关于数据中台的理解和思考
一、什么是数据中台
- 数据中台是指通过数据技术,对海量数据进行采集、计算、存储、加工,同时统一标准和口径。
- 把数据统一后,会形成标准数据,再进行存储,形成大数据资产层,进而为客户提供高效的、可复用的服务。
- 数据中台得基础主要是数据仓库和数据中心。
二、数据中台模型

1、连接数据孤岛打通用户的行为数据和各个业务数据。
2、业务数据化要用更加科学的方式存储数据,一般采用三层建模的方式,让收集上来的数据形成公司的数据资产。
3、数据业务化数据赋能业务人员、领导层进行决策,做到数据反哺业务。
三、数据管理
1、资产管理盘点数据资源、规划数据资源、获取数据资源,并将所有数据资源进行完整呈现,提升数据的利用率。
2、质量管理数据质量就是保障数据正确性的工具,主要包括这么几部分:一是支持准确性校验规则,二是支持双表校验,三是输出校验报告。
3、模型管理进行模型分层和统一开发规范,一个是规则配置,另一个是对表名、字段名的定期校验。
4、标签体系对用户、产品、客商、营销各主题域进行标签提取,将其特征数字化,为后续进行精准营销和用户画像提供必要条件。
四、业务模式
1、传统业务模式数据是副产物,业务人员基于行业经验和流程驱动业务系统,数据主要用于监测业务进展和洞察规律,最终决策由业务人员进行,整个业务流程迭代速度极慢,很难满足现在快速变化的前端应用,商业价值度较低。

- 新业务方式数据为业务系统核心,基于技术中台的能力,将企业内外部数据打通形成数据中台,由数据中台驱动业务中台,并利用业务中台的组件重构业务系统。由于有中台的支撑,各类开放服务可以对前端应用的快速变化做出响应,因此商业价值会更高。

五、整体架构
数据中台整体架构如图:

数据采集
- 采集数据:按照标准数据结构从业务信息系统的原始数据库中提取的数据,或者通过采集器传回的数据;
- 爬虫数据:互联网公开数据、企业信息数据包括工商信息、资质信息、项目信息、人员信息、备案信息、招投标公告、中标公告、资质审核公告等;
- 日志数据:各类平台系统产生的业务日志数据,服务器自身运行时产生的日志数据;
- 业务数据:施工项目结算系统、设计结算系统业务数据库数据;
- 原生数据:使用ERP、CRM、OA、workon等系统时产生的数据。
数据处理
- 数据抽取指从不同网络、平台、业务线数据库等数据清洗后抽取到数据中台统一存放。
- 数据计算和存储
- 数据分层模型
- ODL操作数据层全量数据,和数据源保持一致。
- BDL基础数据层对数据做统一清洗处理,去重、去噪(例如有一个用户的年龄180岁,就要做处理)、空值转换、日期格式化、字段命名规范等。
- IDL接口层主表或宽表,包含各个业务的完整数据全部字段。
- ADL应用层数据集市,与需求对接由IDL层基于某些维度的加工、统计、汇总等操作转化而来,各个表联合的结果。
- 模型之间数据传递
- ODL层数据主要包括MySQL数据、MongoDB数据、日志文件。
- ODL层 到 BDL层业务数据库的数据一般采用Sqoop来离线抽取,每天一次。使用Canal来进行实时抽取。日志文件数据可以使用Flume定时离线抽取。也可以使用Spark Streaming或Storm并借助Kafka来实时抽取。
- BDL到IDL层或ADL层定时离线任务使用Hive、Spark计算最后写入Hbase、MySQL、Redis中。实时数据使用Spark Streaming、Storm或者Flink来计算,最后会落入Es、Hbase或者 Redis 中。
- 数据分层模型
- 数据服务数据被整合计算好之后,以接口形式统一对不同业务线提供服务。

六、任务
数据采集
- 数据采集系统,能够通过配置,对不同网站进行快速爬取,保证数据需求。主要过程包括:数据源配置,验证码破解等;数据采集、简单清洗过滤;数据存储。
- 爬虫管理系统,方便部署爬虫项目,并能够远程启动、停止、查看爬虫。
- 使用python scrapy requests等实现。
数据分析
- 企业资质数据,分析企业项目信息、企业备案、企业资质信息、企业人员信息反映企业及技术人员的资格、能力、业绩等;
- 企业工商信息,分析企业信用,企业变更等数据建立企业诚信档案;
- 招投标信息,分析招投标数据,根据企业中标数据,精准推荐招标公告;分析不同的评标方法,评标因素等对中标的影响,从而提高中标率。
- 资质核准公告,分析资质评定因素、审核未通过原因;
- 设计系统数据,分析企业业绩、企业项目结算等
- 施工系统数据,分析施工数据;
- Workon数据,分析用户管理,企业管理;
- 日志数据分析用户行为等。
平台搭建
-
技术选型
- 操作系统Linux,大数据相关软件都运行在Linux上,Linux比较稳定性。
- Python 爬虫框架包括scrapy、requests等模块,数据处理框架有Pandas、Numpy等,能处理的数据量为GB级别,机器学习有scikit-learn、tensorflow等。
- Java 大数据基础平台中hadoop、Hive、Hbase都是以Java为核心的,处理数据量达到TB、PB级别。
-
架构组织功能

- Sqoop主要用于在Hadoop与传统的数据库(MySQL 、Oracle 、Postgres)间进行数据的传递,可以将关系型数据库中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- Canal阿里巴巴旗下的一款开源项目,主要用途是基于 MySQL 数据库增量日志解析获取增量变更进行实时同步。
- Hadoop分布式文件系统基于Java,主要由HDFS + YARN + MapReduce三个核心组件组成,HDFS是一个文件系统,负责分布式存储;YARN是Hadoop自带的一个通用的资源管理框架,用来对跑在集群上的Application进行资源分配及管理;MapReduce是一个分布式计算框架,跑在YARN上,配合HDFS用来做分布式数据计算。
- HBase是为有数十亿行和数百万列的超大表设计的,这是一种分布式数据库,可以对大数据进行随机性的实时读取/写入访问。基于Hadoop分布式文件系统(HDFS)而建,处理实时数据。
- Hive是面向Hadoop生态系统的数据仓库。它让用户可以使用HiveQL查询和管理大数据,这是一种类似SQL的语言,处理历史数据。
- Spark是一个分布式计算框架,相当于MapReduce的改进版,能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法,为Python、Scala、R等提供接口。
- Zookeeper分布式应用程序协调服务,用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
- Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。
- DataX 是阿里巴巴集团开源的离线数据同步工具,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、HBase、MongoDB 等各种异构数据源之间高效的数据同步功能。
- ElasticSearch是一个开源的基于Lucene的搜索服务器,它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,是一种流行的企业级搜索引擎。
- 人力工时评估
-
Python预估需2-5人,爬虫、数据挖掘、机器学习方向;
-
Java预估需2-5人,大数据方向;
-
工期预估6-12个月。
-
大数据服务
-
MaxCompute是阿里云的一项大数据计算服务,它能提供快速、完全托管的PB级数据仓库解决方案。
-
具体使用和学习方法:https://yq.aliyun.com/articles/68600?spm=5176.7944453.751675.1.330552df4eLjUL&aly_as=fiVTdtly
-
费用
存储费用根据数据实际存储量,按阶梯单价计算
| 存储量 | 阶梯单价 |
|---|---|
| 大于0小于等于0.5GB部分 | 固定0.01元/天,不涉及 |
| 大于0.5GB小于等于10TB部分 | 0.0072元/GB/天 |
| 大于10TB小于等于100TB 部分 | 0.006元/GB/天 |
| 大于100TB部分 | 0.004元/GB/天 |
计算费用10CU起购,包括SQL任务、MapReduce任务、Lightning任务、Spark任务。
| 资源定义 | 内存 | CPU | 售价 |
|---|---|---|---|
| 1CU | 4GB | 1CPU | 150元/月 |
下载费用按照外网下载的数据大小进行计费(数据上载不收费)
| 计费项 | 价格 |
|---|---|
| 外网下载价格 | 0.8元/GB |
七、数据建模
数据模型主要有关系模型,维度模型,实体模型。
关系模型
又叫ER模型,实际操作上大部分采用3NF建模,必须满足:每个属性值唯一;每个非主属性必须完全依赖与整个主键,而非主键得一部分;每个非主属性不能依赖于其他非主属性。
数据仓库的关系建模是站在全企业的高度,将各个系统中的数据按主题进行近似性组合和合并,并进行一致性处理,为数据分析决策服务,需要全面了解企业业务和数据。
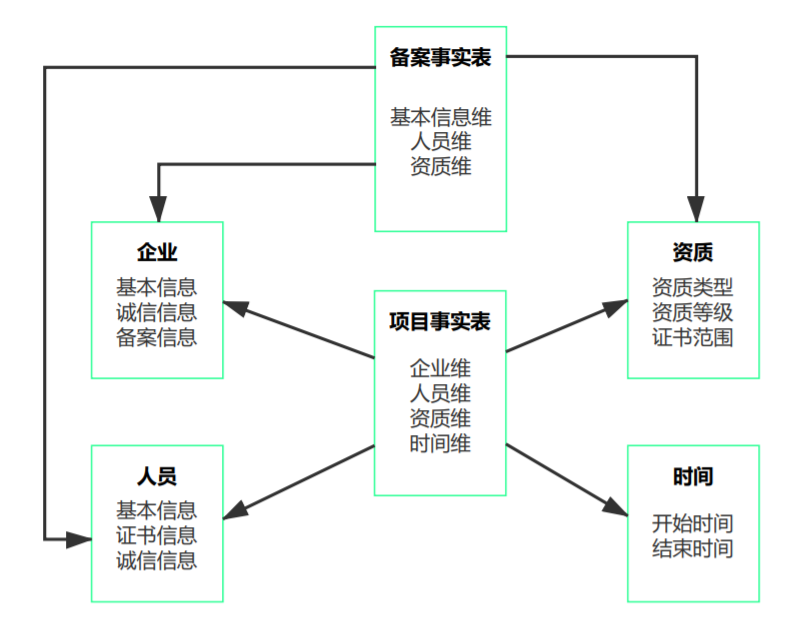
维度模型
维度建模是数据仓库领域比较常用的建模方法。维度模型属于关系模型,但是又两个新的概念,即维度表和事实表。维度表对应现实中的一个对象或一个概念,比如企业、资质、人员、日期等。事实表包含了各维度直接关系的度量值。维度建模的三种模式:星形模式、雪花模式、星座模式。
星形模式,比较常用的方式,以事实表为中心,所有维度表直接以外键形式连接在事实表上,维度表之间没有关联,这样的数据组织比较直观,执行效率高,建立数据集市的时候,大部分数据已经预处理,比如按维度统计、排序等。

雪花模型,在星形模型上将维度表扩展开,每个维度表也可以建立自身的子维度表。这种模型耦合性低,数据冗余小,但是跨表查询变多,导致性能降低。

星座模型,也是星形模型的扩展,允许存在多个事实表共用维度表。当公司业务逐步增多时,基本都会衍生成星座模型。