Azure云工作站上做Machine Learning模型开发 - 全流程演示
目录
- 本文内容
- 先决条件
- 从“笔记本”开始
- 设置用于原型制作的新环境(可选)
- 创建笔记本
- 开发训练脚本
- 迭代
- 检查结果
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

本文内容
了解如何在 Azure 机器学习云工作站上使用笔记本开发训练脚本。 本教程涵盖入门所需的基础知识:
- 设置和配置云工作站。 云工作站由 Azure 机器学习计算实例提供支持,该实例预配置了环境以支持各种模型开发需求。
- 使用基于云的开发环境。
- 使用 MLflow 跟踪模型指标,所有都是在笔记本中完成的。
先决条件
若要使用 Azure 机器学习,你首先需要一个工作区。 如果没有工作区,请完成“创建开始使用所需的资源”以创建工作区并详细了解如何使用它。
从“笔记本”开始
工作区中的“笔记本”部分是开始了解 Azure 机器学习及其功能的好地方。 在这里,可以连接到计算资源、使用终端,以及编辑和运行 Jupyter Notebook 和脚本。
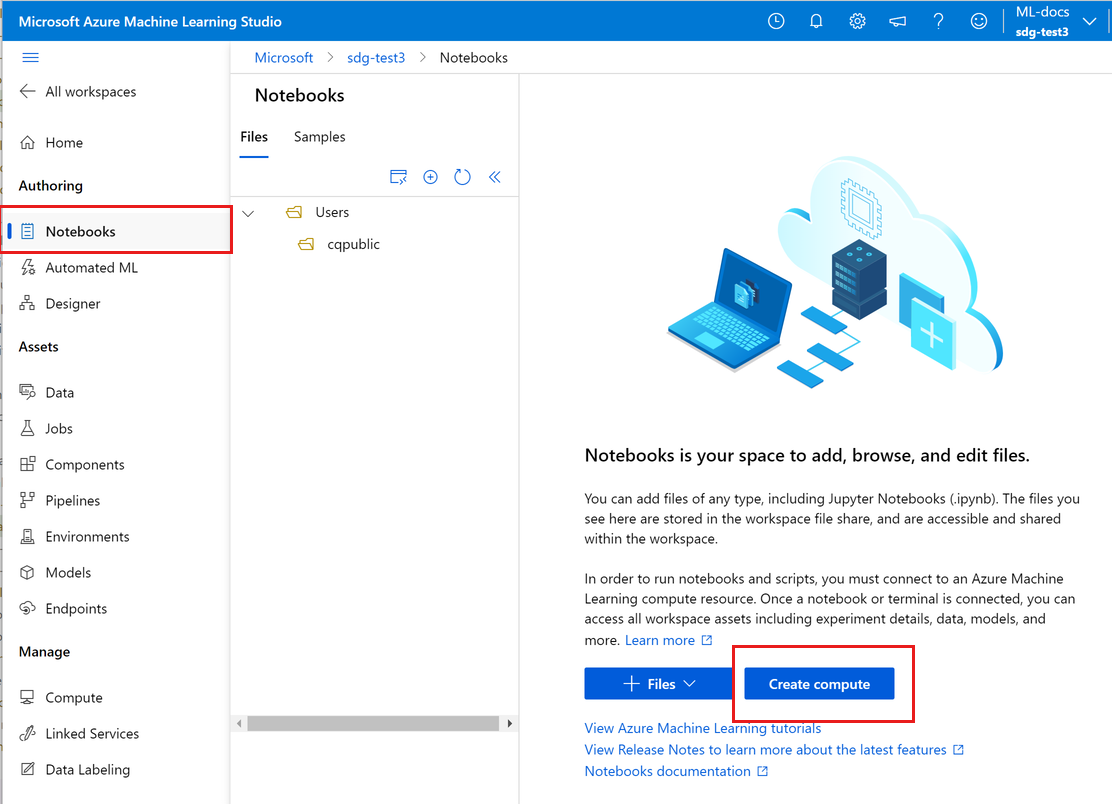
- 登录到 Azure 机器学习工作室。
- 选择你的工作区(如果它尚未打开)。
- 在左侧导航中,选择“笔记本”。
- 如果没有计算实例,屏幕中间会显示“创建计算”。 选择“创建计算”并填写表单。 可以使用所有默认值。 (如果已有计算实例,则会在该位置看到“终端”。本教程稍后会使用“终端”。)
设置用于原型制作的新环境(可选)
为使脚本运行,需要在配置了代码所需的依赖项和库的环境中工作。 本部分可帮助你创建适合代码的环境。 若要创建笔记本连接到的新 Jupyter 内核,请使用定义依赖项的 YAML 文件。
- 上传文件
上传的文件存储在 Azure 文件共享中,这些文件将装载到每个计算实例并在工作区中共享。
