李宏毅2023机器学习作业HW05解析和代码分享
ML2023Spring - HW5 相关信息:
课程主页
课程视频
Sample code
HW05 视频
HW05 PDF个人完整代码分享: GitHub | Gitee | GitCode
运行日志记录: wandbP.S. HW05/06 是在 Judgeboi 上提交的,完全遵循 hint 就可以达到预期效果。
因为无法在 Judgeboi 上提交,所以 HW05/06 代码仓库中展示的是在验证集上的分数。
每年的数据集 size 和 feature 并不完全相同,但基本一致,过去的代码仍可用于新一年的 Homework。
仓库中 HW05 的代码分成了英文 EN 和中文 ZH 两个版本。
(碎碎念:翻译比较麻烦,所以之后的 Homework 代码暂只有英文版本)
任务目标(seq2seq)
- Machine translation 机器翻译,英译中
性能指标(BLEU)
参考链接:
BLEU: a Method for Automatic Evaluation of Machine Translation
Foundations of NLP Explained — Bleu Score and WER Metrics
BLEU(Bilingual Evaluation Understudy) 双语评估替换
公式:
BLEU
=
B
P
⋅
exp
(
∑
n
=
1
N
w
n
l
o
g
p
n
)
1
N
\text{BLEU} = BP \cdot \exp\left( \sum_{n=1}^{N} w_n log\ p_n\right)^{\frac{1}{N}}
BLEU=BP⋅exp(n=1∑Nwnlog pn)N1
首先要明确两个概念
-
N-gram
用来描述句子中的一组 n 个连续的单词。比如,“Thank you so much” 中的 n-grams:- 1-gram: “Thank”, “you”, “so”, “much”
- 2-gram: “Thank you”, “you so”, “so much”
- 3-gram: “Thank you so”, “you so much”
- 4-gram: “Thank you so much”
需要注意的一点是,n-gram 中的单词是按顺序排列的,所以 “so much Thank you” 不是一个有效的 4-gram。
-
精确度(Precision)
精确度是 Candidate text 中与 Reference text 相同的单词数占总单词数的比例。 具体公式如下:
$ \text{Precision} = \frac{\text{Number of overlapping words}}{\text{Total number of words in candidate text}} $
比如:
Candidate: Thank you so much, Chris
Reference: Thank you so much, my brother
这里相同的单词数为4,总单词数为5,所以 Precision = 4 5 \text{Precision} = \frac{{4}}{{5}} Precision=54
但存在一个问题:-
Repetition 重复
Candidate: Thank Thank Thank
Reference: Thank you so much, my brother此时的 Precision = 3 3 \text{Precision} = \frac{{3}}{{3}} Precision=33
-
解决方法:Modified Precision
很简单的思想,就是匹配过的不再进行匹配。
Candidate: Thank Thank Thank
Reference: Thank you so much, my brother
Precision 1 = 1 3 \text{Precision}_1 = \frac{{1}}{{3}} Precision1=31
-
具体计算如下:
C o u n t c l i p = min ( C o u n t , M a x _ R e f _ C o u n t ) = min ( 3 , 1 ) = 1 Count_{clip} = \min(Count,\ Max\_Ref\_Count)=\min(3,\ 1)=1 Countclip=min(Count, Max_Ref_Count)=min(3, 1)=1
$ p_n = \frac{\sum_{\text{n-gram}} Count_{clip}}{\sum_{\text{n-gram}} Count} = \frac{1}{3}$
现在还存在一个问题:译文过短
Candidate: Thank you
Reference: Thank you so much, my brother
p 1 = 2 2 = 1 p_1 = \frac{{2}}{{2}} = 1 p1=22=1
这里引出了 brevity penalty,这是一个惩罚因子,公式如下:
B P = { 1 if c > r e 1 − r c if c ≤ r BP = \begin{cases} 1& \text{if}\ c>r\\ e^{1-\frac{r}{c}}& \text{if}\ c \leq r \end{cases} BP={1e1−crif c>rif c≤r
其中 c 是 candidate 的长度,r 是 reference 的长度。
当候选译文的长度 c 等于参考译文的长度 r 的时候,BP = 1,当候选翻译的文本长度较短的时候,用 e 1 − r c e^{1-\frac{r}{c}} e1−cr 作为 BP 值。
回到原来的公式:$ \text{BLEU} = BP \cdot \exp\left( \sum_{n=1}^{N} w_n log\ p_n\right)^{\frac{1}{N}}$,汇总一下符号定义:
