【机器学习算法】机器学习:支持向量机(SVM)
转载自:
【精选】机器学习:支持向量机(SVM)-CSDN博客
1.概述
1.1,概念
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面,可以将问题化为一个求解凸二次规划的问题。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
具体来说就是在线性可分时,在原空间寻找两类样本的最优分类超平面。在线性不可分时,加入松弛变量并通过使用非线性映射将低维度输入空间的样本映射到高维度空间使其变为线性可分,这样就可以在该特征空间中寻找最优分类超平面。
SVM使用准则:nn 为特征数, 为训练样本数。
如果相较于mm而言,nn要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
如果nn较小,而且mm大小中等,例如nn在 1-1000 之间,而mm在10-10000之间,使用高斯核函数的支持向量机。
如果nn较小,而mm较大,例如nn在1-1000之间,而𝑚大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
1.2 SVM的优缺点
优点:
支持向量机算法可以解决小样本情况下的机器学习问题,简化了通常的分类和回归等问题。
由于采用核函数方法克服了维数灾难和非线性可分的问题,所以向高维空间映射时没有增加计算的复杂性。换句话说,由于支持向量计算法的最终决策函数只由少数的支持向量所确定,所以计算的复杂性取决于支持向量的数目,而不是样本空间的维数。
支持向量机算法利用松弛变量可以允许一些点到分类平面的距离不满足原先要求,从而避免这些点对模型学习的影响。
缺点:
支持向量机算法对大规模训练样本难以实施。这是因为支持向量机算法借助二次规划求解支持向量,这其中会涉及m阶矩阵的计算,所以矩阵阶数很大时将耗费大量的机器内存和运算时间。
经典的支持向量机算法只给出了二分类的算法,而在数据挖掘的实际应用中,一般要解决多分类问题,但支持向量机对于多分类问题解决效果并不理想。
SVM算法效果与核函数的选择关系很大,往往需要尝试多种核函数,即使选择了效果比较好的高斯核函数,也要调参选择恰当的 参数。另一方面就是现在常用的SVM理论都是使用固定惩罚系数 ,但正负样本的两种错误造成的损失是不一样的。
2.硬间隔
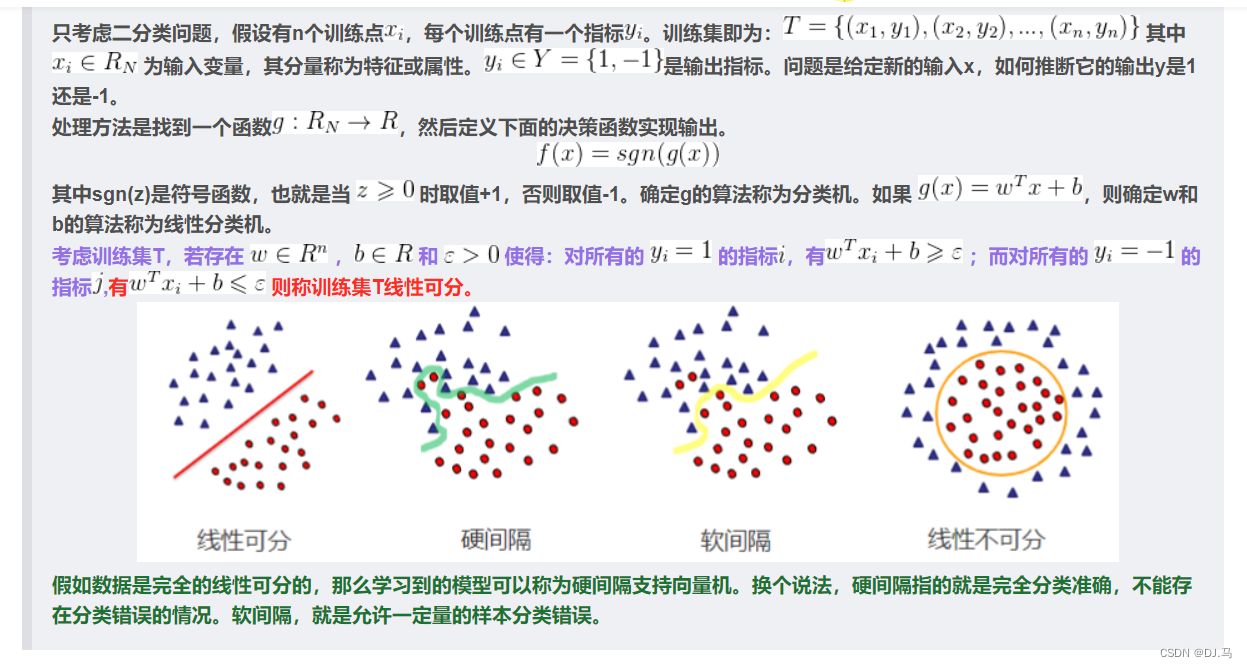
2.1 求解间隔
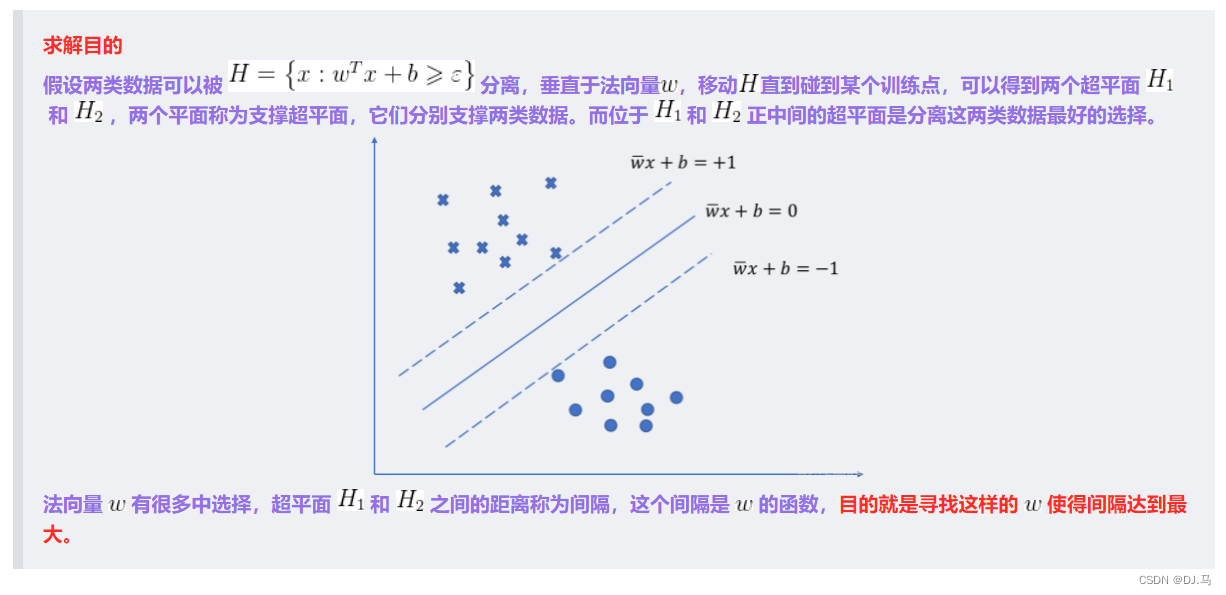


2.2.对偶问题


2.3,感知机与SVM线性可分的区别
感知机的目的是尽可能使得所有样本分类正确,而SVM的目标是分类间隔最大化。支持向量机追求大致正确分类的同时,一定程度上避免过拟合。
感知机使用的学习策略是梯度下降,而SVM采用的是由约束条件构造拉格朗日函数,然后求偏导为0求得极值点。
3,软间隔


4,核函数



5,模型评估和超参数调优
5.1,模型评估
Holdout检验:Holdout检验是最简单也是最直接的验证方法,它将原始的样本集合随机划分成训练集和验证集两部分。比方说,对于一个2分类问题,将样本按照7:3的比例分成两部分,70%的样本用于模型训练;30%的样本用于模型验证,包括绘制ROC曲线、计算精确率和召回率等指标来评估模型性能。
Holdout检验的缺点很明显,即在验证集上计算出来的最后评估指标与原始分组有很大关系。
交叉验证
k-fold交叉验证:首先将全部样本划分成k个大小相等的样本子集;依次遍历这k个子集,每次把当前子集作为验证集,其余所有子集作为训练集,进行模型的训练和评估;最后把k次评估指标的平均值作为最终的评估指标,k通常取10。

留一验证:每次留下1个样本作为验证集,其余所有样本作为测试集。样本总数为n,依次对n个样本进行遍历,进行n次验证,再将评估指标求平均值得到最终的评估指标。在样本总数较多的情况下,留一验证法的时间开销极大。
留p验证:每次留下p个样本作为验证集,而从n个元素中选择p个元素有种可能,因此它的时间开销更是远远高于留一验证,故而很少在实际中应用。
5.2,超参数调优
超参数搜索算法一般包括:目标函数(算法需要最大化/最小化的目标)、搜索范围(通过上限和下限来确定)、算法的其他参数(搜索步长)。
网格搜索:网格搜索是最简单、应用最广泛的超参数搜索算法,它通过查找搜索范围内的所有的点来确定最优值。如果采用较大的搜索范围以及较小的步长,网格搜索有很大概率找到全局最优值。然而,这种搜索方案十分消耗计算资源和时间,特别是需要调优的超参数比较多时。因此,在实际应用中,网格搜索算法一般会先使用较广的搜索范围和较大的步长,来寻找更精确的最优值。这种方案可以降低所需的时间和计算量,但由于目标函数一般是非凸的,所以很可能会错过全局最优值。
随机搜索:随机搜索的思想与网格搜索比较相似,只是不再测试上界和下界之间的所有值,而是在搜索范围中随机选取样本点。它的理论依据是,如果样本点集足够大,那么通过随机采样也能大概率地找到全局最优值或其近似值。随机搜索一般会比网格搜索要快一些,但是和网格搜索一样,结果无法保证。
贝叶斯优化算法:贝叶斯优化算法在寻找最优参数时,采用了与网格搜索、随机搜索完全不同的方法。网格搜索和随机搜索在测试一个新点时,会忽略前一个点的信息;而贝叶斯优化算法则充分利用了之前的信息。贝叶斯优化算法通过对目标函数形状进行学习,找到使目标函数向全局最优值提升的参数。具体来说,它的学习目标函数形状的方法是,首先根据先验分布,假设一个搜索函数;然后每一次使用新的采样点来测试目标函数时,利用这个信息来更新目标函数的先验分布;最后算法测试由后验分布给出全局最值最可能出现的位置的点。对于贝叶斯优化算法,有一个需要注意的地方,一旦找到了一个局部最优值,它会在该区域不断采样,所以很容易陷入局部最优值。为了弥补这个缺陷,贝叶斯优化算法会在探索和利用之间找到一个平衡点,“探索”就是在未取样的区域获取采样点;而“利用”则是根据后验分布在最可能出现的全局最值的区域进行采样。