lvs+keepalived: 高可用集群
lvs+keepalived: 高可用集群
keepalived为lvs应运而生的高可用服务。lvs的调度器无法做高可用,于是keepalived软件。实现的是调度器的高可用。
但是:keepalived不是专门为集群服务的,也可以做其他服务器的高可用。
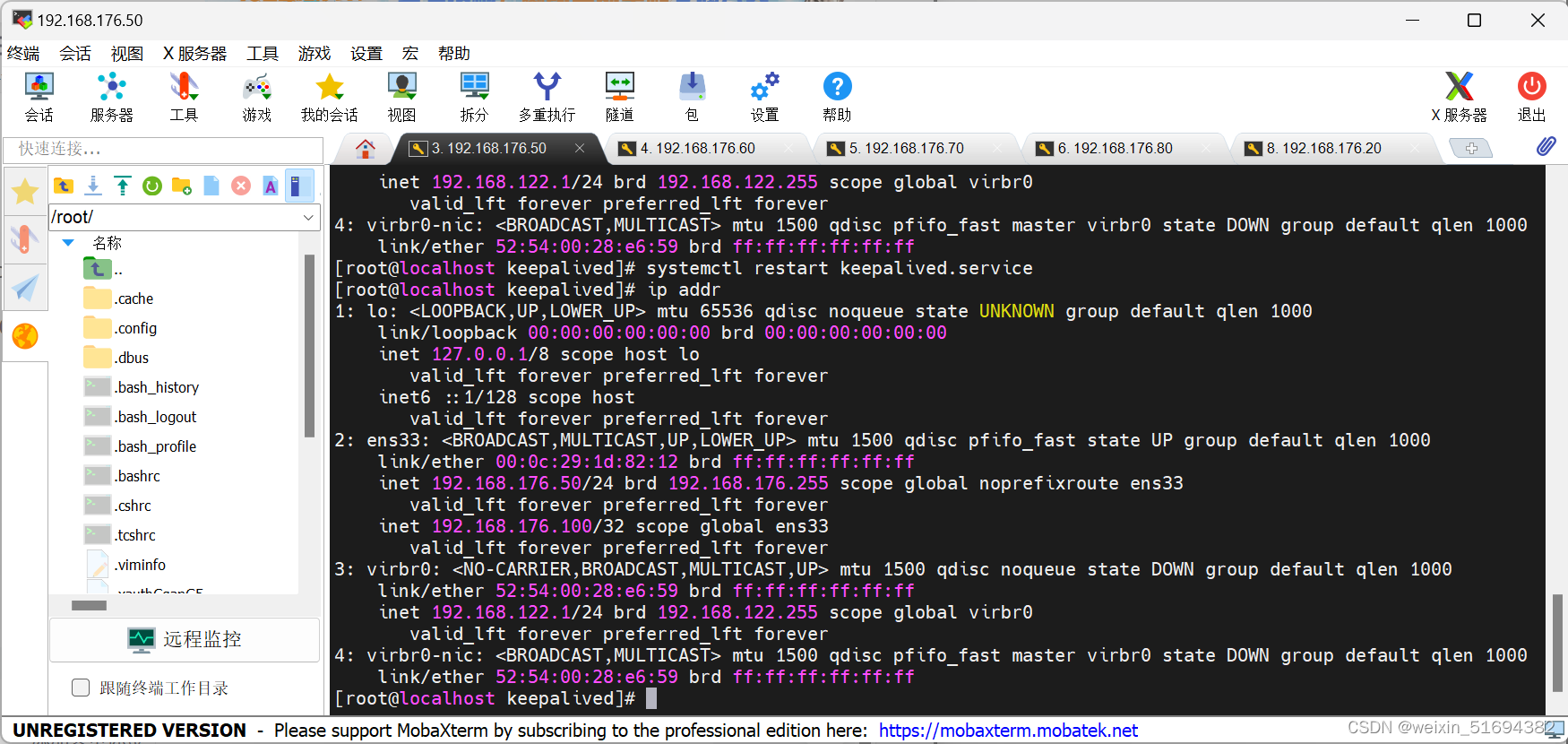
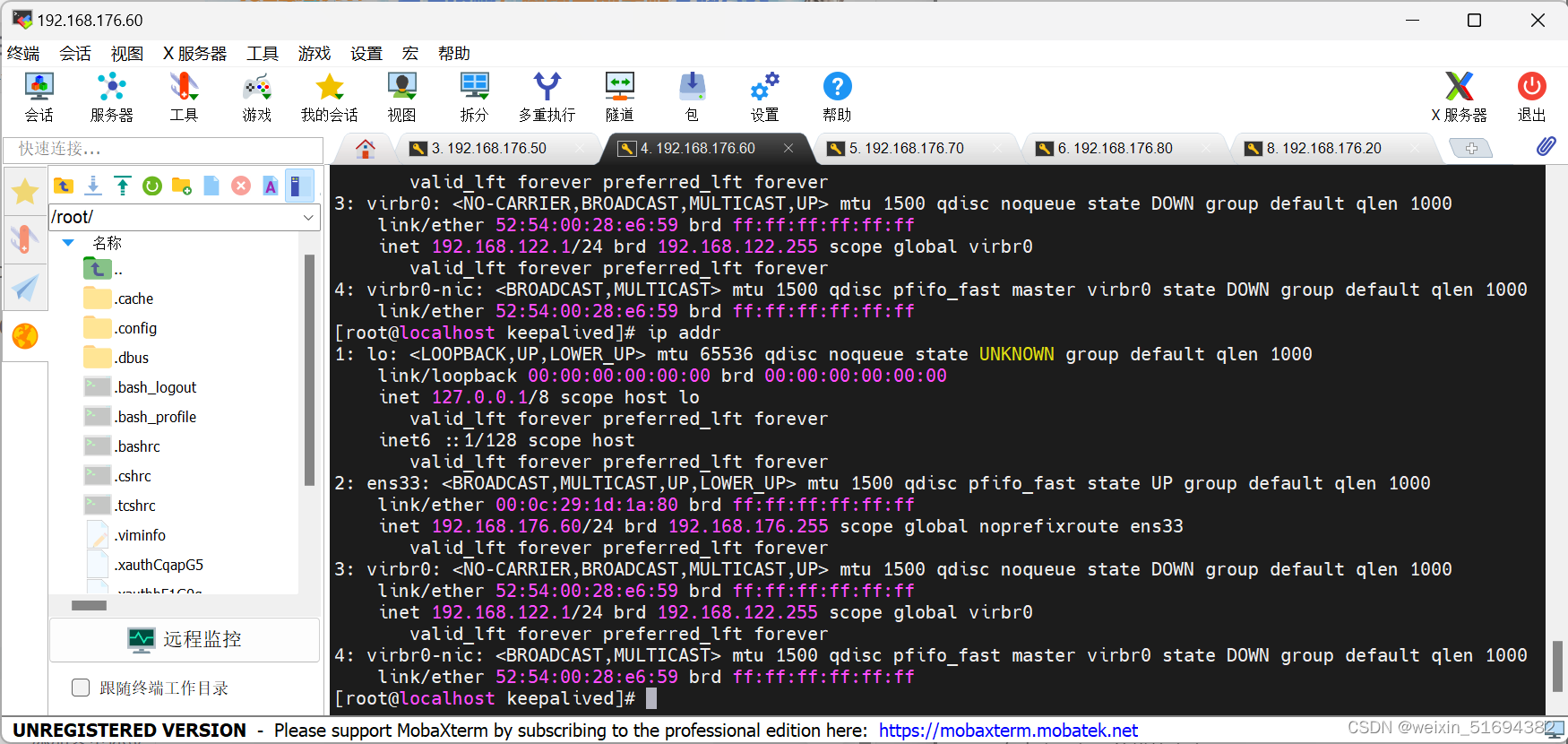
lvs的高可用集群:主调度器和备调度器(可以有多个)一主两备,一主一备。
主调度器能够正常运行时,由主调度器进行后端真实服务器的分配处理。其余的备用调度器处于冗余状态。不参与集群的运转。只有主调度器出现了故障无法运行,备调度器才会承担主调度器的工作。一旦主调度器恢复工作,继续由主调度器进行处理,备调度器又成了冗余。(和ARRP原理相同)