1. 使用右上角的 下载原始文件 按钮,将此 conda 环境文件 [workstation_env.yml](github.com) 下载到计算机。
1. 选择“添加文件”,然后选择“上传文件”,将其上传到工作区。
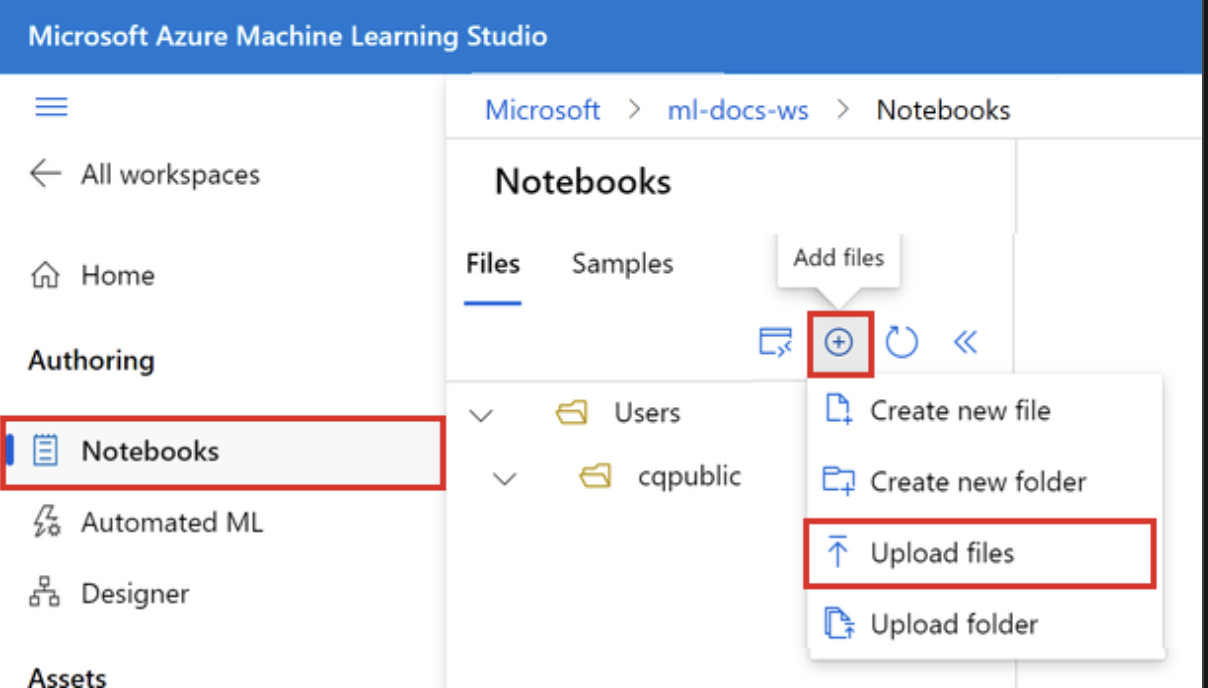
2. 选择“浏览并选择文件”。
3. 选择下载的 workstation_env.yml 文件。
4. 选择“上传”。
你将在“文件”选项卡的用户名文件夹下看到 workstation_env.yml 文件。请选择此文件以预览它,并查看它指定的依赖项。 你将看到如下所示的内容:
name: workstation_env
dependencies:
- python=3.8
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- mlflow==2.4.1
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- ipykernel~=6.0
- matplotlib
- 创建内核
现在,使用 Azure 机器学习终端基于 workstation_env.yml 文件创建新的 Jupyter 内核。
1. 选择“终端”以打开终端窗口。 还可以从左侧命令栏打开终端:
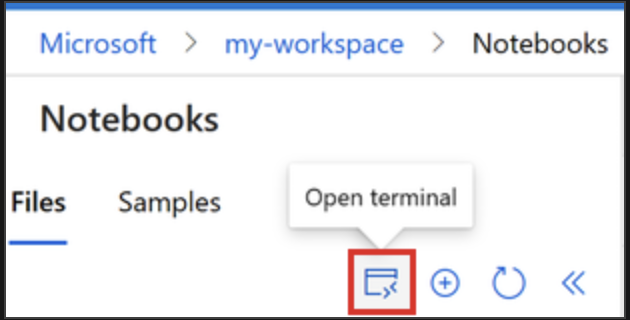
2. 如果计算实例已停止,请选择“启动计算”,并等待它运行。

3. 计算运行后,终端中会显示一条欢迎消息,可以开始键入命令。
4. 查看当前的 conda 环境。 活动环境标有 *。
conda env list
5. 如果为本教程创建了子文件夹,请立即运行 `cd` 转到该文件夹。
6. 根据提供的 conda 文件创建环境。 构建此环境需要几分钟时间。
conda env create -f workstation_env.yml
7. 激活新环境。
