自然语言处理 (NLP) 简介
自然语言处理 (Natural Language Processing NLP) 简介
本课程是关于NLP 101的4部分系列中的第1部分:
- 自然语言处理导论(今天的教程)
- BagofWords模型简介
- Word2Vec:自然语言处理中嵌入的研究
- BagofWords与Word2Vec的比较
这篇博客将简要介绍自然语言处理的历史。对NLP历史的简要介绍表明研究很久以前就开始了。研究人员利用了在语言学中对人类语言的理解所奠定的基础,并对如何推动NLP向前发展有了正确的想法。
然而技术的局限性成为最大的障碍,并且一度该领域的研究几乎停滞不前。但技术只有一条路,那就是前进。技术的发展为NLP研究人员提供了足够的计算能力,并拓宽了许多视野。
现在正处于语言模型帮助创建虚拟助手的阶段,这些助手可以交谈,帮助完成任务等。想象一下,世界已经达到了一个地步,一个盲人可以要求虚拟助手来描述一个图像,它可以完美地做到这一点。
这种进步是以牺牲严格的计算能力需求为代价的,最重要的是,访问大量数据。语言是一个这样的话题,像我们在图像中所做的那样应用增强技术根本无法帮助我们。因此,随后的研究方向集中在以某种方式降低这些巨大的要求上。
即便如此,NLP多年来的增长还是值得称赞的。这些概念既巧妙又直观。本系列的下一篇博客将重点介绍更详细的现代NLP概念。
1. 自然语言处理困惑和现状
我们用眼睛看东西将看到的物体分为不同的组。在工作中应用数学公式,甚至交流方式也需要大脑处理信息。所有这些任务都在不到一秒钟的时间内完成。长期以来人工智能的最终目标一直是重建大脑。 但目前受到一些限制,如计算能力和数据。
制造能够同时完成多个任务的机器是极其困难的。因此对问题进行分类,并将其主要分为计算机视觉和自然语言处理。
我们已经能够熟练地对图像数据进行模型处理。图像具有肉眼可见的基本模式,其核心是图像是矩阵。尤其是通过卷积神经网络取得的进展可以识别数字模式。
但是,当进入自然语言处理(NLP)领域时会发生什么?如何让计算机理解语言、语义、语法等背后的逻辑?由于图像的核心是矩阵,卷积滤波器可以很容易地帮助检测图像的特征。 对于语言来说,情况并非如此。使用CV技术最多只能教会一个模型从图像中识别字母。至少会导致26个标签的培训,总的来说,这是一种非常糟糕的方法,因为根本没有抓住语言的本质。那么如何解开语言之谜?
目前正处于语言模型的时代,如GPT-3(生成预训练Transformer 3)和BERT(Transformers的双向编码器表示)。这些模型能够根据完美的语法和语义与我们进行对话。
但这一切从哪里开始?
让我们通过历史简要回顾一下自然语言处理。
2. 自然语言处理的开端
语言作为一门科学,是语言学学科所包含的内容。因此自然语言处理成为语言学本身的一个子集。
人类创造了语言作为交流媒介,以更有效地共享信息。我们足够聪明可以创造复杂的范例,作为语言的基础。语言在历史上经历了广泛的变化,但通过它共享信息的本质仍然完好无损。
当听到苹果这个词时,一个新鲜的红色椭圆形水果的形象就会浮现在我们的脑海中。我们可以立即将单词与我们脑海中的图像联系起来。我们看到什么,触摸什么,感觉什么,复杂的神经系统会对这些刺激做出反应,大脑会帮助将这些感觉归类为固定的词汇。
但这里进行处理的是一台计算机,它只知道0或1是什么。我们的规则和范例不适用于计算机。那么如何向计算机解释像语言这样复杂的东西呢?
语言学本身就是对人类语言的科学研究。这意味着它需要对语言的各个方面进行彻底、系统、客观和准确的检查。自然语言处理的许多基础都与语言学有直接联系。
20世纪初语言学之父——德·费迪南德·索绪尔将语言描述为系统的方法,语言被规定为不是被视为一个混乱的事实的整体,而是一个所有元素都相互联系的大厦。语言中的声音代表了一种根据语境而变化的概念。在这个系统中,你可以将元素相互关联,从而通过因果关系识别语境。
20世纪50年代,艾伦·图灵发表了他著名的《计算机器和智能》文章,现在被称为图灵测试,或者称为“模仿游戏”,因为该测试旨在观察机器是否能模仿人类。“计算机器和智能”的原始文章问道:“机器能思考吗?”这里出现的一个大问题是,模仿是否等于独立思考的能力。该测试确定了计算机程序在与独立的人类法官进行实时对话时模拟人类的能力。
最值得注意的是,在浏览互联网时,CAPTCHA(区分计算机和人类的完全自动化公共图灵测试)会不时弹出。
1957年,诺姆·乔姆斯基(Noam Chomsky)的“句法结构”采用了基于规则的方法,但仍然成功地彻底改变了自然语言处理世界。然而这也提出了自己的问题,尤其是计算复杂性。之后出现了一些发明,但计算复杂性带来的惊人问题似乎阻止了任何重大进展。
那么,在研究人员慢慢获得足够的计算能力之后,会发生什么呢?
