论文阅读——InstructGPT
论文:Training_language_models_to_follow_instructions_with_human_feedback.pdf (openai.com)
github:GitHub - openai/following-instructions-human-feedback
将语言模型做得更大并不能从本质上使它们更好地遵循用户的意图。例如,大型语言模型可能生成不真实、有害或对用户毫无帮助的输出。换句话说,这些模型与其用户不一致(models are not aligned with their users)。这是因为许多大语言模型的目标是从互联网上预测网页上的下一个token——与“帮助和安全地遵循用户的指示”的目标不同。
这既包括明确的意图,如遵循指示,也包括隐含的意图,例如保持真实,不带偏见、有毒或其他有害因素。
语言模型应该是helpful,honest,harmless,有帮助、诚实、无害的。
一、方法:
收集一个人工手写的提交到openai的prompts和一些人工写的prompts的理想行为的数据集,并使用这些数据集有监督训练基线模型;然后收集人类对openai的API在一个更大prompts输出结果比较的数据集,使用这些数据集训练一个奖励模型来预测标注者会喜欢模型的哪一个输出。最后使用这个奖励模型作为奖励函数并微调基线模型,使用PPO算法来最大化奖励。如下图:
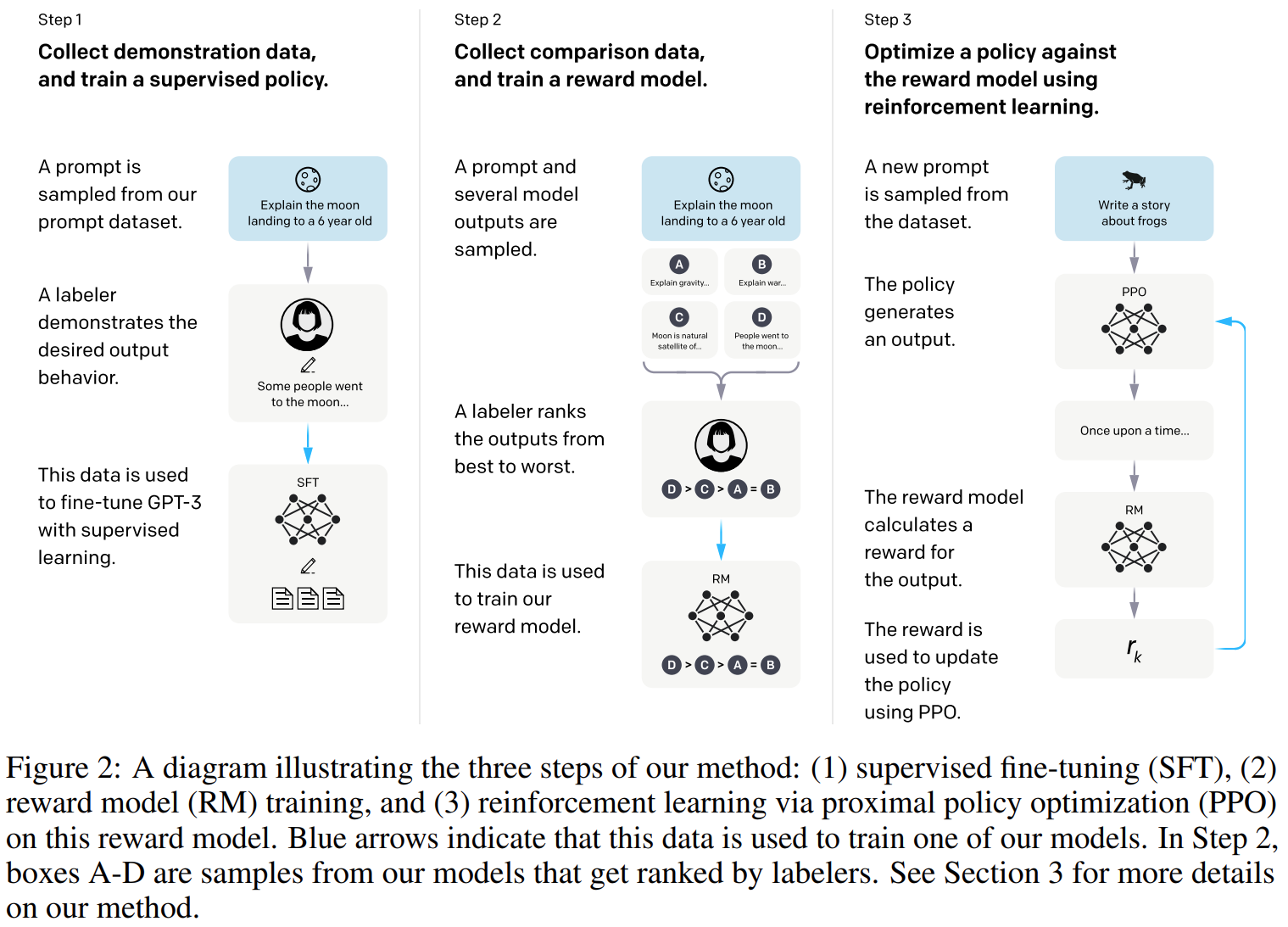
step1:收集示范数据,并用来做监督策略
有一写输入提示分布,标注人员为这些提示提供模型理想输出。然后在使用监督学习在预训练GPT3上微调。
step2:收集比较数据,并训练奖励模型
对于模型输出,标注人员对这些输出做比较,标出最喜欢的输出,然后训练奖励(RM)模型来预测人类偏好的输出。
step3:使用PPO针对奖励模型优化策略
使用RM的输出作为奖励,使用PPO算法对监督策略进行微调,以优化该奖励策略。
二、数据集:
prompt dataset:提示数据集主要由提交给OpenAI API的文本提示组成,也有标注者自己写的。