conda activate workstation_env
8. 验证正确的环境是否处于活动状态,再次查找标有 * 的环境。
conda env list
9. 基于活动环境创建新的 Jupyter 内核。
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"
10. 关闭终端窗口。
创建笔记本
-
选择“添加文件”,然后选择“创建新文件”。
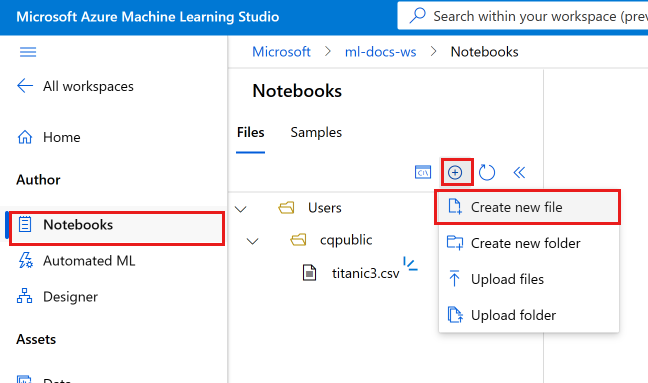
-
将新笔记本命名为 develop-tutorial.ipynb(或输入首选名称)。
-
如果计算实例已停止,请选择“启动计算”,并等待它运行。

-
你将在右上角看到笔记本已连接到默认内核。 如果创建了内核,请切换到使用 Tutorial Workstation Env 内核。
开发训练脚本
在本部分中,你将使用 UCI 数据集中准备好的测试和训练数据集开发一个 Python 训练脚本,用于预测信用卡默认付款。
此代码使用 sklearn 进行训练,使用 MLflow 来记录指标。
-
从可导入将在训练脚本中使用的包和库的代码开始。
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split -
接下来,加载并处理此试验的数据。 在本教程中,将从 Internet 上的一个文件读取数据。
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, ) -
准备好数据进行训练:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.values -
添加代码以使用
MLflow开始自动记录,以便可以跟踪指标和结果。MLflow具有模型开发的迭代性质,可帮助你记录模型参数和结果。 请回顾这些运行,比较并了解模型的性能。 这些日志还为你准备好从 Azure 机器学习中工作流的开发阶段转到训练阶段提供上下文。# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog() -
