k8s_base
应用程序在服务器上部署方式的演变,互联网发展到现在为止 应用程序在服务器上部署方式 历经了3个时代

1. 传统部署 优点简单 缺点就是操作系统的资源是有限制的,比如说操作系统的磁盘,内存
比如说我8G,部署了3个应用程序,当有一天有一个发生内存泄露,就开始吃内存,另外2个占内存就会变小
可能由于第一个程序产生的问题,导致最后2个也不能使用 他们之间有影响
怎么解决 虚拟化部署
我可以在一台物理机上运行多个虚拟机,每一个虚拟机上都有自己的操作系统,这样就解决了应用程序之间的影响
比如说我第一个app部署在第一个虚拟上, 第二个app 部署在第二个虚拟机上,这样的话 我第一个app 就不会影响到了第二个app上
缺点就是我物理机本身就有一个操作系统,你虚拟化之后又有一个操作系统

这些操作系统本身也是要占用一些资源的,而且每个操作系统都有自己的类库,比如说我想部署一个nginx,我的在搞一个操作系统来 在上面跑nginx 你这个操作系统会比nginx还要笨重
进一步优化就是容器化部署,共享了操作系统,他没有了虚拟化,这些程序跑在容器上 没有操作系统了,
处于容器中的程序 他所需要的外界环境是独立的(cpu 内存 进程)
如果在容器中部署一个程序 程序所需要的资源都是由容器提供的,而不是由底层的操作系统提供的
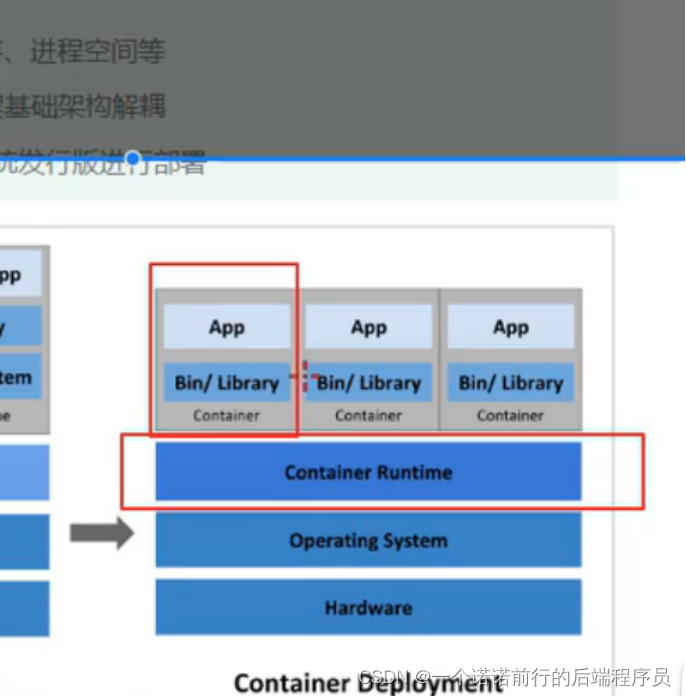
我们的应用程序在服务器上部署方式经过3个时代的演变,最后就是容器化部署
容器化部署遇到的问题
1. 比如说我容器因为宕机了 ,我怎么让另外一个容器去启动做替补
2. 并发大的化 我怎么能做到动态伸缩容
这些都是容器编排的问题 为了解决容器编排的问题 就会有一些容器编排的软件

k8s是一组服务器的集群,他的作用
3. 自我修复 比如说我部署了5个nginx, 有一个nginx 挂了 他就会重新启动nginx,做到自我修复
4. 弹性伸缩 基于流量做到扩缩容
5. 服务发现 比如说 我nginx可以找到mysql
6. 负载均衡 可以分担流量
7. 版本回退 金丝雀发布 比如说新版本有问题了, 我可以回退到老版本上
8. 可以根据容器的自身需求创建存储卷 mysql 的数据可以挂在到外面 我只需要告诉k8s 要多少内存 就可以了

k8s 的本质是服务器的集群
K8s 集群 控制节点和工作节点(每个节点都有不同的组件)
master 控制节点 管理 负责集群的决策管理
node 工作节点 干活的 负责为容器提供运行环境

master节点中
apiService 唯一入口 用户对集群的管理操作都是由apiService 做的,我们可以在apiService做一些访问级别的控制
比如说鉴权
Scheduler:负责集群中资源的调度 比如说我想运行一个nginx 服务 我就得从ApiService发请求,
具体的nginx 在那个Node节点工作,就得决策一下,计算下,根据一定的算法来把这个nginx 放在那个node上
Controller manager 负责执行的 一个ngixn 请求发送到apiService,Scheduler负责计算,此时这个nginx应该运行在node1节点上,然后Controller manager 负责执行
Etcd 负责存储集群中各种资源对象信息,对于master来说 作为控制来讲 这个服务跑在node1 我的知道是在哪里
这些信息全部就记录在etcd中
Node 是真正干活的节点
工作节点上kubectl 控制docker 创建更新
Kubectl 接受master的节点 负责接受控制节点的信息
kubectl 控制docker 吧nignx 跑起来,docker中具体跑的是容器
nginx跑起来 提供对外访问,通过 Kubeproxy 访问
Master节点和node节点各个组件的作用说完毕了

部署一个nginx 来说下 k8s中部署的调用关系 master是负责派活的 node是负责接活的
信息存储在etcd中, Scheduler来计算一下这个请求在node1上执行还是node2上执行
k8s 的集群部署

一主多从中 单机故障风险 节点就是服务器 有可能宕机 比如说master所在的节点down. 整个集群就没有master节点了 整个集群就没有办法工作了 单机故障
由一台服务器引发的整个 集群的故障 只能适用于测试的情况
多诸多从 安全性比较高因为有多个master节点 搭建起来麻烦
我们此时是这样部署的 1 master2 node 因为我们是测试
部署必然讲集群规划
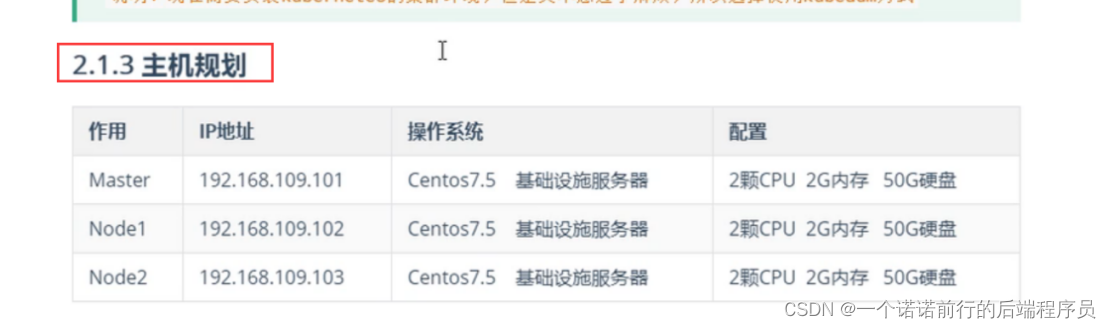 、
、
k8s中各个节点是无法通信的 他的网络没有安装安装网络插件的安装 他还需要安装网络插件

验证这个集群能不能用 我们就让他跑一个nginx程序
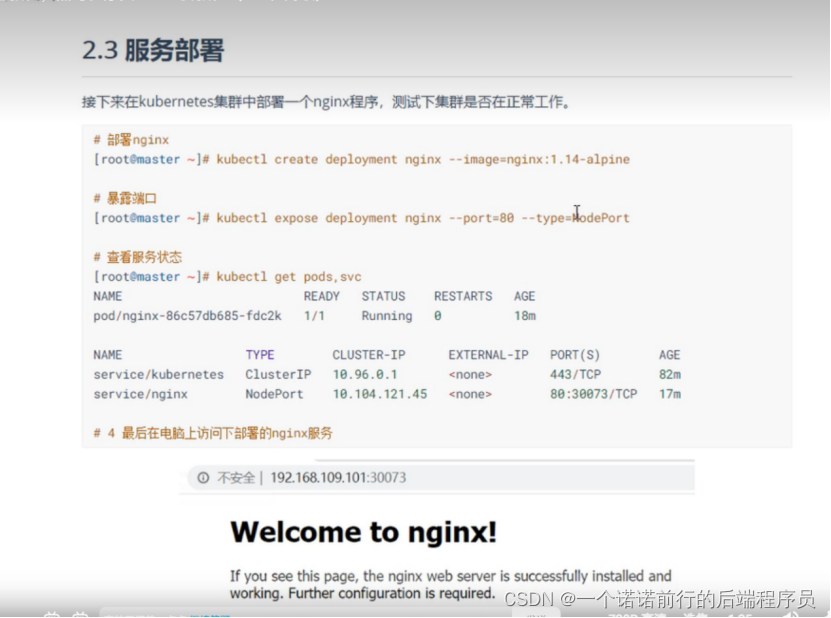
到目前为止我们已经完成一个k8s的集群环境搭建 环境搭建之后跑一个nginx程序