MongoDB随记
MongoDB
- 1、简单介绍
- 2、基本术语
- 3、shard分片概述
- 背景
- 架构
- 路由功能
- chunk(数据分片)
- shard key(分片键值)
- 4、常用命令
1、简单介绍
MongoDB是一个分布式文件存储的数据库,介于关系数据库和非关系数据库之间,支持的数据结构类型为BSON,类似于JSON。MongoDB中的记录是一个document,由字段和值对组成的数据结构。
MongoDB适合在数据量大,读写频繁,对事务性要求不高的场景应用。
2、基本术语
- database:数据库
- collection:表
- document:一条数据
- field:字段
- index:索引
3、shard分片概述
分片(sharding)是 MongoDB 用来将大型集合分割到不同服务器(或者说一个集群)上所采用的方法。
背景
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力,大的查询量会将单机的CPU耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存而将压力转移到磁盘IO上。为了解决这些问题,有两个基本的方法: 垂直扩展和水平扩展。垂直扩展:增加更多的CPU和存储资源来扩展容量。水平扩展:将数据集分布在多个服务器上。水平扩展即分片。
分片为应对高吞吐量与大数据量提供了方法。使用分片减少了每个分片需要处理的请求数,因此,通过水平扩展,集群可以提高自己的存储容量和吞吐量。举例来说,当插入一条数据时,应用只需要访问存储这条数据的分片。而且当某个shard的负载超过一定阙值后,就会自动的重新分发数据,用来保证系统的负载均衡。
架构
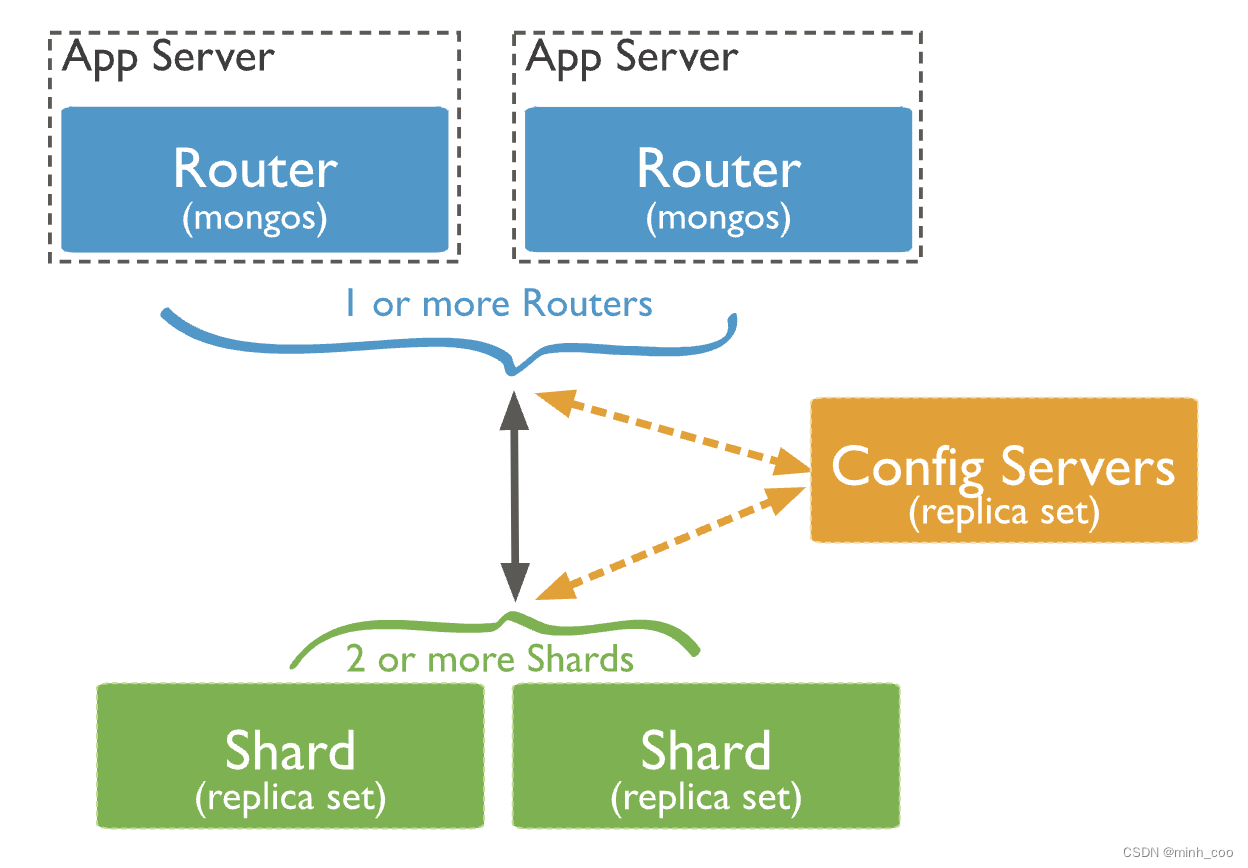
-
shard:分片,数据的真正存储位置,以chunk为单位存数据。
-
mongos:数据路由,和客户端打交道的模块。提供对外应用访问,所有操作均通过mongos执行
mongos本身没有任何数据,他也不知道该怎么处理这数据,会去找config server。
-
config server:存储元数据和所有shard节点的信息,分片功能的一些配置信息。
Mongos本身并不持久化数据,Sharded cluster所有的元数据都会存储到Config Server,而用户的数据会议分散存储到各个shard。Mongos启动后,会从配置服务器加载元数据,开始提供服务,将用户的请求正确路由到对应的碎片。
路由功能
-
当数据写入时,MongoDB Cluster根据分片键设计写入数据。
-
当外部语句发起数据查询时,MongoDB根据数据分布自动路由至指定节点返回数据。
chunk(数据分片)
在一个shard server内部,MongoDB还是会把数据分为chunks,每个chunk代表这个shard server内部一部分数据。chunk的产生,会有以下两个用途:
Splitting:当一个chunk的大小超过配置中的chunk size时,MongoDB的后台进程会把这个chunk切分成更小的chunk,从而避免chunk过大的情况
Balancing:在MongoDB中,balancer是一个后台进程,负责chunk的迁移,从而均衡各个shard server的负载,系统初始1个chunk,chunk size默认值64M,生产库上选择适合业务的chunk size是最好的。ongoDB会自动拆分和迁移chunks。
shard key(分片键值)
MongoDB 中数据的分片是以集合为基本单位的,集合中的数据通过片键(Shard key)被分成多部分。其实片键就是在集合中选一个键,用该键的值作为数据拆分的依据。
