决策树算法介绍
决策树目录
- 1. 决策树基础
- 1.1 决策树定义
- 1.2 熵以及信息熵介绍
- 2. 决策树的划分依据
- 2.1 信息增益
- 2.1.1信息增益应用举例
- 2.2 信息增益率
- 2.2.1 信息增益率使用举例
- 2.2.2 信息增益率使用举例2
- 2.3 基尼值和基尼指数
- 2.3.1 基尼值和基尼指数介绍
- 2.3.2 基尼值和基尼指数实现案例
1. 决策树基础
1.1 决策树定义
决策树思想的来源⾮常朴素,程序设计中的条件分⽀结构就是if-else结构,最早的决策树就是利⽤这类结构分割数据的⼀种分类学习⽅法
决策树是什么?
是⼀种树形结构,本质是⼀颗由多个判断节点组成的树
其中每个内部节点表示⼀个属性上的判断,
每个分⽀代表⼀个判断结果的输出,
最后每个叶节点代表⼀种分类结果
简单的决策树图形示例:
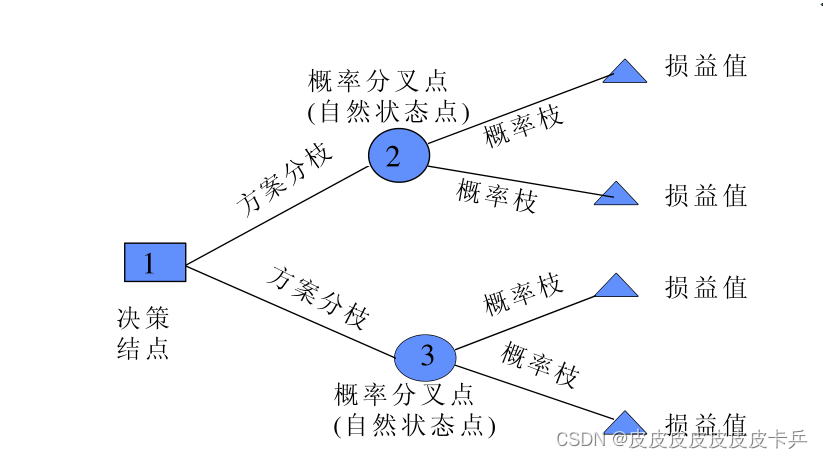
总之,决策树是⼀种树形结构,本质是⼀颗由多个判断节点组成的树
1.2 熵以及信息熵介绍
决策树是根据信息增益以及信息增益率等来进行划分的,由信息增益计算出对当前决策影响较大的特征,在进行特征选择或者数据分析中作为重点考察对象,所以在这里详细介绍一下信息熵。
熵的概念:物理学上,熵 Entropy 是“混乱”程度的量度。系统越有序,熵值越低;系统越混乱或者分散,熵值越⾼。“信息熵” (information entropy)是度量样本集合纯度最常⽤的⼀种指标。
- 信息熵
- 从信息的完整性上进⾏的描述
- 当系统的有序状态⼀致时,数据越集中的地⽅熵值越⼩,数据越分散的地⽅熵值越⼤。
- 从信息的有序性上进⾏的描述
- 当数据量⼀致时,系统越有序,熵值越低;系统越混乱或者分散,熵值越⾼。
- 从信息的完整性上进⾏的描述
信息熵的计算:

2. 决策树的划分依据
2.1 信息增益
概念:
信息增益:以某特征划分数据集前后的熵的差值。熵可以表示样本集合的不确定性,熵越⼤,样本的不确定性就越⼤。因此可以使⽤划分前后集合熵的差值来衡量使⽤当前特征对于样本集合D划分效果的好坏。
定义与公式:

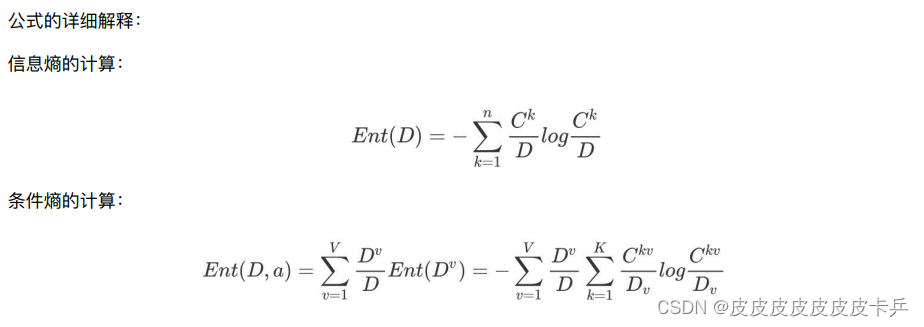

2.1.1信息增益应用举例
如下图,第⼀列为论坛号码,第⼆列为性别,第三列为活跃度,最后⼀列⽤户是否流失。
我们要解决⼀个问题:性别和活跃度两个特征,哪个对⽤户流失影响更⼤?
