fopen/fwrite/fread 对UNICODE字符写入的总结
windows对fopen函数进行了升级,可以支持指定文件的编码格式(ccs参数指定)。
例如:
FILE *fp = fopen("newfile.txt", "rt+, ccs=UTF-8");当以 ccs 模式打开文件时,进行读写操作的数据应为 UTF-16 编码,存储为 wchar_t 类型。这意味着你应使用如 fgetws、fputws 等宽字符版本的函数进行读写,或者使用fread/fwrite读取和写入wchar_t 类型数据。
- 我们下面来编写一个例子,文件编码格式指定为UTF-8,写入字符串带中文和英文,代码如下:
#include <stdafx.h>
#include <stdio.h>
void main()
{
FILE *g_LogFile = fopen("D:\\UTF8.log", "w,ccs=UTF-8");
int num = 10;
while (--num > 0)
{
//用fputws和fwrite能得到相同的效果
//fputws(L"hunan bowan tech 湖南泊湾科技有限公司\n", g_LogFile);
wchar_t szLog[1024] = L"hunan bowan tech 湖南泊湾科技有限公司\n";
fwrite(szLog, 2, wcslen(szLog), g_LogFile);
}
fclose(g_LogFile);
}
执行完上面代码,我们可以得到一个文件,用记事本打开文件如下:

然后用WinHex打开文件查看一下每个字节的数据如下:
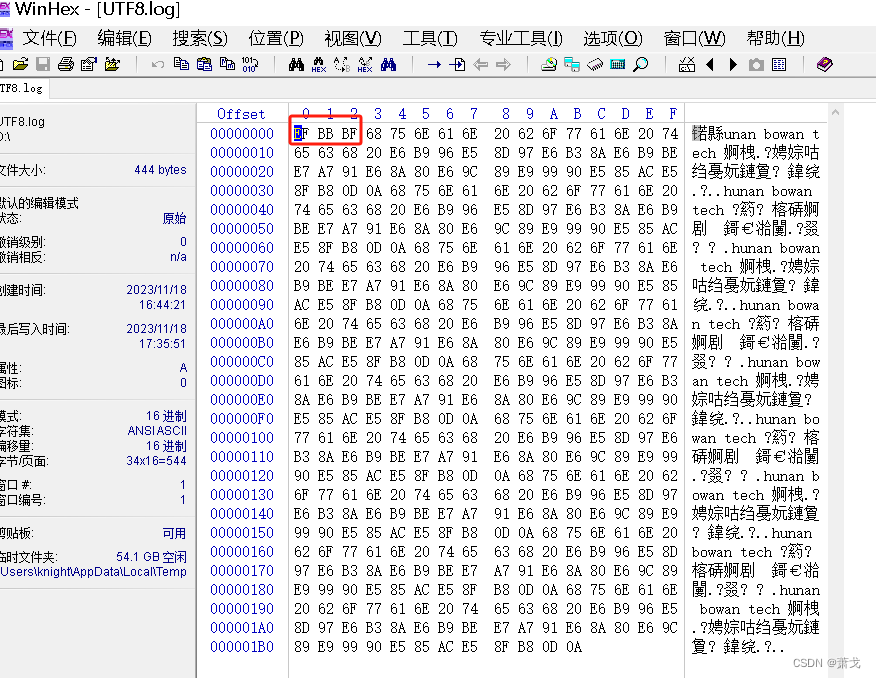
从截图可知,确实是将Unicode字符集转成了UTF-8编码格式的字符集,然后写入了文件。
UTF-8编码格式的文件前面有3个字节的文件头。
- 我们下面来编写另外一个例子,文件编码格UNICODE,写入字符串带中文和英文,代码如下:
#include <stdafx.h>
#include <stdio.h>
void main()
{
FILE *g_LogFile = fopen("D:\\UNICODE.log", "w,ccs=UNICODE");
int num = 10;
while (--num > 0)
{
//fputws(L"hunan bowan tech 湖南泊湾科技有限公司\n", g_LogFile);
wchar_t szLog[1024] = L"hunan bowan tech 湖南泊湾科技有限公司\n";
fwrite(szLog, 2, wcslen(szLog), g_LogFile);
//char szLog[1024] = "xiaoge is very good 我爱中国\n";
//fwrite(szLog, 1, 19, g_LogFile);
}
fclose(g_LogFile);
}上面代码执行结果如下,记事本打开:
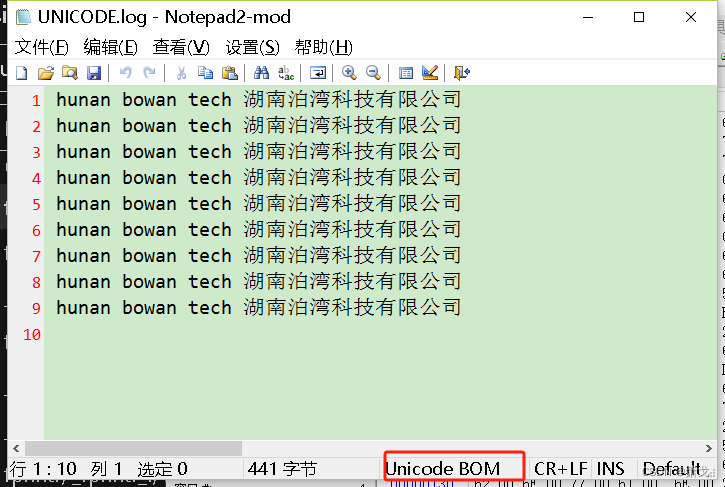
WinHex打开:
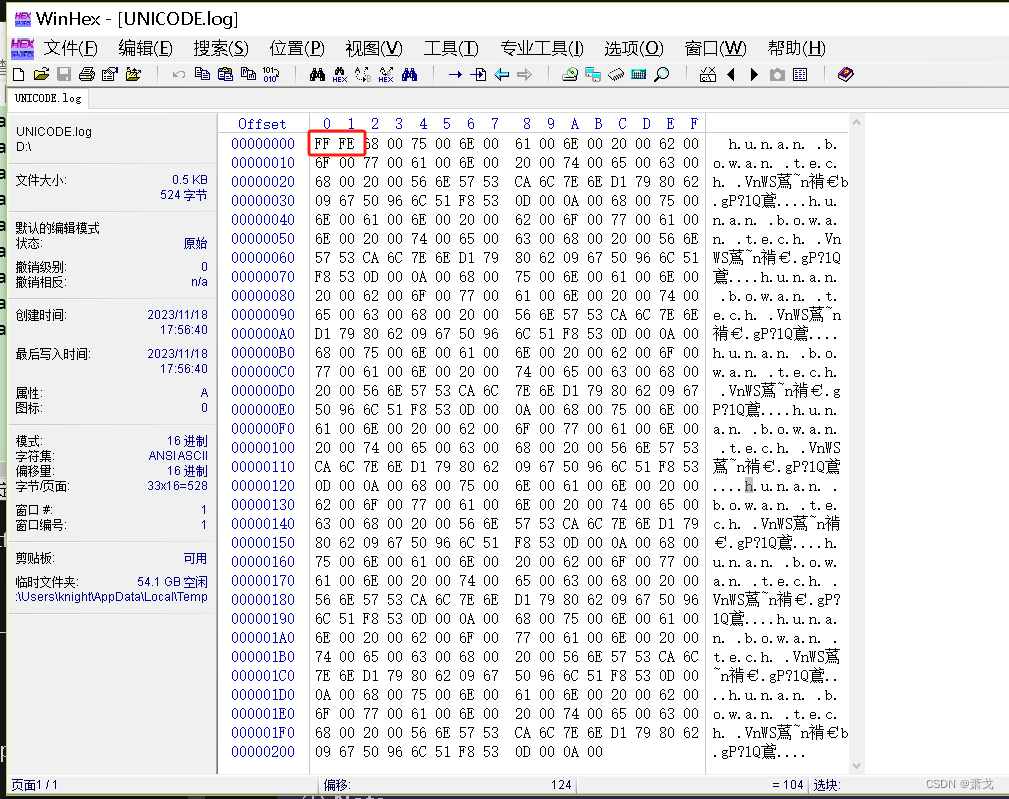
从截图可知,写入文件的编码格式为UNICODE编码,UNICODE编码格式的文件前面有2个字节的文件头。
- 当以
ccs模式打开文件时,如果读写数据为char类型,则需要写入偶数字节,如果写入奇数字节,则会报错。
下面是写入奇数字节的代码:
#include <stdafx.h>
#include <stdio.h>
void main()
{
FILE *g_LogFile = fopen("D:\\UNICODE.log", "w,ccs=UNICODE");
int num = 10;
while (--num > 0)
{
//fputws(L"hunan bowan tech 湖南泊湾科技有限公司\n", g_LogFile);