- B P BP BP 文本长度的惩罚因子
- N N N n-gram 中 n 的最大值,作业中设置为 4。
- w n w_n wn 权重
- p n p_n pn n-gram 的精度 (precision)
数据解析
- Paired data
- TED2020: 演讲
- Raw: 400,726 (sentences)
- Processed: 394, 052 (sentences)
- 英文和中文两个版本
- TED2020: 演讲
- Monolingual data
- 只有中文版本的 TED 演讲数据
Baselines
这里存在一个问题,就是HW05是在 Judgeboi 上进行提交的,所以没办法获取最终的分数,所以简单的使用 simple baseline 对应的 validate BLEU 来做个映射。
因为有 EN / ZH 两个版本,对于每个 hint 我会给出代码的修改位置方便大家索引。
Simple baseline (15.05)
- 运行所给的 sample code
Medium baseline (18.44)
- 增加学习率的调度 (
Optimizer: Adam + lr scheduling/优化器: Adam + 学习率调度) - 训练得更久 (
Configuration for experiments/实验配置)
这里根据预估的时间,可以简单的将 epoch 设置为原来的两倍。
Strong baseline (23.57)
- 将模型架构转变为 Transformer (
Model Initialization/模型初始化) - 调整超参数 (
Architecture Related Configuration/架构相关配置)
这里需要参考 Attention is all you need 论文中 table 3 的 transformer-base 超参数设置。
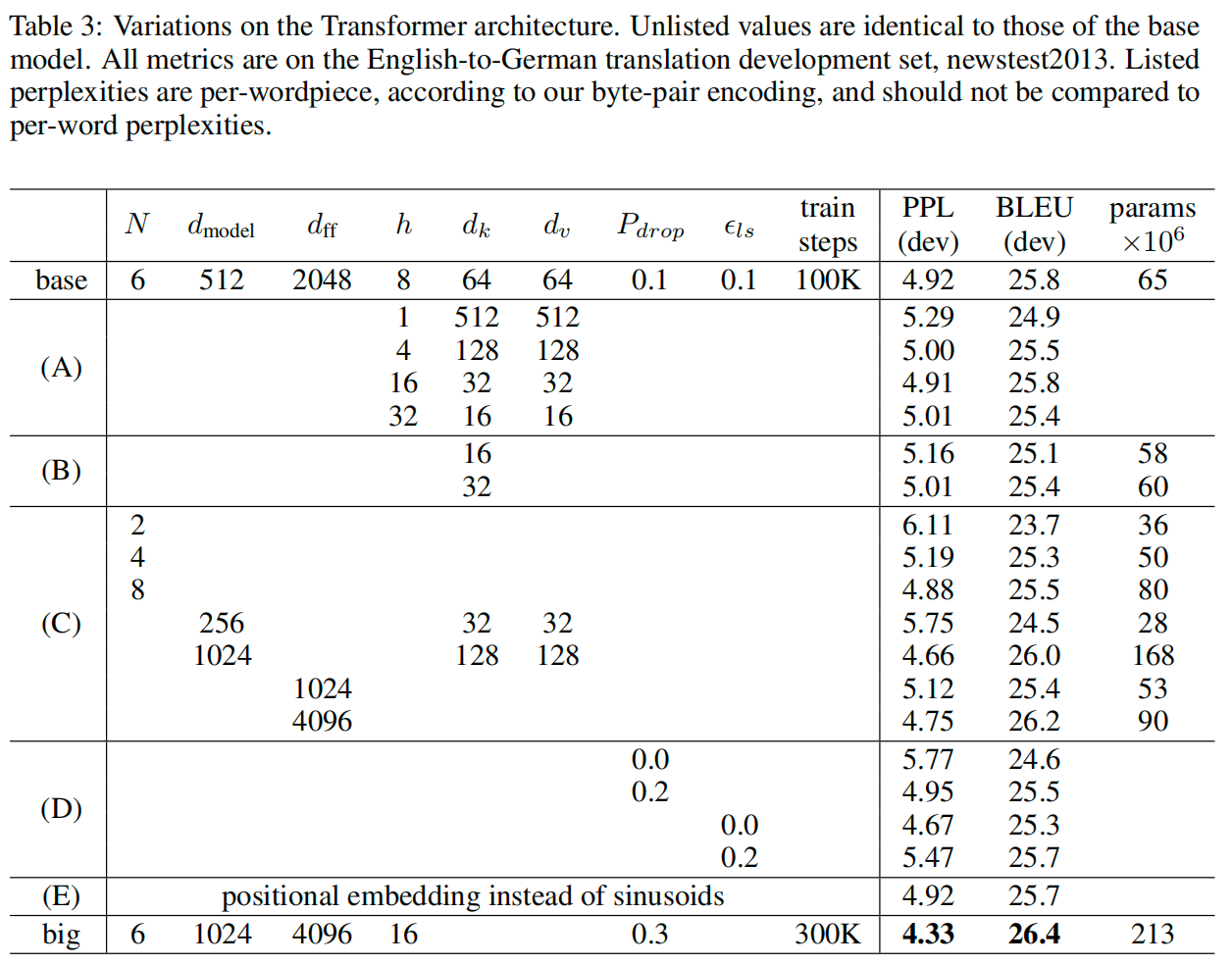
你可以仅遵循 sample code 的注释,将 encoder_layer 和 decoder_layer 改为 4(简单的将这一个改动称之为 transformer_4layer),此时模型的参数数量会和之前的 RNN 差不多,在 max_epoch =30 的情况下,Bleu 可以达到 23.59。
代码仓库中分享的 Strong 代码完全遵循了 transformer-base 的超参数设置,此时的模型参数将约为之前 RNN 的 5 倍,每一轮训练的时间约为 transform_4layer 的三倍,所以我将 max_epoch 设置为了 10,让其能够匹配上预估的时间,此时的 Bleu 为 24.91。如果将 max_epoch 设置为 30,最终的 Bleu 可以达到 27.48。
下面是二者实验对比。
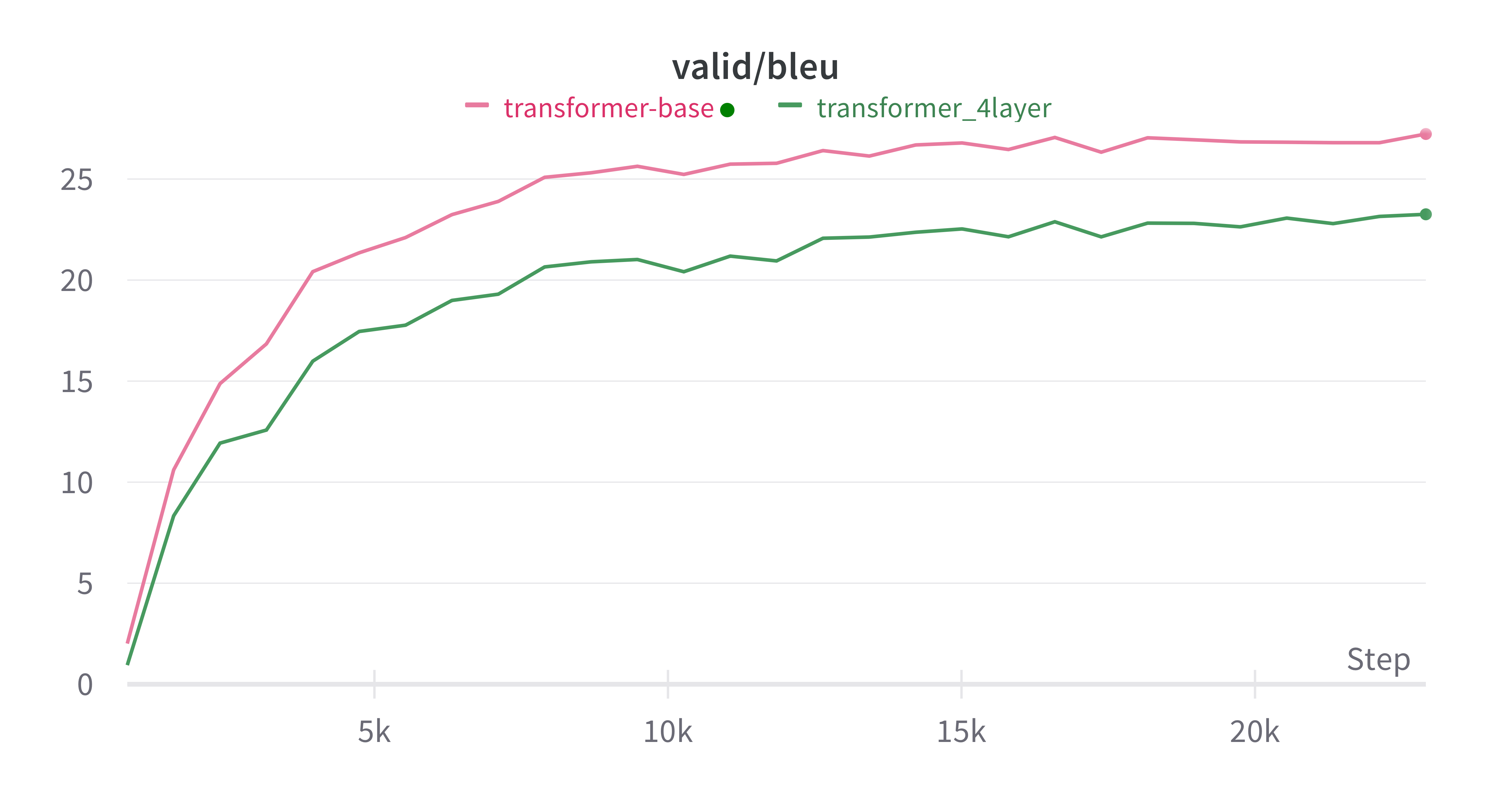
Boss baseline (30.08)
-
应用 back-translation (
TODO)这里我们需要交换实验配置 config 中的 source_lang 和 target_lang,并修改 savedir,训练一个 back-translation 模型后再修改回原来的 config。
然后你需要将 TODO 的部分完善,修改并复用之前的函数就可以达到目的。
(为了与预估时间匹配,这里将 max_epoch 设置为 30 进行实验。)
代码仓库中分享的 Boss 代码展示的是最终训练的结果,完整的运行流程是:
- 将
实验配置中/Configuration for experiments的 BACK_TRANSLATION 设置为 True 运行
训练一个 back-translation 模型,并处理好对应的语料。 - 将
实验配置/Configuration for experiments中的 BACK_TRANSLATION 设置为 False 运行
结合 ted2020 和 mono (back-translation) 的语料进行训练。
Gradescope
Visualize Positional Embedding
你可以直接在 确定用于生成 submission 的模型权重 / Confirm model weights used to generate submission 后进行处理,在仓库的代码中我已经提前注释掉了 训练循环 / Training loop 中的训练部分,如果在之前,模型没有训练,直接运行代码会报错。
添加的处理代码如下(可以复制下面的处理代码放到你的 submission 模块之后):
推荐阅读:All Pairs Cosine Similarity in PyTorch
pos_emb = model.decoder.embed_positions.weights.cpu().detach()
# 计算余弦相似度矩阵
def get_cosine_similarity_matrix(x):
x = x / x.norm(dim=1, keepdim=True)
sim = torch.mm(x, x.t())
return sim
sim = get_cosine_similarity_matrix(pos_emb)
#sim = F.cosine_similarity(pos_emb.unsqueeze(1), pos_emb.unsqueeze(0), dim=2) # 一样的
# 绘制位置向量的余弦相似度矩阵的热力图
plt.imshow(sim, cmap="hot", vmin=0, vmax=1)
plt.colorbar()
plt.show()
Clipping Gradient Norm
只需要将 config.wandb 设置为 True 即可,此时可以在 wandb 上查看。
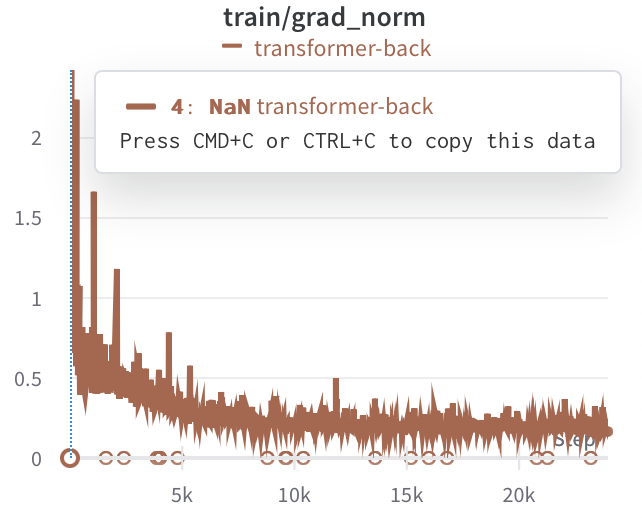
或者直接在 train_one_epoch 添加一下处理代码,记录 gnorm。