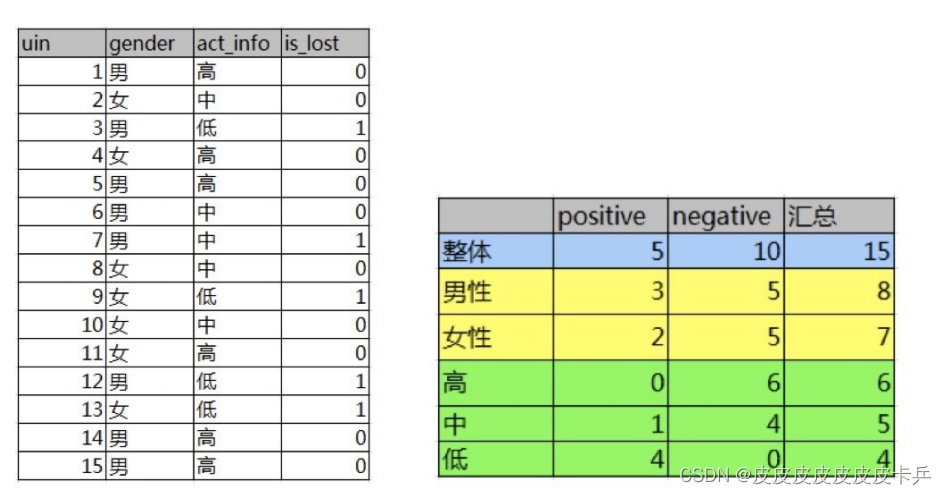
通过计算信息增益可以解决这个问题,统计上右表信息
其中Positive为正样本(已流失),Negative为负样本(未流失),下⾯的数值为不同划分下对应的⼈数。可得到三个熵:
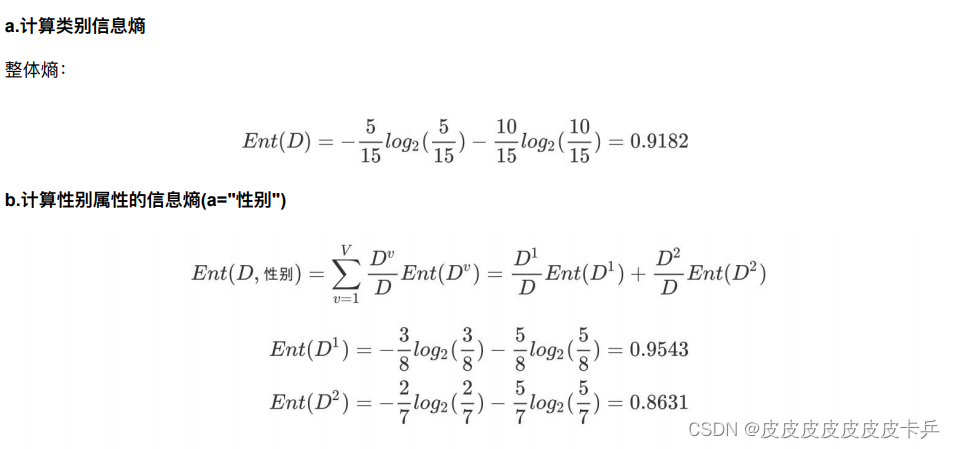

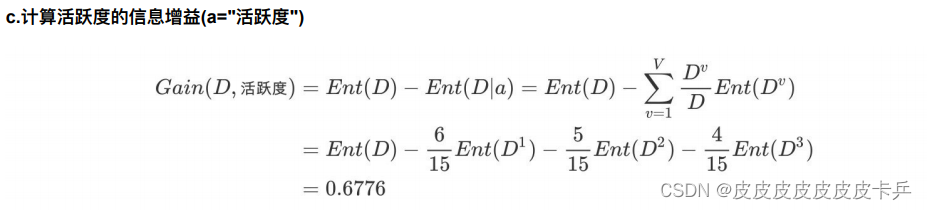
活跃度的信息增益⽐性别的信息增益⼤,也就是说,活跃度对⽤户流失的影响⽐性别⼤。在做特征选择或者数据分析的时候,我们应该重点考察活跃度这个指标。
实现步骤:
Ⅰ计算类别信息熵
Ⅱ计算类别的属性信息熵
Ⅲ计算类别的属性信息增益
Ⅳ重复执行二三步骤,直到计算所有的属性的信息增益
Ⅴ对比每个属性的信息增益,信息增益比较大的就是对当前决策层影响很大,应当作为重点考虑对象
2.2 信息增益率
概念:
在上⾯的介绍中,我们有意忽略了编号这⼀列.若把"编号"也作为⼀个候选划分属性,则根据信息增益公式可计算出它的信息增益为 0.9182,远⼤于其他候选划分属性。
实际上,信息增益准则对可取值数⽬较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C4.5 决策树算法 [Quinlan, 1993J 不直接使⽤信息增益,⽽是使⽤"增益率" (gain ratio) 来选择最优划分属性.
计算:
增益率:增益率是⽤前⾯的信息增益Gain(D, a)和属性a对应的"固有值"(intrinsic value) [Quinlan , 1993J的⽐值共同定义的。

2.2.1 信息增益率使用举例
在上一个例题的基础上计算固有值,从而计算信息增益。

活跃度的信息增益率更⾼⼀些,所以在构建决策树的时候,优先选择
C4.5算法流程:
while(当前节点"不纯"):
1.计算当前节点的类别熵(以类别取值计算)
2.计算当前阶段的属性熵(按照属性取值下得类别取值计算)
3.计算信息增益
4.计算各个属性的分裂信息度量
5.计算各个属性的信息增益率
end while
当前阶段设置为叶⼦节点
2.2.2 信息增益率使用举例2
如下图,第⼀列为天⽓,第⼆列为温度,第三列为湿度,第四列为⻛速,最后⼀列该活动是否进⾏。
我们要解决:根据下⾯表格数据,判断在对应天⽓下,活动是否会进⾏?
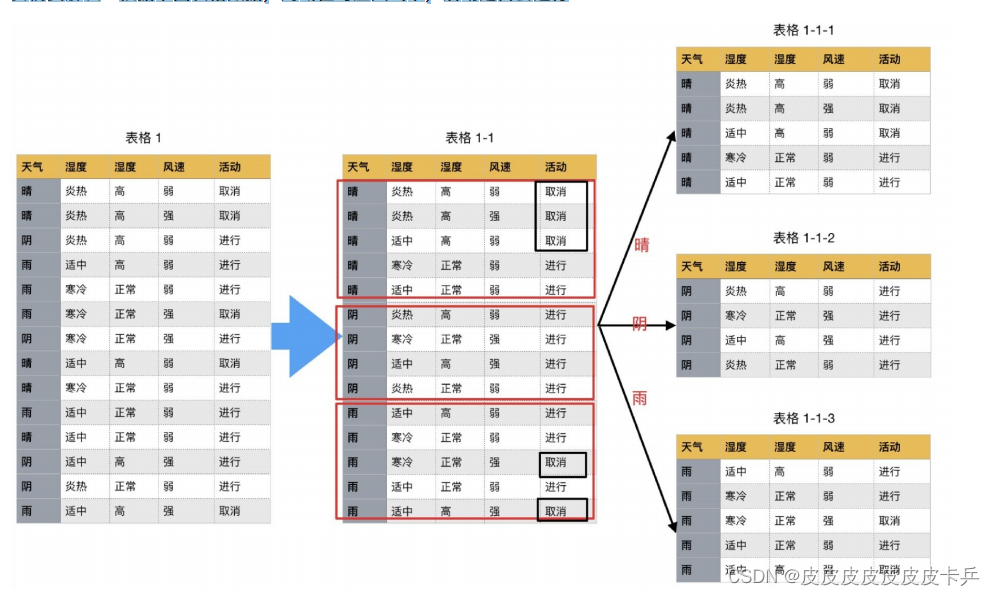
数据汇总:
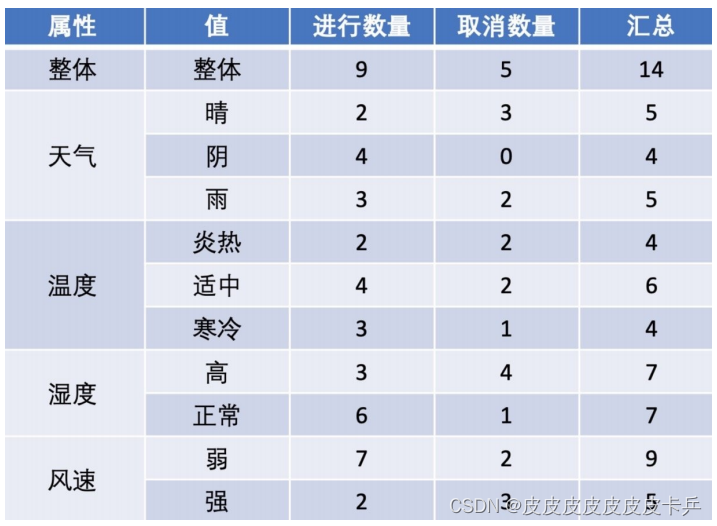
该数据集有四个属性,属性集合A={ 天⽓,温度,湿度,⻛速}, 类别标签有两个,类别集合L={进⾏,取消}。
a.计算类别信息熵
类别信息熵表示的是所有样本中各种类别出现的不确定性之和。根据熵的概念,熵越⼤,不确定性就越⼤,把事情搞清楚所需要的信息量就越多。
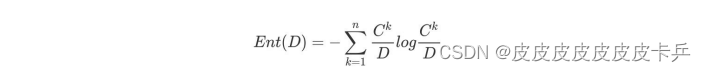
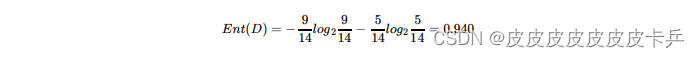
b.计算每个属性的信息熵
每个属性的信息熵相当于⼀种条件熵。他表示的是在某种属性的条件下,各种类别出现的不确定性之和。属性的信息熵越⼤,表示这个属性中拥有的样本类别越不“纯”。
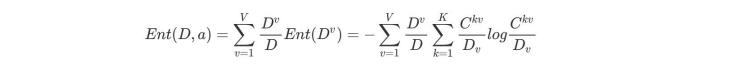
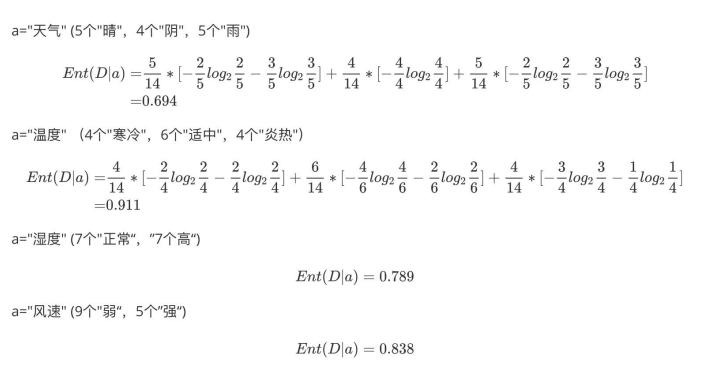
c.计算信息增益
信息增益的 = 熵 - 条件熵,在这⾥就是 类别信息熵 - 属性信息熵,它表示的是信息不确定性减少的程度。如果⼀个属性的信息增益越⼤,就表示⽤这个属性进⾏样本划分可以更好的减少划分后样本的不确定性,当然,选择该属性就可以更快更好地完成我们的分类⽬标。--------信息增益就是ID3算法的特征选择指标。