//wchar_t szLog[1024] = L"hunan bowan tech 湖南泊湾科技有限公司\n";
//fwrite(szLog, 2, wcslen(szLog), g_LogFile);
char szLog[1024] = "xiaoge is very good 我爱中国\n";
fwrite(szLog, 1, 19, g_LogFile);
}
fclose(g_LogFile);
}执行上面代码会报错,报错如下:

如果我们将代码改为偶数字节,代码如下:
#include <stdafx.h>
#include <stdio.h>
void main()
{
FILE *g_LogFile = fopen("D:\\UNICODE.log", "w,ccs=UNICODE");
int num = 10;
while (--num > 0)
{
//fputws(L"hunan bowan tech 湖南泊湾科技有限公司\n", g_LogFile);
//wchar_t szLog[1024] = L"hunan bowan tech 湖南泊湾科技有限公司\n";
//fwrite(szLog, 2, wcslen(szLog), g_LogFile);
char szLog[1024] = "xiaoge is very good 我爱中国\n";
fwrite(szLog, 1, 20, g_LogFile);
}
fclose(g_LogFile);
}代码能执行成功,写入文件用记事本打开如下:
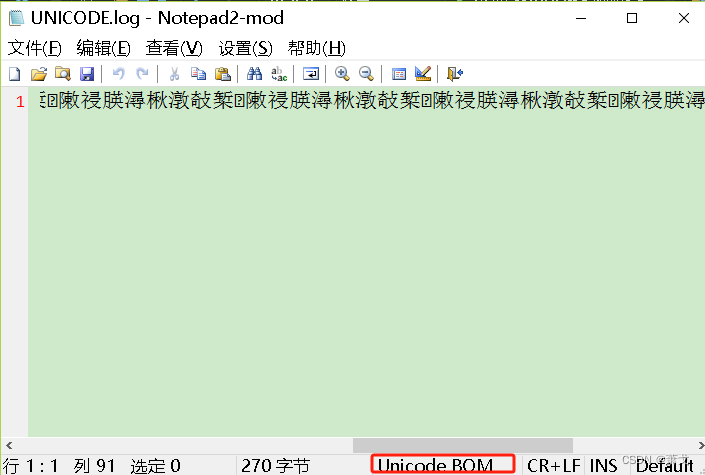
用WinHex打开如下:

从上面截图可知,数据确实成功写入了,文件也是UNICODE编码格式,但是写入的字符集不是UNICODE编码的,所以记事本打开会出现乱码。
从上面的代码执行结果确实验证了前面的结论:用css指定了文件的编码格式,读写数据的类型一定要用wchar_t类型,否则读写的数据是错误的。
- 当不以
ccs模式打开文件时,写入wchar_t类型数据,代码如下:
#include <stdafx.h>
#include <stdio.h>
void main()
{
FILE *g_LogFile = fopen("D:\\ANSI.log", "w");
int num = 10;
while (--num > 0)
{
//fputws(L"hunan bowan tech 湖南泊湾科技有限公司\n", g_LogFile);
wchar_t szLog[1024] = L"hunan bowan tech 湖南泊湾科技有限公司\n";
fwrite(szLog, 2, wcslen(szLog), g_LogFile);
//char szLog[1024] = "xiaoge is very good 我爱中国\n";
//fwrite(szLog, 1, 20, g_LogFile);
}
fclose(g_LogFile);
}
执行上面代码,用记事本打开文件如下:
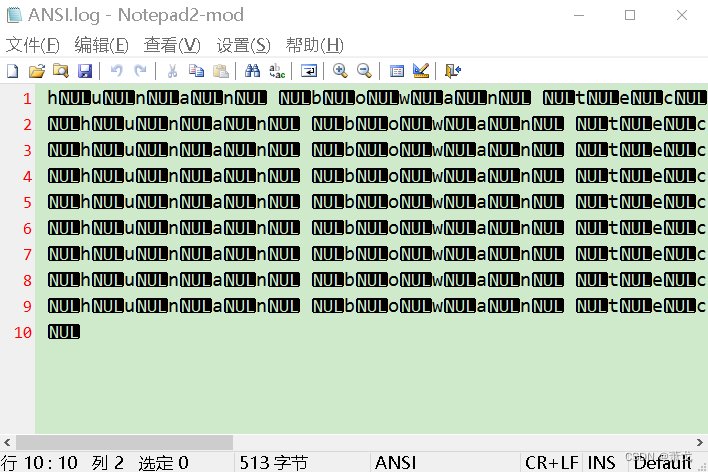
用WinHex打开文件如下:
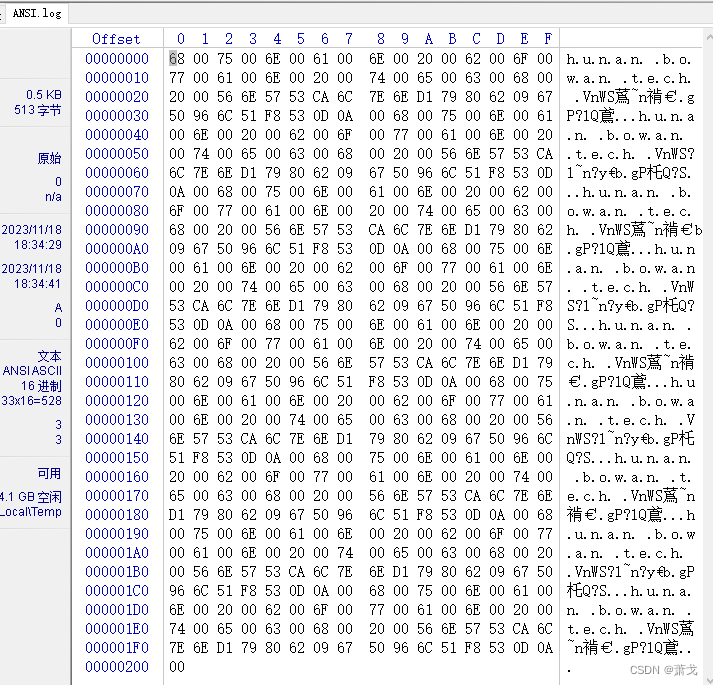
从上面截图可知,文件编码格式为ANSI。由于编码格式和字节流对应不上,所以记事本显示乱码。
如果我们将写入的字节流改为char类型的数据,编码格式和字节流就能对应上,都为ANSI,此时文件显示也没问题。
- 我们将写入文件的模式改为wb方式,文件编码格式将根据我们写入字节流的类型推断出来。
例如,我们用wb的模式写入wchar_t类型数据,代码如下:
#include <stdafx.h>
#include <iostream>
void main()
{
FILE *g_LogFile = fopen("D:\\AUTO.log", "wb");
int num = 10;
while (--num > 0)
{
//fputws(L"hunan bowan tech 湖南泊湾科技有限公司\n", g_LogFile);