训练模型。
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()
注意
可以忽略 mlflow 警告。 你仍将获得需要跟踪的所有结果。
迭代
现在你已经有了模型结果,可能需要更改某些内容,然后重试。 例如,请尝试其他分类器技术:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()
注意
可以忽略 mlflow 警告。 你仍将获得需要跟踪的所有结果。
检查结果
现在,你已尝试两个不同的模型,请使用 MLflow 跟踪的结果来确定哪个模型更好。 可以引用准确性等指标,或者引用对方案最重要的其他指标。 可以通过查看 MLflow 创建的作业来更详细地了解这些结果。
-
在左侧导航栏中,选择“作业”。
-
选择“在云上开发教程”的链接。
-
显示了两个不同的作业,每个已尝试的模型对应一个。 这些名称是自动生成的。 将鼠标悬停在某个名称上时,如果要重命名该名称,请使用名称旁边的铅笔工具。
-
选择第一个作业的链接。 名称显示在顶部。 还可以在此处使用铅笔工具重命名它。
-
该页显示作业的详细信息,例如属性、输出、标记和参数。 在“标记”下,你将看到 estimator_name,其描述模型的类型。
-
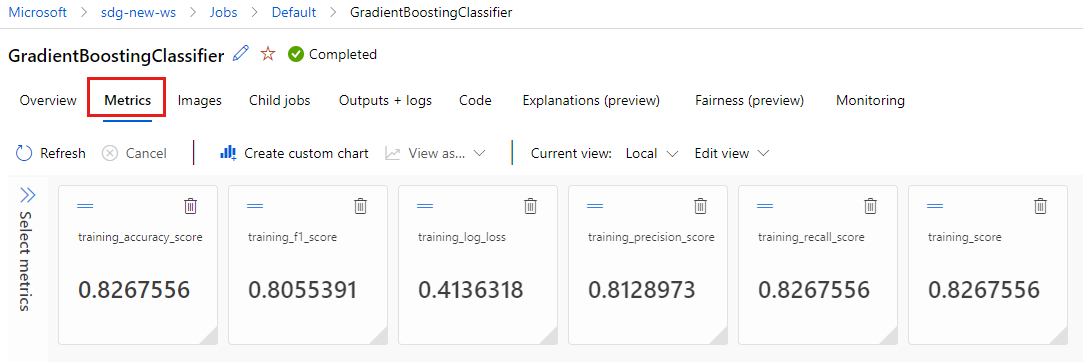
选择“指标”选项卡以查看
MLflow记录的指标。 (预期结果会有所不同,因为训练集不同。)
-
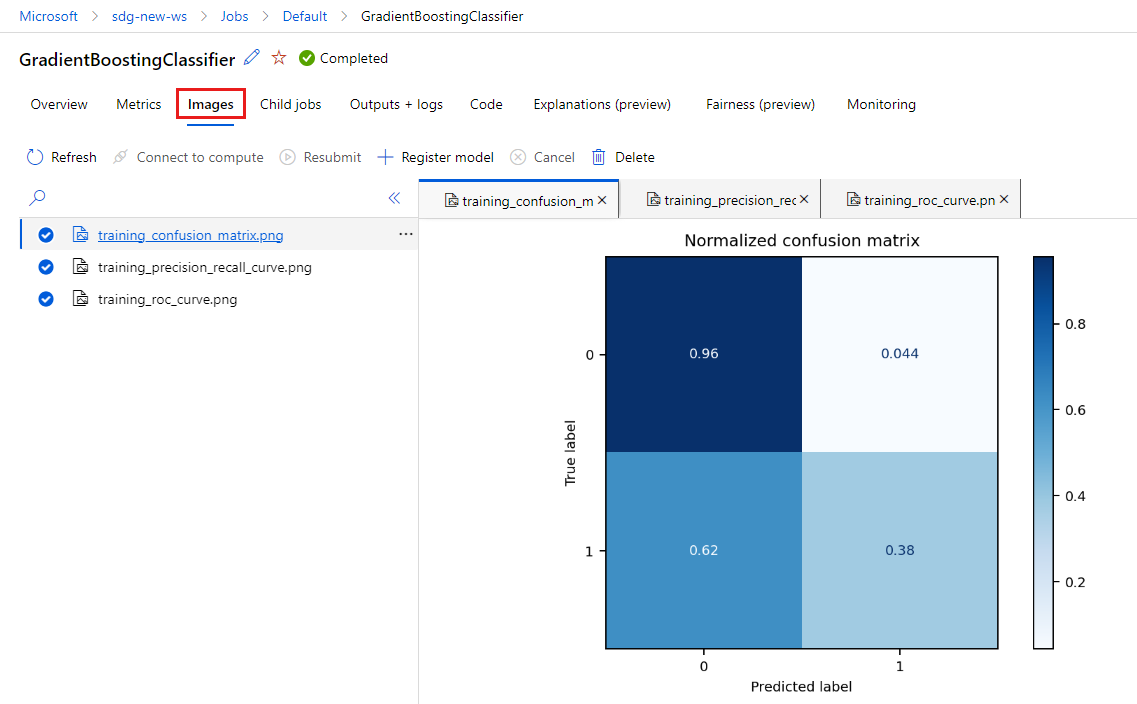
选择“图像”选项卡以查看
MLflow生成的图像。
-
返回并查看其他模型的指标和图像。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。