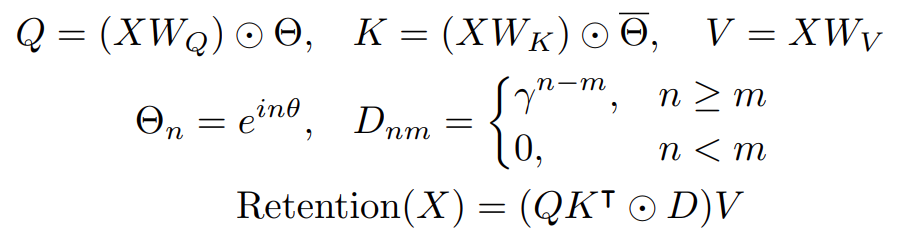论文阅读——RetNet
transformer的问题:计算量大,占用内存大,不好部署。
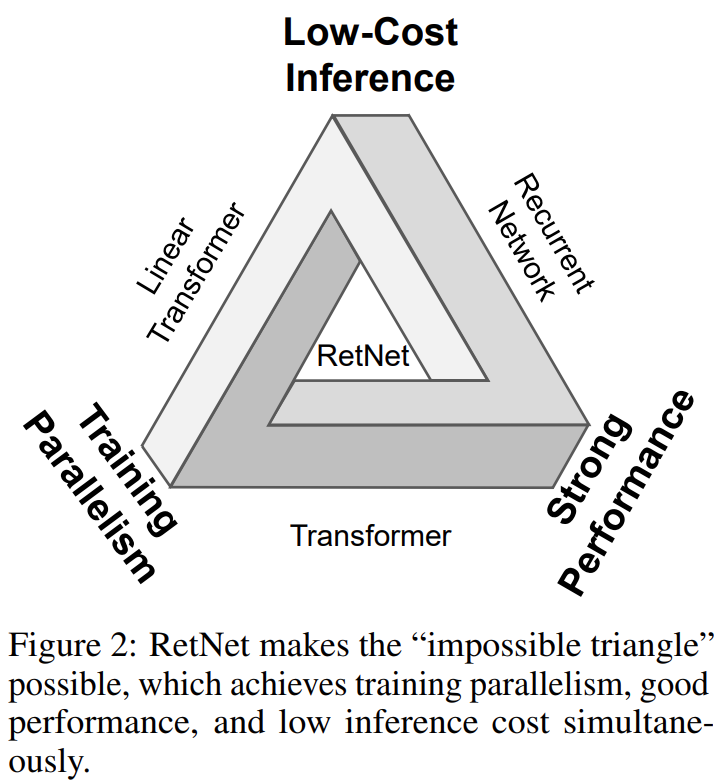
所以大家在找能解决办法,既能和transformer表现一样好,又能在推理阶段计算复杂度很低。
这些方法大概分类三类:一是代替transformer非线性注意力机制的线性注意力,二是牺牲并行训练,但是推理效率高的循环模型,三是寻找一种其他机制代替注意力机制。但是都不成功。
RetNet整体结构:
![]()

![]()
X是每层的输入序列,LN是LayerNorm
MSR:multi-scale retention
RetNet是L个单独模块堆叠,每个模块包含MSR和FFN两部分。
考虑循环模型序列建模问题,可以表示为:
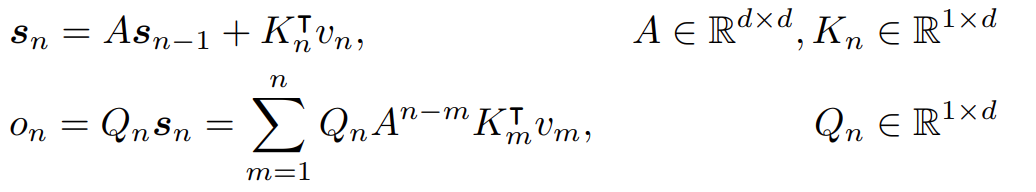
其中,Sn是隐层,Vn是输入。
![]()
![]()
![]()
![]()
By absorbing A into WQ and WK,把方程写为:

γ简化为标量:
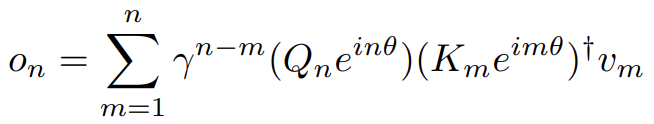
retention layer定义为: