从一到无穷大 #19 TagTree,倒排索引入手是否是优化时序数据库查询的通用方案?
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 文章主旨
- 时序数据库查询的一般流程
- 扫描
- 维度聚合
- 时间聚合
- 管控语句
- TagTree
- 整体结构
- 索引结构
- 可能的问题
- 测试
文章主旨
文章针对的问题点在于现有的倒排索引实现在高基数的情况下性能较差,现有方法问题如下:
- 使用外部数据库管理tag信息时,时间序列数据库需要为每次用户查询向外部数据库发送请求,从而大大增加了tag查询延迟。
- 将tag索引与时间序列数据一起存储在多个时间分段文件中,每个数据段包含一个时间窗口中的所有时间序列数据以及将时间序列映射到数据的倒排索引,此时跨越多个时间窗口的时间序列元数据将存储在多个时间段中,从而导致元数据重复。这种重复的元数据会带来巨大的内存消耗和 I/O 开销以及多个分段的额外搜索开销。
文章的主要思想是设计一个全局共享的倒排索引,与时间分区方法相比,内存消耗和存储空间占用可以大大减少,此外倒排索引在内部进行了时间分区。对于每个tag,seriesId被分为多个分区,每个分区对应一个时间段,时间段本身也被编码在key中,这意味着对于多个时间段的查询可以很好的利用B+树的有序特性,元数据的扫描只需要一次;对于单次的查询也可以根据查询时间范围快速定位所需的分区,避免稀疏数据带来的额外扫描数据的开销(不做时间分区可能存在大量时间线指定时间区间内无数据)。
时序数据库查询的一般流程
以influxdb引擎举例子,引擎侧查询侧涉及TSI(基于Predicate筛选SeriesID),SeriesFile(基于SeriesID获取原始SerieKey)和TSM(基于SeriesID扫描压缩后的数据)三个结构。而不同的sql涉及的瓶颈则各不相同,举几个例子:
扫描
select field1,field2 from car where “taga” = ‘lizhaolong’
select aggregate(field1) from car where “taga” = ‘lizhaolong’
select selector(field1) from car where “taga” = ‘lizhaolong’
此时查询的开销基本集中在TSI和TSM,且大概率集中在TSM,但是也于数据本身的稀疏程度,基数有关
维度聚合
select field1,field2 from car where “taga” = ‘lizhaolong’ group by tagb
select aggregate(field1) from car where “taga” = ‘lizhaolong’ group by tagb
select selector(field1) from car where “taga” = 'lizhaolong group by tagb
通过TSI获取此次查询涉及到的SeriesIDSets后,需要基于SeriesID反查SeriesFile获取实际的tag组合,最后扫描数据
数据的稀疏程度,基数,写入流程中涉及到的时间线分布(影响反查SeriesFile)
时间聚合
select field1,field2 from car where “taga” = ‘lizhaolong’ group by tagb, time(12m)
select aggregate(field1) from car where “taga” = ‘lizhaolong’ group by tagb, time(12m)
select selector(field1) from car where “taga” = 'lizhaolong group by tagb, time(12m)
在之前的基础上,此时CPU的计算可能成为瓶颈,因为涉及到大量数据的聚合计算
管控语句
show tag values
show series cardinality
此时瓶颈基本存在在TSI查询和SeriesIDs的合并流程(虽然基于RoaringBitmap的合并很快,但是有时仍旧会成为瓶颈)
TagTree
从上一节可以看到,工程上的查询优化的流程并不是简单的替换某个结构就可以完成的,因为基于不同的条件,查询的瓶颈并不相同,所以对于结构的修改一般非常谨慎,我们需要衡量其优势和劣势,并针对于业务的场景做决策。
回到论文本身,TagTree的思路其实非常简洁,即通过合并多个时间分片中的倒排索引结构,并实现高效的B+树,和定期与磁盘结构合并的内存索引,以做到:
- 去除磁盘上重复的元数据存储
- 去除查询多个时间分片中倒排索引带来的内存消耗, I/O 开销以及额外搜索开销
- 写入性能不受影响
整体结构
优点看完了,我们来过一遍TagTree的设计,思考这样做可能存在的问题:

整体的设计有三个地方比较重要:
- symbol table is a list of all strings that appear in the tags to reduce space overhead for duplicate strings.
