【CSS 知识总结】第二篇 - HTML 扩展简介
一,前言
上一篇,简单介绍了 html 标签和使用语义化的好处;
本篇,继续介绍 HTML 的文档声明、meta 元信息、HTML Entity 字符实体等 HTML 扩展内容;
二,DOCTYPE 文档声明
1,文档声明简介
- 文档声明能够帮助浏览器正确地显示网页;
- 文档声明不区分大小写,一定不能省略,否则将会发生怪异事件;
- 由于浏览器从上到下进行解析,所以文档声明必须放在文档的第一行;
- 通过文档声明指定文档类型 HTML 版本,浏览器识别到将按照对应类型对文档进行解析;
- 文档声明的高版本会兼容低版本,在工作中默认指定高版本即可(即 html5 文档声明);
- 文档声明 VsCode 快捷键:! + shift
2,文档声明的类型
HTML5
<!DOCTYPE html>
HTML 4.01
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
XHTML 1.0
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
二,meta 元信息
- meta 标签,提供关于 HTML 文档的元数据;
- meta 元信息不会显示在页面上,但是对于机器是可读的;
- meta 元信息可用于浏览器(如何显示内容或重新加载页面),搜索引擎(关键词),或其他 web 服务;
<!-- 声明编码 -->
<meta charset="UTF-8" />
<!-- 页面关键词 -->
<meta name="keywords" content="" />
<!-- 页面描述 -->
<meta name="description" content=" " />
<!-- 移动设备视口 -->
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- 搜索引擎索引方式 -->
all:文件将被检索,且页面上的链接可以被查询;
none:文件将不被检索,且页面上的链接不可以被查询;
index:文件将被检索;
follow:页面上的链接可以被查询;
noindex:文件将不被检索;
nofollow:页面上的链接不可以被查询。
<meta name="robots" content="index,follow" />
<!-- 网页的作者 -->
<meta name="author" content="author name" />
<!-- 优先使用 IE 最新版本和 Chrome -->
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" />
// 关于 X-UA-Compatible
<meta http-equiv="X-UA-Compatible" content="IE=6" ><!-- 使用IE6 -->
<meta http-equiv="X-UA-Compatible" content="IE=7" ><!-- 使用IE7 -->
<meta http-equiv="X-UA-Compatible" content="IE=8" ><!-- 使用IE8 -->
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" ><!-- 优先使用IE最新版本和Chrome -->
<!-- 页面重定向和刷新 -->
<meta http-equiv="refresh" content="0;url=" />
<!-- 禁止浏览器从本地缓存访问页面内容(无法脱机浏览) -->
<meta http-equiv="Pragma" content="no-cache">
<!-- 转码声明:避免网站的自动转码 -->
<meta http-equiv="Cache-Control" content="no-siteapp" />
<!-- 启用 WebApp 全屏模式 -->
<meta name="apple-mobile-web-app-capable" content="yes" />
<!-- 隐藏状态栏/设置状态栏颜色(开启 WebApp 全屏模式下才会生效) -->
<!-- content的值为 default | black | black-translucent -->
<meta name="apple-mobile-web-app-status-bar-style" content="black-translucent" />
<!-- 添加到主屏后的标题 -->
<meta name="apple-mobile-web-app-title" content="标题">
<!-- 忽略数字自动识别为电话号码 -->
<meta content="telephone=no" name="format-detection" />
<!-- 忽略识别邮箱 -->
<meta content="email=no" name="format-detection" />
<!-- 添加智能 App 广告条 Smart App Banner -->
<meta name="apple-itunes-app" content="app-id=myAppStoreID,
affiliate-data=myAffiliateData, app-argument=myURL">
<!-- 手持设备优化(不识别 viewport 的浏览器,如黑莓) -->
<meta name="HandheldFriendly" content="true">
<!-- 微软的老式浏览器 -->
<meta name="MobileOptimized" content="320">
<!-- uc 强制竖屏 -->
<meta name="screen-orientation" content="portrait">
<!-- QQ 强制竖屏 -->
<meta name="x5-orientation" content="portrait">
<!-- UC 强制全屏 -->
<meta name="full-screen" content="yes">
<!-- QQ 强制全屏 -->
<meta name="x5-fullscreen" content="true">
<!-- UC 应用模式 -->
<meta name="browsermode" content="application">
<!-- QQ 应用模式 -->
<meta name="x5-page-mode" content="app">
<!-- windows phone 点击无高光 -->
<meta name="msapplication-tap-highlight" content="no">
<!-- 浏览器内核控制 -->
<meta name="renderer" content="webkit|ie-comp|ie-stand">
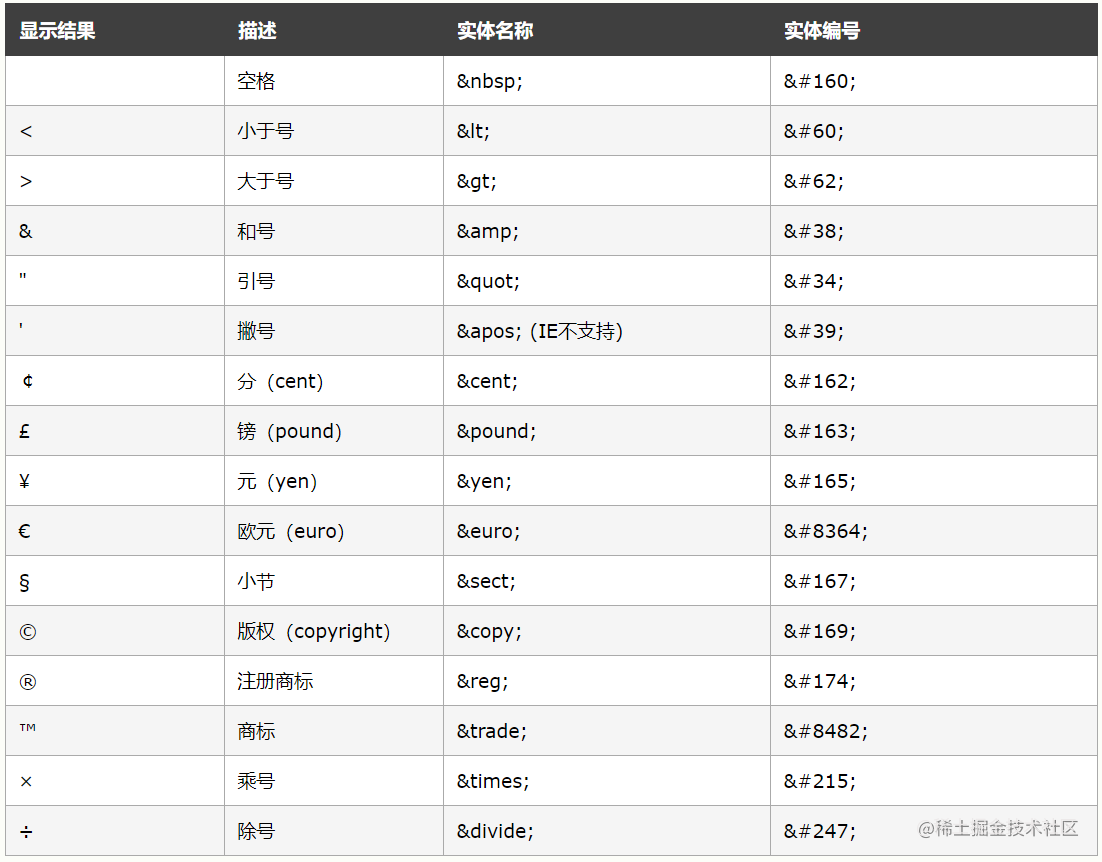
三,HTML Entity 字符实体
1,什么是字符实体
编写 html 时,如果需要用到 “<”、“>”、“空格” 等符号,浏览器默认会将他们与标签混合处理;
为了能够输出这些符号,就需要进行转义操作:
- 在 HTML 中,这些字符被称为 HTML Entity,即 HTML 字符实体;
- 一个 HTML Entity 包含 2 种转义格式:Entity Name 和 Entity Number;
2,字符实体的作用
- 用于显示 HTML 的保留字符,如 <、>、&、 " 等;
- 用于表示难以在常规输入设备下完成输入的字符,如 ©、®、± 等;
- 给定的字符编码无法表达文档字符集的其他字符,如 ASCII 编码;
3,Entity Name 实体名称
- 格式: &entityName;
- 说明:以 “&” 开头,“;” 结尾,以语义的形式描述字符;
字符"<“,英文"less than”,取2个单词的首字母 <;
4,Entity Number 实体数字
- 格式: &#entityNumber;
- 说明:以 “&#” 开头,“;” 结尾,以编号的形式描述字符;
这个编号可以是十进制、十六进制等,以 “&#x” 开头的数字格式
5,实体名称、实体编号对照表
四,结尾
本篇,主要介绍 HTML 的文档声明、meta 元信息、HTML Entity 字符实体等 HTML 扩展内容;
下一篇,第三篇 - CSS 选择器的权重和优先级;