Linux网络——HTTP
一.应用层
我们程序员写的一个个解决我们实际问题, 满足我们日常需求的网络程序, 都是在应用层.
我们上一次写的网络版本计算器就是一个应用层的网络程序。
我们约定了数据的读取,一端发送时构造的数据, 在另一端能够正确的进行解析, 就是ok的. 这种约定, 就是应用层协议。
在应用层我们只负责将数据怎么读取,和怎么构造数据,然后将构造好的数据交给应用层的协议层传输层,再由传输层何其一下的网络协议栈来帮我们完成数据在网络中发送,至于数据在这之间是怎么发送的,什么时候发送的,我们不知道,不清楚,也不关心。
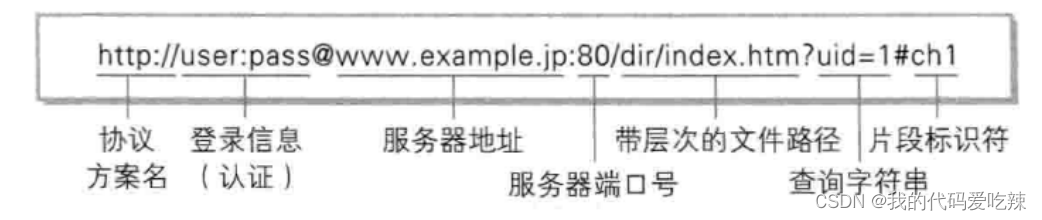
二.认识URL
平时我们俗称的 "网址" 其实就是说的 URL.
1.域名
服务器地址可以是一个IP地址,但是IP地址是点分十进制的字符串,为了方便记忆就有了和IP地址一 一对应的域名。
例如:
- 112.29.213.131 —— www.JD.com
- 36.155.132.55 —— www.baidu.com
2.urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式,这个过程就是urlencode。
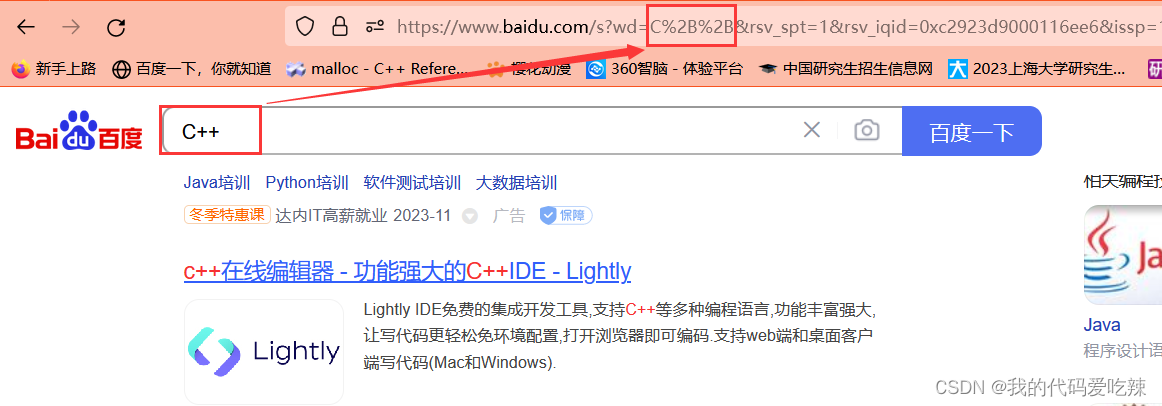
"+" 被转义成了 "%2B"。
urldecode就是urlencode的逆过程。
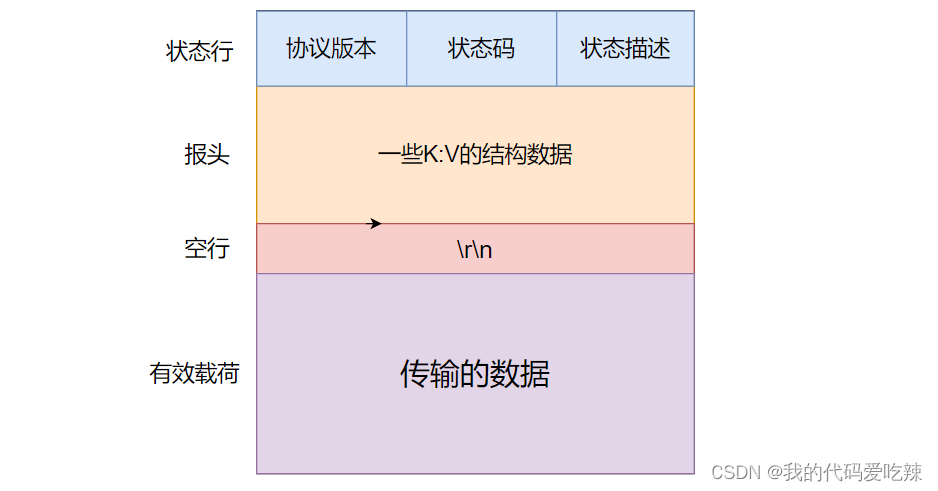
三.HTTP协议格式
1.请求格式http
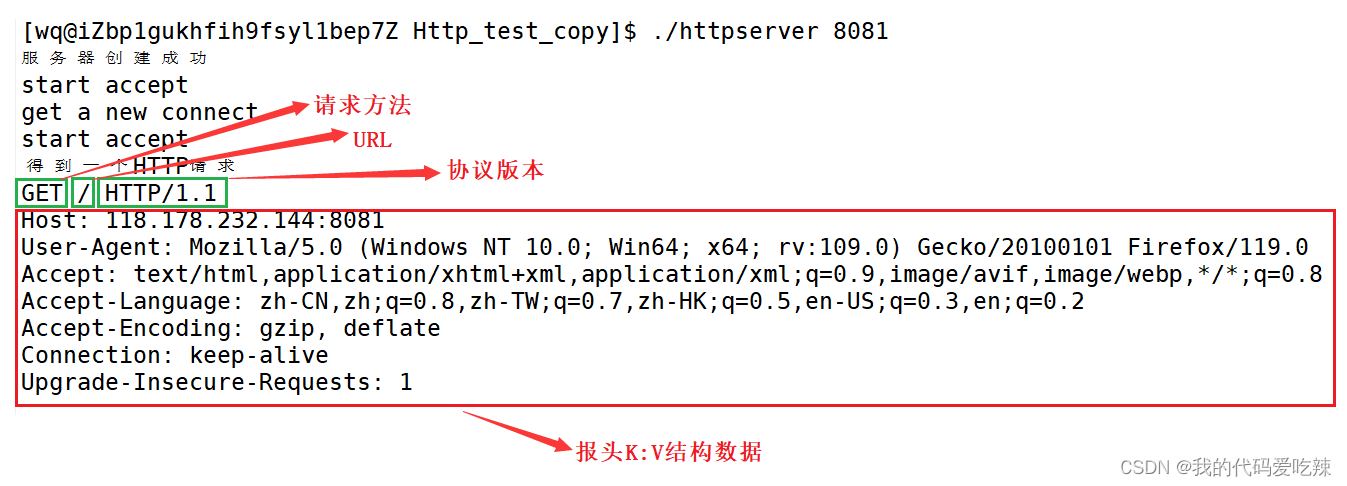
见一见http请求:
部分测试代码:
编写一个服务器,服务器多线程接受网络数据,使用浏览器在url栏框中输入服务端车程序的IP和端口,然后回车。此时浏览器就会构建一个http请求发送给我们的服务端程序,服务端程序直接将收到的数据直接以字符串的形式输出到终端。
void serverIO(int fd)
{
string message;
char buff[102400];
// 读取一个完整的http请求报文
int n = recv(fd, buff, sizeof(buff), 0);
message = buff;
// 直接将该请求以字符串的形式输出
cout << "得到一个HTTP请求" << endl;
cout << message << endl;
close(fd);
}得到的http请求:
2.响应格式
见一见http响应:
使用telnet 向百度模拟发送一个http请求,接受返回的http响应。
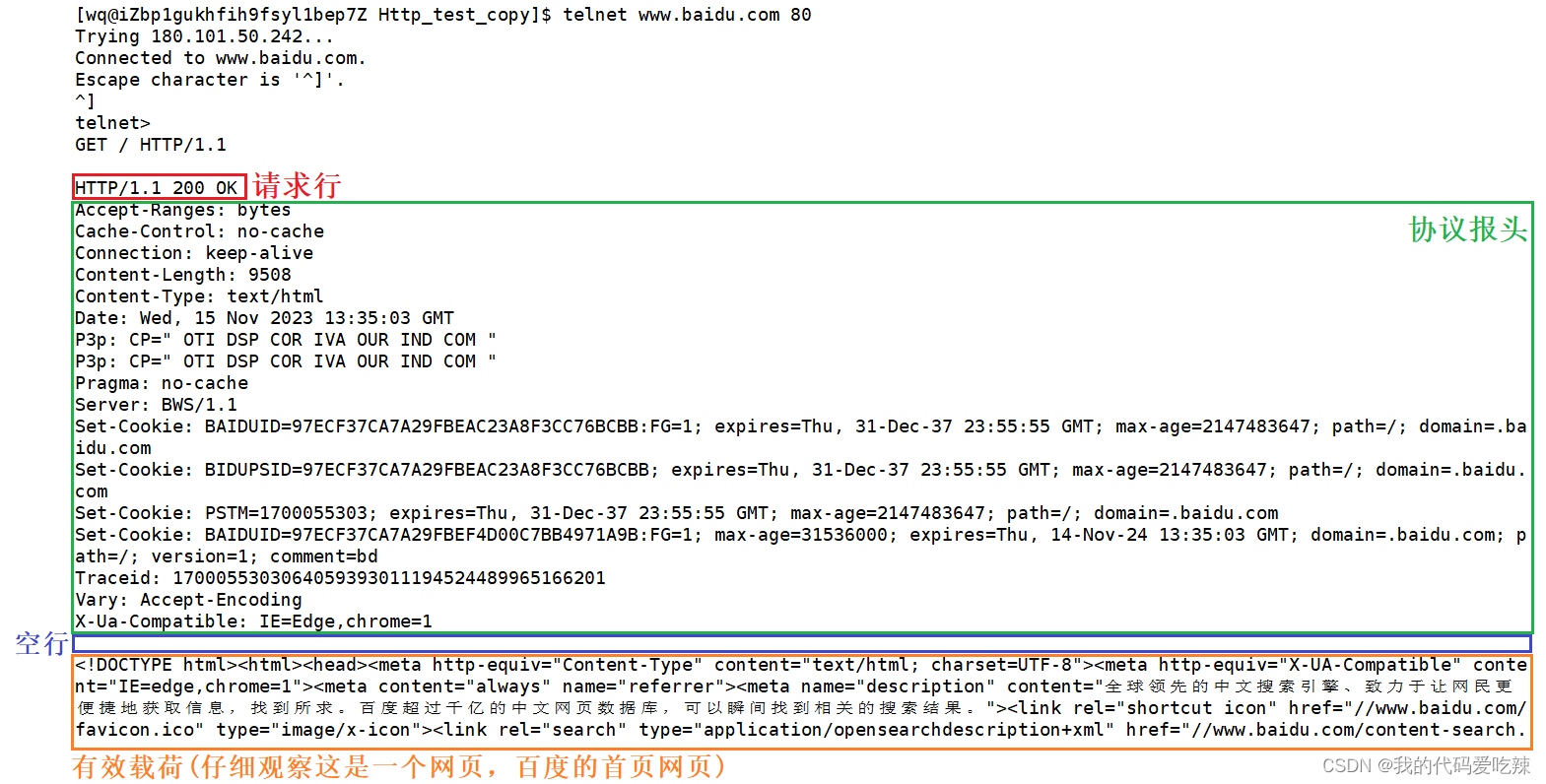
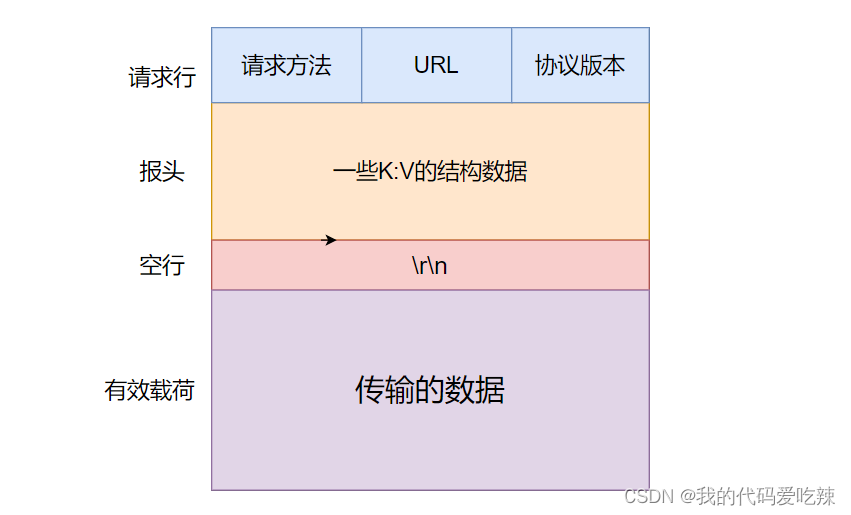
HTTP协议的格式大致有四部分组成:
- 首行:HTTP请求——[ 方法 ]+[ url ]+[ 版本 ];HTTP响应——[ 版本 ]+[ 状态码 ]+[ 描述 ];其中请求中url实际上就是服务器上的请求的资源路径。
