目标检测YOLO实战应用案例100讲-改进YOLOv4的遥感图像目标检测
目录
前言
遥感图像目标检测国内外研究现状
传统遥感图像目标检测算法
深度学习遥感图像目标检测算法
2目标检测相关理论基础
2.1卷积神经网络
2.1.1基础理论
2.1.2卷积神经网络训练参数优化方式
2.2目标检测经典算法
2.2.1 两阶段目标检测算法
2.2.2 单阶段目标检测算法
2.3非极大值抑制
本文篇幅较长,分为上下两篇,下篇详见改进YOLOv4的遥感图像目标检测 (续)
前言
伴随互联网技术蓬勃发展,人工智能愈发强大,对计算机视觉领域的研究也开创了新 的时代,计算机可以解决越来越多的问题,例如对现实中的图像进行目标分类、目标检测 和跟踪等[1]。目标检测是我国计算机视觉中图像处理应用研究的热点方向之一,其根本任 务是通过提取输入图像的目标特征,分析得到目标所属类别和目标所在的位置,并用框标 出位置,同时显示所属类别及得分[2-3]。因此对图像进行目标检测方法的研究,对于其他领 域的应用有着重大意义[4]。
随着航天遥感技术的发展,遥感技术在军用、民用等多个领域都占据着重要的地位。 遥感技术是通过不同的传感器隔空获取地面目标的电磁特性,这些传感器可能搭载在航 空、人造卫星、无人机等机载平台上,再经过一系列操作处理最终得到遥感图像。所提供 的遥感图像中,可见光遥感图像能够最为直观的提供丰富的地面信息,随着其分辨率由低 分辨率向高分辨率转变、清晰度不断提升,所提供的地面信息的细节也越来越丰富,在各 领域的应用也越来越广泛。在空中侦察、无人机、军事航海等军用领域[5-6],通过对遥感图 像进行目标检测可以快速获得战事情报,实时监测飞机、军舰等军事目标,实时导弹预警 等,为国家国防提供重要信息[7]。在城市规划、灾难救援、自然灾害监测等民用领域[8-11], 通过对遥感图像进行目标检测,可以为保障人民安全、社会经济稳定发展提供重要信息。 因此,对遥感图像目标检测方法的研究及其应用有着重大的研究意义和价值[12-13]。
虽然对遥感图像和普通场景图像进行目标检测方法类似,但是可见光遥感图像在拍摄 角度、背景复杂和目标小且密集排列等方面和普通场景图像有所不同,这也是对遥感图像 进行目标检测的难点所在[14],具体如下: (1) 拍摄角度均是由上至下俯视角度拍摄,如图(a)(b)(c)。
(1) 拍摄角度均是由上至下俯视角度拍摄,如图(a)(b)(c)。
(2) 由于遥感图像多在高空取景,背景复杂,很多目标隐身其中,增加背景噪音。同时
在收集图像时,还受到天气情况、光照的影响,如图(b)。 (3) 目标小且密集排列,遥感图像中很多目标都比较小,例如船、油罐等,而且分布无
规律,有些聚集在一起,有些特别分散,这也会对遥感图像目标检测造成影响,如 图(c)。
由于遥感图像存在的这些特点,导致传统目标检测算法并不能很好的对其中目标进行 检测,在面对大规模遥感图像处理时,往往会暴露出许多不足。传统目标检测算法依托机 器学习[15],包括AdaBoost框架、支持向量机和梯度直方图等,先确定候选区域,通过滑 动窗口框住图像中的部分区域,然后通过人工先设计的特征提取框来进行图像的特征提 取,最后通过支持向量机等方法进行检测。该方法不仅需要大量的先验知识,还只能提供 浅层信息,使得目标检测的准确率和速度都较差。深度学习的快速发展使得卷积神经网络 (Convolutional Neural Networks, CNN)更为广泛应用于许多场景。研究发现使用CNN来进 行图像分类[16-17]、目标检测[18-20]等计算机视觉的相关任务时,可以大大提升其准确率,缩 短完成任务时间。与传统目标检测相比,在深度学习基础上的目标检测方法[21]可以通过监 督或者非监督学习等方法,从低级至高级自动学习所需的特征表示。对图像进行特征提取、 对目标进行分类和定位,均通过卷积神经网络完成,不需要人工设计特征,而是自主通过 数据进行训练,不断学习,端到端的完成目标检测[22-23]。
目前,对自然场景图像进行多分类的目标检测已经有很多优秀的检测方法,如单阶段 目标检测方法SSD[24](Single Shot multibox Detector)、YOLO[25-28](You Only Look Once)系列 等,两阶段目标检测方法 Faster R-CNN[29] (Faster Region-Convolutional Neural Network)、 Mask R-CNN[ 30]等,还有新兴FCOS[31](Fully Convolutional One-Stage Object Detection)、 CenterNet[ 32]等,这些方法在未来实际应用中都有良好的发展前景。然而,对于遥感图像来 说,在实际工程应用中,不仅仅需要考虑检测的准确性,模型大小、参数量以及检测速度 也尤为重要。在多数应用场景中,比如在空中侦察、实时导弹预警、灾难检测救助等,不 仅要保证良好的准确率,还要对场景进行快速检测,才能保证更好的应用于实际工程中。 使用基于深度学习的目标检测方法,使用更为深层次的卷积神经网络,模型复杂度提高使 得检测准确率也提高[33],但是多数复杂模型都存在参数量多、模型较大的问题,同时对部 署平台的计算性能要求高,存储设备需求大等,小型设备根本不能部署这些模型。能满足 快速处理目标检测的应用设备普遍使用强大的独立显卡,如Titan RTX、RTX2080Ti等, 显存一般都超过10G。很难部署在无人机、卫星等内存、算力和重量受限的平台。
轻量化网络为解决遥感图像目标的快速检测提供了可能,轻量化网络技术的关键点就 是使用更为高效率的神经网络结构,保持性能不下降的同时,降低神经网络的参数量和计算量。如今多数研究者提出轻量化网络是为了解决图像分类等问题,能够在保持效果的同 时减少模型大小,已经取得较好的成果,但是对于目标检测任务的轻量化网络模型研究较 少。
综上,随着遥感图像数据量变大、种类更为丰富、分辨率提升、时效性提高等多种方 面的提升,快速发展的遥感技术为遥感图像目标检测带来了更多机会。因此研究更高效率、 高准确率的基于深度学习的遥感目标检测方法对于其在各个领域的研究和应用有着重大 意义。
遥感图像目标检测国内外研究现状
目标检测作为计算机视觉基础的方法之一,最开始的传统机器学习方法通过人工进行 特征提取,现在基于深度学习的方法,目标检测效果得到了极大的提升。目标检测主要是 从图像中提取特征,分析后进行目标识别。传统目标检测算法依托人们的先验知识,对原 始数据进行特征处理,获取手工特征,而目标识别阶段是基于模式识别,根据提取到的手 工特征,将目标进行分类。早期的遥感图像目标检测算法[34]都是采用传统目标检测方法, 提取出候选区域,对预测目标人为设计特征,最后使用分类器进行分类。深度学习目标检 测算法最值得关注的就是通过卷积神经网络进行特征提取,相比传统方式,基于深度学习 的方法是让网络模型自己学习提取特征,由特征层组成更高级的特征进行表现,其展现出 了一定的优越性,可以大幅度提升目标检测的精确率,保持较快的检测速度。但是由于遥 感图像的特点,现有的基于深度学习的目标检测不能直接用于遥感图像的目标检测,而是 普遍在其基础上提出许多改进方案[35],提升遥感图像的目标检测性能。
传统遥感图像目标检测算法
传统目标检测算法一般由三个部分组成,分别是候选区域的生成、目标定位、匹配分 类。在过去国内外相关人员提出了许多传统遥感图像目标检测算法,根据已有的自然场景 目标检测的方法进行改造,可以分为三种:基于先验模板的方法,基于知识和规则的方法, 基于机器学习的方法。
(1)基于先验模板的方法:此方法容易实现,是遥感目标检测最开始使用的算法之 一。先验模板方法最重要就是得到先验模板,该模板可以是手工设计的,也可以使用训练 集生成的。将生成的模板通过欧氏距离、差值等相似性度量等方法与图像形成最佳匹配。 根据模板的不同性质,还可以分为两类。第一类是当模板和图像的方向和尺度不同时也可 以进行匹配,Kim等人[36]采用最小二乘法进行模板匹配,使用矩形模板替换剖面图,实现 对城市遥感图像的城市带状道路进行目标跟踪。Weber等人[37]提出自适应二进制方法,可 以对不同尺寸的目标进行检测,例如遥感图像中的建筑、油罐等遥感目标。这类方法对方 向变化、尺度大小较敏感,且要求模板的精度较高,不适用于同一类别中有较大差异的情况;而另一类方法在对存在差异较大的情况时有更高的灵活性。Kass等人[38]提出根据预先 设计的模板,对轮廓曲线进行动态调整,找到能力最小的轮廓即为目标。虽然该类方法灵 活度更高,但是先验信息较多,计算量大,参数量过多。
(2)基于知识和规则的方法:此方法是传统目标检测算法中应用于遥感图像领域比 较常用的方法。将目标检测问题设置为假设检验问题,重点是设定知识和规则。其中上下 文和几何知识是最为流行的,其中上下文知识是目标和相邻背景的联系,例如飞机和其影 子等,Peng等人[39]提出了阴影和上下文相关联的方法,验证建筑物,并在城市航拍图像数 据集上进行实验。几何知识使用特殊的参数或者通用形状编码等先验信息。Tinger[40]等人 提出了包含几何特征和辐射特性的道路检测模型,采用手工设计的规则生成道路假设,并 由自顶向下的流程验证假设。基于知识和规则的目标检测方法最重要的就是定义目标的知 识和规则,定义的内容会直接影响检测效果,定义的过于宽松会造成误检,过于精细会造 成漏检。
(3)基于机器学习的方法:使用分类的方法来进行目标检测,使用HOG[41]、SIFT[42] 等方法来提取图像中的特征描述子,然后使用监督或者弱监督学习的方法训练分类器,使 用分类器进行分类。许多研究已经发现支持向量机[43](Support Vector Machine, SVM)和 条件随机场对分类识别遥感目标比较有效,K邻近[44]算法适用于简单的特征数据。Bai等 人[45]提出了一共整合SIFT和目标空间信息的新特征描述子,使用SVM将目标检测问题转 换为查询任务以便检测遥感图像中的目标。Shi等人[46]提出通过高光谱获得船舰的位置, 将船舰视为异常,增强HOG特征形成假设并检测目标。基于机器学习的目标检测方法, 由于将特征提取和分离器训练相结合使得在检测效果方面取得了一定的提升,但是特征提 取出来的特征实质上只是中低层的特征,提取不到包含高层语义的特征信息,而且需要根 据目标类型的不同设计不同的特征,不能很好的应用于不同类别目标的检测,同时检测结 果受参数和训练样本的影响,往往结果不能令人满意。
深度学习遥感图像目标检测算法
深度学习的迅猛发展,使得计算机视觉也快速发展[47]。目前,应用最为广泛的目标检 测方法均基于深度学习。该方法最值得关注的就是通过卷积神经网络进行特征提取,还可 以使用GPU加速训练和检测,相比传统手工方式,可以大幅度提升检测精度和速度,检 测性能远远超出了传统目标检测算法。2014年Girshick等人[48]提出R-CNN模型,首次将 深度学习应用到目标检测中,结果检测精度远远超出传统目标检测算法。该算法主要通过 选择性搜索算法得到大量的候选框,再利用卷积神经网络对候选区域进行特征提取,并进 行分类和定位,最终得到检测结果。现今基于深度学习的目标检测方法可分为两大类[49]: 一种是两阶段目标检测,例如R-CNN、Fast R-CNN和Faster R-CNN等。该类型的算法将候选框机制和卷积网络的分类器有机地结合在一起,分两个阶段来实现:第一个阶段就是 对图像中所需要提取的特征数据进行粗略的回归分类,从而可以得到一系列被建议的区域 (proposal);第二个阶段使用前面所得proposal候选框来做回归和分类计算。此外,Corner Net[ 50]和Extreme Net[51]提出了一种新的无需设置锚框参数的检测方法,降低了因使用锚框 所带来的计算量。
这些两阶段的目标检测算法的普遍检测的精确率较高,但是检测效率一般,不能满足 快速检测的需求;相比之下,另一种以SSD和YOLO系列为代表的单阶段目标检测模型, 提出将所有运算封装在一个CNN中,通过主网络提取特征进行一次回归与多分类计算, 同时预测目标的位置和类别信息,从而很大程度上加快了检测速度。为进一步提升目标检 测算法的准确率和检测速度,许多专家研究如何优化算法。例如FPN[52]这种多尺度特征融 合方式,自顶向下和自底向上两种融合方法,可以引入更多的上下文信息,提升算法的检 测效果。为了进一步提升检测速度,谷歌团队提出了轻量级卷积神经网络MobileNet,可 以部署在移动端,使用深度卷积和点卷积组合替换普通卷积,并且基于SSD构建更为轻量 化的目标检测模型[53],为深度学习在实际工程中的应用提供了一个思路。
