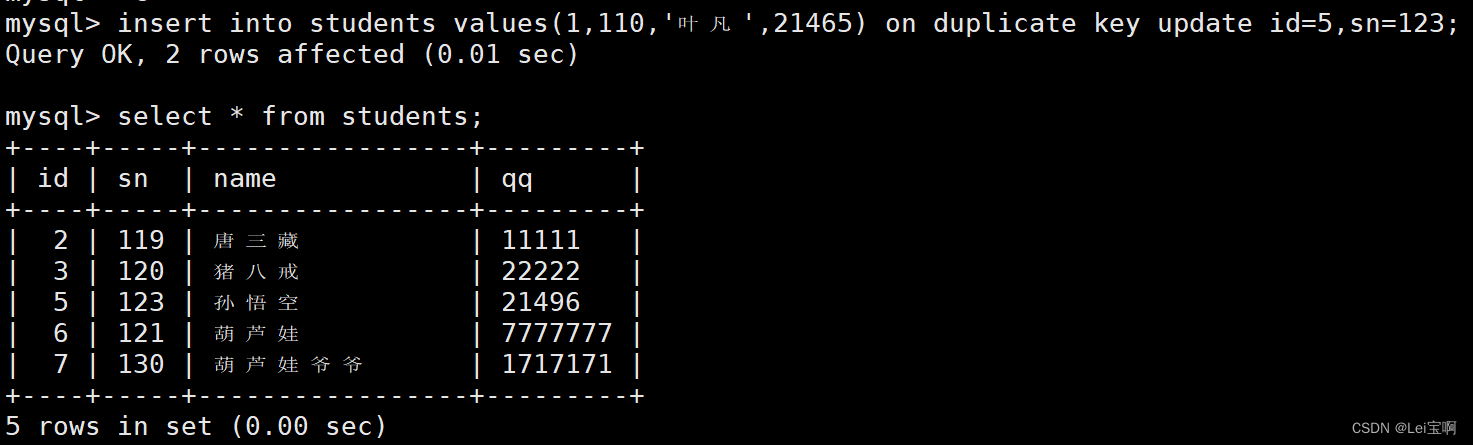
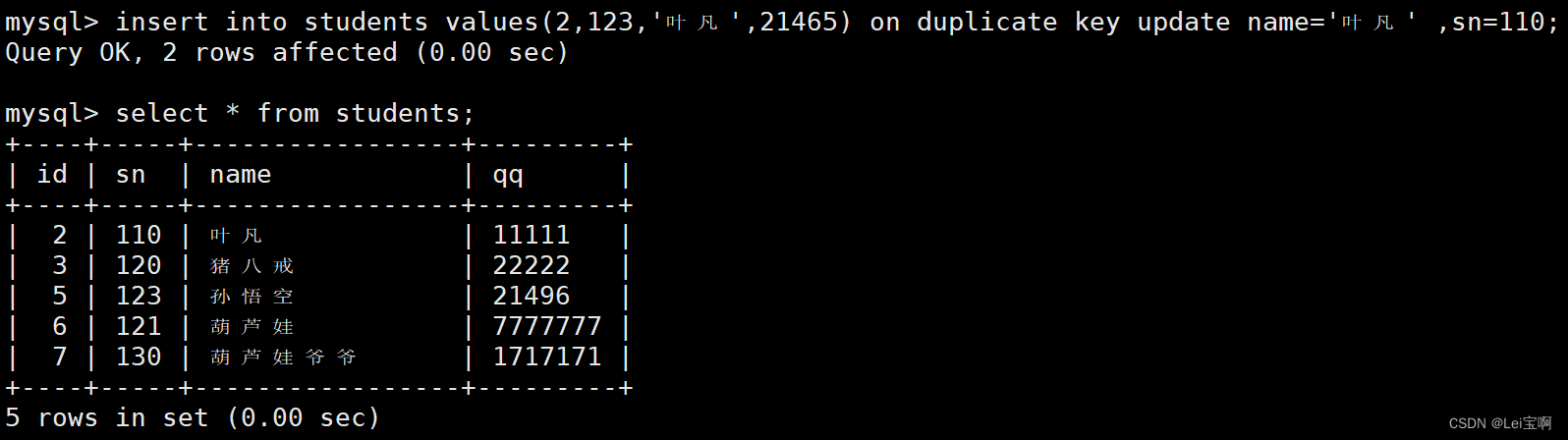
插入否则更新
由于主键或者唯一键对应的值已经存在而导致插入失败。
主键冲突:

唯一键冲突:

可以选择性的进行同步更新操作语法:
INSERT ... ON DUPLICATE KEY UPDATE
-- ON DUPLICATE KEY 当发生重复key的时候
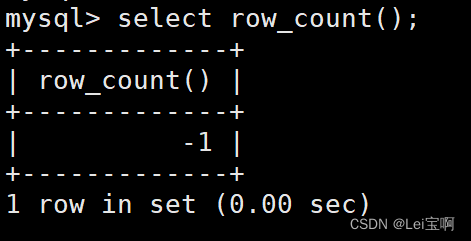
select row_count()可以查看被影响的行数,在进行插入操作后使用。
替换
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入

展示替换结果

-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入
Retrieve
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
创建一个新的测试表。
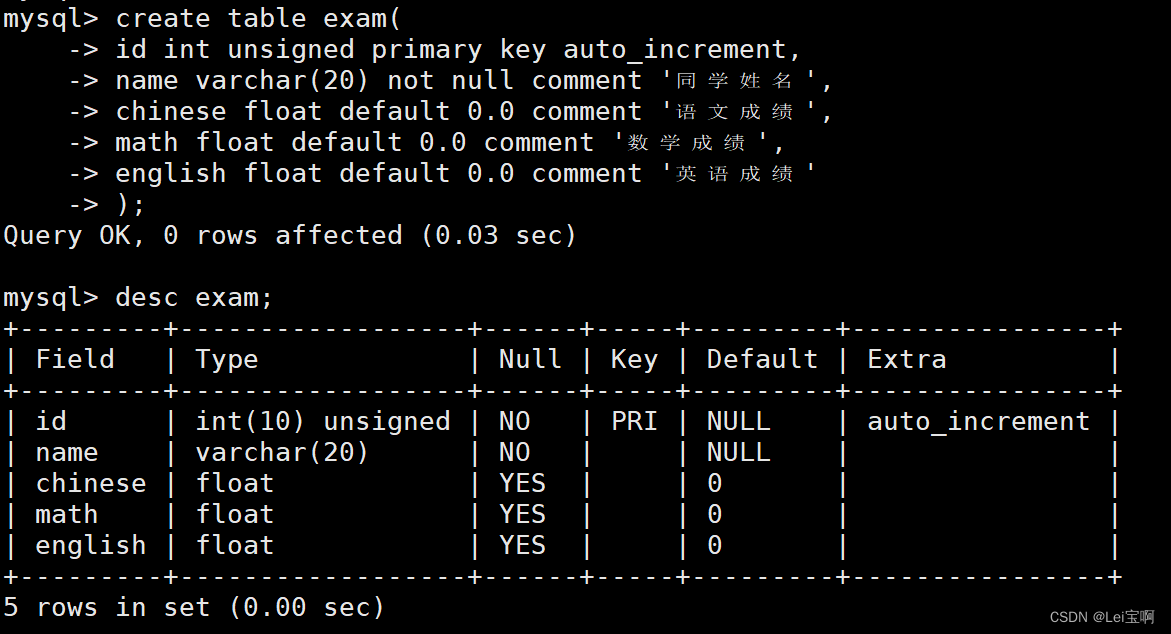
插入一些测试数据。
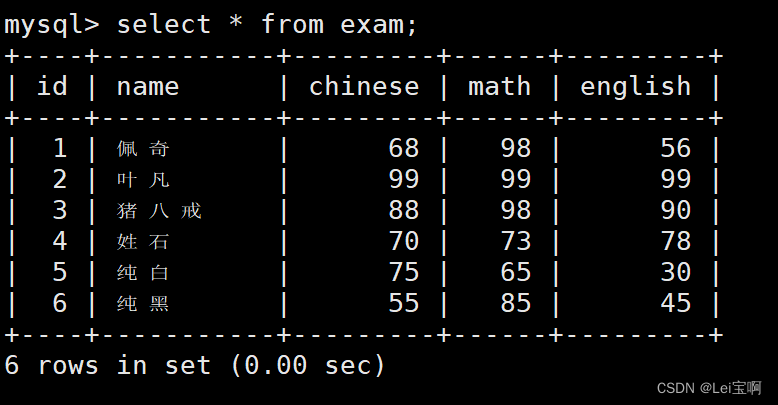
SELECT 列
全列查询
-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。
select * from exam;
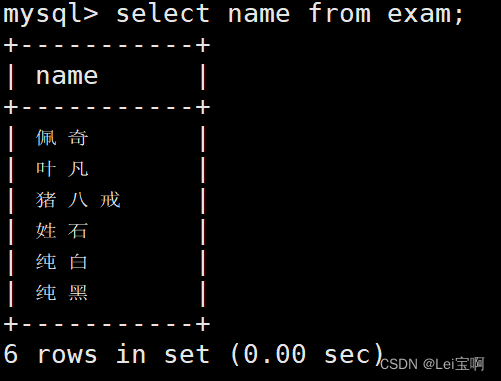
指定列查询
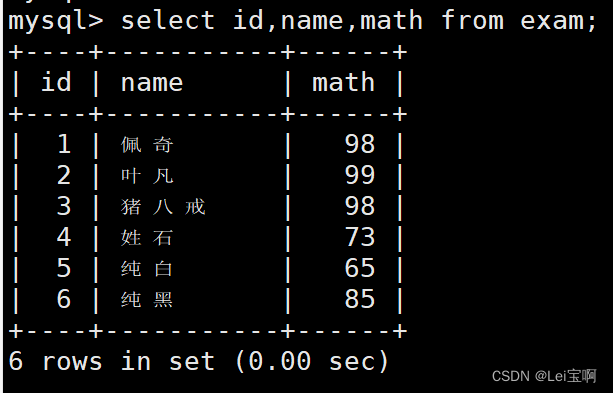
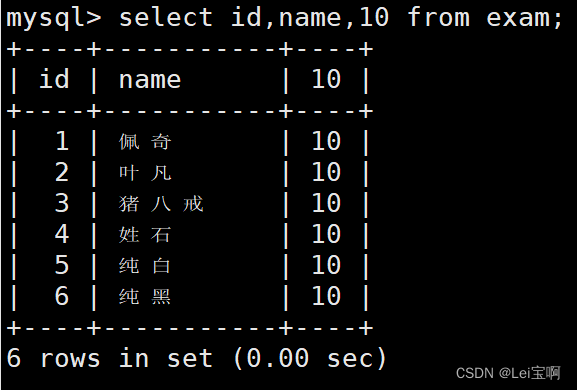
查询字段为表达式
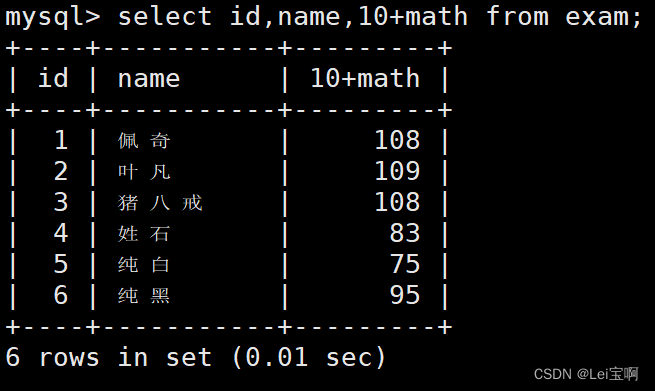
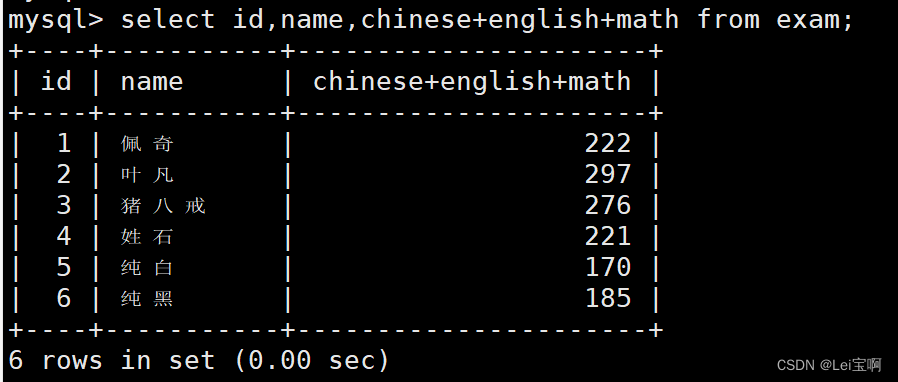
为查询结果指定别名
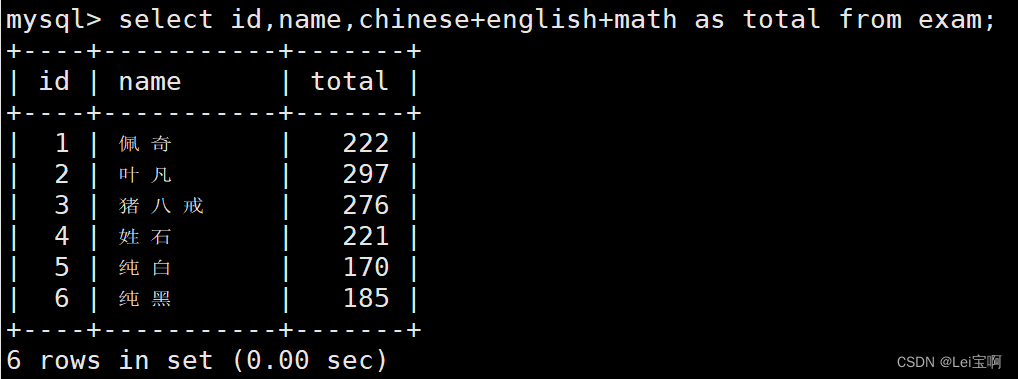
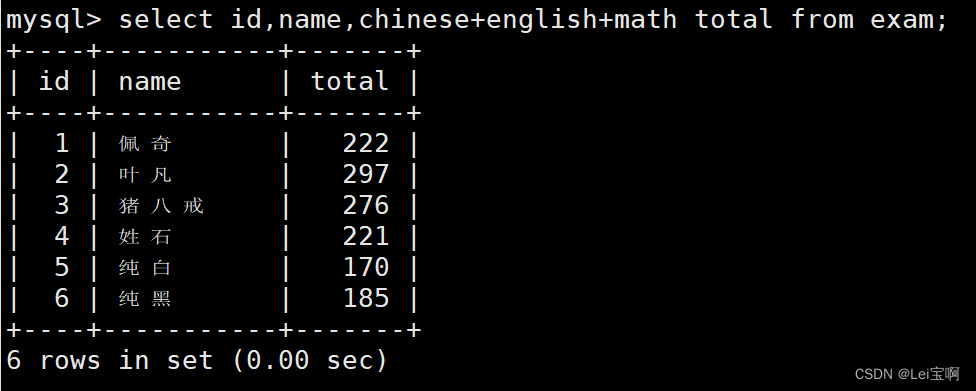
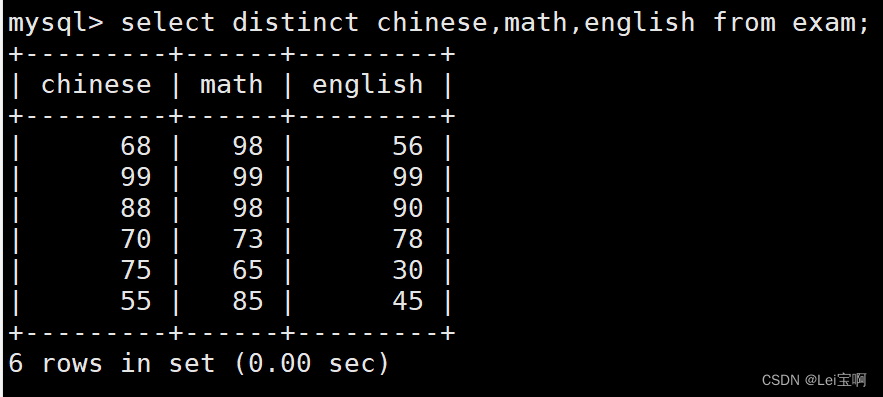
结果去重
98分有重复
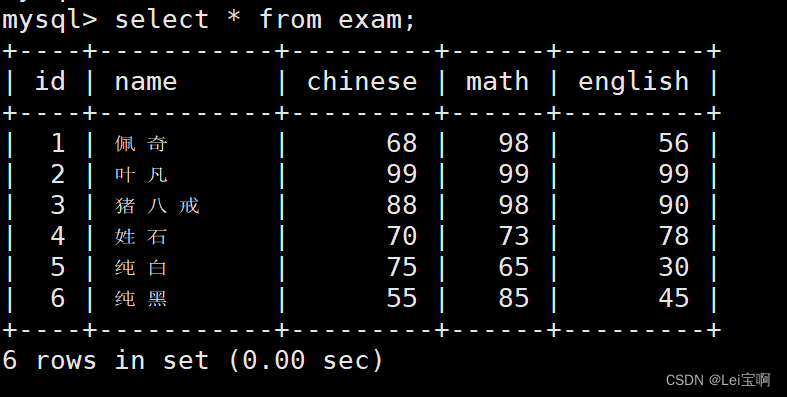
去重结果

没有三个成绩同时重复的
WHERE 条件
比较运算符:
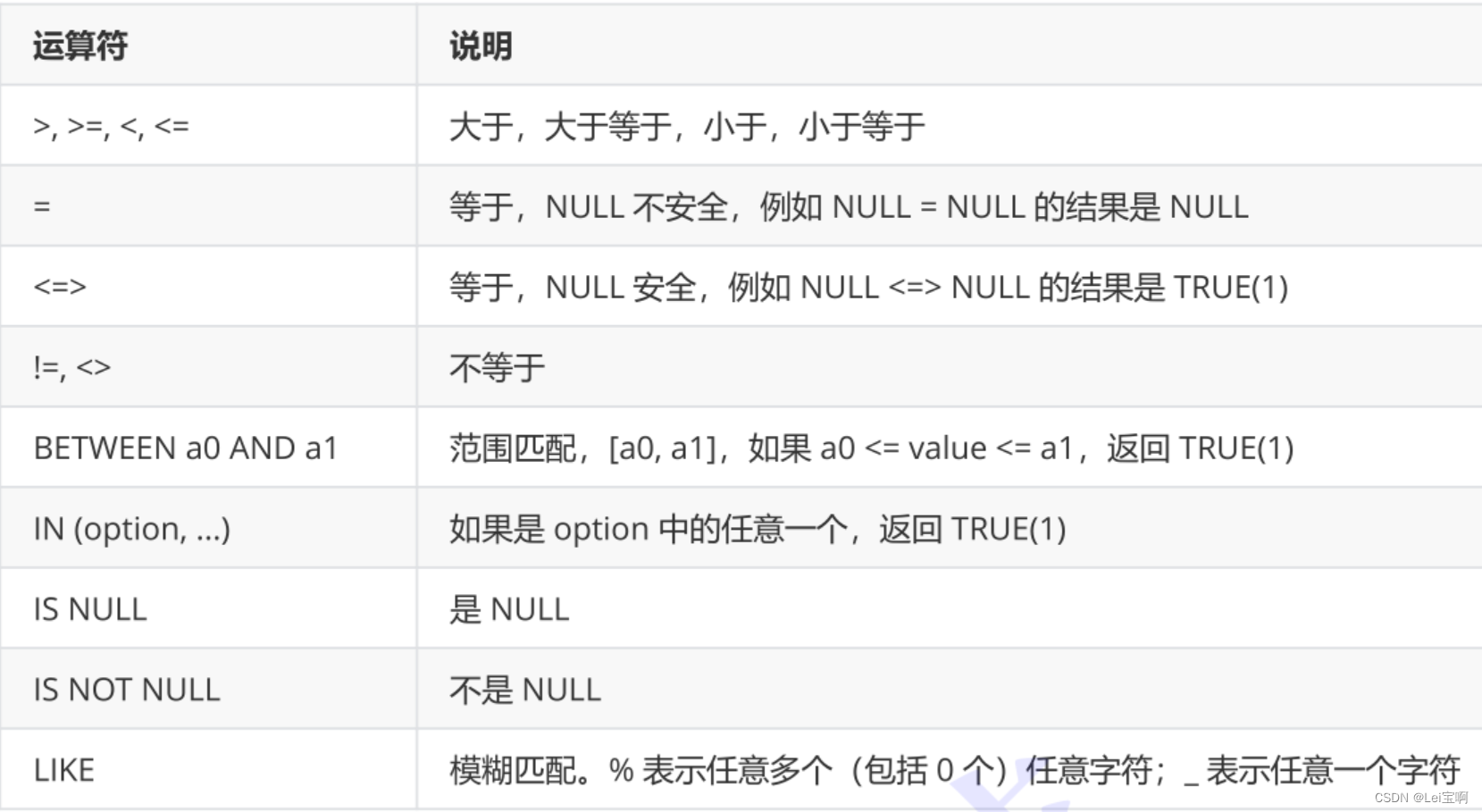
逻辑运算符:

下面是上面的一些案例。
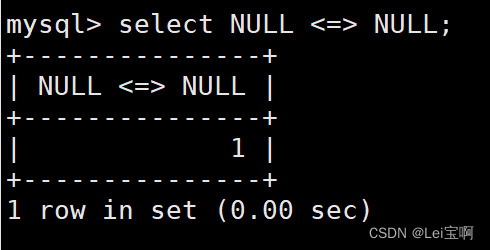
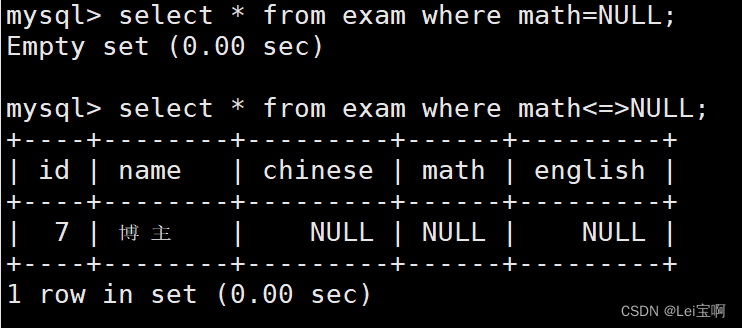
测试NULL的比较:
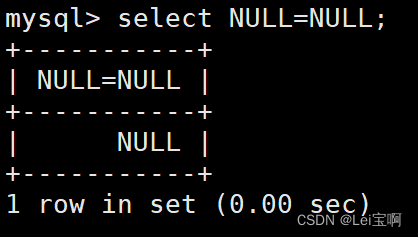
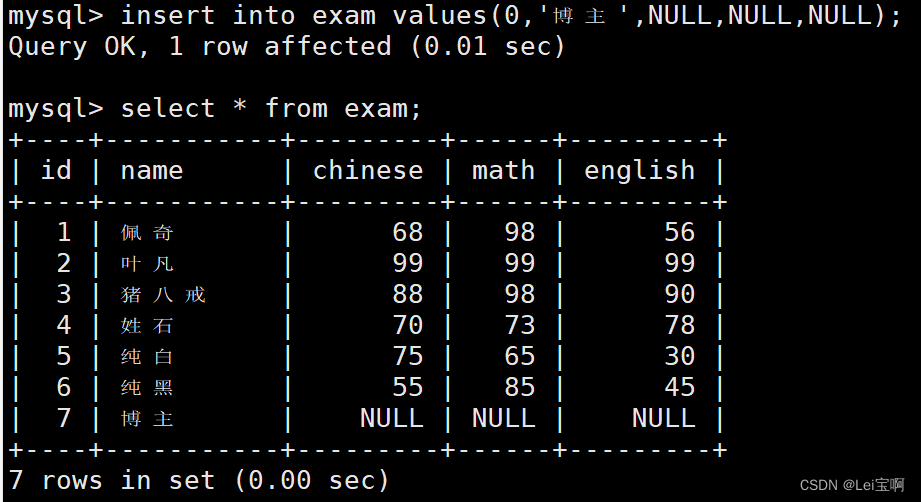
又是一个好的示例:
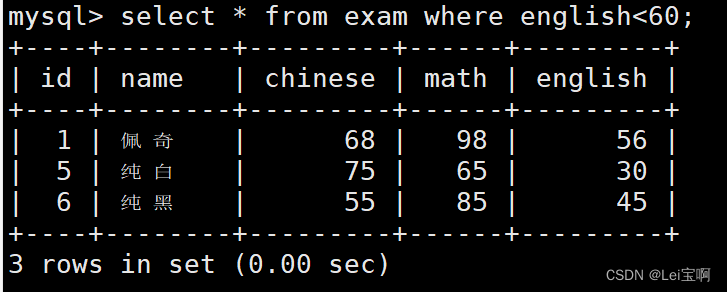
英语不及格的同学及英语成绩 ( < 60 )
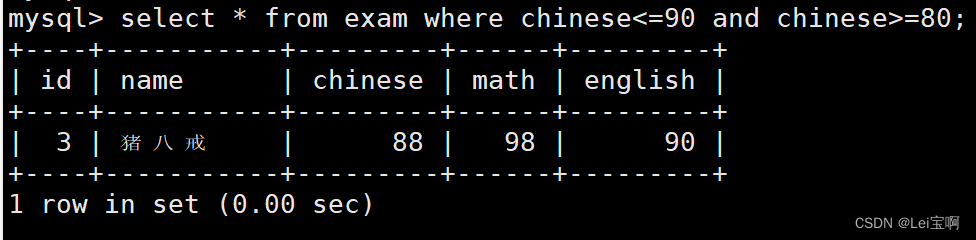
语文成绩在 [80, 90] 分的同学及语文成绩

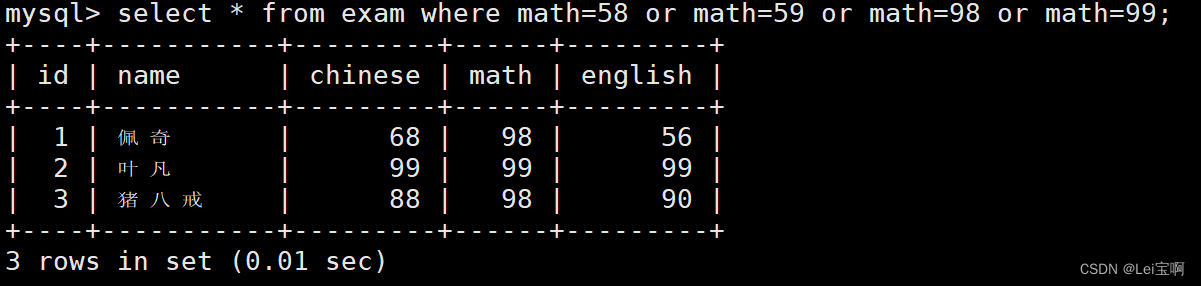
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
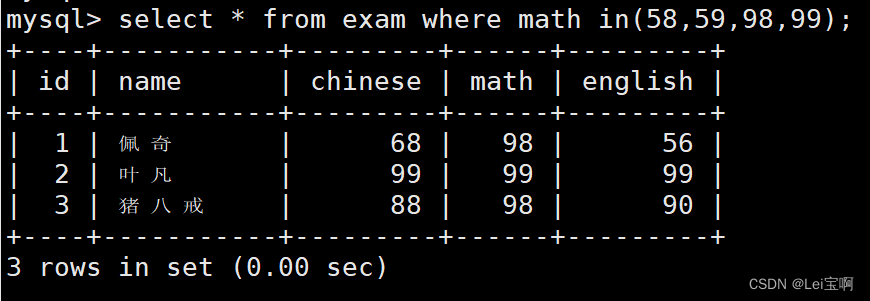
不够优雅,换种方式
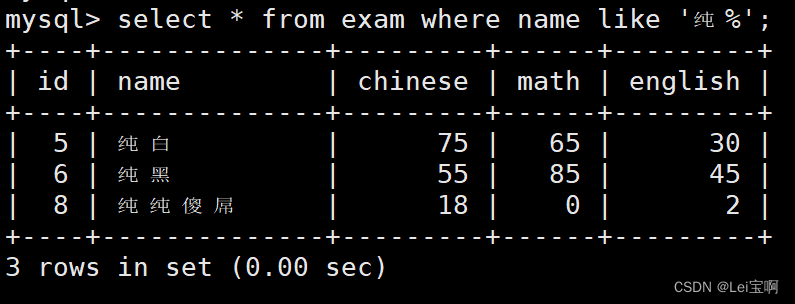
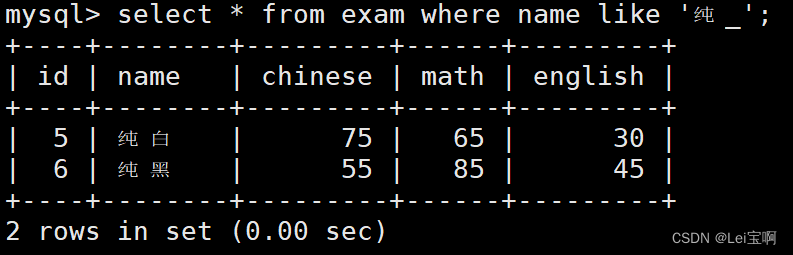
姓纯的同学 及 纯某同学
-- % 匹配任意多个(包括 0 个)任意字符

-- _ 匹配严格的一个任意字符
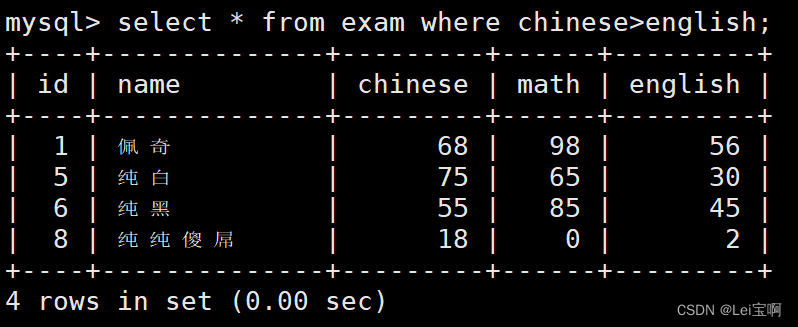
语文成绩好于英语成绩的同学
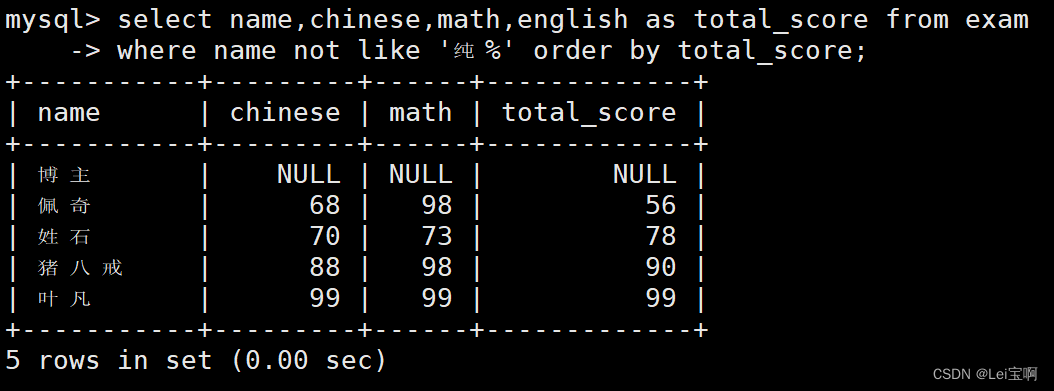
总分在 200 分以下的同学

