分库分表
分库,分表,分库分表
“只分库“,“只分表“,“既分库又分表"
何时分库
在面对高并发的情况下,数据库连接成为性能瓶颈。当数据QPS过高导致数据库连接数不足时,考虑分库。在读多写少的场景下,增加多个从库或使用分库方法,实现数据库的高可用。
避免大量数据集中访问在单台机器上,对磁盘IO、CPU负载造成过大压力,影响性能。
分库与添加Slave机器的关系
-
添加Slave机器:
- 读写分离:通过添加Slave机器实现主从复制,将读操作分散到多个机器上,减轻主库的读压力。
- 提高查询性能:Slave机器可处理大量只读查询。
- 异步复制:主库执行后,数据会异步复制到Slave机器上,可能导致一定延迟。
-
分库:
- 水平扩展:分库可将数据划分到不同数据库实例中,每个实例负责一部分数据,可通过在同一服务器实例中运行不同数据库实例或在不同服务器上运行不同db实例实现。
如进行微服务拆分,把单一数据库拆到不同的数据库当中
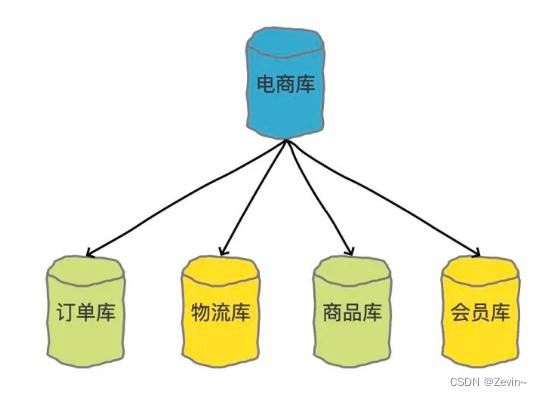
什么时候分表
分表解决数据量大的情况。当单表数据量非常大、并发量不高、数据连接足够但存储和查询遇到瓶颈时,需减少单表数据量,提高速度。通常在单表行数超过500万行或单表容量超过2GB后,考虑分库分表。

何时既分库又分表
解决并发量和数据量都很大的情况。通常,高并发和大数据量同时发生,因此经常遇到分库分表的情况。当数据库连接不足、同时单表数据量很大、查询速度很慢时,需要进行分库分表。
水平拆分和垂直拆分
- 垂直拆分: 将表中某记录的多个字段拆分到多个表中。
- 水平拆分: 将一张表中不同记录分别放到不同表中,减少单表数据。
水平拆分。把不同的用户的订单分表拆分到不同的表中,每个表中维护一些记录
垂直拆分减少字段数,使每个单表数据存储减少;水平拆分将不同用户的订单分表,每表维护一些记录。
分表的字段选择
分表的字段决定了数据如何在不同的分表中的划分和存储,比如按用户分表,按时间分表,按地区分表,这里面的用户,时间,地区就是分表的字段
需要注意的是(按照买家进行分表是把所有相同的买家信息放在同一张表中,而不是一个买家一个表)
- 用户ID:按照用户ID分表,将同一个用户的数据分到同一个分表,便于按用户进行查询,这样方便避免热点数据的数据倾斜,同时方便进行水品扩张,将新的买家的数据分布到新的分表中,不影响已有的分表
- 时间:按照时间进行分表,按照年,月,日等,使用在按时间范围查询场景,方便后期的数据清理
- 地区:按照地区分表,适用于有地域数据的数据
卖家查询怎么办
我们一般都是使用买家ID来实现分表,避免某些大卖家的大量数据导致数据倾斜的问题
但是买家查询很方便,那么卖家如何查询呢
由于卖家可能会涉及到多个买家的表,如果直接在分表中查询就会涉及到跨表查询,影响性能,为了解决这个问题,就提出了同步一张卖家维度的表,这张表只用来查询,而不涉及写操作,卖家ID同样可以可以定位到这个卖家维度的表
我们可以使用binlog 或者Flink等同步方案,将写入买家的数据同步到卖家维度的表中,直接在这个卖家维度的表中查询,而不需要进行跨表查询
由于卖家表只用来查询,所以可以使用一些高性能db,如HBase,PolarDB满足大查询量的需求
全局ID的生成
涉及到分库分表,就会引申出分布式系统的唯一主键ID的生成问题,因为在单表中我们可以使用数据库主键来做唯一的ID,但是做了分库分表,多张单表中的自增主键就一定会冲突,就不具有唯一性了
雪花算法
雪花算法具有全局唯一、递增、高可用的特点:
-
1位符号位: 表示正负,通常这个位没有特殊用途。
-
41位时间戳位: 精确到毫秒,可以容纳约69年的时间。表示当前时间戳,通常为当前值减去一个固定的起始时间戳。
-
10位机器ID: 高5位是数据中心ID,低5位是工作节点ID,最多可以容纳1024个节点,确保在同一个时间戳内,不同的机器生成不同的ID。
-
12位序列号位: 表示在同一时间戳和机器ID下的序列号,每个节点每毫秒从0开始不断累加,递增到4095。因此,雪花算法在同一毫秒内最多生成1024 * 4096个唯一的ID。