【SPSS】基于RFM+Kmeans聚类的客户分群分析(文末送书)

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.项目简介
2.1分析目标
2.2数据说明
2.3技术工具
3.算法理论
3.1聚类
3.2 RFM模型
4.实验过程
4.1数据探索
4.2构建RFM模型
4.3聚类分群
5.总结
文末推荐与福利
1.项目背景
随着行业竞争越来越激烈,商家将更多的运营思路转向客户。例如,购物时,常常被商家推荐扫码注册会员;各种电商平台也推出注册会员领优惠券等推销政策,而这些做法都是为了积累客户,以便对客户进行分析。
那么,在商家积累的大量的客户交易数据中,如何根据客户历史消费记录分析不同客户群体的特征和价值呢?例如,了解哪些是重要保持客户、哪些是发展客户、哪些是潜在客户,从而针对不同客户群体定制不同的营销策略,实现精准营销、降低营销成本,提高销售业绩,使企业利润最大化。例如,淘宝电商客户繁多,消费行为复杂,客户价值很难人工评估,并对客户进行分类,这就霸要通过科学的分析方法评估客户价值,实现智能客户分类,快速定位客户、当然,也要清醒地认识到,即便是预测的客户价值较高,也只能说明其购买潜力较高,同时必须结合实际与客户互动,推动客户追加购买、交叉购买才是电商努力的方向。
2.项目简介
2.1分析目标
随着行业竞争越来越激烈,商家将更多的运营思路转向客户,客户是企业生存的关键,能够把握住客户就能够掌控企业的未来。客户的需求是客户消费的最直接原因,因此我们主要研究以下问题:
1)企业如何细分客户;
2)哪些是重要的保持客户 ;
3)哪些是发展客户;
4)哪些是潜在客户。
从而针对不同客户群体定制不同的营销策略,使企业利润最大化。
2.2数据说明
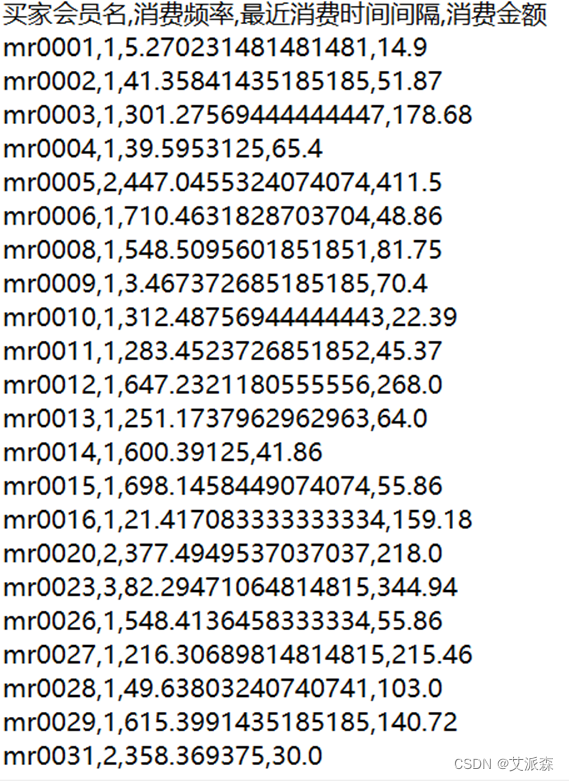
实验使用从网络获取的客户数据集进行分析,数据集中共有2417行,4列数据。我们的目标就是细分客户,从而针对不同客户群体定制不同的营销策略,使企业利润最大化。
2.3技术工具
本次实验主要使用SPSS软件实现KMeans聚类算法和RFM模型。
3.算法理论
3.1聚类
聚类,即将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。在数据挖掘中,聚类也是很重要的一个概念。传统的聚类分析计算方法主要有划分方法、层次方法、基于密度的方法、基于网格的方法、基于模型的方法五种。
3.2 RFM模型
R:最近消费时间间隔,表示客户最近一次消费时间与之前消费时间的距离。
R越大,表示客户越久未发生交易,R越小,表示客户最近有交易发生。R越大,则客户越可能会“沉睡”,流失的可能性越大。在这部分客户中,可能有些优质客户,值得通过一些营销手段进行激活。
F:消费频率,表示一段时间内的客户消费次数。F越大,则表示客户交易越频繁,是非常忠诚的客户,也是对公司的产品认同度较高的客户;F越小,则表示客户不够活跃,且可能是竞争对手的常客。针对F较小、且消费额较大的客户,需要推出一定的竞争策略,将这批客户从竞争对手中争取过来。
M:消费金额,表示客户每次消费金额,可以用最近-次消费金额,也可以用过去的平均消费金额,根据分析的目的不同,可以有不同的标识方法。
一般来讲,单次交易金额较大的客户,支付能力强,价格敏感度低,帕累托法则告诉我们,一个公司80%的收入都是由消费最多的20%客户贡献的,所以消费金额大的客户是较为优质的客户,也是高价值客户,这类客户可采取一对一的营销方案。
4.实验过程
4.1数据探索
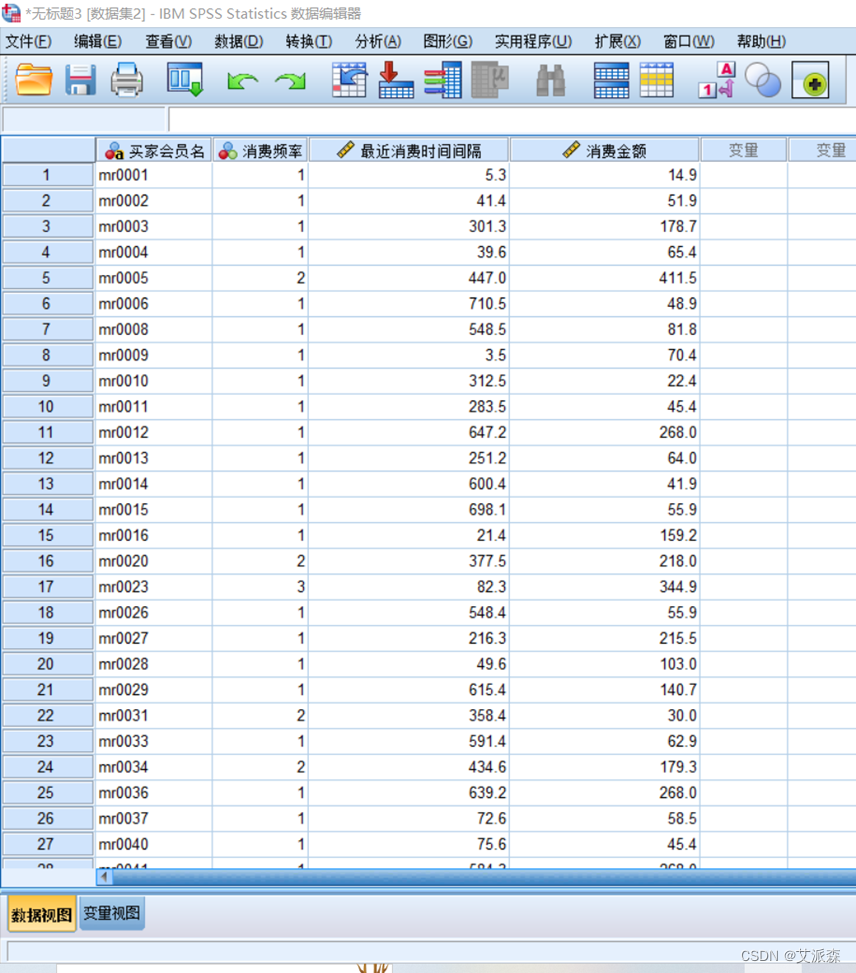
首先导入数据
做出数据描述性统计

从数据描述性统计分析中我们可以看出各个变量的个案总计、最大最小值、均值、标准差、方差、偏度、峰度等信息。
做出各数值变量的直方图进行分析
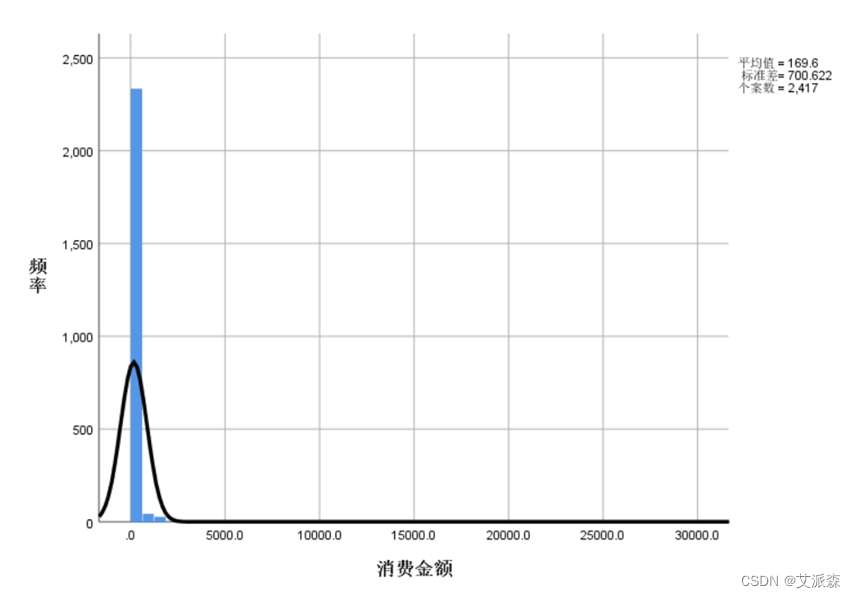
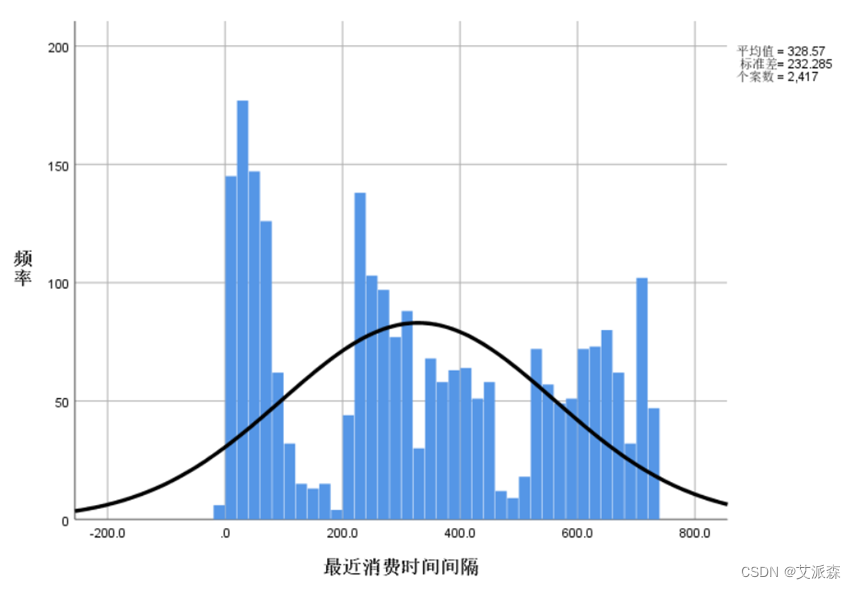

对各变量进行相关性分析
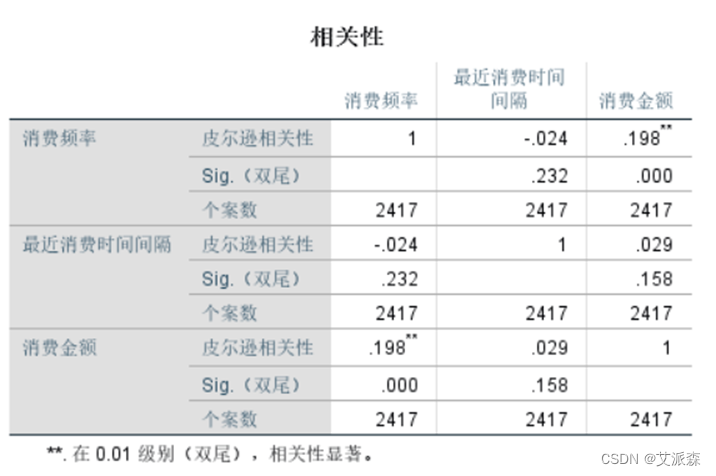
从相关性结果看出,消费频率和最近消费时间间隔的相关系数较小,从P值看出,消费频率和最近消费时间间隔相关性不显著;消费频率和消费金额呈正相关,从P值看出,消费频率和消费金额相关性很显著。
4.2构建RFM模型
由于我们的原始数据已经符合RFM模型的要求,所以我们将变量名进行更改
由于RFM这三个变量的数值分布过于大,所以需要进行标准化处理
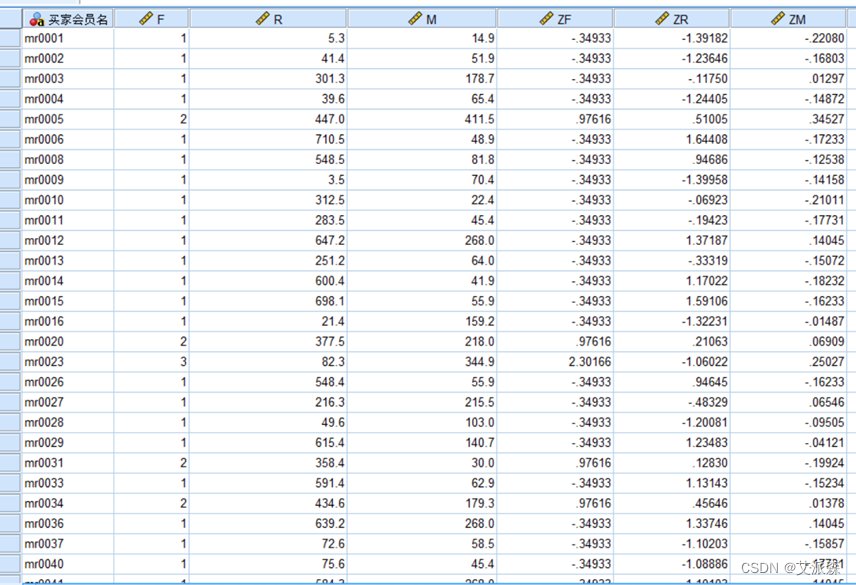
4.3聚类分群
使用SPSS进行K-均值聚类
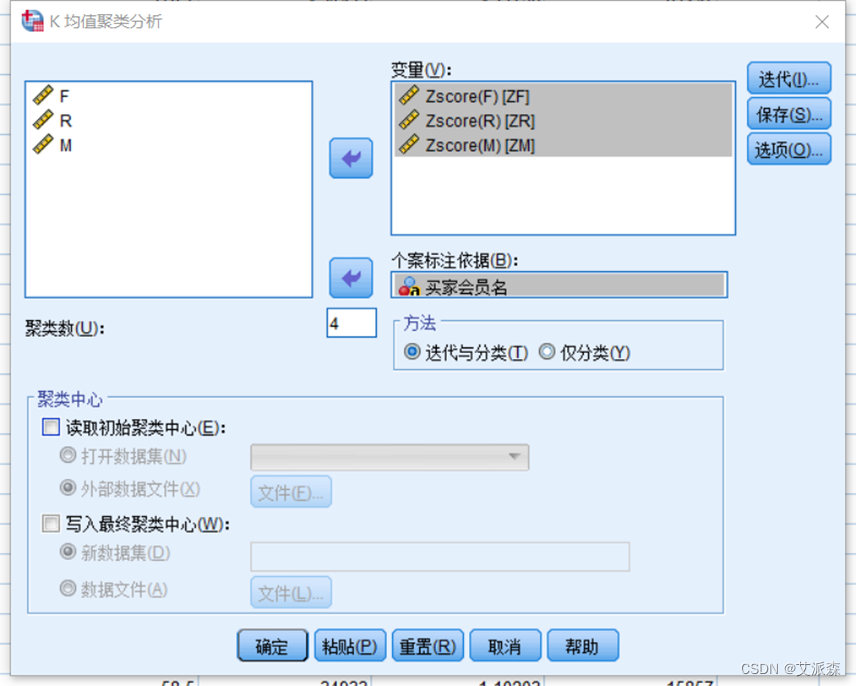

从结果中,我们可以看出各个变量的聚类中心。
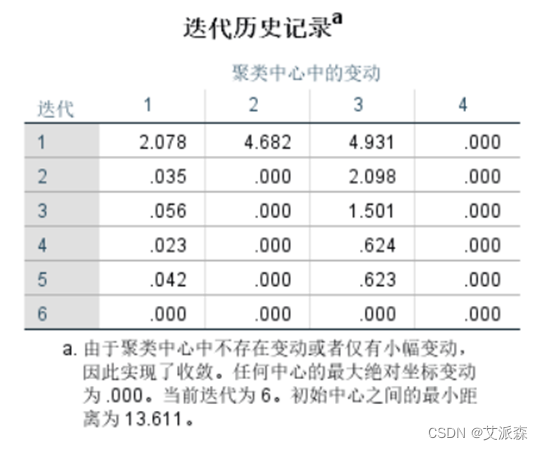
从结果中可看出各每一次的迭代记录。
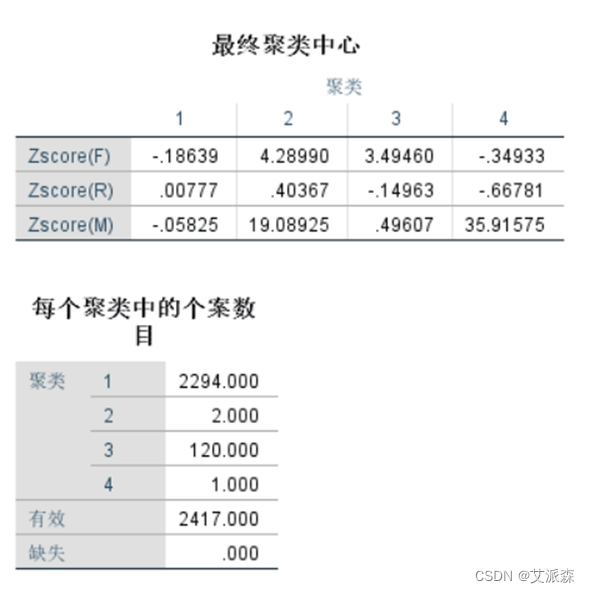
从结果中可看出最终的聚类中心以及每个聚类类别的个数。
5.总结
最后我们将客户群按价值高低进行分类和排名,客户群1是潜在客户;客户群3是一般发展客户,客户群2是一般保持客户,客户群4是重要保持客户。
| R | F | M | 聚类类别 | 客户类别 | 客户数 | 排名 |
| 低 | 低 | 低 | 1 | 潜在客户 | 2294 | 4 |
| 高 | 低 | 低 | 3 | 一般发展客户 | 120 | 3 |
| 低 | 高 | 低 | 2 | 一般保持客户 | 2 | 2 |
| 高 | 高 | 高 | 4 | 重要保持客户 | 1 | 1 |
根据以上分析,得到客户分类的依据:
(1)重要保持客户:F、M高,R略高于平均分。他们是淘宝电商的高价值客户,是最为理想型的客户类型,他们对企业品牌认可,对产品认可,贡献值最大,所占比例却非常小。这类客户花钱多又经常来,但是最近没来,这表示他们是一段时间没来的忠实客户。淘宝电商可以将这类客户作为VIP客户进行一对一营销,以提高这类客户的忠诚度和满意度,尽可能延长这类客户的高水平消费。
(2)一般保持客户: F高,这类客户消费次数多,是忠实的客户。针对这类客户应多传递促销活动、品牌信息、新品或活动信息等。
(3)潜在客户: R、F和M低,这类客户短时间内在店铺消费过,消费次数和消费金额较少,是潜在客户。虽然这类客户的当前价值并不是很高,但却有很大的发展潜力。针对这类客户应进行密集的营销信息推送,增加其在店铺的消费次数和消费金额。
(4)一般发展客户:低价值客户,R高,F、M低,说明这类客户很长时间没有在店铺进行交易了,而且消费次数和消费金额也较少。这类客户可能只会在店铺打折促销活动时才会消费,要想办法推动客户的消费心理,否则会有流失的危险。
文末推荐与福利
《MATLAB科学计算从入门到精通》免费包邮送出3本!

内容简介:
本书从 MATLAB 基础语法讲起,介绍了基于 MATLAB 函数的科学计算问题求解方法,实现了大量科学计算算法。
本书分为三大部分。第 1 章和第 2 章为 MATLAB 的基础知识,对全书用到的 MATLAB 基础进行了简单介绍。第 3 ~ 12 章为本书的核心部分,包括线性方程组求解、非线性方程求解、数值优化、数据插值、数据拟合与回归分析、数值积分、常微分方程求解、偏微分方程求解、概率统计计算及图像处理与信号处理等内容。第 13 ~ 15 章为实战部分,以实际生活中的数学问题为例,将前文介绍的各类科学计算算法应用其中。
本书内容全面、通俗易懂,适合有一定 MATLAB 基础、想要进行进阶学习的读者。
编辑推荐:
从代码到函数,掌握多种经典算法
跨越多个领域,精通各类科学计算
多种应用实例,高效解决实际问题
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-11-1 20:00:00
京东购买链接:https://item.jd.com/14098836.html
名单公布时间:2023-11-1 21:00:00