 这里有个先后顺序,先筛选总分小于200,才起别名输出,而不是先起别名输出,后筛选。
这里有个先后顺序,先筛选总分小于200,才起别名输出,而不是先起别名输出,后筛选。
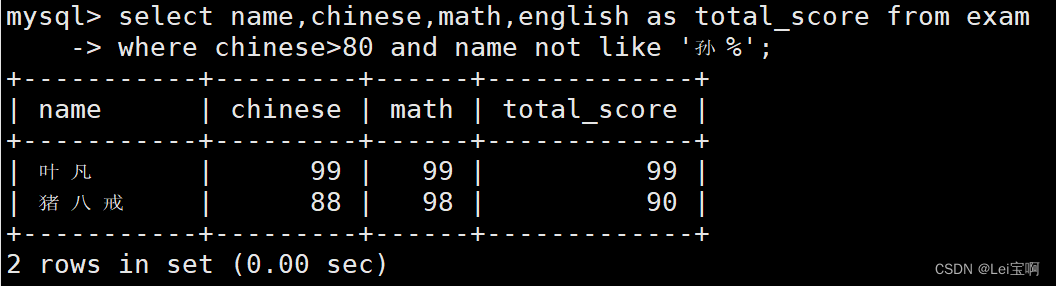
语文成绩 > 80 并且不姓孙的同学
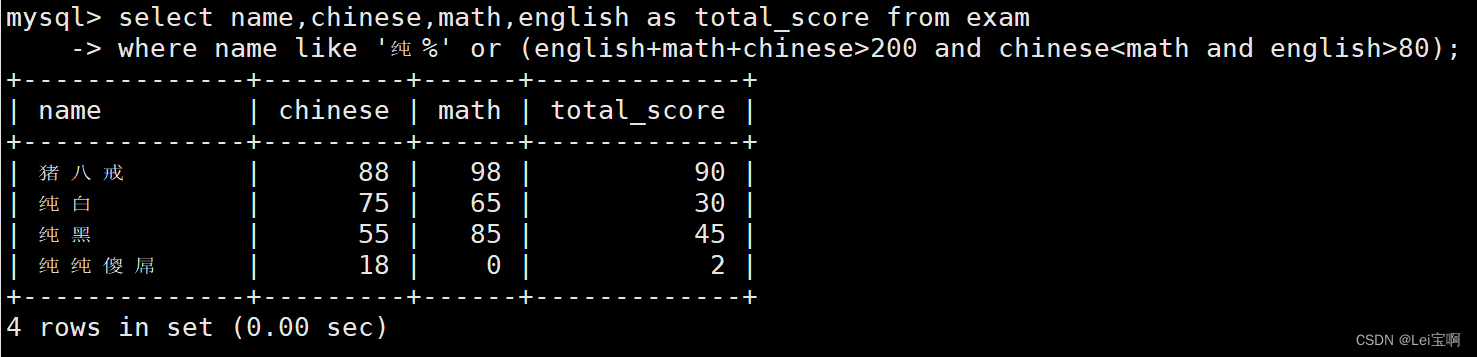
纯某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
结果排序
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
同学及数学成绩,按数学成绩升序显示
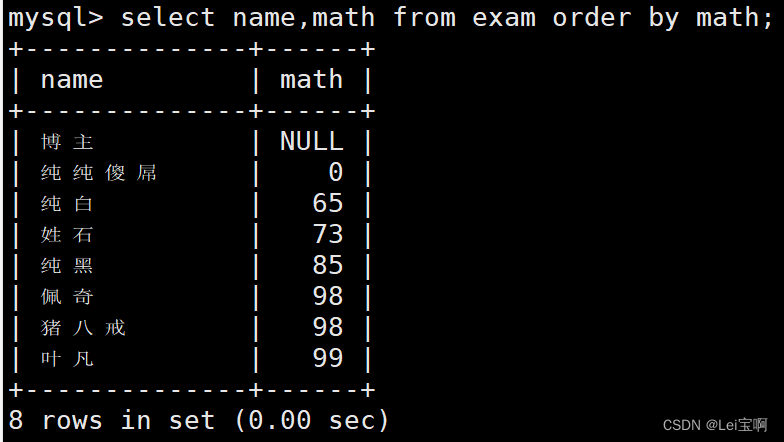
降序
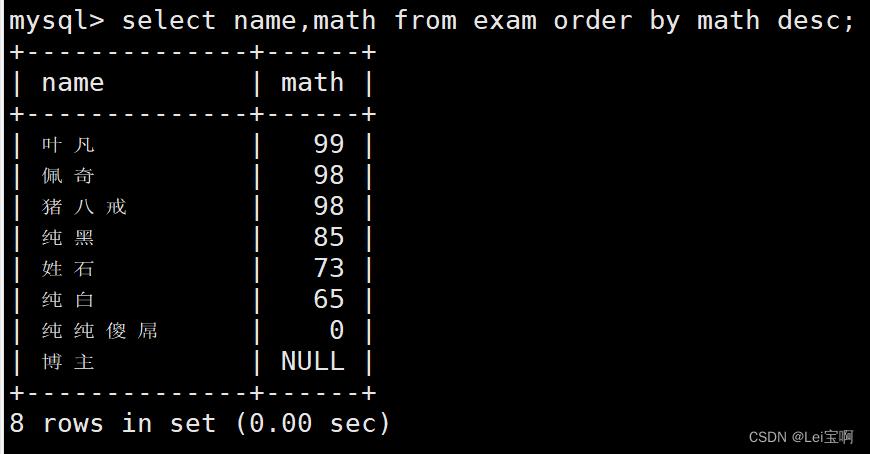
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
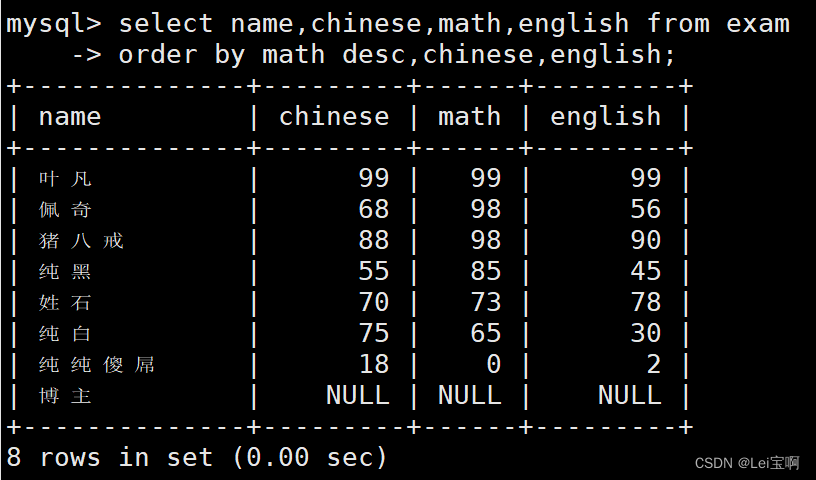
查询同学及总分,由高到低
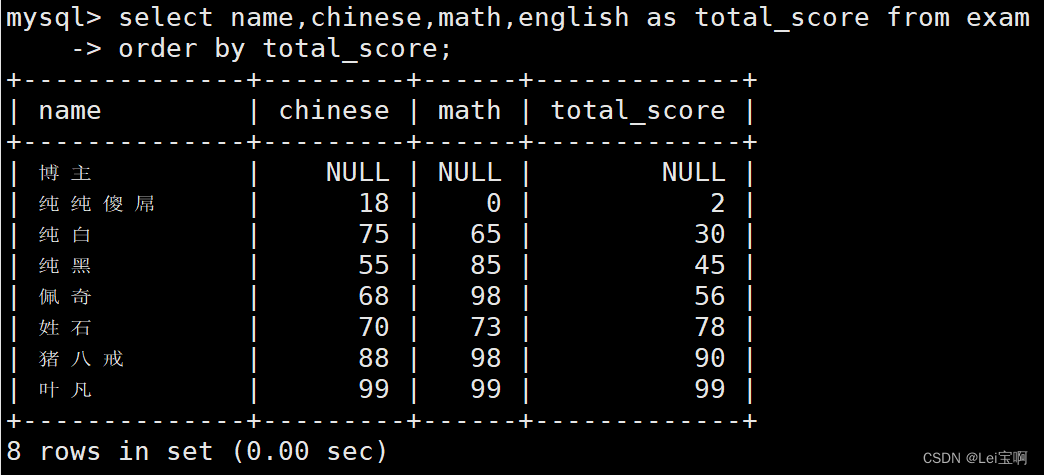
这里举个例子
这里会有人问,order by后面为什么可以用别名,where后面不可以,这里先后顺序为
- from
- where
- select
- order by
取别名在第三步,第四步当然可以使用别名。
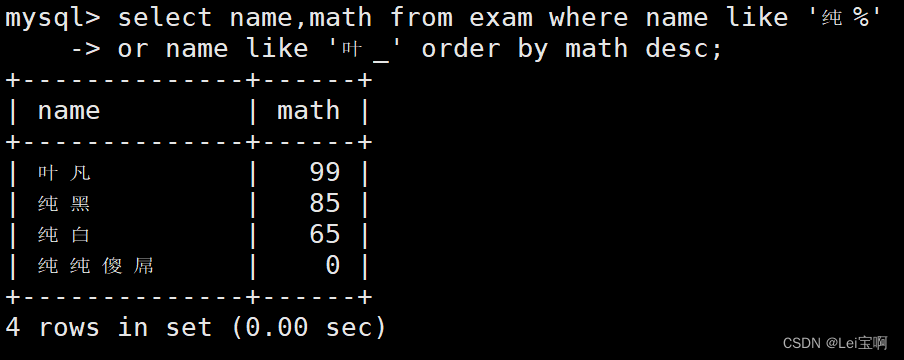
查询姓纯的同学或者姓叶的同学数学成绩,结果按数学成绩由高到低显示
筛选分页结果
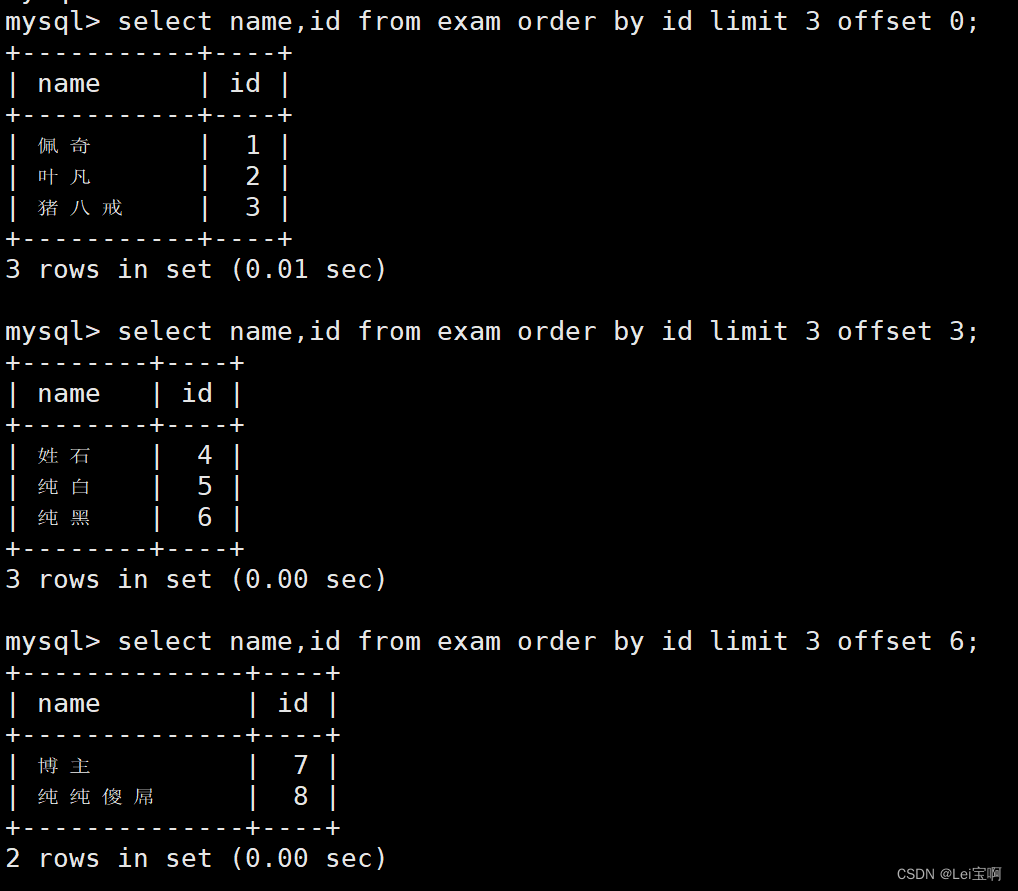
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
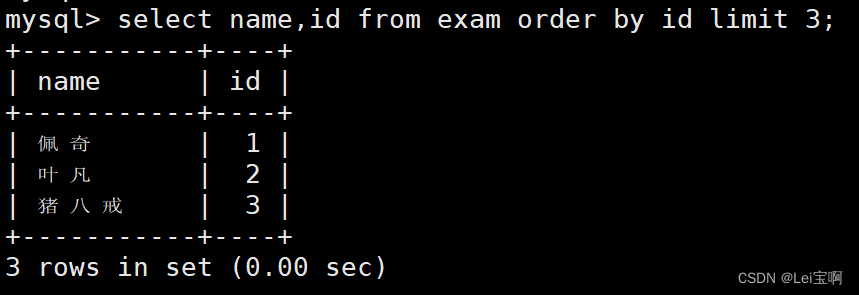
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
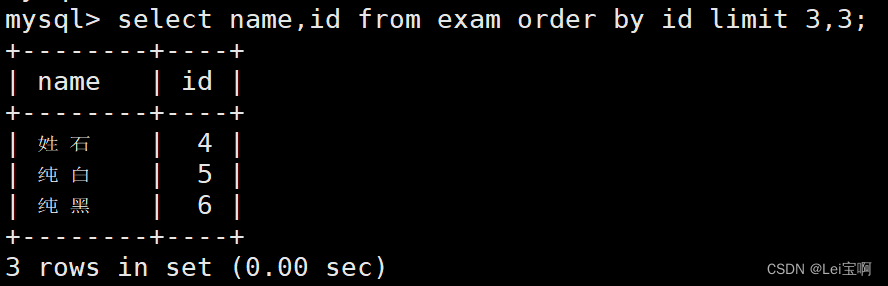
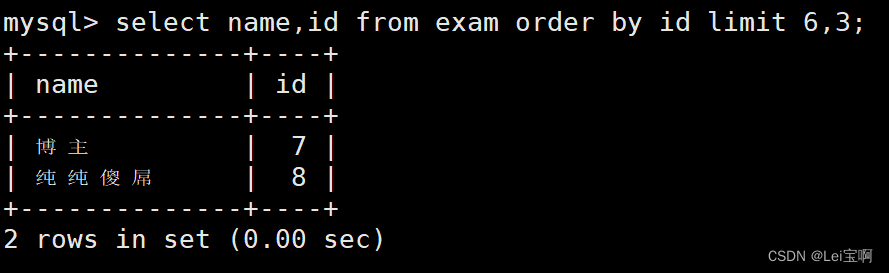
更明确的写法。
Update
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
对查询到的结果进行列值更新
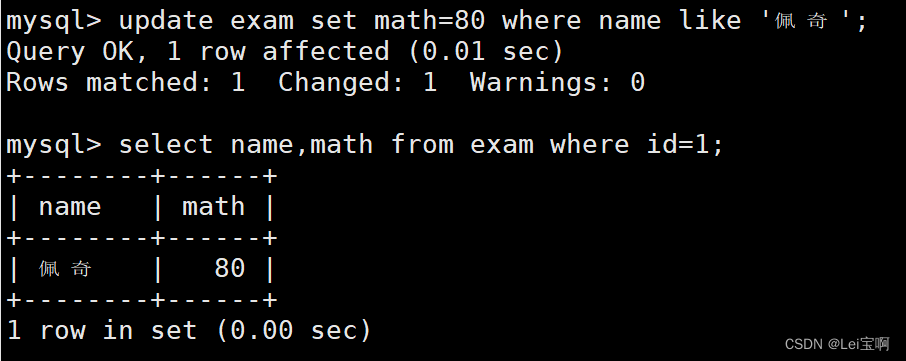
案例:
将佩奇同学的数学成绩变更为 80 分
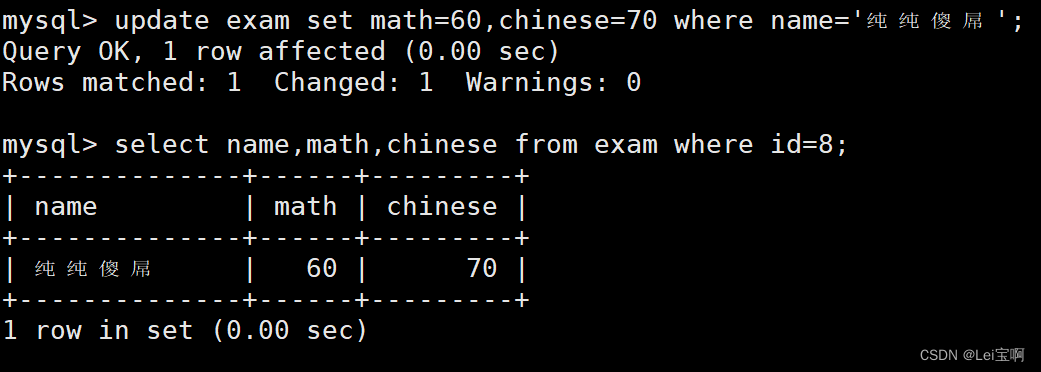
将纯纯傻屌同学的数学成绩变更为 60 分,语文成绩变更为 70 分
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
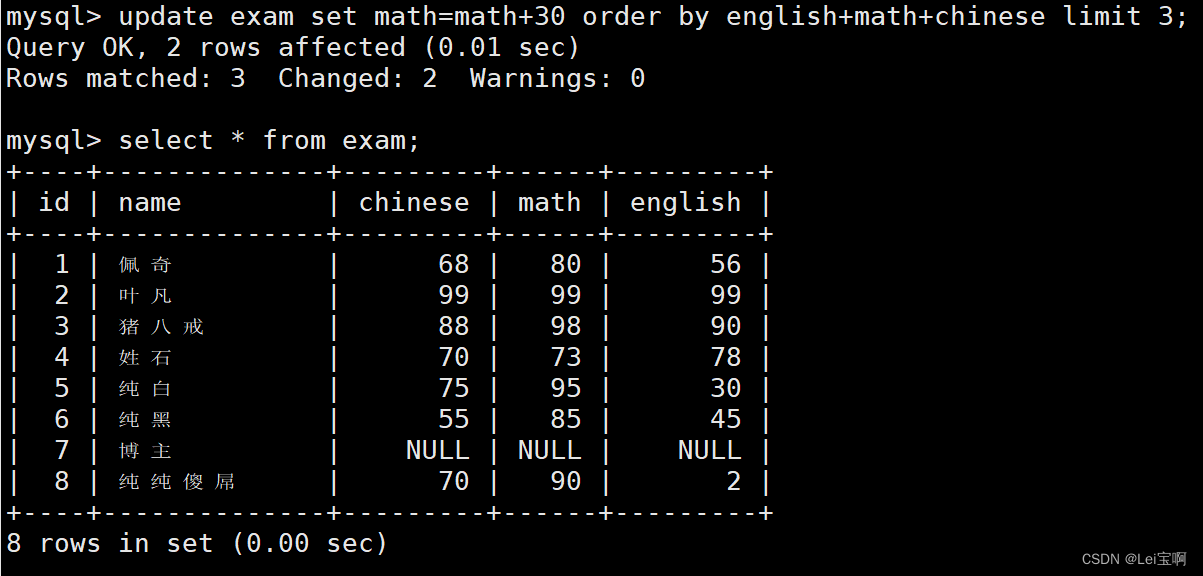
NULL不参与计算