随着基于深度学习的目标检测算法应用越来越广泛,并取得了显著成效。因此,许多 研究遥感图像领域的研究者将深度学习引入遥感图像目标检测中。Cheng等人[54]提出一种 改进CNN模型的遥感目标检测算法,在R-CNN框架中引入旋转不变层,并优化目标函数, 降低角度对卷积神经网络特征提取的影响,提升了检测精度。文献[55]提出了一种基于深 度学习的遥感目标检测算法HSF-Net,用于检测舰船目标,该方法基于Faster R-CNN,使 用分层选择滤波层,将多尺度的特征映射到同一尺度上。Yang等[56]在2018年提出一种可 对飞机目标的高效检测方法,将残差网络和超矢量编码相结合,增强小目标的特征表达能 力,提高检测效果。同期XU等[57]将特征融合技术应用到全卷积网络中,提高飞机目标定 位精度。Etten等人提出YOLT[58]方法,将YOLOv2模型引入至遥感图像检测领域,并针 对遥感图像分辨率较大,目标尺寸较小的特点,研究数据预处理方式,保持检测精度的同 时,一定程度上提升了检测速度。Tang等人[59]在SSD算法的基础上,通过对每个特征图 使用不同比例的默认框生成预测框,用于检测车辆目标。Liu等[60]增加CBL (Convolution Batch Normalization Leaky ReLU)操作在YOLOv3特征提取网络中,更有效进行特征提取, 用于航拍汽车检测。许等[61]将密集连接网络加入YOLOv3中,代替部分残差连接,与原 YOLOv3相比遥感目标的检测能力有所提高,但是检测速度较慢。
2目标检测相关理论基础
2.1卷积神经网络
1998年,在生物视觉信息传递机制的启示下,LeCun等人[62]提出了Le Net-5,这是第一 个卷积神经网络,其中的感受野概念尤为重要,引起了众多学者的研究和探讨。2012年, Alex Net[ 63]在Image Net[64]竞赛上获得了出色的成绩,使得CNN进入计算机视觉算法研究者 的视野。CNN的主要是由多个不同的结构组成,每一部分有各自的任务,通力合作来实现 对特征的提取和分类。一个图像输入经由CNN结构中,会通过每一部分提取特征信息,通 过这些信息进行反向误差传播,进行预测,根据结果对结构中的参数进行调整,减少损失 函数的大小提升学习性能,由全连接层进行分类处理。一个标准的CNN网络结构主要由卷 积层(Convolution Layer)、池化层(Pooling Layer)、激活函数(Active Function)和全连接层 (Fully Connected Layer)等构成。
2.1.1基础理论
(1)卷积层
卷积层作为整个CNN的关键,主要任务是通过卷积运算的方式得到输入数据的特征, 该卷积方式使用可自主学习的卷积核,不断通过训练,迭代优化卷积核的参数,得到包含 丰富语义信息的特征。同一卷积核在输入的所有位置上通过卷积操作决定卷积的输出,卷 积操作可以使得需要的特征被加强,抑制不必要的干扰。输入图像每个位置的特征都不同, 然后利用不同尺寸的卷积核提取不同的特征,对于较深的神经网络,利用从简单到复杂的 卷积核依次提取特征。 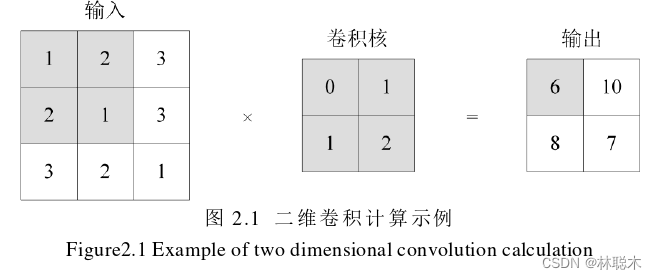
对二维卷积进行具体说明,如图2.1所示,当输入一个3×3的数组,使用2×2的卷积 核来进行卷积操作,具体运算过程如图中阴影所示,将对应的元素通过相乘再相加的方式, 得到输出中的第一个结果,在输入矩阵数组中进行相同步骤进行滑动,得到最终输出结果。 卷积过程如图2.2所示,输入图像尺寸为h×w×C,使用m个卷积核进行操作,卷积核尺寸 为k×k×C,最终生成大小为 h’×w’×m的特征图。 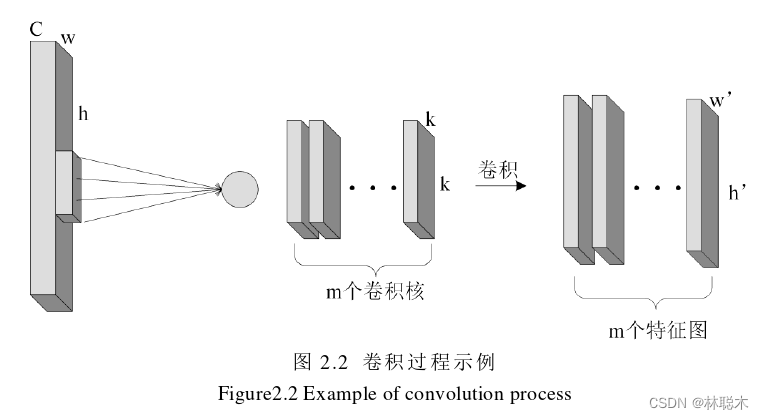
(2)池化层
经过卷积操作得到的特征信息多数时候都比较复杂且庞大,若直接对信息进行处理, 不仅会产生庞大的计算量,还会导致效率变低,池化层就是用来解决这种问题。池化层又 叫做下采样,可以用于降低网络模型的复杂度、降低特征维度,将所提取到的特征去繁就 简,减去冗余的特征信息。一般通过最大池化操作或者均值池化操作对特征进行下采样操 作,其中也有卷积核等参数,普遍的卷积核尺寸为2×2。池化层操作有很多优点,可以更 针对性的留下重要的特征信息,具有平移不变性,还可以剔除冗余的信息,提高操作效率, 实现模型的简化。