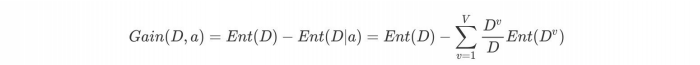

d.计算属性分裂信息度量
⽤分裂信息度量来考虑某种属性进⾏分裂时分⽀的数量信息和尺⼨信息,我们把这些信息称为属性的内在信息
(instrisic information)。信息增益率⽤信息增益/内在信息,会导致属性的重要性随着内在信息的增⼤⽽减⼩(也就是说,如果这个属性本身不确定性就很⼤,那我就越不倾向于选取它),这样算是对单纯⽤信息增益有所补偿。
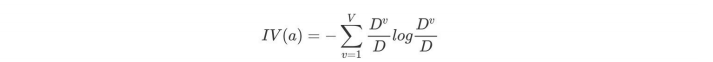
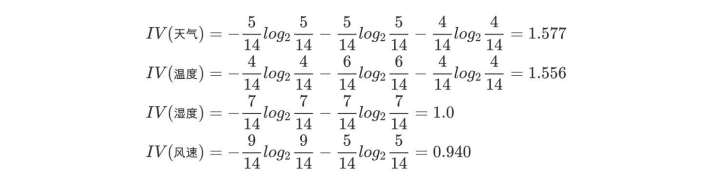
e.计算信息增益率
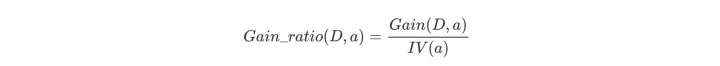

天⽓的信息增益率最⾼,选择天⽓为分裂属性。发现分裂了之后,天⽓是“阴”的条件下,类别是”纯“的,所以把它定义为叶⼦节点,选择不“纯”的结点继续分裂。
2.3 基尼值和基尼指数
2.3.1 基尼值和基尼指数介绍
基尼值Gini(D):从数据集D中随机抽取两个样本,其类别标记不⼀致的概率。故,Gini(D)值越⼩,数据集D的纯度越⾼(也就是说属于同类的概率)。
数据集 D 的纯度可⽤基尼值来度量:
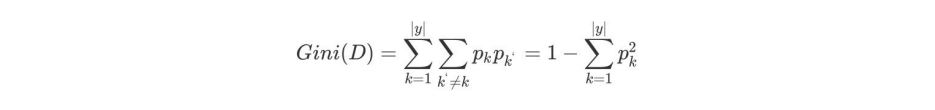
p = , D为样本的所有数量,C 为第k类样本的数量。