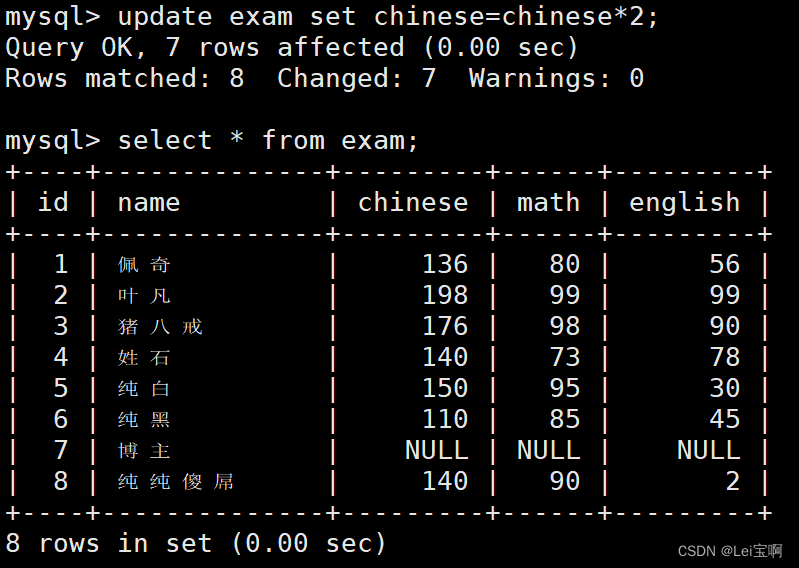
将所有同学的语文成绩更新为原来的 2 倍
删除数据
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
删除单行
删除纯纯傻屌同学的考试成绩
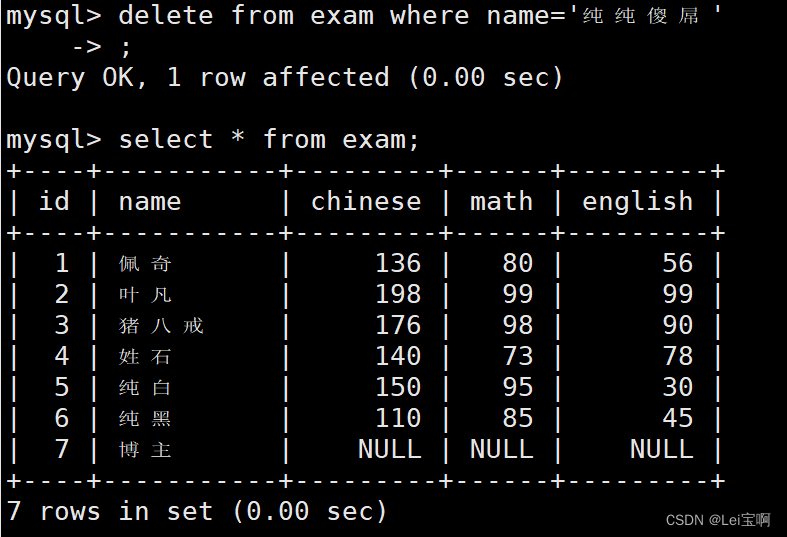
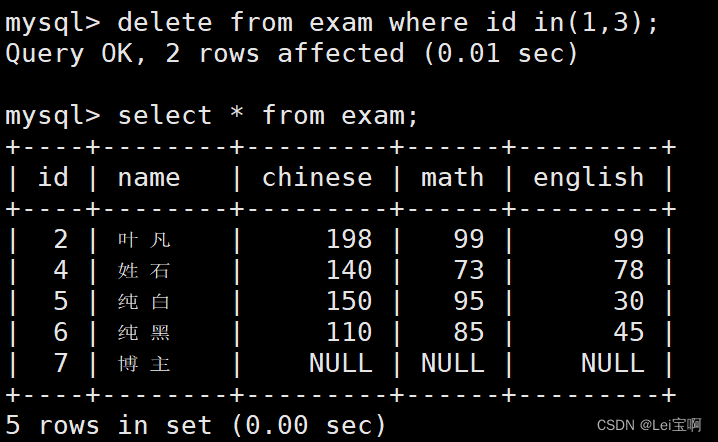
也可以删多行,没加标题,汗-_-||
删除整张表数据
注意:删除整表操作要慎用!
准备一个测试表
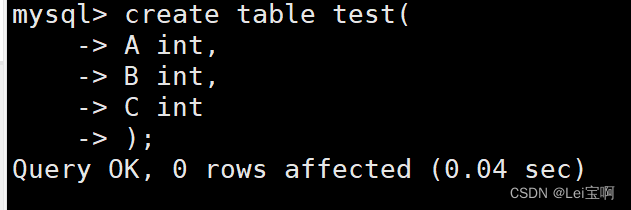
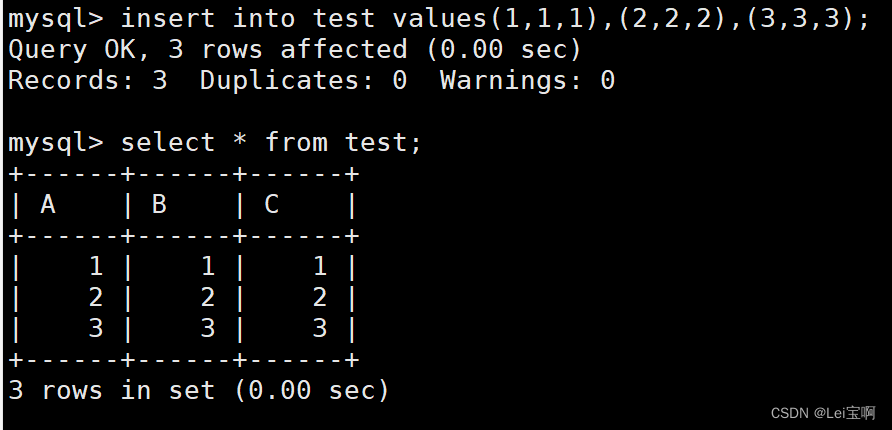

