基于数据库(MySQL)与缓存(Redis)实现分布式锁
分布式锁
分布式锁:分布式锁是在分布式的情况下实现互斥类型的一种锁
实现分布式锁需要满足的五个条件
- 可见性:多个进程都能看到结果
- 互斥性:只允许一个持有锁的对象的进入临界资源
- 可用性:无论何时都要保证锁服务的可用性(集群模式)
- 锁超时(死锁问题):允许持锁对象持锁最长时间,客户端一定可以获得锁
- 脑裂问题:集群同步时产生数据不一致,导致新的进程有可能拿到锁,但之前的进程以为自己还有锁,就出现了两个进程拿到了同一个锁的问题
基于数据库实现分布式锁
基于防重表(表记录)实现
- 创建锁表,内部存在字段表示资源名及资源描述,同一资源名使用数据库唯一性限制。
- 多个进程同时往数据库锁表中写入对某个资源的占有记录,当某个进程成功写入时则表示其获取锁成功。
- 其他进程由于资源字段唯一性限制插入失败陷入自旋并且失败重试。
- 当执行完业务后持有该锁的进程则删除该表内的记录,此时回到步骤一。
注意事项
- 当某进程持有锁并且挂死时候会造成资源一直不释放,造成死锁,因为需要维护一个time字段,定时清理任务去清理持有过久的锁
- 要设置为可重入模式,可以添加持有锁的进程的信息以及加锁的次数
基于悲观锁实现
- 关闭自动commmit属性
- 每次执行业务前使用查询语句后接for update锁定该行的数据
- 执行业务流程
- 提交commit
注意事项
- 并发量很高的情况下,影响系统的可用性
基于乐观锁实现
表里面冗余一个版本号字段
- 每次执行业务前首先进行数据库查询,查询当前的需要修改的资源的版本号
- 进行资源的修改操作,但会比较一下当前数据的版本号与操作1中的版本号是否相同
- 如果相同修改资源,否则返回第一步
注意事项
- 并发量很高的情况下,会对数据库造成很大的压力,同时并发不是很高
- 对业务具有侵入性,设置版本号会增加数据库冗余
基于分布式缓存实现分布式锁
基于分布式缓存实现分布式锁,这个大多数都是依靠redis来进行实现的,所以我们也以redis来进行举例
使用set命令然后在这个命令后加一些参数来实现一个原子命令来设置对应过期时间或者使用lua脚本来实现这个功能
SET key value[EX seconds][PX milliseconds][NX|XX]
但是存在问题:
- 锁过期了,但是业务还没有执行完
- 锁被其他线程给误删了
避免被误删
对于value设置一个当前进程唯一的随机值
同时为了一个保证判断当前值是否一致以及删除键的操作是唯一的,那么就会使用到lua脚本
在Redis中,Lua脚本能够保证原子性的主要原因还是Redis采用了单线程执行模型。也就是说,当Redis执行Lua脚本时,Redis会把Lua脚本作为一个整体并把它当作一个任务加入到一个队列中,然后单线程按照队列的顺序依次执行这些任务,在执行过程中Lua脚本是不会被其他命令或请求打断,因此可以保证每个任务的执行都是原子性的。
锁续期机制
在redisson中有一个看门狗机制,相当于有一个后台线程,每隔10s都会检测一下,如果线程还持有锁,那么就会不断延长key的生存时间
RedLock
在企业里面大多数都是基于redis集群的状态,不会是单个节点,所以确保每个节点上都加上锁才是真正的加锁成功
RedLock:搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
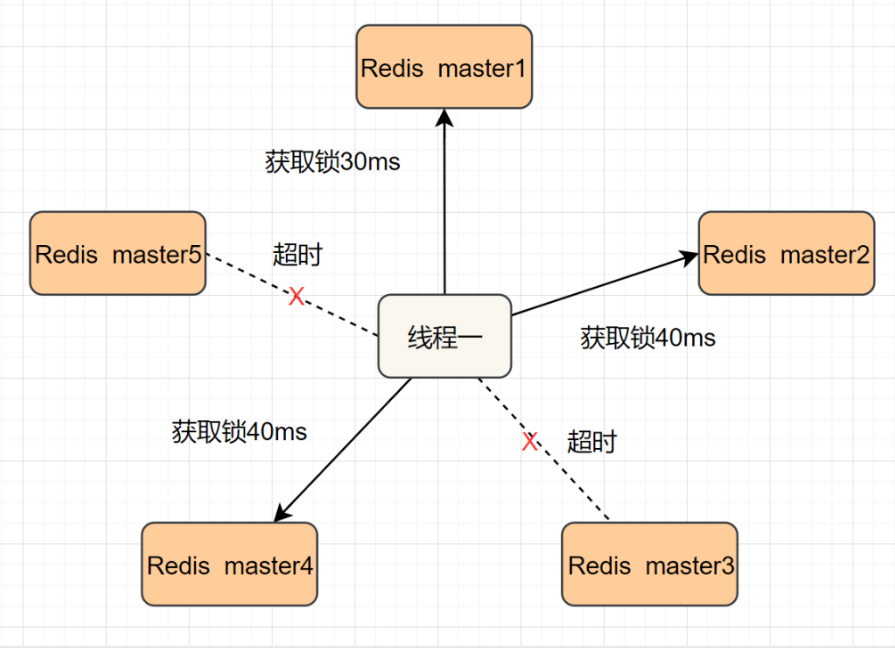
- 获取当前时间,以毫秒为单位
- 按顺序像五个节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间
- 用当前时间减去步骤1的时间,得到获取锁使用的时间,当且仅当超过一半的节点都获取到锁并且使用时间小于锁失效时间,锁才算获取成功
- 如果不满足步骤3则就是加锁失败,同时释放刚才的锁
实现锁重入
如果想实现可重入功能,那么可以使用redis里面的hash的数据结构,然后使用lua脚本来设置具体的值,具体要使用到的三个值就是下面的这三个命令
hset [name] [key] [value]
hincrby
expire