(3)激活函数
现实生活中存在的问题普遍是非线性的,激活函数的作用就是增强卷积神经网络中输
出的非线性因素,利用其来进行非线性处理。()常见的激活函数ReLU Rectified Linear Unit
最大的优势是收敛速度快,计算梯度简单,可以避免梯度消失,是现在使用较多的激活函 数。其他常用的还有Sigmoid、Tanh和Mish等。四种激活函数的计算公式如式2.1所示:
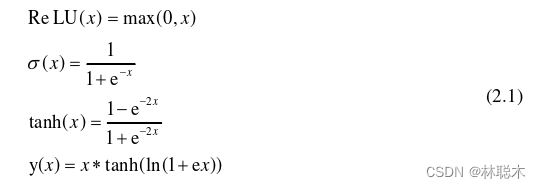
(4)全连接层
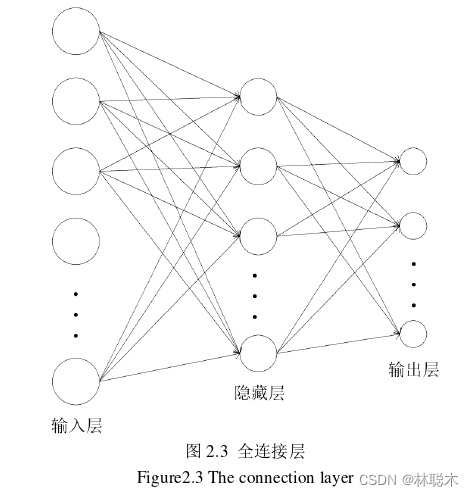
全连接层一般在网络的最后,可以整合卷积层中包含类别的信息。如图2.3所示,经 过前面的操作后输入数据变成了包含大量信息的多维特征,为了能够分类,需要将多维信 息展开为一维的特征向量,然后通过矩阵向量的乘积运算,对提取的信息进行加权,得到 最终的结果。
2.1.2卷积神经网络训练参数优化方式
卷积神经网络训练参数常用的有三种优化方式,分别为梯度下降法、反向传播和迁移 学习。
梯度下降法:是一种通用的优化方法,先使用误差反向传播算法Back (Propagation algorithm, BP)[ 63]算法计算参数的梯度,然后沿着目标函数梯度下降的方向不断更新参数 值,迭代到取得较小的损失函数值,最后得到全局最优解。梯度下降法是现在深度学习网 络中最常用的优化方法。
反向传播:随着深度学习的发展,网络层次越来越多,参数量激增,计算也愈发复杂。 反向传播就是梯度下降法的具体实现方式。数据经由网络得到输出,而输出的最终结果与 真实结果往往有一定的偏差。该方法主要是将最后得到的输出结果与实际结果比较得到的 误差,将误差反向传递,更新参数值,来达到优化模型的方法。
迁移学习:其主要是将已经训练完成的模型作为基础,然后将该模型用于其他模型的 训练中,这样明显降低了训练时间,还能大幅度提高模型的性能。表2.1显示迁移学习的 方法,根据数据集大小的不同和相似度来确定最终使用的迁移学习方法。在多数卷积神经 网络中,浅层网络一般学习到的是最为基础的信息,这些基础的信息包含纹理或者边缘特 征等,在很多问题中都是相似的,因此适当使用迁移学习是达到快速优化模型的方法。

2.2目标检测经典算法
2.2.1 两阶段目标检测算法
两阶段目标检测算法是将候选框机制和卷积网络的分类器有机地结合在一起,分两个 阶段来实现:第一个阶段就是对图像中所需要提取的特征数据进行粗略的回归分类,从而 可以得到一系列被建议的区域(proposal);第二个阶段使用前面所得的proposal 来做回归和 分类计算。这些两阶段的目标检测算法精度虽然较高,但是效率较低,普遍存在检测速度 慢、模型过大等问题。下面以经典的两阶段目标检测算法Faster-RCNN为例,介绍两阶段 目标检测算法的原理。
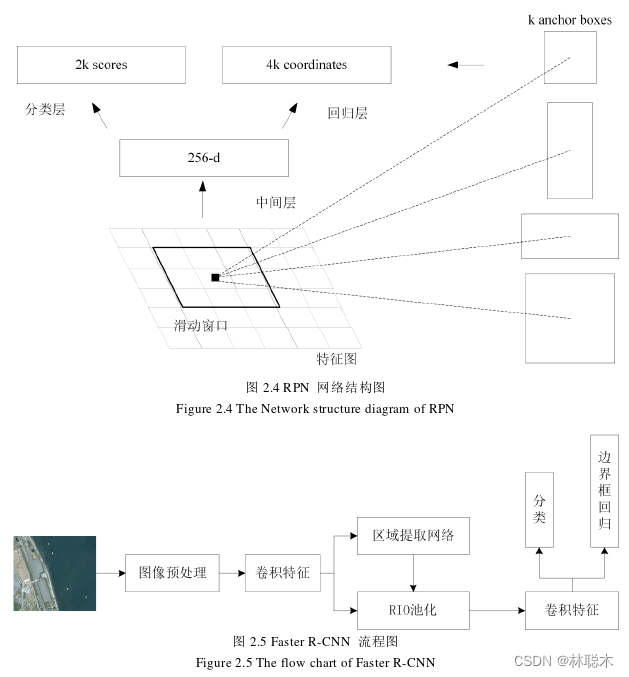
Faster R-CNN是在R-CNN和Fast R-CNN基础上改进得到的,其最大的改进点是使用 区域生成网络(Region Proposal Networks, RPN),RPN的网络结构如图2.4所示。使用RPN 替代选择性搜索,加速候选框的提取。RPN是一个全卷积网络,通过滑动窗口获得特征图, 然后继续卷积操作进行二分类,最后得到候选区域。
如图2.5所示,可以看出Faster R-CNN 的主要流程:首先,输入图像到CNN中,进 行特征提取;其次,使用RPN网络先生成尺寸不同、比例不同的候选框,并使用softmax 方法对这些候选框进行判断,确定是物体还是背景,与此同时使用回归修正候选框,得到 较为精确的候选框;最后,通过ROI pooling生成固定尺寸的特征图,再用Softmax函数对 其进行分类,利用Smooth L1 Loss函数进行边框回归,获得目标的精确位置。Faster R-CNN 的训练较为简单,是一个端到端的训练,不需要分别对网络的局部进行训练,其将分类器 和回归做了良好的结合。
综上所述,Faster R-CNN将特征提取和候选框生成相结合,极大的缩短了生成候选框 的时间。使用共享的卷积层进行特征提取,增强方法的特征提取能力,提高了小目标的检 测精度。但是尽管Faster R-CNN的检测速度已经有了很大的提升,但是距离达到实时检测 还有很长的距离。