- Header:请求/响应 的属性,冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束。例如:Content-Length:8899,标识 请求/响应 的有效载荷长度,有效载荷的长度是8899。
- 空行:用来分隔Header和Body。
- Body:就是有效载荷部分,空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度;
四.HTTP响应状态码
| 状态码 | 类别 | 描述 |
| 1XX | lnformational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
说明:
Client Error:
- 客户端连接的端口错了。
- 客户端连接的域名或者IP地址错误。
- 如果客户端使用了域名连接,域名可能指向了错误的服务器。
- 当客户端发送了一个无效请求时,服务器可能会因为无法处理而返回 Client Error。
lnformational:
- 主要作用是告知客户端请求已经被接受 。
Redirection:
- 是服务器在处理客户端请求时,为了保证流程的顺利进行而发出的一种信号。
- 当客户端发送一个请求到服务器,服务器会根据需要将请求重定向到另一个URL。
Success:
- 表示客户端与服务器之间的通信已经成功完成,并且服务器已经处理了客户端的请求。
Server Error:
- 表示服务器在处理客户端请求时发生了错误。
- 服务器遇到了一个未知的错误,无法完成请求的处理。
- 服务器当前无法处理请求,因为过载或维护。
五.HTTP常见Header
Header是以K/V形式存储的字符串,主要是一些协议的属性说明等。
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx(重定向)状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
介绍Content-Type:表明此次http报文的body传输的是什么内容。
对于服务器上的每一种资源,都是以文件的形式存在的,文件都会有自己的类型,例如(网页文件).html,(音频文件).mp3,(图片).jpg/.png,(视频).mp4。
每一种文件类型,都会有自己对应的Content-Type类型:
- text/html:HTML 文档
- text/css:CSS 样式表
- text/javascript:JavaScript 脚本
- image/jpeg:JPEG 图像
- image/png:PNG 图像
- image/gif:GIF 图像
Content-Type 对照表
六.简单的HTTP服务器
编写一个服务器,多线程处理请求,对于请求的处理,解析一个http请求反序列化,根据http的请求的资源,构建响应并返回。
Sock.hpp
#pragma once
#include <iostream>
#include <cstdio>