基尼指数Gini_index(D):⼀般,选择使划分后基尼系数最⼩的属性作为最优化分属性。
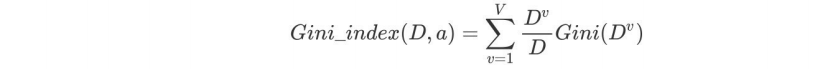
2.3.2 基尼值和基尼指数实现案例
依照下表做出决策树
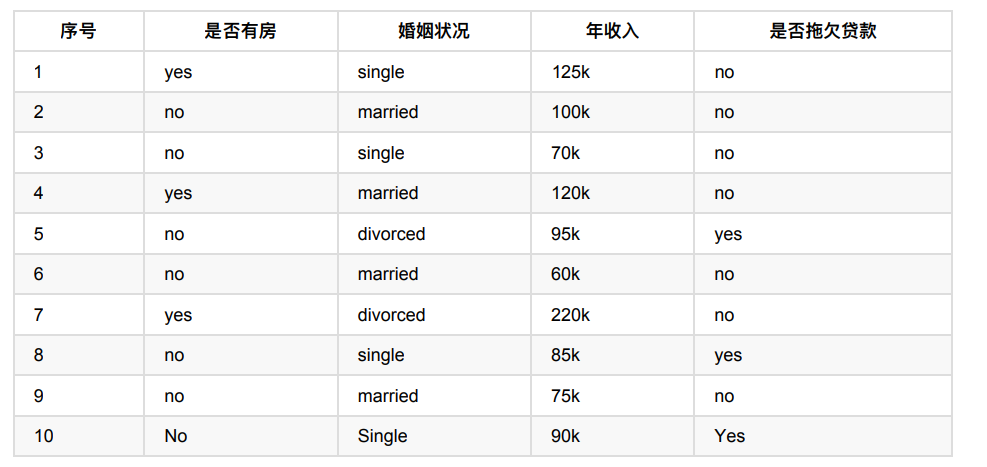
实现方法:对数据集⾮序列标号属性{是否有房,婚姻状况,年收⼊}分别计算它们的Gini指数,取Gini指数最⼩的属性作为决策树的根节点属性。
第一轮
第一步:根节点的Gini值为:
作用:比较其他属性的Gini指数看是否有划分的必要
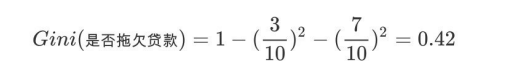
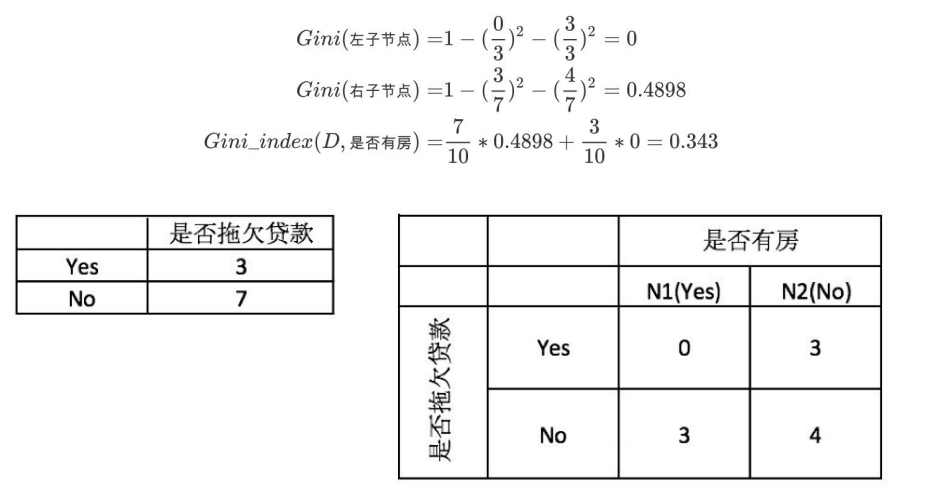
第二步:当根据是否有房来进⾏划分时,Gini指数计算过程为:
第三步:若按婚姻状况属性来划分,属性婚姻状况有三个可能的取值{married,single,divorced},分别计算划分后的Gini系数增益。

第四步:年收⼊Gini:
对于年收⼊属性为数值型属性,⾸先需要对数据按升序排序,然后从⼩到⼤依次⽤相邻值的中间值作为分隔将样本划分为两组。
例如当⾯对年收⼊为60和70这两个值时,我们算得其中间值为65。以中间值65作为分割点求出Gini指数。
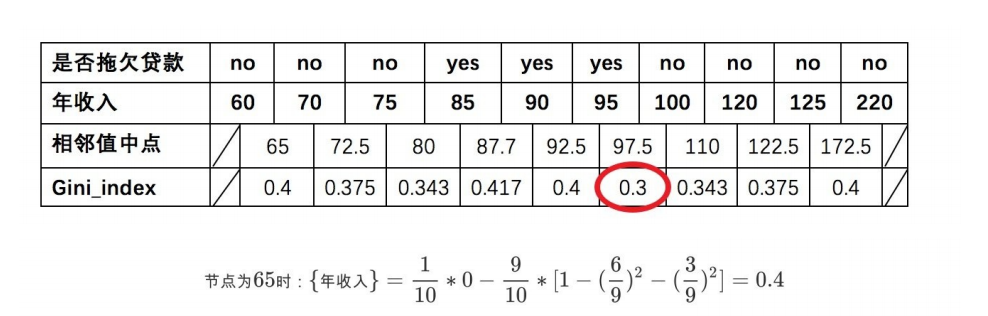