片键必须是一个索引。
对集合进行分片时,你需要选择一个片键,片键是每条记录都必须包含的,且建立了索引的单个字段或复合字段,MongoDB按照片键将数据划分到不同的数据块中,并将数据块均衡地分布到所有分片中。
MongDB查询结果按照shard key排列,且每一shard中按索引有序排列。
4、常用命令
show dbs # 查看所有数据库
use [database] # 选择某一数据库
show tables # 查看数据库中的所有表
db.[collection].find() # 查看某一集合的数据
db.[collection].find({"id":{$regex:"^a*"}}) # 正则查询,^:表示匹配字符串开头;*:匹配任意字符;$:表示匹配字符串结尾
db.[collection].find().limit() # 限制查询结果条数
db.[collection].find({}, {id:1, name:1}) # 限制返回结果字段只有id和name
db.[collection].insert({}) # 插入一条数据
db.[collection].update({"id":"123456"}, {$set:{"name":"minh"}}) # 更新id为123456的name字段值为minh
db.[collection].sort() # 对查询结果按某字段排序
pretty() # 查询结果进行格式化处理
findOne() # 查询单条数据
db.[collection].remove({"name":"minh"}) # 删除数据
db.[collection].find().hint({name:1}) # 强制使用某个索引查询
$and $or
示例:
show dbs
use books
show tables
use literature
db.literature.find()
db.literature.findOne()
db.literature.find().pretty()
db.literature.find().sort()
db.literature.find().hint({name:1})
db.literature.find().limit(10)
db.literature.find({"name":"WeThree"})
db.literature.find({"name":"WeThree"}, {name:1, author:1, price:1})
db.literature.find({$and:[{"name":"WeThree"}, {"price": {$gte: 30}}]})
db.literature.find({$or:[{"name":"WeThree"}, {"name": "homeless"}]})
db.literature.find({"name": {$in : ["a", "b", "c"]}})
db.literature.insert({id:"2", name:"name", author:"minh", price:NumberInt(66), date:NumberLong(12345678)})
db.literature.update({name:"name"}, {$set: {name:"minh"}})
db.literature.remove({id:"2"})
参考:
https://www.mongodb.com/docs/manual/sharding/
https://zhuanlan.zhihu.com/p/598892366