#include <cstring>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include "Log.hpp"
#define TCP SOCK_STREAM
#define UDP SOCK_DGRAM
const static int backlog = 32;
enum
{
SOCK_ERR = 10,
BING_ERR,
LISTEN_ERR,
CONNECT_ERR
};
class Udp
{
public:
Udp(int SOCK)
{
_listensock = socket(AF_INET, SOCK, 0);
if (_listensock == -1)
{
Logmessage(Fatal, "socket err ,error code %d,%s", errno, strerror(errno));
exit(SOCK_ERR);
}
}
Udp(uint16_t port, int SOCK)
: _port(port)
{
_listensock = socket(AF_INET, SOCK, 0);
if (_listensock == -1)
{
Logmessage(Fatal, "socket err ,error code %d,%s", errno, strerror(errno));
exit(10);
}
}
void Bind()
{
struct sockaddr_in host;
host.sin_family = AF_INET;
host.sin_port = htons(_port);
host.sin_addr.s_addr = INADDR_ANY; // #define INADDR_ANY 0x00000000
socklen_t hostlen = sizeof(host);
int n = bind(_listensock, (struct sockaddr *)&host, hostlen);
if (n == -1)
{
Logmessage(Fatal, "bind err ,error code %d,%s", errno, strerror(errno));
exit(BING_ERR);
}
}
int FD()
{
return _listensock;
}
~Udp()
{
close(_listensock);
}
protected:
int _listensock;
uint16_t _port;
};
class Tcp : public Udp
{
public:
Tcp(uint16_t port)
: Udp(port, TCP)
{
}
Tcp()
: Udp(TCP)
{
}
void Listen()
{
int n = listen(_listensock, backlog);
if (n == -1)
{
Logmessage(Fatal, "listen err ,error code %d,%s", errno, strerror(errno));
exit(LISTEN_ERR);