3. 计算能力逐步提升——自然语言处理找到了立足点
一旦对复杂硬编码规则的依赖性减轻,就可以使用早期的机器学习算法(如决策树)获得优异的结果。
20世纪80年代统计计算的兴起也进入了自然语言处理领域。这些模型的基础仅仅在于能够为输入特征分配加权值。因此,这意味着输入将始终决定模型所做的决策,而不是基于复杂的范例。
基于统计的非线性规划的最简单示例之一是n-grams,其中使用了马尔可夫模型的概念(当前状态仅依赖于前一状态)。在这里,我们的想法是在语境中识别对单词的解释。
推动自然语言处理领域向前发展的最成功的概念之一是递归神经网络(RNN),RNNs背后的想法很巧妙,但却极其简单。有一个循环单元,输入x1通过该单元。循环单元输出一个y1和一个隐藏状态h1,它携带来自x1的信息。
RNN的输入是表示一个单词序列的令牌序列。对所有输入重复此操作,因此,始终保留以前状态的信息。当然,RNN并不完美,被更强大的算法(如LSTM和GRU)取代。
这些概念使用了RNN背后相同的总体思想,但引入了一些额外的效率机制。LSTM(long short-term memory 长短时记忆)细胞有三个通路或门:输入、输出和遗忘门。LSTM试图解决长期依赖性问题,在这个问题上,它可以将输入与其之前的长序列相关联。然而,LSTM带来了复杂性问题。选通递归单元(GRUs Gated Recurrent Units )通过减少门的数量和降低LSTM的复杂性来解决这一问题。
让我们花一点时间来欣赏这些算法在20世纪90年代末和21世纪初出现的事实,当时计算能力仍然是一个问题。让我们看看我们用强大的计算能力所取得的成就。
4. 计算能力得到解决——自然语言处理的兴起
先来了解一下计算机是如何理解语言的。计算机可以创建一个矩阵,其中列指评估行中单词的上下文。
试图在有限的N维空间中“表示”每个单词。该模型根据每个N维中的权重来理解每个单词。这种表征学习方法于2003年首次出现,自20世纪10年代以来,它在自然语言处理领域得到了广泛应用。
2013年,word2vec系列论文发表。它使用了表征学习(嵌入)的概念,通过在N维空间中表达单词,并定义为该空间中存在的向量。
根据输入语料库的好坏,适当的训练将表明,当在可见空间中表达时,具有相似上下文的单词最终会在一起,根据数据的质量和在类似语境中使用单词的频率,其含义取决于其相邻单词。
这个概念再次打开了自然语言处理的世界,直到今天,嵌入在所有后续研究中都发挥着巨大的作用。Word2Vec的著名精神追随者是FastText系列论文,该系列论文引入了子词的概念,以进一步增强模型的能力。
2017年,注意力的概念出现了,这使得模型关注每个输入词与每个输出词的相关性。Transformers 这个令人困惑的概念是基于一种称为自我注意力的注意力变体。
Transformers已经生产出足够强大的模型,甚至可以轻松击败图灵测试。这本身就证明了在教计算机如何理解语言的过程中所取得的进步。最近,当任务训练的GPT-3模型出现在网络上时,GPT-3模型引起了巨大的轰动。这些模型可以完美地与任何人进行对话,这也成为了一个有趣的话题,因为为不同的任务微调它们会产生非常有趣的结果。
让我们看看transformers对语言的掌握程度(图6)。
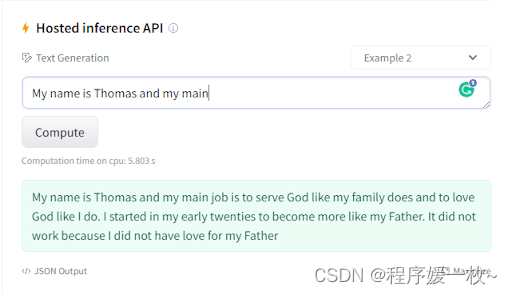
通过提供一些起始令牌,即GPT Neo 1.3B,EleutherAI的GPT-3复制模型为我们提供了一个小段落作为输出,最大限度地尊重语法和语义规则。
有一次,自然语言处理被认为过于昂贵,其研究也被严重停止。我们缺乏计算能力和数据访问能力。现在,有了可以与我们保持对话的模型,甚至不用怀疑我们在与非人类对话。
然而,如果你想知道GPT Neo名称中的1.3B代表什么,那就是模型中的参数数量。这充分说明了当今最先进的(SOTA)语言模型具有多大的计算复杂性。
参考
- https://pyimagesearch.com/2022/06/27/introduction-to-natural-language-processing-nlp/