2.2.2 单阶段目标检测算法
单阶目标检测算法以SSD和YOLO系列为代表,提出将所有运算封装在一个CNN中, 通过主网络提取特征进行一次回归与多分类计算,同时预测目标的位置和类别信息,从而 很大程度上加快了检测速度。
(1)SSD
SSD作为主流的单阶段目标检测模型之一,骨干网络采用VGG16分类网络,并新增 一系列尺度不同的卷积层。其中,较大的特征图来检测相对较小的目标,较小的特征图检 测相对较大的目标。VGG16中的Conv4_3层将作为第一个特征图,从后面新增卷积层中再提取五个检测所用的特征图,得到共六个特征图用于检测。
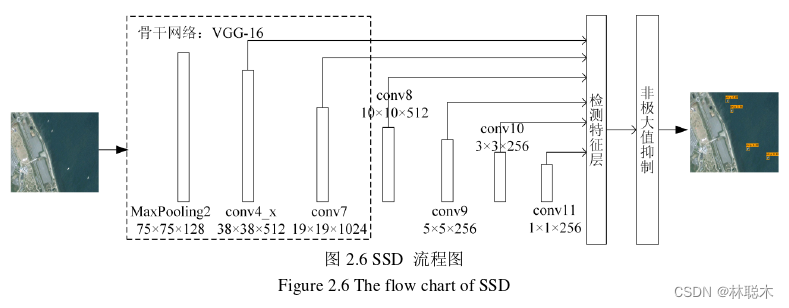 SSD流程图如图2.6所示。其主要检测流程为:首先输入图片通过resize操作将长宽 均变成300,将处理后的图片输入到主干特征提取网络VGG16中,添加四个卷积块,得到 六个有效特征层;其次,上述提到的六个特征层,每个特征层的每个特征点对应的先验框 数量分别为4、6、6、6、4、4。对每一个特征层通过两次卷积操作,一次用于预测该特征 层上每个特征点上每一个先验框的变化情况,另一次用于预测该特征层上每一个特征点上 每一个预测对应的种类。共生成8732个先验框;最后,通过图片高度和宽度调整先验框 获得预测框的宽和高以及中心位置,对每一个预测框进行得分进行排序,并通过非极大抑 制筛选,得到最终预测框,并在图片上绘制结果。SSD多尺度特征提取的方法使得不同尺 寸的默认框与不同尺寸的目标相匹配,提高了算法对小目标的检测能力。
SSD流程图如图2.6所示。其主要检测流程为:首先输入图片通过resize操作将长宽 均变成300,将处理后的图片输入到主干特征提取网络VGG16中,添加四个卷积块,得到 六个有效特征层;其次,上述提到的六个特征层,每个特征层的每个特征点对应的先验框 数量分别为4、6、6、6、4、4。对每一个特征层通过两次卷积操作,一次用于预测该特征 层上每个特征点上每一个先验框的变化情况,另一次用于预测该特征层上每一个特征点上 每一个预测对应的种类。共生成8732个先验框;最后,通过图片高度和宽度调整先验框 获得预测框的宽和高以及中心位置,对每一个预测框进行得分进行排序,并通过非极大抑 制筛选,得到最终预测框,并在图片上绘制结果。SSD多尺度特征提取的方法使得不同尺 寸的默认框与不同尺寸的目标相匹配,提高了算法对小目标的检测能力。
(2)YOLO
YOLO系列算法凭借其较强的实时性而被广泛应用各个领域的目标检测,其主要是将 检测看作一个回归问题,整张图片输入到网络中,通过检测头直接回归边界框的位置和所 属类别。YOLOv1作为第一代算法,其达到了较高的检测速度,且通用性较强,但是由于 使用全连接层进行输出,被检测图片的尺寸有限制,必须和训练图片相同。同时,小目标 的检测性能较低。
YOLOv2在YOLOv1的基础上进行改进,保持检测速度的同时,提高检测精度和识别 目标类别数。提出了一个新的训练方式,在分类数据集和检测数据集上同时训练算法,用 分类数据集增加识别目标类别数,用训练数据集学习目标的位置,去掉网络结构中的全连 接层,引入锚框机制,提高召回率,可以输入尺寸不同的图片,解决了图片分辨率不同的 问题,使用Darknet-19作为骨干网络。相比YOLOv1,提高了检测速度和检测精度。
YOLOv3使用Darknet-53替换Darknet-19进行特征提取,因其包含残差结构且添加了 跳跃连接,可以通过增加网络的深度提高目标检测的准确率,也缓解了深度增加带来的梯 度消失问题。同时,引入多尺度预测FPN,对提取的特征进行加强,将得到的三个特征图进行特征融合,得到信息更为丰富的特征图。经过模型完善,YOLOv3的目标检测性能已 经达到了一定的水平。
在此基础上,YOLOv4融合了许多目标检测领域较为优秀的技术,在YOLOv3的基础 上进行改进,是一种更为强大而高效的算法。其网络结构如图2.7所示,主要包含主干网 络、特征增强网络和预测网络三部分。
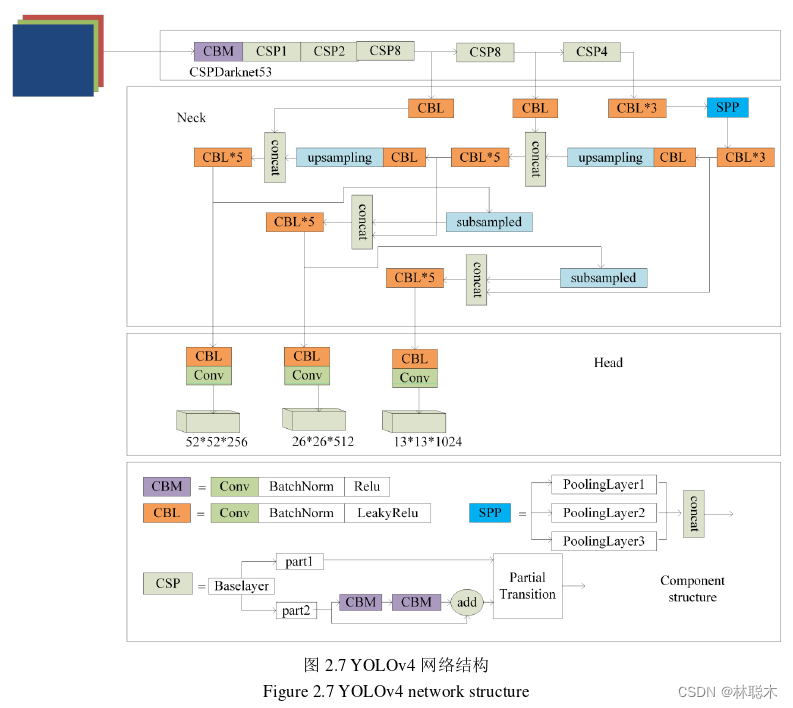 主干网络也称为特征提取网络,选用CSPDarkNet-53进行特征提取,在YOLOv3的基 础上增加了跨阶段初等网络(Cross Stage Partial Network, CSPNet),解决了大型卷神经网 络中的梯度信息重复问题。如图2.8所示,CSPNet首先将基础的特征映射分为两部分,一 部分使用残差连接,缓解梯度爆炸问题,避免出现过拟合现象,另一部分使用跳跃连接并 与第一部分合并,降低计算量,从而减少训练时间。
主干网络也称为特征提取网络,选用CSPDarkNet-53进行特征提取,在YOLOv3的基 础上增加了跨阶段初等网络(Cross Stage Partial Network, CSPNet),解决了大型卷神经网 络中的梯度信息重复问题。如图2.8所示,CSPNet首先将基础的特征映射分为两部分,一 部分使用残差连接,缓解梯度爆炸问题,避免出现过拟合现象,另一部分使用跳跃连接并 与第一部分合并,降低计算量,从而减少训练时间。
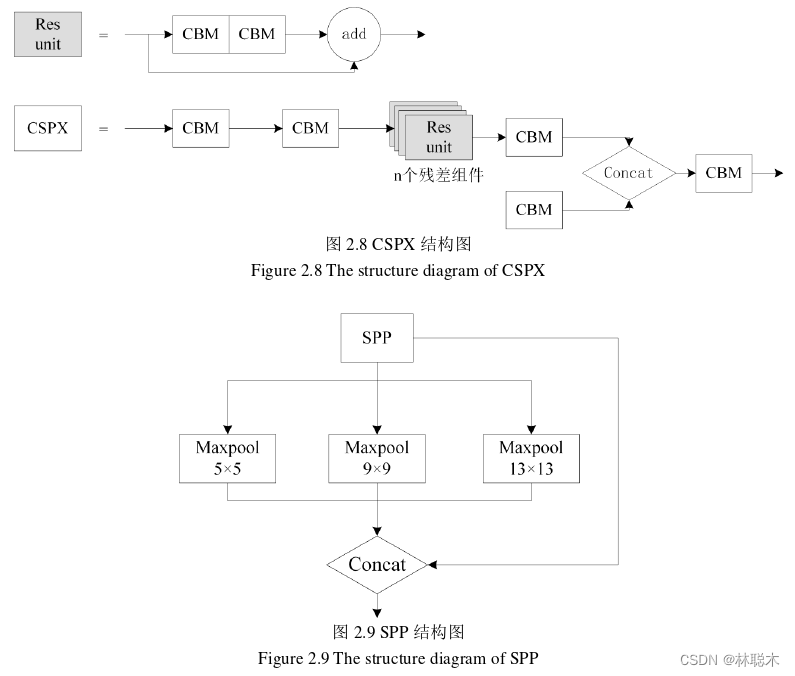 特征增强网络也称颈部网络,采用了空间金字塔池化(Space Pyramid Pool, SPP)模块, 对特征层进行四种最大池化操作,提高网络感受野,还加入改进特征金字塔PANet结构, 加入路径增强结构,增强浅层信息的使用。其中SPP结构如图2.9所示,其主要核心就是 采用固定尺寸的最大池化操作,得到固定数量的特征,主干网络输出经过四个不同尺寸的 最大池化操作,池化核分别为1×1、5×5、9×9、13×13,将得到的不同尺寸的特征图进行 拼接。该结构可以增加感受野,分离上下文信息,起到特征增强的作用。其中PANet结构 由FPN改进而来,添加了PAN新模块。PANet结构如图2.10所示,FPN是采用一系列上 采样操作,将深层次的语义信息传递到浅层网络,然后相对应的特征采用横向连接进行融 合,而PAN则是利用一系列下采样操作,将浅层次的位置信息传递给深层次的网络,再进 行相同的特征融合。PANet包含多次特征金字塔操作,将FPN和PAN两个模块相结合, 既能保证浅层信息的使用,也能保证深层语义信息的丰富,能够使得定位精度和语义信息 都得到提升,提高模型的检测能力。
特征增强网络也称颈部网络,采用了空间金字塔池化(Space Pyramid Pool, SPP)模块, 对特征层进行四种最大池化操作,提高网络感受野,还加入改进特征金字塔PANet结构, 加入路径增强结构,增强浅层信息的使用。其中SPP结构如图2.9所示,其主要核心就是 采用固定尺寸的最大池化操作,得到固定数量的特征,主干网络输出经过四个不同尺寸的 最大池化操作,池化核分别为1×1、5×5、9×9、13×13,将得到的不同尺寸的特征图进行 拼接。该结构可以增加感受野,分离上下文信息,起到特征增强的作用。其中PANet结构 由FPN改进而来,添加了PAN新模块。PANet结构如图2.10所示,FPN是采用一系列上 采样操作,将深层次的语义信息传递到浅层网络,然后相对应的特征采用横向连接进行融 合,而PAN则是利用一系列下采样操作,将浅层次的位置信息传递给深层次的网络,再进 行相同的特征融合。PANet包含多次特征金字塔操作,将FPN和PAN两个模块相结合, 既能保证浅层信息的使用,也能保证深层语义信息的丰富,能够使得定位精度和语义信息 都得到提升,提高模型的检测能力。
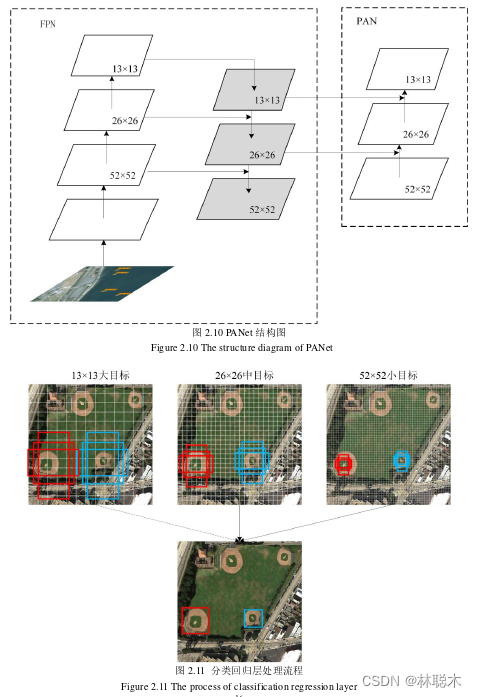 预测网络主要对预测特征层进行预测和解码,完成对不同大小的目标的检测任务,如 图2.11所示,三个特征图不同的尺寸对应三个不同的网格数,这些不同大小的网格用于检 测不同尺寸的目标。其中划分为52×52个网格,每一个网格尺寸都较小,用于检测小目标; 划分为26×26个网格,每一个网格尺寸中等,用于检测中等大小的目标;划分为13×13个 网格,每一个网格尺寸偏大,用于检测大目标。接下来以每个网格中心生成不同尺寸的先 验框,如表2.2所示。然后计算得分,使用非极大值抑制对边界框来进行筛选,得到最终 的目标位置和目标类别。
预测网络主要对预测特征层进行预测和解码,完成对不同大小的目标的检测任务,如 图2.11所示,三个特征图不同的尺寸对应三个不同的网格数,这些不同大小的网格用于检 测不同尺寸的目标。其中划分为52×52个网格,每一个网格尺寸都较小,用于检测小目标; 划分为26×26个网格,每一个网格尺寸中等,用于检测中等大小的目标;划分为13×13个 网格,每一个网格尺寸偏大,用于检测大目标。接下来以每个网格中心生成不同尺寸的先 验框,如表2.2所示。然后计算得分,使用非极大值抑制对边界框来进行筛选,得到最终 的目标位置和目标类别。
 在众多优秀技术的加持下,YOLOv4目标检测算法已经有着较高的检测速度和检测精 度,同时能有效的通过单GPU进行训练,和其他算法相比,精度相差不多的检测速度更 快,检测速度差不多的检测精度更高。
在众多优秀技术的加持下,YOLOv4目标检测算法已经有着较高的检测速度和检测精 度,同时能有效的通过单GPU进行训练,和其他算法相比,精度相差不多的检测速度更 快,检测速度差不多的检测精度更高。
2.3非极大值抑制
目标检测的任务是精确输出一个边界框,将每个目标紧密地包围起来。然而,大多数 目标检测会产生大量冗余的高度重叠的边界框,引入大量的误检框。非极大值抑制(Non- Maximum Suppression, NMS)[ 64]是抑制冗余边界框的重要步骤,用于提取置信度高的目标检 测边界框,而抑制置信度低的误检框。在基于锚框的目标检测算法中,已经训练好的模型 在用于检测时,会生成许多预测框,其数量远远超出真实目标的数量,这也就体现出了NMS 的重要性。现今NMS已经有多种变体可以提高检测精度。SoftNMS[65]采用降低要抑制的 边界框的分数,而不是直接删除这些边界框。自适应非极大值抑制算法(Adaptive Non-Maximum Suppression, ANMS)[ 66]根据目标的密度自适应设置框选择阈值,使得特征点 在局部上稀疏分布,在全局上均匀分布。可见性引导非极大值抑制[67]利用对物体整体的检测以及对可见部分的检测来解决物体高度遮挡的检测问题。FeatureNMS[68]利用特征嵌入距 离来决定是抑制还是保留边界框。MaxpoolNMS[69]将NMS重新定义,通过最大池化操作 删除冗余框,实现NMS的加速。但是MaxpoolNMS只能应用于两阶段目标检测中的第一 阶段,不能使用于单阶段目标检测的后处理阶段。
图2.12展示出NMS的作用,图像(a)被输入到算法中,得到含有很多得分不同的预测 框如图像(b),若再进行NMS于图像(b),去掉许多置信度不是极大值的边界框,每个目标 只保留置信度最高的边框作为最终的预测目标边界框,得到最后的图像(c)。
 GreedyNMS即传统的NMS算法是现今最受到广泛使用的算法,其先根据置信度分数 降序对这些锚框进行排序,消除与最终预测有较大重叠的其他框,最后从剩余的框中选出 最终的预测边界框。但是其属于贪心的思想策略使得其当被检测的目标存在遮挡的时候, 效果一般,因为目标互相遮挡导致预测框排列过于密集,不能保证每个预测框都能有最终 的预测框,出现漏检的情况。如图2.13所示,原图(a)中存在较多被遮挡的椅子,和没有被 遮挡的椅子,结果图(b)中可以清楚看出,GreedyNMS可以准确返回未被遮挡椅子的边框,但是对于有遮挡的椅子,五个尺寸相差不大的椅子只检测出了三个,后面被遮挡的因为其 预测框与旁边置信度较高的预测框重叠面积过大,虽然包含目标,但是由于低于最高值而 被剔除,导致出现漏检情况。
GreedyNMS即传统的NMS算法是现今最受到广泛使用的算法,其先根据置信度分数 降序对这些锚框进行排序,消除与最终预测有较大重叠的其他框,最后从剩余的框中选出 最终的预测边界框。但是其属于贪心的思想策略使得其当被检测的目标存在遮挡的时候, 效果一般,因为目标互相遮挡导致预测框排列过于密集,不能保证每个预测框都能有最终 的预测框,出现漏检的情况。如图2.13所示,原图(a)中存在较多被遮挡的椅子,和没有被 遮挡的椅子,结果图(b)中可以清楚看出,GreedyNMS可以准确返回未被遮挡椅子的边框,但是对于有遮挡的椅子,五个尺寸相差不大的椅子只检测出了三个,后面被遮挡的因为其 预测框与旁边置信度较高的预测框重叠面积过大,虽然包含目标,但是由于低于最高值而 被剔除,导致出现漏检情况。