}
}
int Accept(string *clientip, uint16_t *clientport)
{
struct sockaddr_in client;
socklen_t clientlen;
int sock = accept(_listensock, (struct sockaddr *)&client, &clientlen);
if (sock < 0)
{
Logmessage(Warning, "bind err ,error code %d,%s", errno, strerror(errno));
}
else
{
*clientip = inet_ntoa(client.sin_addr);
*clientport = ntohs(client.sin_port);
}
return sock;
}
void Connect(string ip, uint16_t port)
{
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(port);
server.sin_addr.s_addr = inet_addr(ip.c_str());
socklen_t hostlen = sizeof(server);
int n = connect(_listensock, (struct sockaddr *)&server, hostlen);
if (n == -1)
{
Logmessage(Fatal, "Connect err ,error code %d,%s", errno, strerror(errno));
exit(CONNECT_ERR);
}
}
~Tcp()
{
}
};
Server.hpp
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>
#include <functional>
#include "Sock.hpp"
using fun_t = std::function<string(string &)>;
class Httpserver;
struct Args
{
Args(Httpserver *ser, string ip, uint16_t port, int fd)
: _ip(ip), _port(port), _pserver(ser), _fd(fd)
{
}
int _fd;
uint16_t _port;
string _ip;
Httpserver *_pserver;
};
class Httpserver
{
public:
Httpserver(fun_t func, uint16_t port)
: _func(func)
{
tcp = new Tcp(port);
tcp->Bind();
tcp->Listen();
cout << "服务器创建成功" << endl;
}
void start()
{
while (1)
{
string clientip;
uint16_t clientport;
