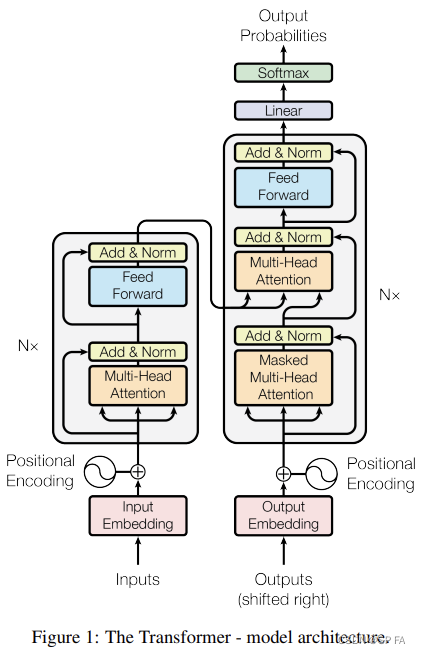
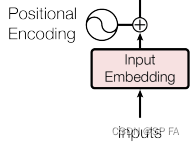
当前位置: 首页 > article >正文 基于 pytorch 的手写 transformer + tokenizer article 2025/2/28 15:23:16 先放出 transformer 的整体结构图,以便复习,接下来就一个模块一个模块的实现它。 1. Embedding Embedding 部分主要由两部分组成,即 Input Embedding 和 Positional Encoding,位置编码记录了每一个词出现的位置。通过加入位置编码可以提高模型的准确率,因为同一个词出现在不同位置可能代表了不同意思,这直接影响了最终的结果,所以要考虑位置因素。 位置编码公式: P E ( p o s , 2 i ) = 查看全文 http://www.kler.cn/a/1197.html 相关文章: 重新学习Vue,了解一下Vue的故事和核心特点 深度学习11. CNN经典网络 LeNet-5实现CIFAR-10 STL总结 【Python/Opencv】图像权重加法函数:cv2.addWeighted()详解 节流还在用JS吗?CSS也可以实现哦 JAVA并发编程(2)——(如何保证原子性,原子类,CAS乐观锁,JUC常用类) 176万,GPT-4发布了,如何查看OpenAI的下载量? 面试官:聊聊你知道的跨域解决方案 Linux 路由表说明 剑指 Offer II 031. 最近最少使用缓存 Linux:函数指针做函数参数 介绍两款红队常用的信息收集组合工具 【CSS 知识总结】第二篇 - HTML 扩展简介 OKHttp 源码解析(二)拦截器 中断控制器 面试官问 : ArrayList 不是线程安全的,为什么 ?(看完这篇,以后反问面试官) 信创办公–基于WPS的PPT最佳实践系列(表格和图标常用动画) 每日算法题 Unity学习日记12(导航走路相关、动作完成度返回参数) yolo车牌识别、车辆识别、行人识别、车距识别源码(包含单目双目)
先放出 transformer 的整体结构图,以便复习,接下来就一个模块一个模块的实现它。 1. Embedding Embedding 部分主要由两部分组成,即 Input Embedding 和 Positional Encoding,位置编码记录了每一个词出现的位置。通过加入位置编码可以提高模型的准确率,因为同一个词出现在不同位置可能代表了不同意思,这直接影响了最终的结果,所以要考虑位置因素。 位置编码公式: P E ( p o s , 2 i ) = 查看全文 http://www.kler.cn/a/1197.html 相关文章: 重新学习Vue,了解一下Vue的故事和核心特点 深度学习11. CNN经典网络 LeNet-5实现CIFAR-10 STL总结 【Python/Opencv】图像权重加法函数:cv2.addWeighted()详解 节流还在用JS吗?CSS也可以实现哦 JAVA并发编程(2)——(如何保证原子性,原子类,CAS乐观锁,JUC常用类) 176万,GPT-4发布了,如何查看OpenAI的下载量? 面试官:聊聊你知道的跨域解决方案 Linux 路由表说明 剑指 Offer II 031. 最近最少使用缓存 Linux:函数指针做函数参数 介绍两款红队常用的信息收集组合工具 【CSS 知识总结】第二篇 - HTML 扩展简介 OKHttp 源码解析(二)拦截器 中断控制器 面试官问 : ArrayList 不是线程安全的,为什么 ?(看完这篇,以后反问面试官) 信创办公–基于WPS的PPT最佳实践系列(表格和图标常用动画) 每日算法题 Unity学习日记12(导航走路相关、动作完成度返回参数) yolo车牌识别、车辆识别、行人识别、车距识别源码(包含单目双目)