- 创建feaderSpider项目:feapder create -p feapderSpider,已创建可忽略
- 进入feapderSpider目录:cd .\ feapderSpider\spiders
- 创建爬虫:feapder create -s airSpiderDouban,选择AirSpider爬虫模板,可跳过1、2直接创建爬虫文件
- 配置邮件报警:报警配置163邮箱,https://feapder.com/#/source_code/%E6%8A%A5%E8%AD%A6%E5%8F%8A%E7%9B%91%E6%8E%A7
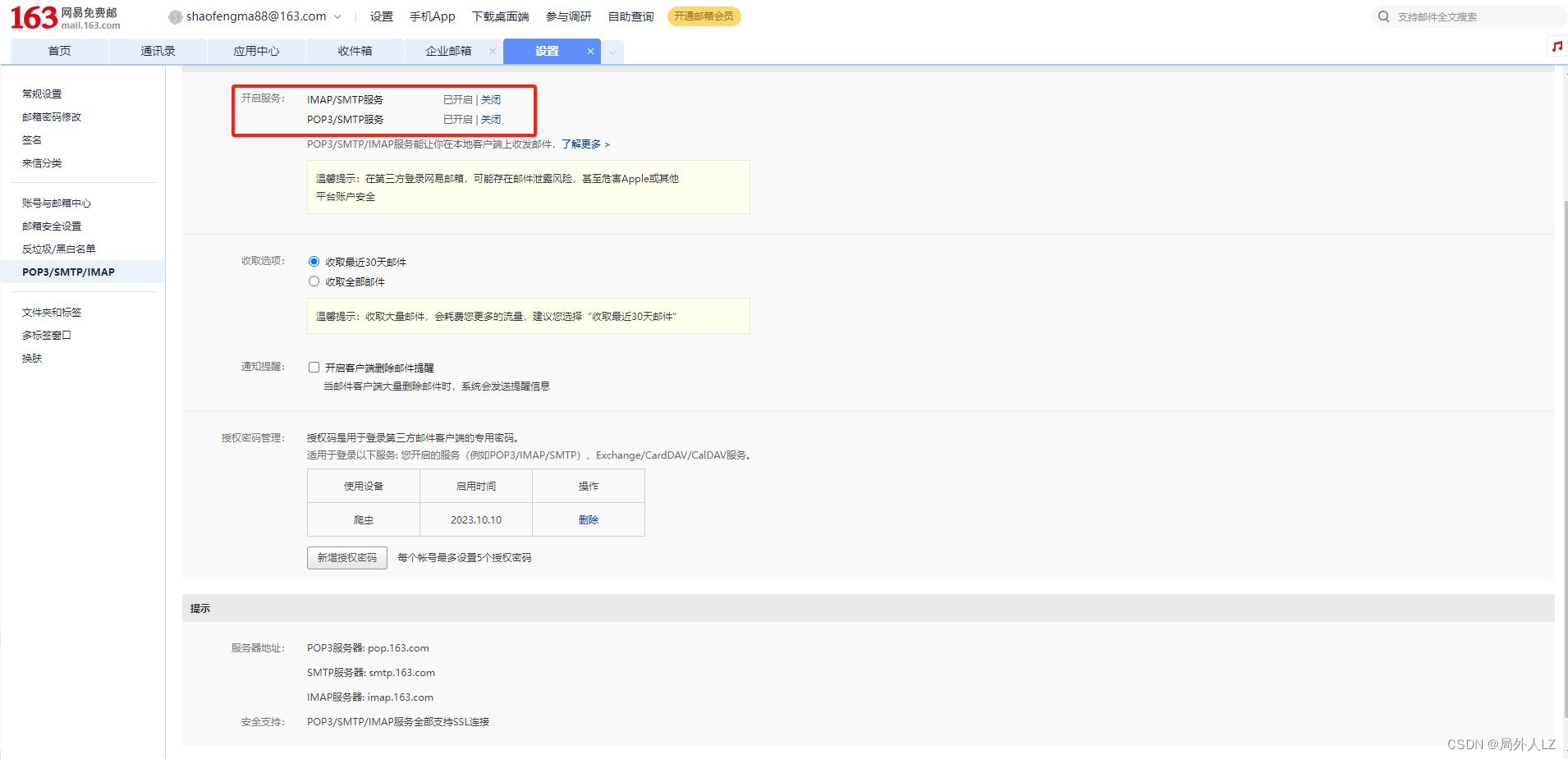
- setting.py打开mysql配置,无setting.py文件,运行命令feapder create --setting
# # MYSQL
MYSQL_IP = "localhost"
MYSQL_PORT = 3306
MYSQL_DB = "video"
MYSQL_USER_NAME = "root"
MYSQL_USER_PASS = "root"
# # REDIS
# # ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"]
REDISDB_IP_PORTS = "localhost:6379"
REDISDB_USER_PASS = ""
REDISDB_DB = 0
# 连接redis时携带的其他参数,如ssl=True
REDISDB_KWARGS = dict()
# 适用于redis哨兵模式
REDISDB_SERVICE_NAME = ""
# # 去重
ITEM_FILTER_ENABLE = True # item 去重
ITEM_FILTER_SETTING = dict(
filter_type=1, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4
name="douban"
)
# # 邮件报警
EMAIL_SENDER = "123123123@163.com" # 发件人
EMAIL_PASSWORD = "EYNXMBWJKMLZFTKQ" # 授权码
EMAIL_RECEIVER = ["123123123@163.com"] # 收件人 支持列表,可指定多个
EMAIL_SMTPSERVER = "smtp.163.com" # 邮件服务器 默认为163邮箱
- 创建item:feapder create -i douban,选择item,需要现在数据库创建表
CREATE TABLE IF NOT EXISTS douban(
id INT AUTO_INCREMENT,
title VARCHAR(255),
rating FLOAT,
quote VARCHAR(255),
intro TEXT,
PRIMARY KEY(id)
)
- 修改douban_item.py文件
# -*- coding: utf-8 -*-
"""
Created on 2023-10-08 16:17:51
---------
@summary:
---------
@author: Administrator
"""
from feapder import Item
class DoubanItem(Item):
"""
This class was generated by feapder
command: feapder create -i douban
"""
__table_name__ = "douban"
__unique_key__ = ["title","quote","rating","title"] # 指定去重的key为 title、quote,最后的指纹为title与quote值联合计算的md5
def __init__(self, *args, **kwargs):
super().__init__(**kwargs)
# self.id = None
self.intro = None
self.quote = None
self.rating = None
self.title = None
- 爬虫文件:air_spider_douban.py
# -*- coding: utf-8 -*-
"""
Created on 2023-10-06 15:36:09
---------
@summary:
---------
@author: Administrator
"""
import feapder
from items.douban_item import DoubanItem
from feapder.network.user_agent import get as get_ua
from requests.exceptions import ConnectTimeout,ProxyError
from feapder.utils.email_sender import EmailSender
import feapder.setting as setting
class AirSpiderDouban(feapder.AirSpider):
def __init__(self, thread_count=None):
super().__init__(thread_count)
self.request_url = 'https://movie.douban.com/top250'
def start_requests(self):
yield feapder.Request(self.request_url)
def download_midware(self, request):
request.headers = {
'User-Agent': get_ua()
}
return request
def parse(self, request, response):
video_list = response.xpath('//ol[@class="grid_view"]/li')
for li in video_list:
item = DoubanItem()
item['title'] = li.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()
item['rating'] = li.xpath('.//div[@class="bd"]//span[@class="rating_num"]/text()').extract_first()
item['quote'] = li.xpath('.//div[@class="bd"]//p[@class="quote"]/span/text()').extract_first()
detail_url = li.xpath('.//div[@class="hd"]/a/@href').extract_first()
if detail_url:
yield feapder.Request(detail_url, callback=self.get_detail_info, item=item)
# 获取下一页数据
next_page_url = response.xpath('//div[@class="paginator"]//link[@rel="next"]/@href').extract_first()
if next_page_url:
yield feapder.Request(next_page_url,callback=self.parse)
def get_detail_info(self, request, response):
item = request.item
detail = response.xpath('//span[@class="all hidden"]/text()').extract_first() or ''
if not detail:
detail = response.xpath('//div[@id="link-report-intra"]/span[1]/text()').extract_first() or ''
item['intro'] = detail.strip()
yield item
def exception_request(self, request, response, e):
prox_err = [ConnectTimeout,ProxyError]
if type(e) in prox_err:
request.del_proxy()
def end_callback(self):
with EmailSender(setting.EMAIL_SENDER,setting.EMAIL_PASSWORD) as email_sender:
email_sender.send(setting.EMAIL_RECEIVER, title='python',content="爬虫结束")
if __name__ == "__main__":
AirSpiderDouban(thread_count=5).start()
- feapder create -p feapderSpider根据该命令创建的项目下会有main文件,除了单独运行爬虫文件,可以在main文件中运行,一般用于运行多个爬虫
from feapder import ArgumentParser
from spiders import *
def crawl_air_spider_douban():
"""
AirSpider爬虫
"""
spider = air_spider_douban.AirSpiderDouban()
spider.start()
if __name__ == "__main__":
parser = ArgumentParser(description="爬虫练习")
parser.add_argument(
"--crawl_air_spider_douban", action="store_true", help="豆瓣AirSpide", function=crawl_air_spider_douban
)
parser.run("crawl_air_spider_douban")