cout << "start accept" << endl;
int sock = tcp->Accept(&clientip, &clientport);
cout << "get a new connect" << endl;
// 多线程处理请求
pthread_t t;
Args *args = new Args(this, clientip, clientport, sock);
pthread_create(&t, nullptr, ThreadRun, args);
}
}
~Httpserver()
{
delete tcp;
}
private:
static void *ThreadRun(void *args)
{
pthread_detach(pthread_self());
Args *ts = static_cast<Args *>(args);
ts->_pserver->serverIO(ts->_fd);
delete ts;
return nullptr;
}
void serverIO(int fd)
{
string message;
char buff[102400];
// 1.确信,读取一个完整的http请求报文
int n = recv(fd, buff, sizeof(buff), 0);
message = buff;
string re = _func(message);
send(fd, re.c_str(), re.length(), 0);
close(fd);
}
private:
Tcp *tcp;
fun_t _func;
};Server.cc
#include <sstream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <signal.h>
#include <sys/socket.h>
#include <iostream>
#include <cstring>
#include <cstdio>
#include <string>
#include <vector>
#include "Server.hpp"
#include "util.hpp"
const string wwwroot = "./html/3";
const string defaupath = "/index.html";
class HttpRequest
{
public:
HttpRequest()
{
}
~HttpRequest() {}
void Print()
{
cout << method_ << ":" << url_ << ":" << httpVersion_ << endl;
for (auto &e : body_)
cout << e << endl;
cout << "suffix:" << suffix_ << endl;
cout << "path:" << path_ << endl;
}
public:
std::string method_; // 请求方法
std::string url_; // 资源地址