InstructGPT模型最早版本的提示是标注者自己写的,这是因为我们需要一个类似指令的提示的初始来源来引导进程,而这些类型的提示并不经常提交给API上的常规GPT-3模型。
早期自己写的提示有三类:
1、Plain 简单:任意的任务,同时确保任务具有足够的多样性
2、Few-shot:给出一条指令,以及该指令的多个查询/响应对
3、User-based:在OpenAI API的等待列表应用程序中声明了许多用例。我们要求标注人员给出与这些用例相对应的提示。
从这些提示(提交给OpenAI API的文本提示和标注者自己写的)产生三个微调阶段的数据集:SFT(Supervised fine-tuning) dataset(约13K提示,从API和手写获得),RM dataset(约33K提示,从API和手写获得),PPO dataset(约31K提示,只从API获得)。
提示分布和例子说明如下表:

三、任务:
1、显示的任务(如:“写一个关于聪明的青蛙的故事”);
2、隐式任务(如:给两个青蛙的故事,提示模型写一个新的故事);
3、续写(如:提供一个故事的开头)
四、模型:
1、Supervised fine-tuning (SFT):
根据RM分数选择最终模型
2、Reward modeling (RM):
把SFT模型最终unembedding层去掉。把提示和响应作为输入,输出奖励值。使用6B RMs。RM训练时将比较作为标签,对4-9个输出进行比较,产生个比较,将每个提示的
个比较作为一个训练批次,既不过拟合也能减少计算量(直接将所有比较打乱一起训练会导致过拟合)。
损失函数:

最后对奖励模型使用一个偏差归一化,以使得标注者示范例子在做RL前的平均分数是0。
3、Reinforcement learning (RL)
使用PPO算法优化SFT模型。
PPO:为每个token添加来自SFT模型的KL惩罚来缓和RM模型的过度优化,值函数从RM模型初始化。
PPO-ptx:将预训练模型梯度混合进PPO梯度
损失函数:

五、评价:
helpful, honest, and harmless.