根据计算知道,三个属性划分根节点的指数最⼩的有两个:年收⼊属性和婚姻状况,他们的指数都为0.3。此时,选取⾸先出现的属性【married】作为第⼀次划分。
第⼆轮:
第一步:计算根节点的Gini指数:由于第一轮已经分出去四个,还剩下六个
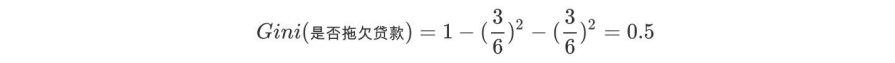
第二步:对于是否有房属性,可得
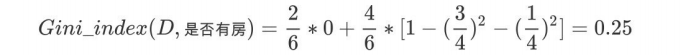
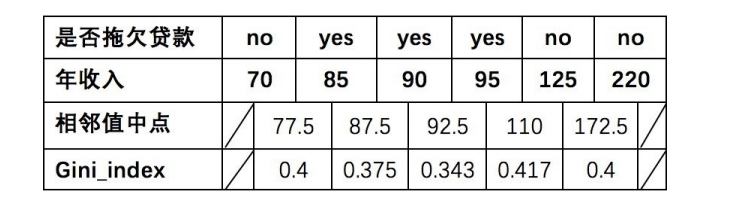
第三步:对于年收⼊属性则有
最终构造出决策树:
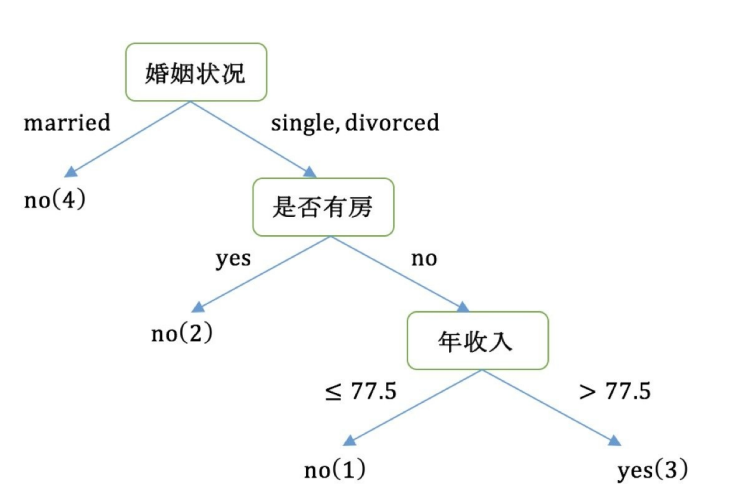
流程:
while(当前节点"不纯"):
1.遍历每个变量的每⼀种分割⽅式,找到最好的分割点
2.分割成两个节点N1和N2
end while
每个节点⾜够“纯”为⽌
三者比较:
| 名称 | 提出时间 | 分支方式 | 备注 |
|---|---|---|---|
| ID3 | 1975 | 信息增益 | ID3只能对离散属性的数据集构成决策树 |
| C4.5 | 1993 | 信息增益 率 | 优化后解决了ID3分⽀过程中总喜欢偏向选择值较多的 属性 |
| CART | 1984 | Gini系数 | 可以进⾏分类和回归,可以处理离散属性,也可以处理连续属性 |