这里我们需要注意:如果这个表中有主键,并且自增长,那么使用delete清空这个表中的所有数据时,自增长的值没有被清空,延续上一个最大值。
截断表
语法:
TRUNCATE [TABLE] table_name
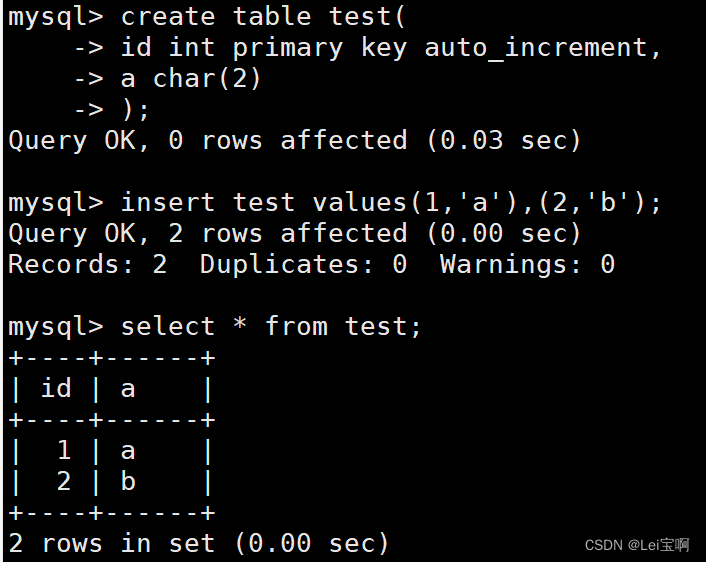
试着截断它。
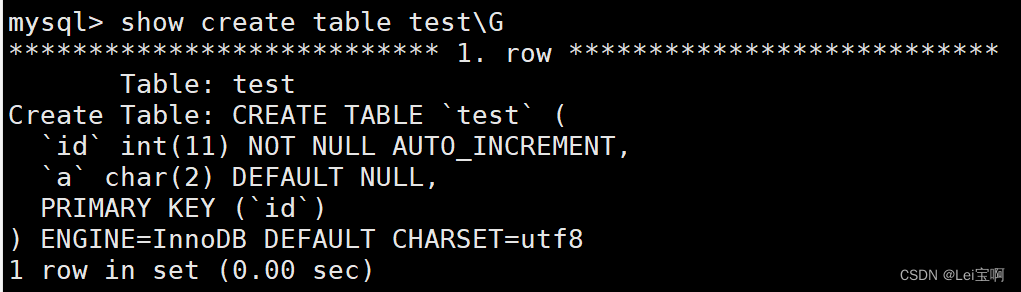
再插入数据时id就会从1开始了。
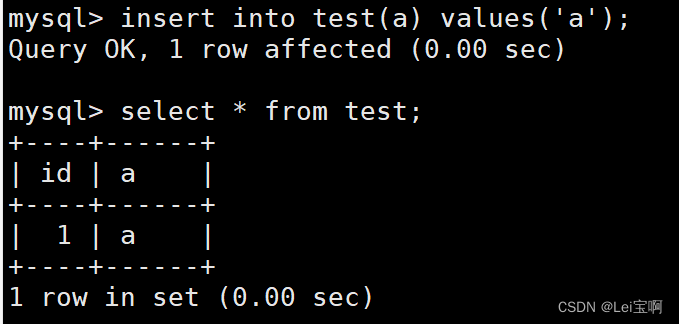
注意:这个操作慎用
只能对整表操作,不能像 DELETE 一样针对部分数据操作
Delete
删除的知识点在update了,忘记写在这个下面了,哈哈。
插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
案例:删除表中的的重复复记录,重复的数据只能有一份
老规矩,先建个新的测试表。
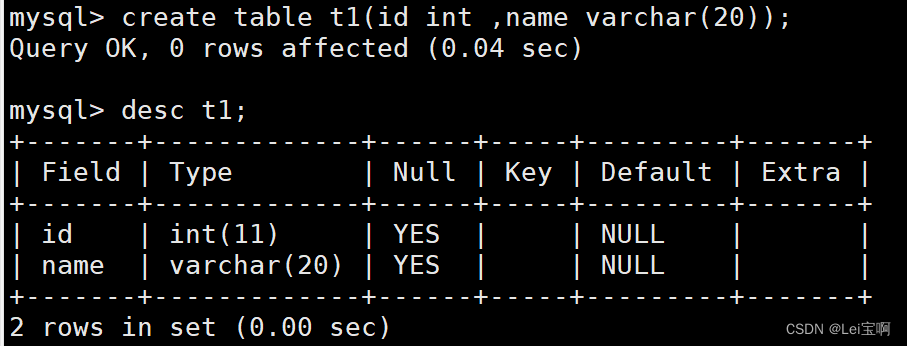
插入几个数据。
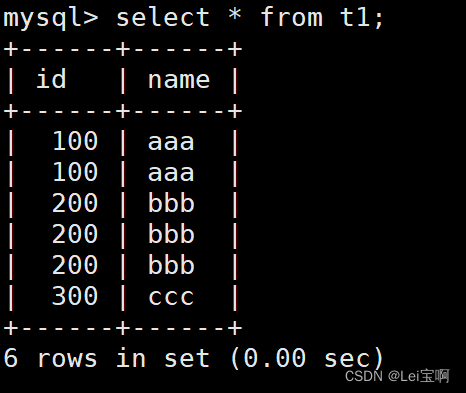
还记得我们如何去重的吗?
select distinct * from table_name;
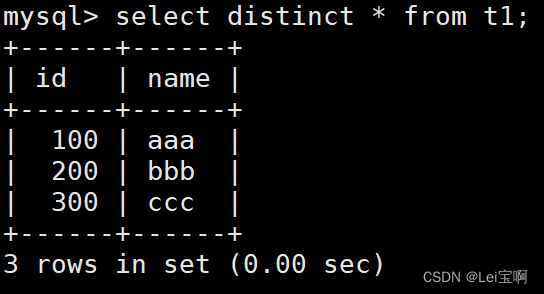
也就是一个拼接。
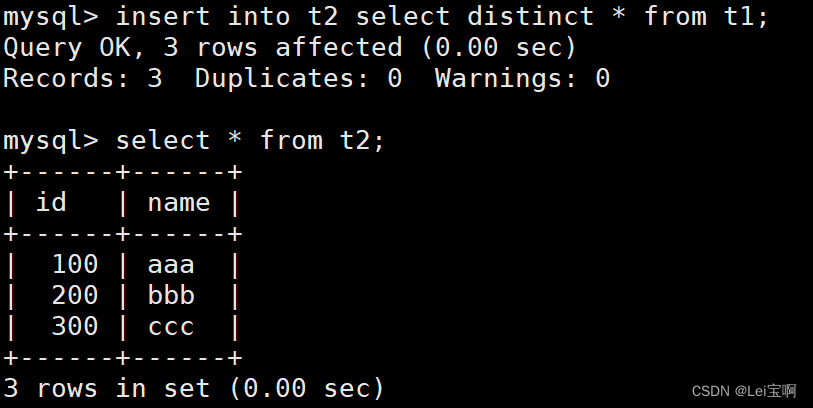
将旧的t1改名,t2改名为t1,不就相当于给t1表去重了吗。
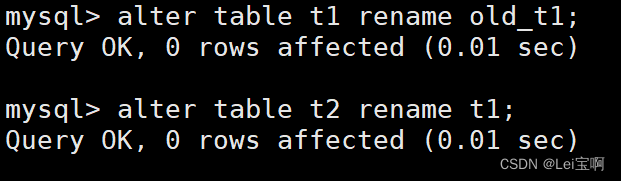
也可以这么改名。
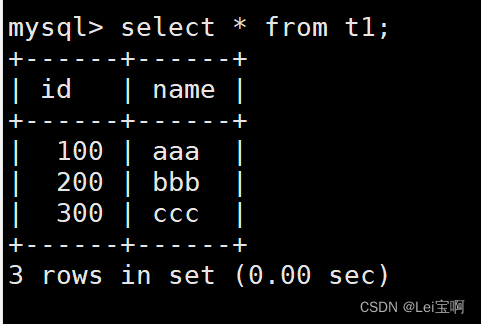
查看去重结果。
聚合函数
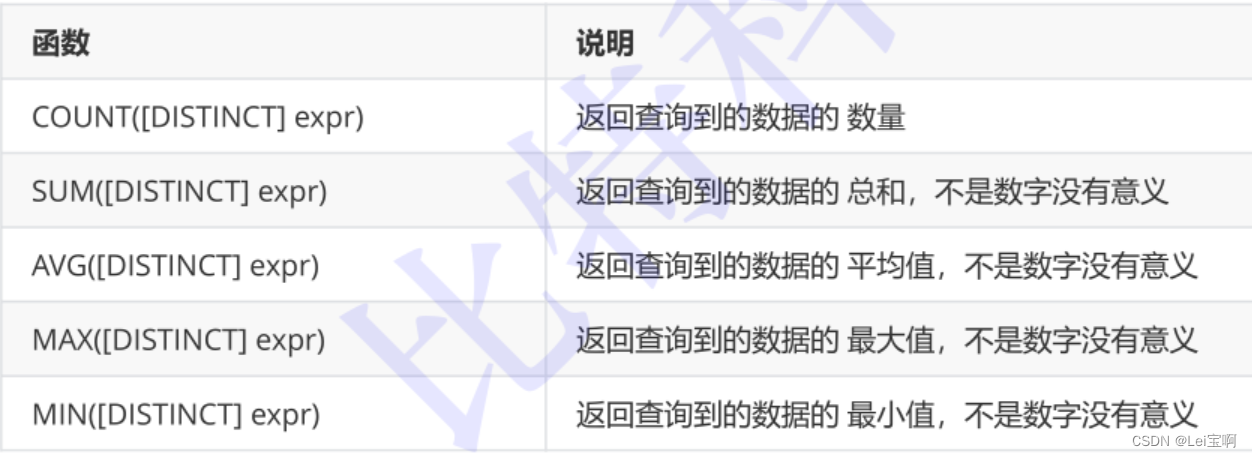
查看一下我们去重后表剩下有多少数据。
测试剩下的数据我们先来建一个新表。