- The memory index and the index tree implement the inverted index which finds series IDs by tag sets.
- The series manager contains a list of series entries that hold the metadata for each time series.
基于这里可以看出设计tagTree的团队至少已经意识到了tagkey/tagvalue本身带来的磁盘空间占用问题,所以引入symbol table,这里我认为可以理解为字典化减少存储开销
其次可以看到Index Tree和Series Manager的实现是基于Page cache的,而不是基于mmap,这样的好处我已经不想说了,influxdb使用mmap的行为目前来看实在是架构上最为错误的决定,带来了性能上的致命缺陷,而自己管理page cache和淘汰才是最优方案。

文中把倒排索引看作一个键值存储,那键的编码自然非常重要,文中认为每个唯一键都可以代表一个这个tag组合的SeriesSets的一个分段。
键本身分为四个部分:
- tagkey的哈希值
- tagvalue的哈希值
- 分区的起始时间戳
- segment selector
key编码中加入时间最大的优势是查询中的Predicate在KeyNameSpace中被编码为一个区间,这个区间包含某个Predicate涉及的所有时间区间可以被一次B+树的查询找到起始点,随后利用B+树的有序优势,迅速索引到剩下的时间区间。
segment selector的概念其实是因为tagTree希望利用到seriesID到有序特性,SeriesSets在磁盘中采用bitmap存储,这样一个4kb的页可以存储32k个seriesID,但是因为seriesID本身是有序的,而tagTree全局唯一后SeriesID的分配也必将全局唯一,这样就导致伴随着时间的移动,可能存在一大片区间bitmap中永远为0,所以可以把SeriesSet的存储划分为N段,分段 1 涵盖 ID 为 0 至 32k 的时间序列,分段 2 涵盖 32k 至 64k 的时间序列,tagTree使用最低两个字节来指代SeriesSet的特定段,这意味着tagTree最多可以支持2^16*32k=2147450880的时间线上限,基本已经足够,但是我想说这样的做法不一定更节省存储(极端情况需要用4kb代表一个时间序列),而且以时序数据库的磁盘利用率来看这里也并不是瓶颈。
当然SeriesSets的页面还存储了这个tagkey对应在符号表中的引用,为了正则操作可以正确的进行。
从架构来看,Series Manager也是TagTree很重要的模块,功能可以类比influxdb中的SeriesFile,但是文中只是提了寥寥几笔,可以理解为这里的实现没有什么创新点,但是也同时可以看到series-cache的概念已经被用于非常多的时序数据库(Lindorm)。
The series manager contains a list of series entries and each entry is a tuple of the series ID of a time series and its tag set. The series entries are stored on the disk and the series manager maintains a series-cache in the memory to accelerate the access to the most recent time series. The series manager also handles loading series entries from the disk.
索引结构
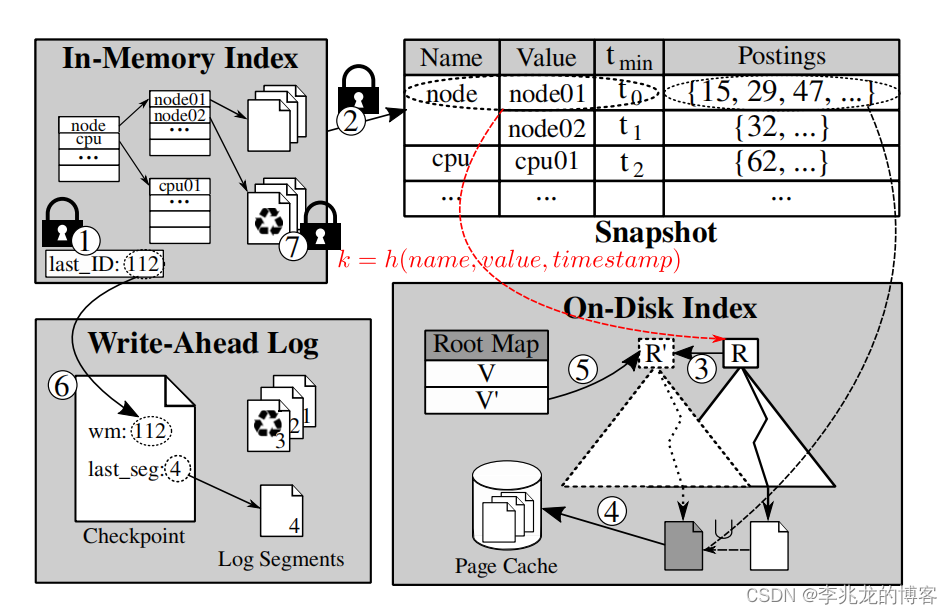
索引本身的实现的高效依赖于copy-on-write B±tree,它以一种存储效率高的格式存储索引数据,但只支持通过内存组件进行分批插入。
内存中的结构不必多说,tagkey->tagvalue->SeriesSets,这里需要的是一个内存友好的倒排索引,在内存到达阈值后触发异步索引合并流程
异步索引合并对张贴列表页和树节点页都采用了写时复制的方法。
对于每个tag组合都需要顾及seriesSet的大小(前文提到是用segment selector+bitmap实现的),其次确定最小时间戳,与现有B+数中的分段执行合并后写入 shadow pages,随后从根节点开始修改PageID指向,创建新版本的copy-on-write tree。
新的时间序列已经被保留在磁盘,就可以截断WAL,丢弃内存数据,从而将内存索引的大小保持在阈值以下。
可能的问题
事实上优化思路是没错的,工程不是学术,对于一个新结构我们最关心的是这个特性的普适程度以及各种负载下的稳定性,目前看到的问题有这些:
- 现有的云数据库全面拥抱Parquet(IotDB tsfile)不是没道理的,分离索引设计带来的性能/存储开销一般来看不是性能瓶颈,反而带来了允许批量导入的极大优势,合并倒排索引后基本上断了批量导入就只能慢慢悠悠的写数据了,就连打包迁移都不好做。
- Copy-on-write B+树本身的问题,
a. 数据一致性: 在高并发环境中,读取操作可能会遇到数据一致性问题。虽然COW策略可以减少锁的使用,但在写操作发生时,读操作可能会读到旧的数据,因为它可能在新数据被完全写入之前就已经开始了。
b. 内存使用: 由于COW需要在写操作时复制节点,这可能会导致内存使用的短暂增加,尤其是在大量写操作发生时。
c. 稳定的实现需要时间 - 优化的仅仅是TSI的查询部分,大多数查询语句瓶颈不在这里
测试
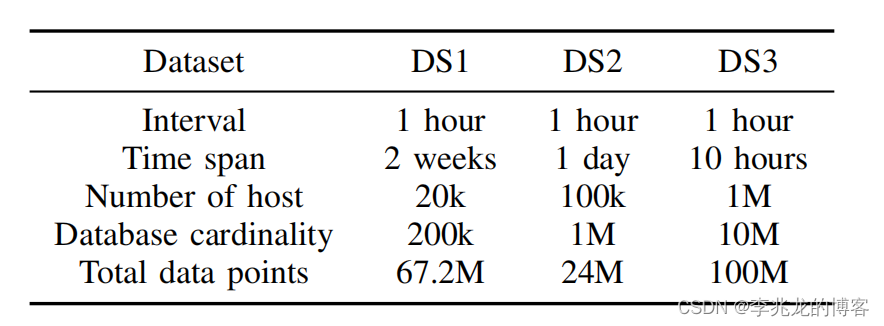
- Q1 (single-groupby-1-1-1): Select one metric for one host (point query).