VRRP:keepalived是基于vrrp协议实现lvs服务的高可用。解决了调度器单节点的故障问题。
VRRP协议:提高网络路由器的可靠性开发的一种协议。
选举出主和备。预先设定好了和备的优先级。主高,备低。一旦开服务器,优先级高的,会自动抢占主的位置。
VRRP组播通信:224.0.0.18 VRRP协议当中主备服务器通过组播地址进行通信,交换主备服务器之间的运行状态。主服务器会周期性的发送VRRP报文消息,以告知其他备服务器。主服务器现在的状态。
主备切换:主服务器发送故障,或者不可达,VRRP协议会把请求转移到备服务器。通过组播地址,VRRP可以迅速的通知其他服务器发生了主备切换,确保新的主服务器可以正常的处理客户端的请求。
故障恢复:一旦主服务器恢复通信之后,由组播地址进行通信,发现在主服务器优先级更高,会抢占主服务器的位置,成为主服务器,调度和接受请求。
实验1:
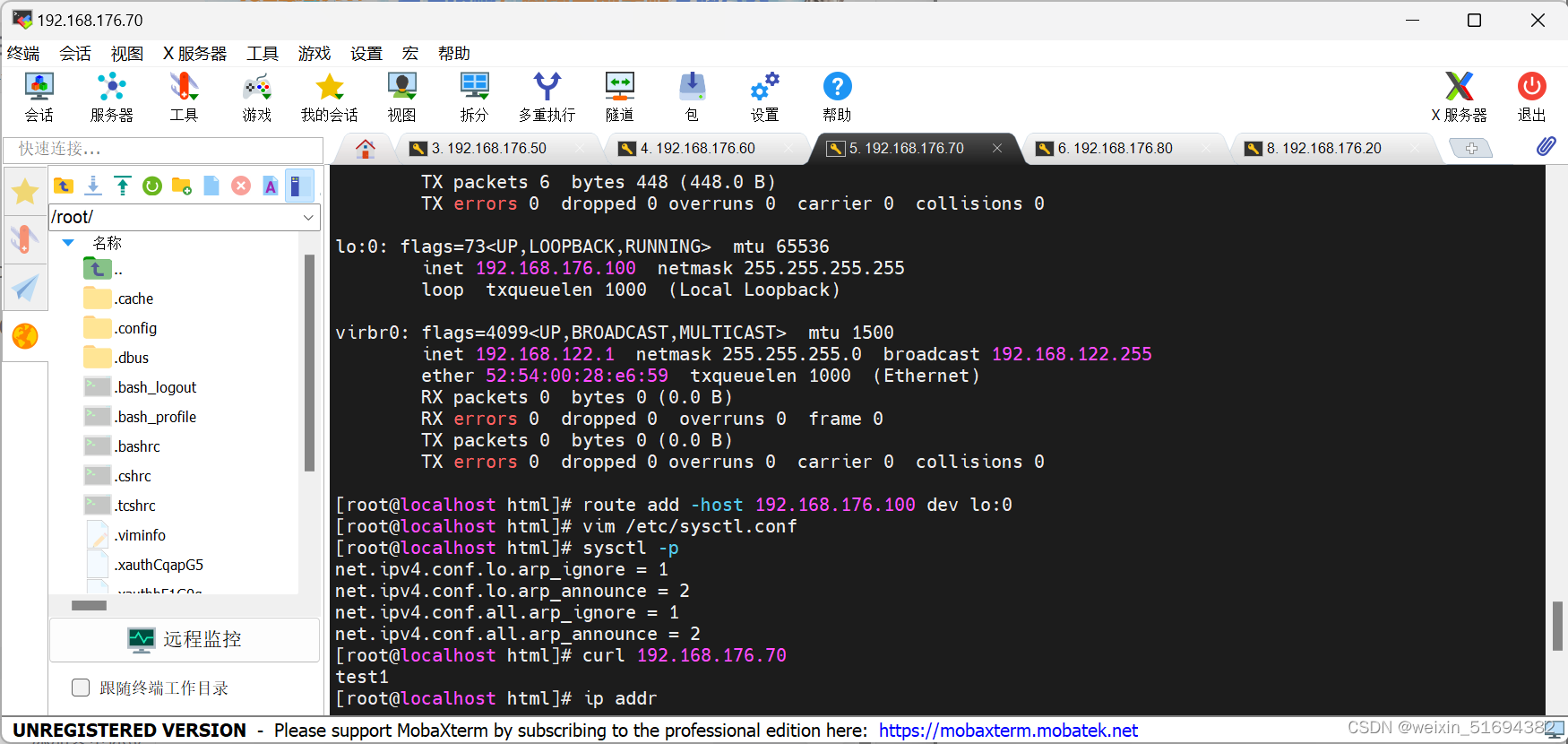
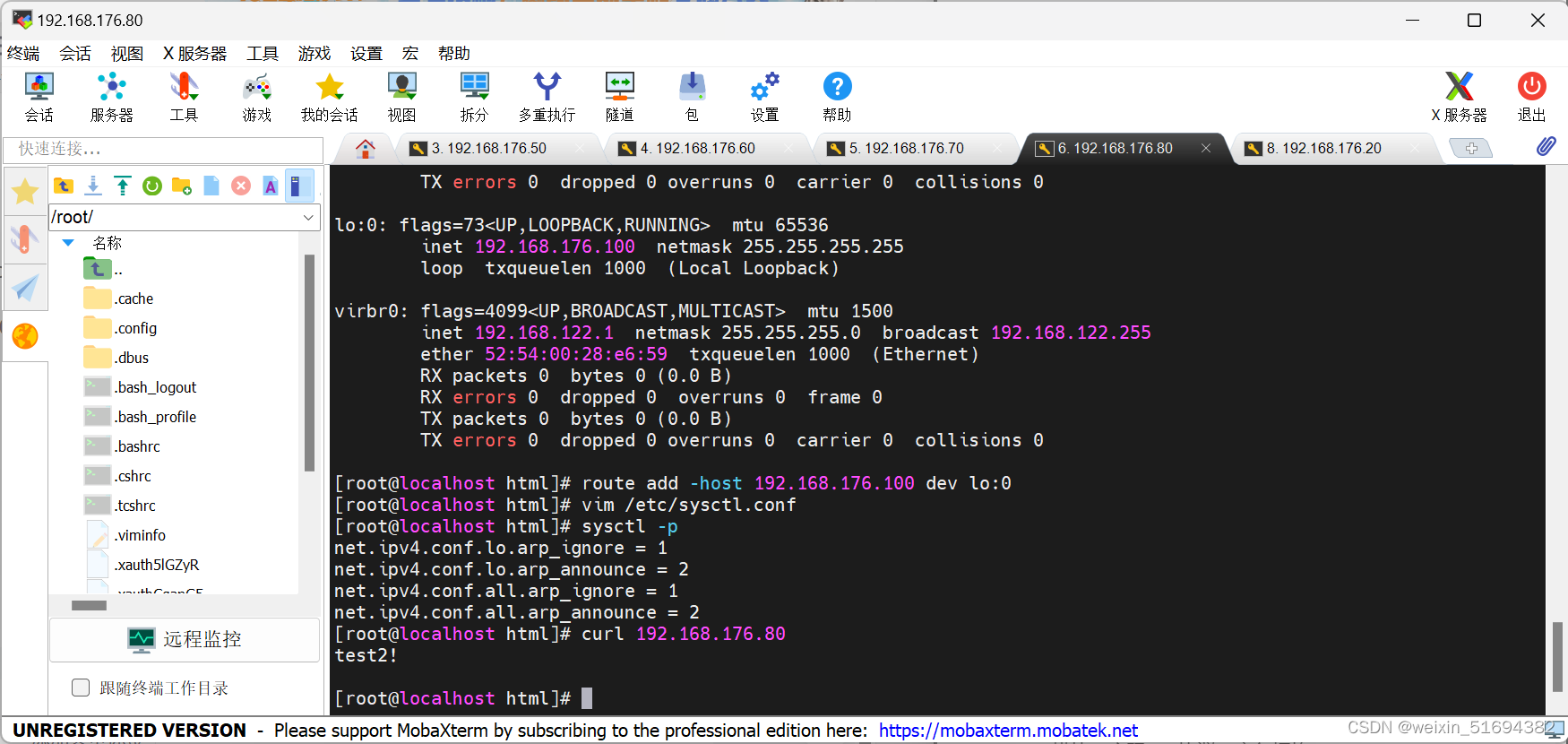
工作模式:lvs-DR模式结合keepalived
test1:主调度器 192.168.233.10
test2:备调度器
后端真实服务器1
后端真实服务器2
客户端
keepalived的体系模块:
全局模块:core模块,负载整个keepalived启动加载和维护。
VRRP模块:实现vrrp协议,主备切换。
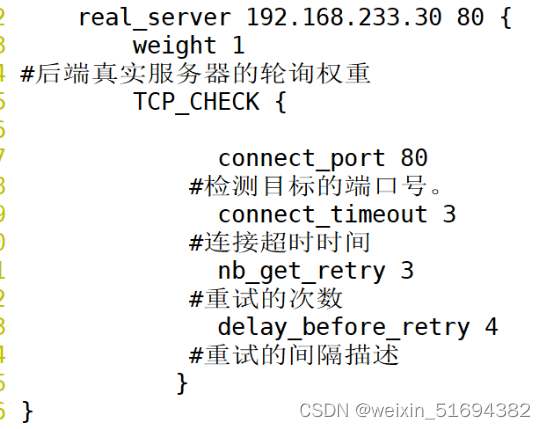
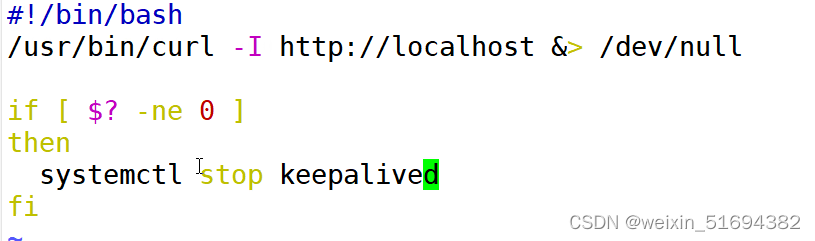
check:负责健康检查,检查后端真实服务器的健康。配置在真实服务器的模块当中。
工作中10秒左