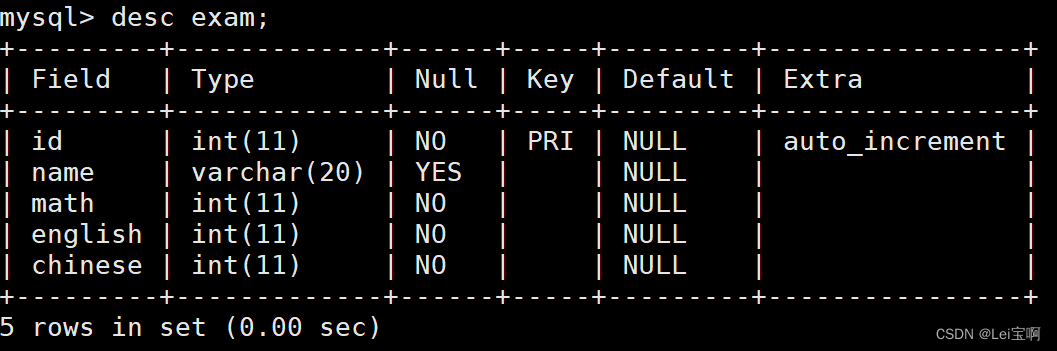
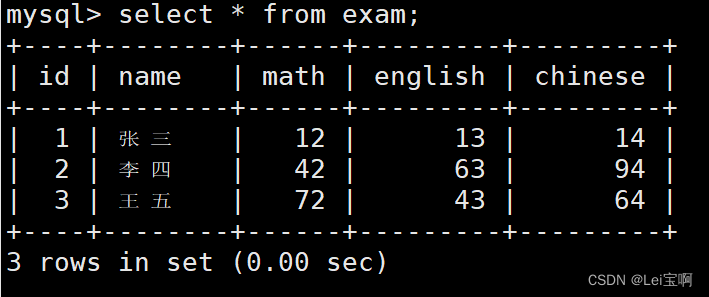
测试sum聚合函数
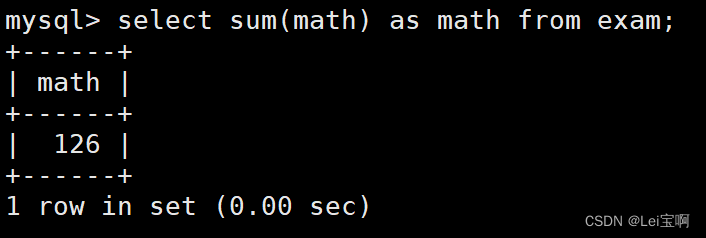
所有人的总分
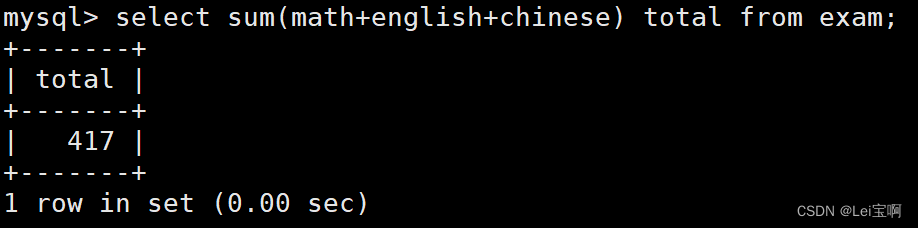
每个人的总分
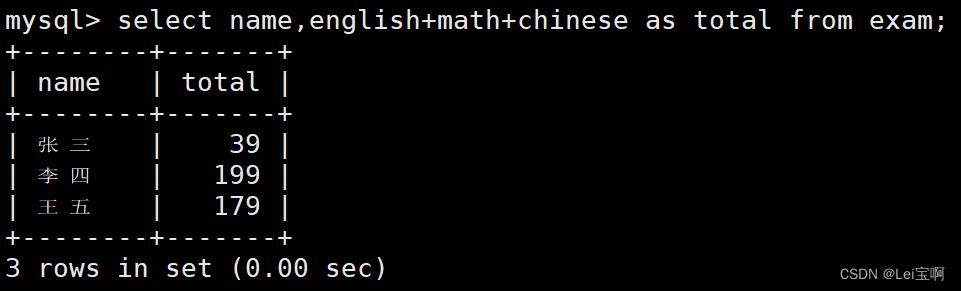
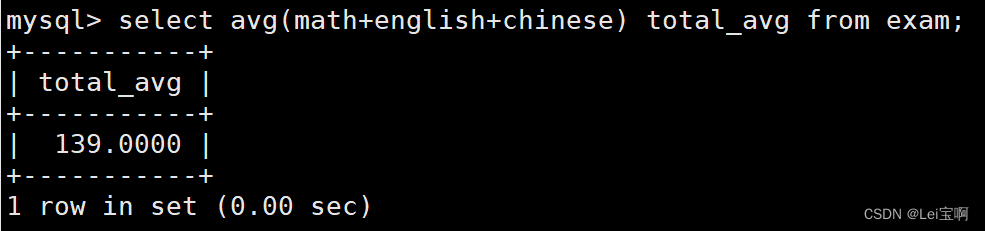
测试avg聚合函数
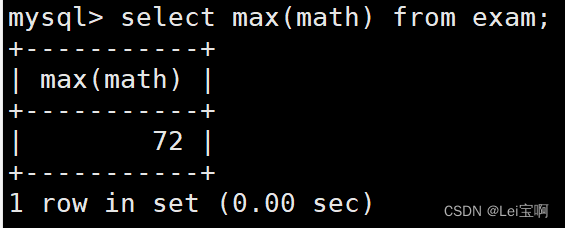
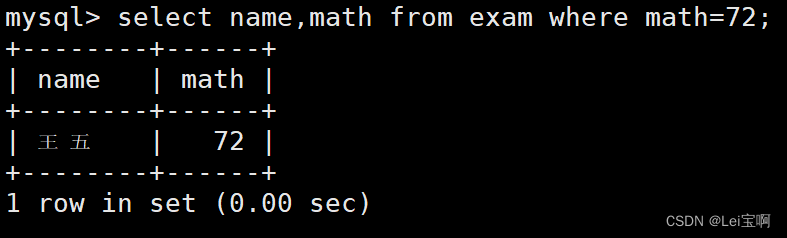
测试max和min函数
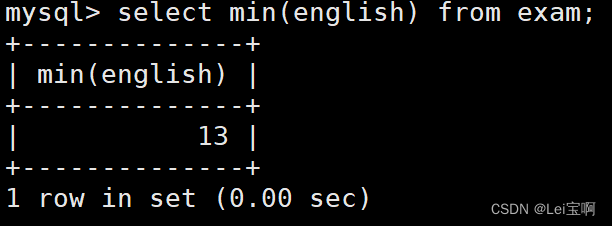
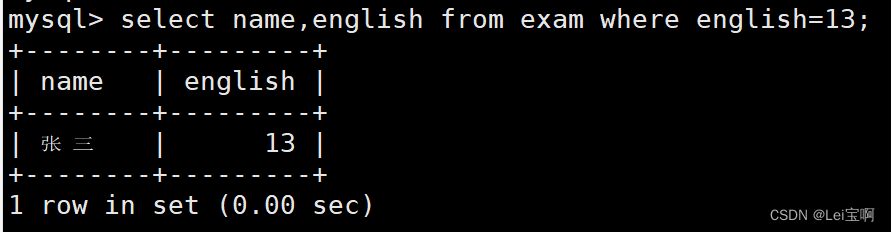
group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
EMP员工表
DEPT部门表
SALGRADE工资等级表
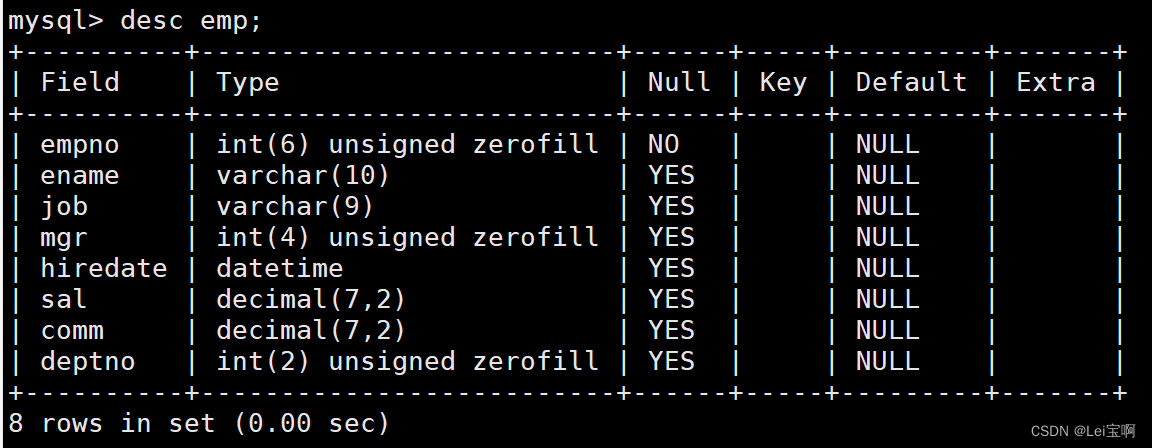
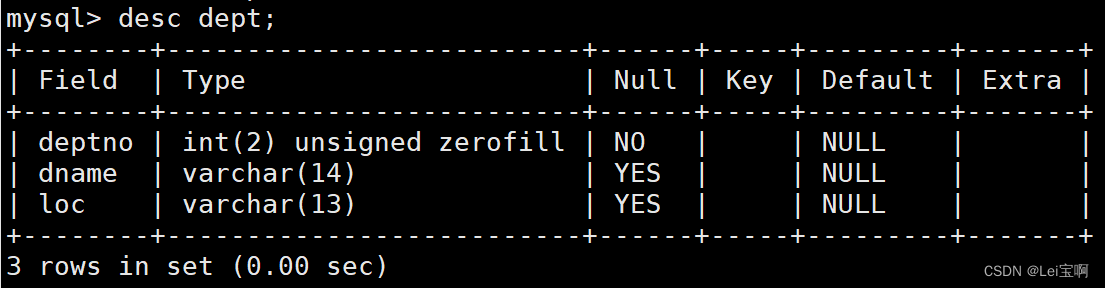
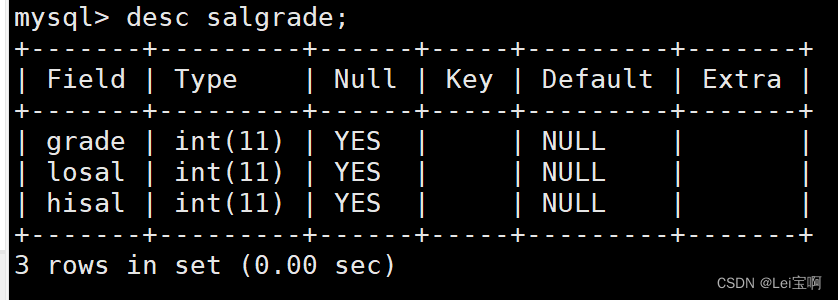
之后我们向里面插入了部分数据,我们可以开始展示group by的用法了
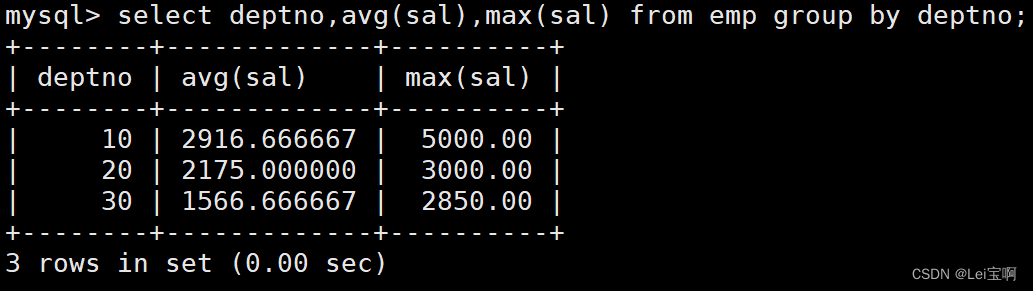
显示每个部门的平均工资和最高工资
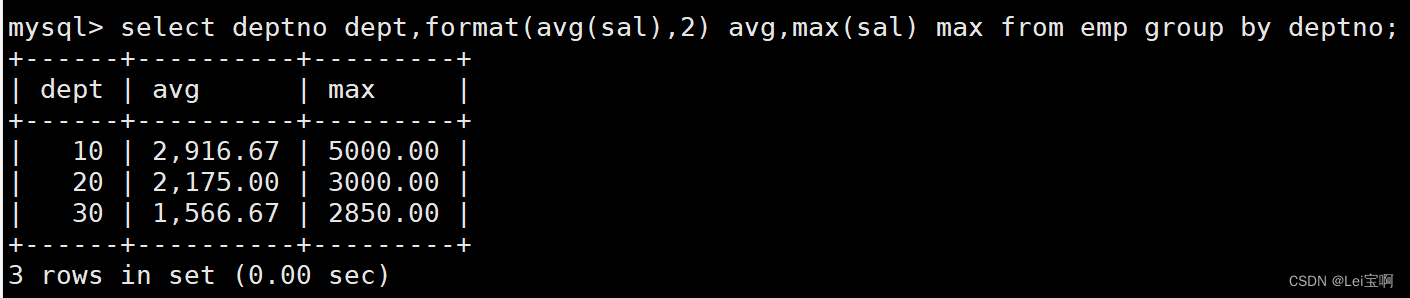
显示每个部门的每种岗位的平均工资和最低工资
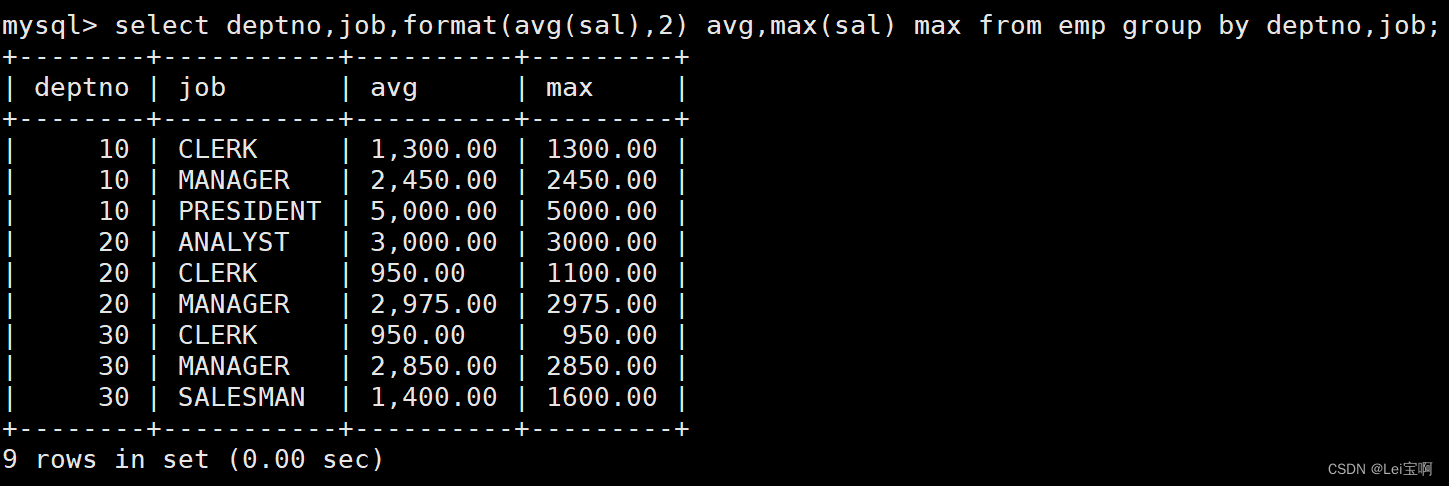
显示平均工资低于2000的部门和它的平均工资

- 先从emp中寻找数据
- 再分组
- 按列查询,计算函数
- having条件
having和group by配合使用,对group by结果进行过滤
--having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。
实战OJ
批量插入数据_牛客题霸_牛客网 (nowcoder.com)

找出所有员工当前薪水salary情况_牛客题霸_牛客网 (nowcoder.com)

查找最晚入职员工的所有信息_牛客题霸_牛客网 (nowcoder.com)



查找入职员工时间排名倒数第三的员工所有信息_牛客题霸_牛客网 (nowcoder.com)

查找薪水记录超过15条的员工号emp_no以及其对应的记录次_牛客题霸_牛客网 (nowcoder.com)

从titles表获取按照title进行分组_牛客题霸_牛客网 (nowcoder.com)

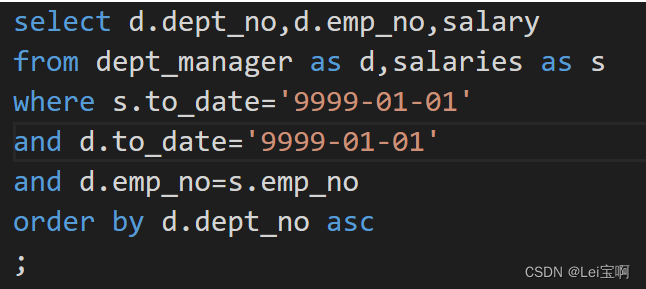
获取所有部门当前manager的当前薪水情况,给出dept__牛客题霸_牛客网 (nowcoder.com)
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