wchar_t szLog[1024] = L"hunan bowan tech 湖南泊湾科技有限公司\n";
fwrite(szLog, 2, wcslen(szLog), g_LogFile);
//char szLog[1024] = "hunan bowan tech 湖南泊湾科技有限公司\n";
//fwrite(szLog, 1, strlen(szLog), g_LogFile);
}
fclose(g_LogFile);
}
执行上面代码,用记事本打开文件如下:
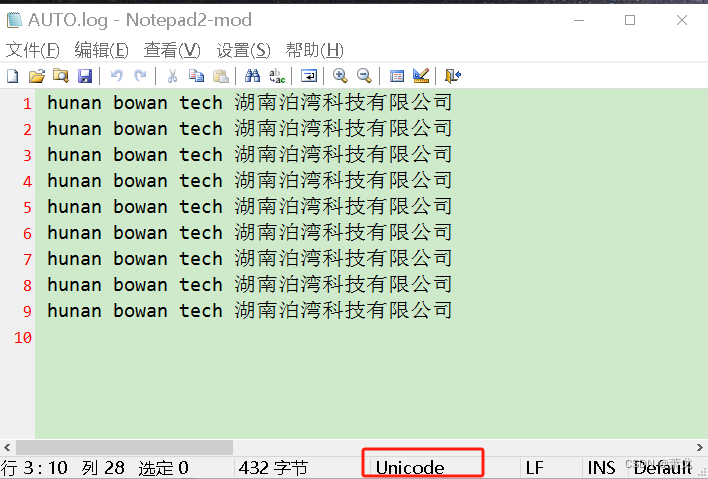
如果我们用wb的模式写入char类型数据,代码如下:
#include <stdafx.h>
#include <iostream>
void main()
{
FILE *g_LogFile = fopen("D:\\AUTO.log", "wb");
int num = 10;
while (--num > 0)
{
//fputws(L"hunan bowan tech 湖南泊湾科技有限公司\n", g_LogFile);
//wchar_t szLog[1024] = L"hunan bowan tech 湖南泊湾科技有限公司\n";
//fwrite(szLog, 2, wcslen(szLog), g_LogFile);
char szLog[1024] = "hunan bowan tech 湖南泊湾科技有限公司\n";
fwrite(szLog, 1, strlen(szLog), g_LogFile);
}
fclose(g_LogFile);
}
执行上面代码,用记事本打开文件如下:
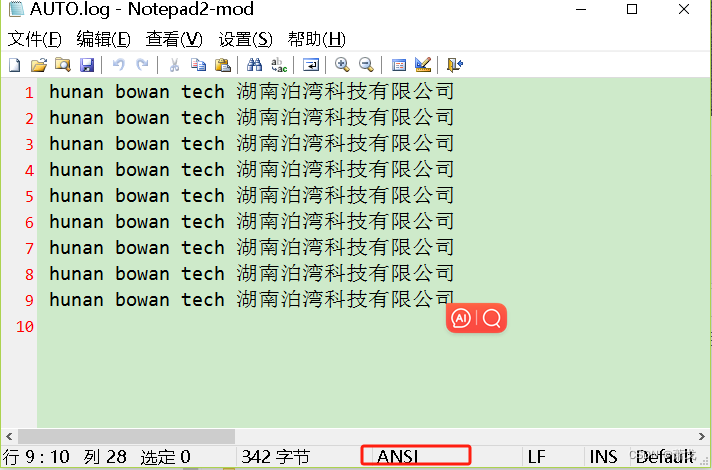
综上所述可知:
如果用"w"的模式,写入wchar_t类型字节数据,最好通过ccs指定编码格式。
否则就用“wb”的模式写入。