034、test
之——全纪录
目录
之——全纪录
杂谈
正文
1.下载处理数据
2.数据集概览
3.构建自定义dataset
4.初始化网络
5.训练
杂谈
综合方法试一下。
leaves
1.下载处理数据
从官网下载数据集:Classify Leaves | Kaggle
解压后有一个图片集,一个提交示例,一个测试集,一个训练集。
images,27153个树叶图片:

test.csv,8800个:
train.csv,18353个:

2.数据集概览
训练集、测试集、类别:
#导包
import random
import torch
from torch import nn
from torch.nn import functional as F
from torchvision import datasets, transforms
import torchvision
import pandas as pd
import matplotlib.pyplot as plt
from d2l import torch as d2l
from PIL import Image
train_data=pd.read_csv(r"D:\apycharmblackhorse\leaves\train.csv")
test_data=pd.read_csv(r"D:\apycharmblackhorse/leaves/test.csv")
train_images=train_data.iloc[:,0].values #把所有的训练集图片路径读进来成list
print("训练集数量:",len(train_images))
n_train=len(train_images)
test_images=test_data.iloc[:,0].values
print("测试集数量:",len(test_images))
n_test=len(test_images)
train_labels = pd.get_dummies(train_data.iloc[:, 1]).values.astype(int).argmax(1)
#独热编码后找到每行最大的索引记下来就是类别号,而顺序与独热编码colums,也就是与下方排序一致
# print(len(train_labels),train_labels)
#记录并排序所有的类别名
train_labels_header = pd.get_dummies(train_data.iloc[:, 1]).columns.values
print("总类别:",len(train_labels_header))
classes=len(train_labels_header)
3.构建自定义dataset
继承 torch.utils.Dataset 类,自定义树叶分类数据集:
#继承 torch.utils.Dataset 类,自定义树叶分类数据集
class leaves_dataset(torch.utils.data.Dataset):
#root数据目录, images图片路径, labels图片标签, transform数据增强
def __init__(self, root, images, labels, transform):
super(leaves_dataset, self).__init__()
self.root = root
self.images = images
if labels is None:
self.labels = None
else:
self.labels = labels
self.transform = transform
#获得指定样本
def __getitem__(self, index):
image_path = self.root + self.images[index]
image = Image.open(image_path)
#预处理
image = self.transform(image)
if self.labels is None:
return image
label = torch.tensor(self.labels[index])
return image, label
#获得数据集长度
def __len__(self):
return self.images.shape[0]
构建读取数据与预处理:
def load_data(images, labels, batch_size, train):
aug = []
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
if (train):
aug = [torchvision.transforms.CenterCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),
transforms.ToTensor(),
normalize]
else:
aug = [torchvision.transforms.Resize([256, 256]),
torchvision.transforms.CenterCrop(224),
transforms.ToTensor(),
normalize]
transform = transforms.Compose(aug)
dataset = leaves_dataset(r"D:\apycharmblackhorse\leaves\\", images, labels, transform=transform)
if train==True:type="训练"
else:type="测试"
print("载入:",dataset.__len__(),type)
return torch.utils.data.DataLoader(dataset=dataset, batch_size=batch_size, num_workers=0, shuffle=train)
train_iter = load_data(train_images, train_labels, 512, train=True)4.初始化网络
使用官方预训练模型初始化网络,并修改输出类别数:
#初始化网络
net = torchvision.models.resnet18(pretrained=True)
net.fc = nn.Linear(net.fc.in_features, classes)
nn.init.xavier_uniform_(net.fc.weight)
net.fc![]()
5.训练
定义迭代器、优化器以及其他超参数,进行训练:
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=64, num_epochs=20,
param_group=True):
train_slices = random.sample(list(range(n_train)), 15000)
test_slices = list(set(range(n_train)) - set(train_slices))
train_iter = load_data(train_images[train_slices], train_labels[train_slices], batch_size, train=True)
test_iter = load_data(train_images[test_slices], train_labels[test_slices], batch_size, train=False)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
#别的层不变,最后一层10倍学习率
trainer = torch.optim.Adam([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.Adam(net.parameters(), lr=learning_rate,
weight_decay=0.001)
print(111)
try:
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)
except Exception as e:
print(e)
#%%
#较小的学习率,通过微调预训练获得的模型参数
train_fine_tuning(net, 1e-3)
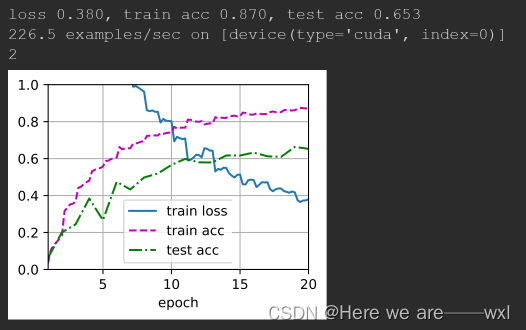
小破脑跑得慢,之前不用预训练5个epoch后acc大概只能到0.3 ,使用预训练后到了0.6,但实际上感觉对于树叶的针对性分类还是需要从头开始才是最好的选择,资源不够这里就不做尝试了,大概尝试情况: