来自论文:Language Models are Few-Shot Learners
Arxiv:https://arxiv.org/abs/2005.14165v2
记录下一些概念等。,没有太多细节。
预训练LM尽管任务无关,但是要达到好的效果仍然需要在特定数据集或任务上微调。因此需要消除这个限制。解决这些问题的一个潜在途径是元学习——在语言模型的背景下,这意味着该模型在训练时发展了一系列广泛的技能和模式识别能力,然后在推理时使用这些能力来快速适应或识别所需的任务(如图1.1所示)
“in-context learning”:

关于“zero-shot”, “one-shot”, or “few-shot”的解释:

随着模型增大,in-context learning效果越好:
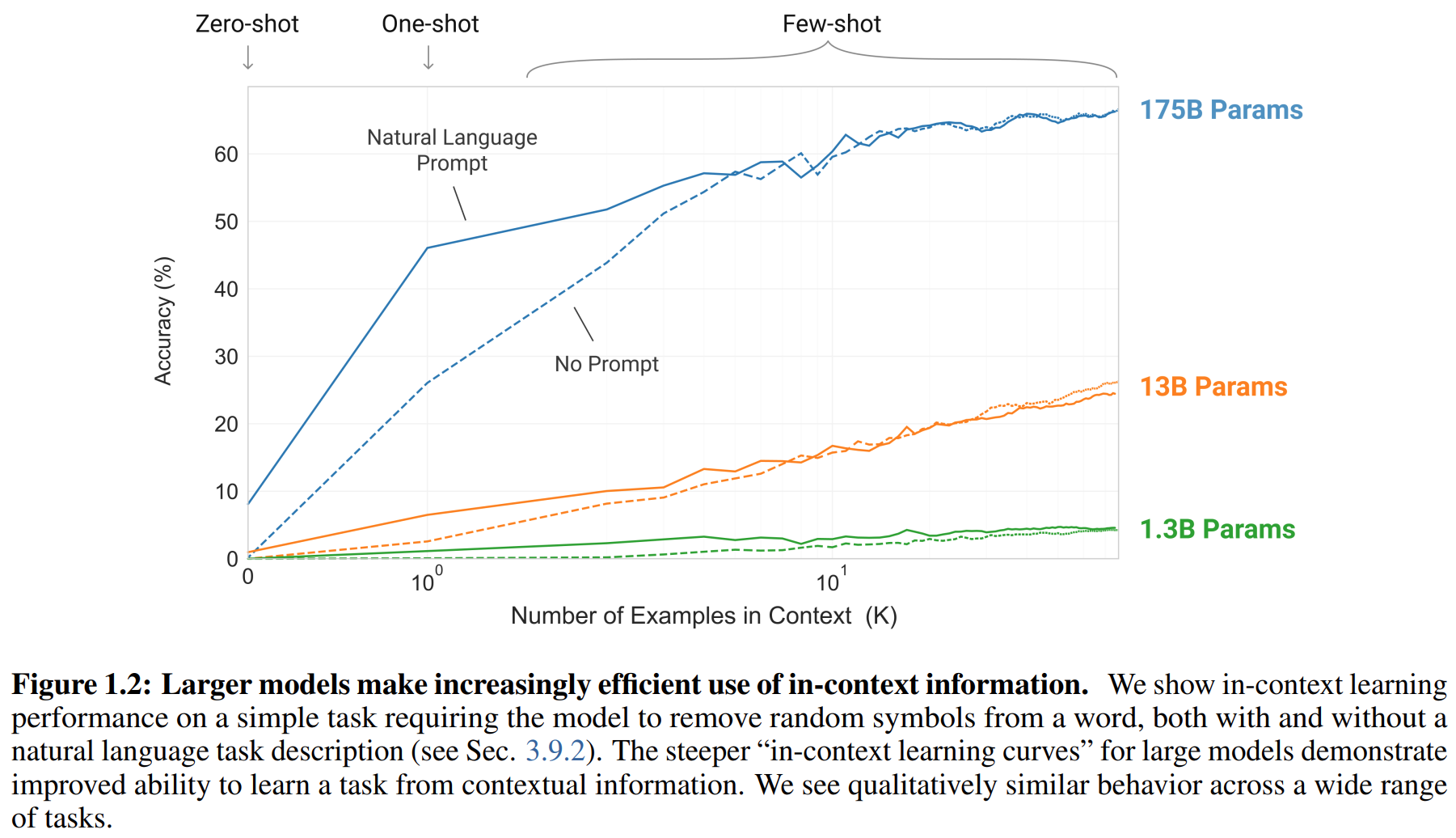
关于“zero-shot”, “one-shot”, or “few-shot”

模型结构和GPT2一样,但是改了初始化、预归一化、reversible tokenization,以及在transformers层中使用类似Sparse Transformer的交替密集和局部稀疏的注意力模式。
内容窗口大小=2048 tokens
训练了8个不同大小的模型:
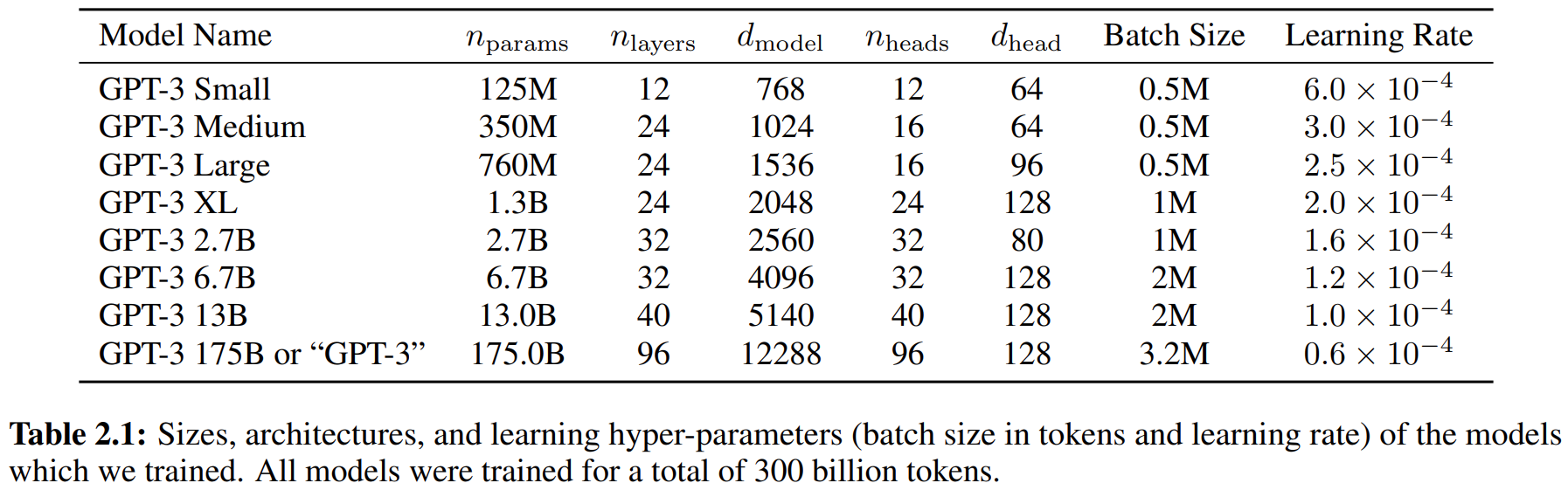
其他细节:
训练大模型需要大batch,小学习率。
few-shot learning中,实例样本数量k取值可以从0到最大窗口大小,一般可以设为10-100。