std::string httpVersion_; // 协议版本
std::vector<std::string> body_; // 报头
std::string path_; // 请求资源路径
std::string suffix_; // 资源类型
};
HttpRequest Deserialize(string &message)
{
HttpRequest req;
// 1.拿到请求行
string oneline = HeadOneLine(message, SEP);
// 2.解析请求行
DisposeOneLine(oneline, &req.method_, &req.url_, &req.httpVersion_);
// 3.解析反序列化报头
while (!message.empty())
{
string mes = HeadOneLine(message, SEP);
req.body_.push_back(mes);
}
// 4.设置请求资源路径 url:/a/b/c
if (req.url_[req.url_.length() - 1] == '/')
{
req.path_ = wwwroot + defaupath; //./html/index.html
}
else
{
req.path_ = wwwroot + req.url_; //./html/a/b/c
}
// 5.设置请求资源类型
auto pos = req.url_.find('.');
if (pos == string::npos)
req.suffix_ = ".html";
else
req.suffix_ = req.url_.substr(pos);
return req;
}
string Dispose(string &message)
{
// 这里我们一定读取的是一个完整的报文
// 一个网页会有很多的资源,每一个资源(网页,图片,视频),都需要一次http请求来得到
// 所以我们需要知道,每次请求的资源是什么,即需要知道请求的url是什么,url的类型是什么
// 反序列化请求
HttpRequest req = Deserialize(message);
req.Print();
// 响应————最简单的一个响应
// 4.有效载荷
string body = Readfile(req.path_) + SEP;
// 1.响应的状态行————"HTTP版本 状态码 状态描述\r\n"
string request_head = string("HTTP/1.0 200 OK") + SEP;
// 2.响应报头————Content-Length,Content-Type
request_head += string("Content-Length: ") + to_string(body.length()) + SEP;
request_head += GetContentType(req.suffix_) + SEP;
// 3.空行
request_head += SEP;