- Q2 (cpu-max-all-1): Find all metrics for one host.
- Q3 (single-groupby-1-8-1): Find one metric for each of 8 hosts.
- Q4 (cpu-max-all-8): Find all metrics for 8 hosts.
- Q5 (single-groupby-5-8-1): Find 5 metrics for each of the 8 hosts.
- Q6: cpu{ metric !=“usage user”} This query selects time series for all CPU usages except usage user for all hosts. This query selects 90% of all time series in the database. This query is to test the performance of range queries with a large result set.
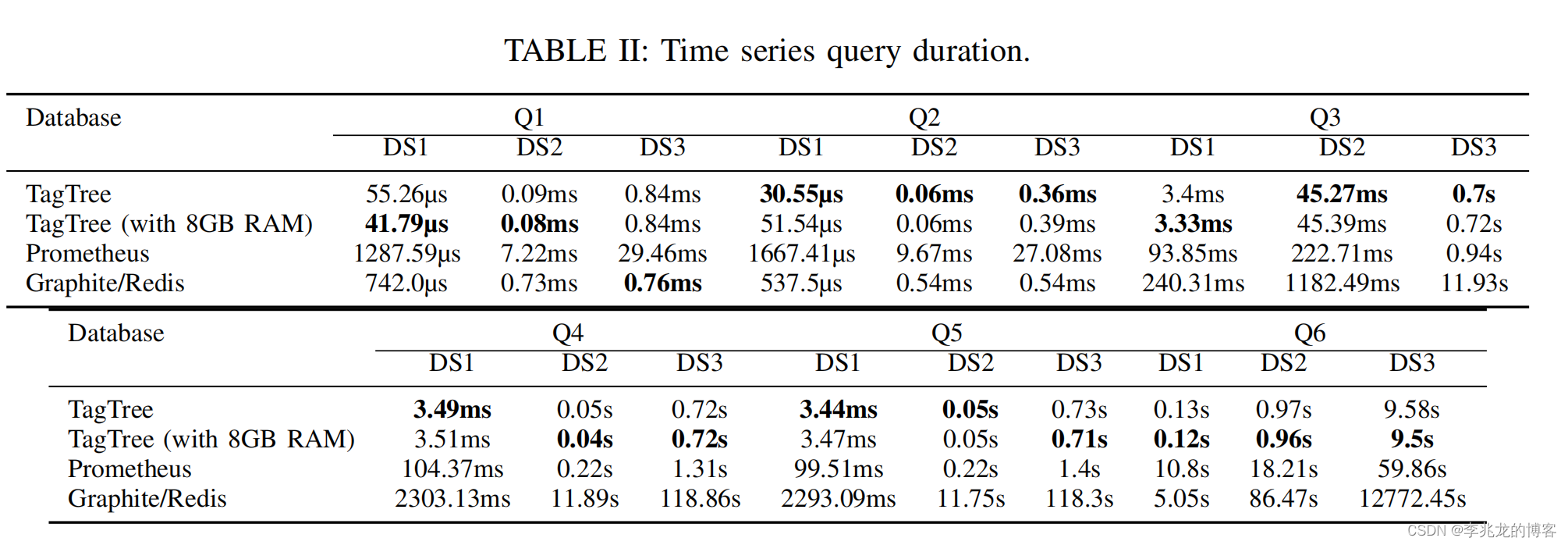
tagTree在时间跨度较长,Predicate涵盖范围较多,数据量较少,数据集不稀疏,计算较少,性能相对于一般倒排索引结构会有显著提升,显然测试中的case就是这样。
参考:
- Reducing the storage overhead of main-memory oltp databases with hybrid indexes sigmod 2016
- Db2 Event Store,A Purpose-Built IoT Database Engine
- ByteSeries: an in-memory time series database for large-scale monitoring systems
- TagTree: Global Tagging Index with Efficient Querying for Time Series Databases