面试题:什么是脑裂:主和备同时拥有vip地址。:在高可用系统当中。联系两个节点的心跳线,本来是一体的。动作协调的高可用系统。心跳线断开之后,分裂成了两个独立的个体。主备之间失去了联系,都以为对方出现了故障,两个调度器,就像脑裂人一样,开始抢占主的位置,抢占VIP。主也由VIP,备也有VIP。导致整个集群失败。
怎么解决:
软件层面:(基本上都是优先级)
1,配置文件。
2,tcpdump抓包分析
3,重启配置,先重启主,再重启备
就重启就可以了
网络层面:
高可用服务器之间心跳线检测失败。主备之间无法通信。
硬件层面:
连接主备之间的心跳线老化
网卡或者网卡的驱动失败,ip地址配置冲突。
防火墙没有配置心跳线的传输通道,导致检测失败
后端服务器的配置问题,心跳广播冲突,软件BUG。
如何解决keepalived脑裂的配置:
1,硬件:准备两条心跳线,这样断了一条依然能够传送心跳消息
2,设置防火墙一定要让心跳的消息通过
3,监控软件,实现监控(zabbix)。
面试时:说脑裂的现象是什么,说一下解决思路软件就重启,硬件就多插一条线,配置防火墙让他通过,实时监控。
生产当中的几个环境:
dev 开发环境 开发人员专用
sit 测试环境 测试人员使用(开发,运维)
pre 预生产环境 运维和开发 (和最终的生产环境保持一致)
prd 生产环境 (面向用户的最终环境)
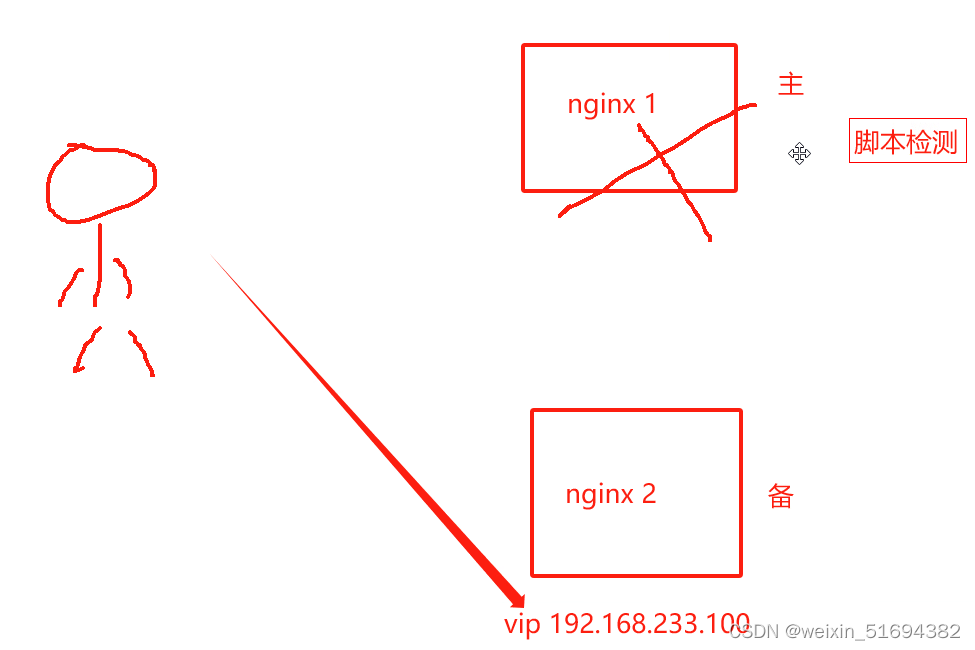
实验2:nginx+keepalive高可用
keepalived:
工作方式:基于vrrp协议;
1,确定主备
2,VIP地址只能有一个,出现在主服务器上。
3,VRRP 244.0.0.18组播地址,发送vrrp报文,检测主的心跳。
4,主备切换,主出现故障,vip地址会漂移到备
5,主服务器恢复,vip地址要回到主
6,脑裂主备都有vip 软件层面;检查文件,重启。
7,keepalived不是只能和lvs搭配,也可以和其他的服务配合,实现高可用。