// 整体的响应报文
string responce = request_head + body;
return responce;
}
void daemonize()
{
// 1.忽略SIGPIPE信号
signal(SIGPIPE, SIG_IGN);
// 2.更改进程的工作目录
// chdir();
// 3.让自己不要成为进程组组长
if (fork() > 0)
exit(0);
// 4.设置自己是一个独立的会话
setsid();
// 5.重定向0,1,2
int fd = 0;
if (fd = open("dev/null", O_RDWR) != -1)
{
dup2(fd, STDIN_FILENO);
dup2(fd, STDOUT_FILENO);
dup2(fd, STDERR_FILENO);
// 6.关闭掉不需要的fd
if (fd > STDERR_FILENO)
{
close(fd);
}
}
}
int main(int argc, char *argv[])
{
daemonize();
uint16_t port = atoi(argv[1]);
Httpserver httpser(Dispose, port);
httpser.start();
return 0;
}
Util.hpp
#pragma once
#include <iostream>
#include <unistd.h>
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#define SEP "\r\n"
using namespace std;
string Readfile(const string path)
{
// 1. 获取文件本身的大小
string fileContent;
struct stat st;
int n = stat(path.c_str(), &st);
if (n < 0)
return "";
int size = st.st_size;
// 2. 调整string的空间
fileContent.resize(size);
// 3. 读取
int fd = open(path.c_str(), O_RDONLY);
if (fd < 0)
return "";
read(fd, (char *)fileContent.c_str(), size);
close(fd);
return fileContent;
}
string HeadOneLine(string &message, const string &sep)
{
auto pos = message.find(sep, 0);
if (pos == string::npos)
return "";
string oneline = message.substr(0, pos);
message.erase(0, pos + sep.size());
return oneline;
}
void DisposeOneLine(const string &oneline, string *method, string *url, string *httpVersion)
{
stringstream line(oneline);
line >> *method >> *url >> *httpVersion;
}
string GetContentType(const string &suffix)
{
std::string content_type = "Content-Type: ";
if (suffix == ".html" || suffix == ".htm")
content_type + "text/html";
else if (suffix == ".css")
content_type += "text/css";
else if (suffix == ".js")
content_type += "application/x-javascript";
else if (suffix == ".png")
content_type += "image/png";
else if (suffix == ".jpg")
content_type += "image/jpeg";
else
{
}
return content_type;
}
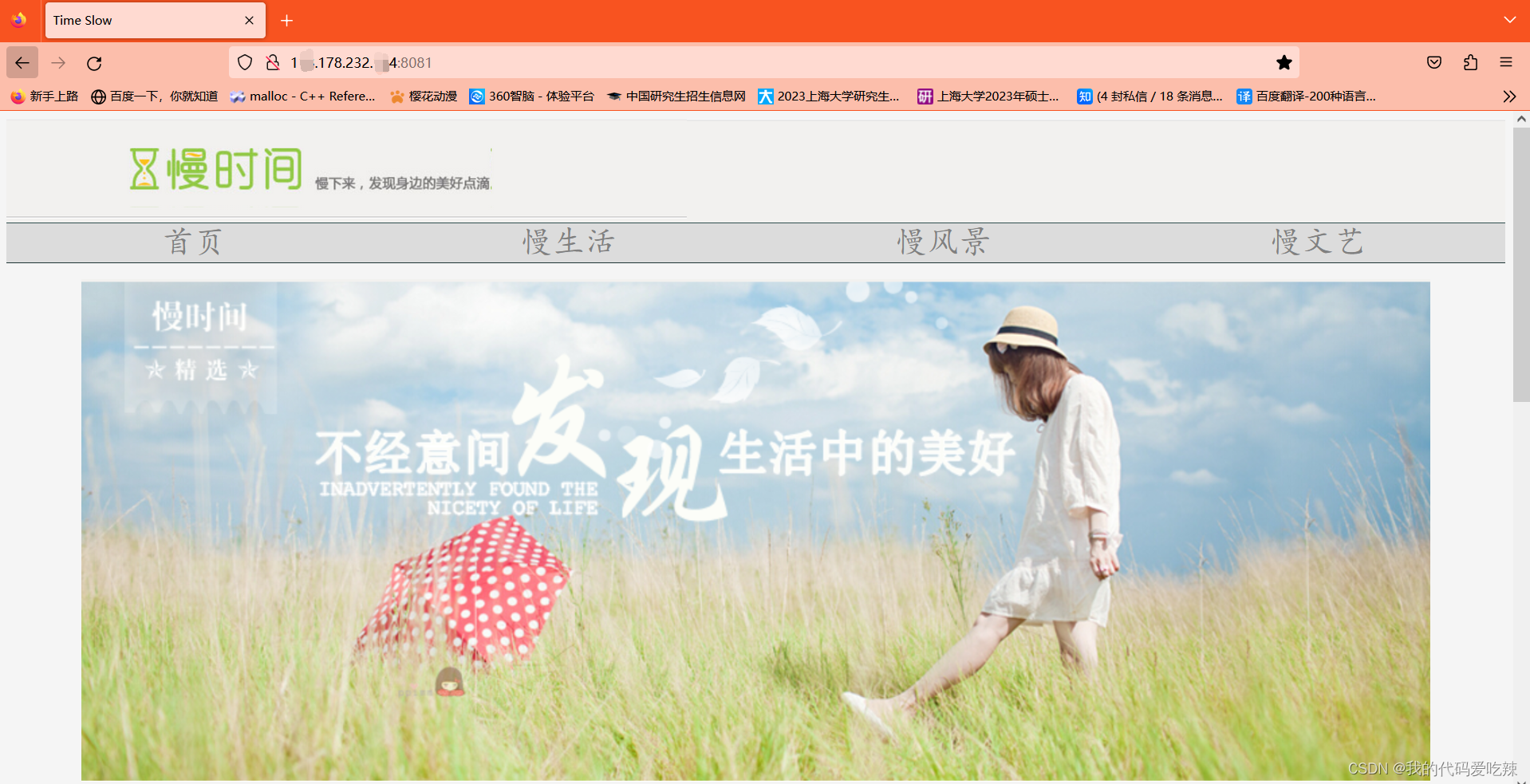
效果展示:
七.HTTP的方法

HTTP的方法有很多但是最常用的只有两个:GET,POST。
1.GET方法
我们要促使浏览器使用不同的方法进行资源请求,提交,要使用html的表单。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>CSDN</title>
</head>
<body>
<h1>test</h1>
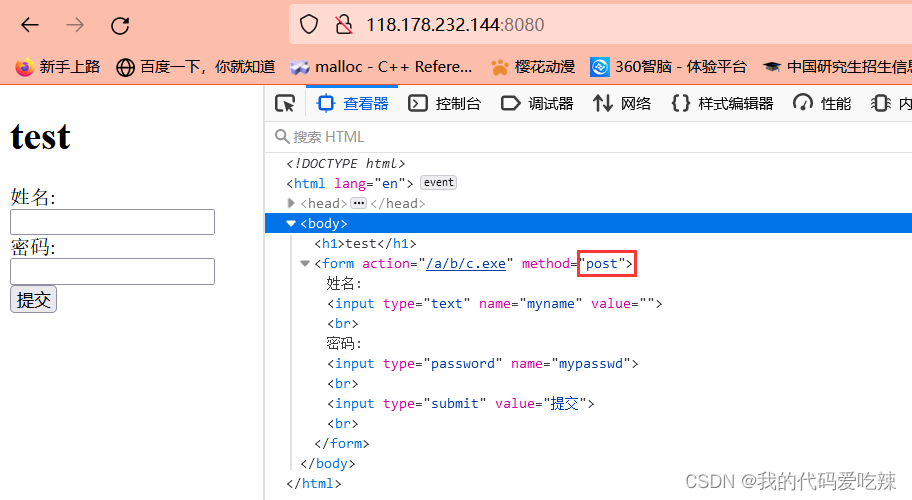
<form action="/a/b/c.exe" method="get">
姓名: <input type="text" name="myname" value=""><br />
密码: <input type="password" name="mypasswd"><br />
<input type="submit" value="提交"><br />
</form>
</body>
</html>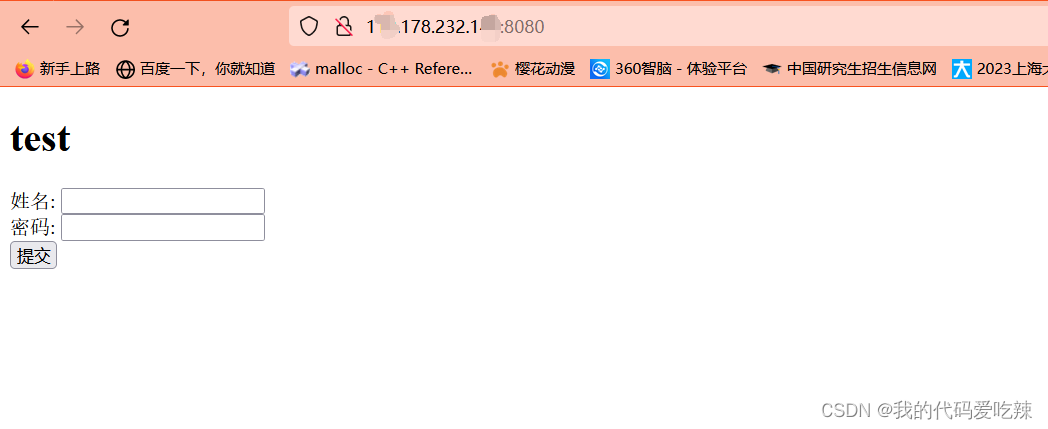
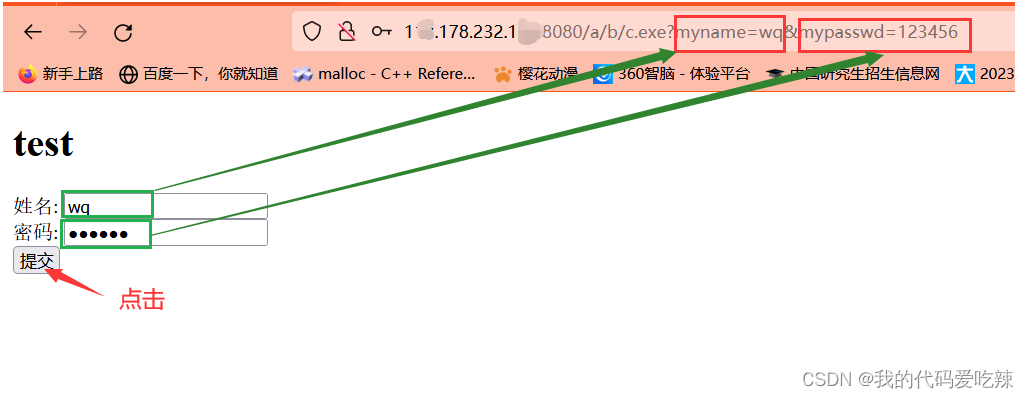
尝试提交数据:

2.POST方法
再次尝试提交数据:

区别:
- GET能获取一个静态网页,GET也能提交参数,通过URL的方式提交参数。
- POST请求,提交的参数的时候,是通过正文的部分提交的参数。
- GET方法提交参数,不私密(没有不安全的说法),安全对HTTP来说本身就没有保障。
- POST提交参数比较私密一些。
- 由于GET使用url提交参数,所以大小一般会受限。
- POST使用正文提交参数,正文理论上可以非常大。