机器学习第10天:集成学习
文章目录
机器学习专栏
介绍
投票分类器
介绍
代码
核心代码
示例代码
软投票与硬投票
bagging与pasting
介绍
核心代码
随机森林
介绍
代码
结语
机器学习专栏
机器学习_Nowl的博客-CSDN博客
介绍
集成学习的思想是很直观的:多个人判断的结合往往比一个人的想法好
我们将在下面介绍几种常见的集成学习思想与方法
投票分类器
介绍
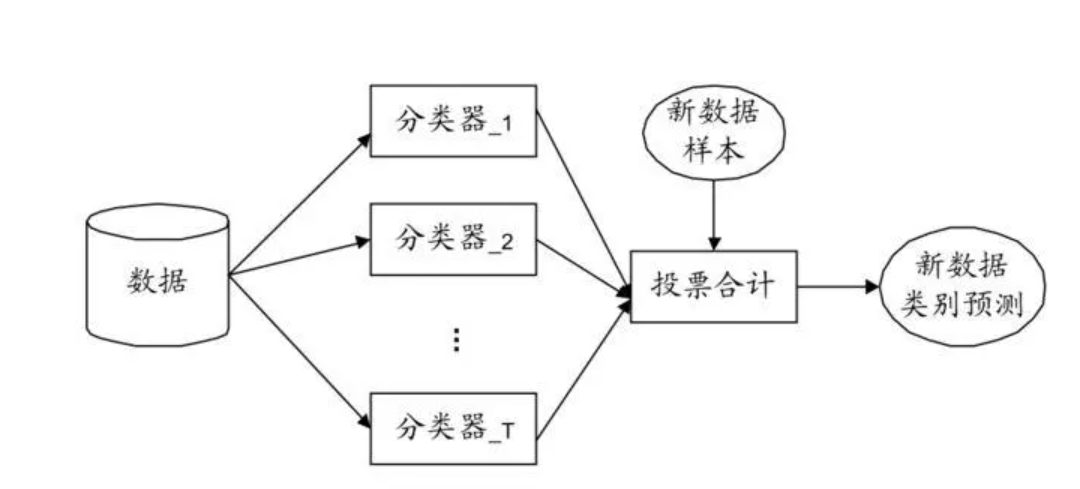
假如我们有一个分类任务,我们训练了多个模型:逻辑回归模型,SVM分类器,决策树分类器,然后我们看他们预测的结果,如果两个分类器预测为1,一个分类器预测为0,那么最后模型判断为1,采用的是一种少数服从多数的思想
代码
核心代码
引入投票分类器库,并创建模型
from sklearn.ensemble import VotingClassifier
log_model = LogisticRegression()
tree_model = DecisionTreeClassifier()
svc_model = SVC()
voting_model = VotingClassifier(
estimators=[('lr', log_model), ('df', tree_model), ('sf', svc_model)],
voting='hard'
)
voting_model.fit(x, y)例子中创建了三个基础分类器,最后再组合成一个投票分类器
示例代码
我们在鸢尾花数据集上测试不同模型的分类效果
from sklearn.ensemble import VotingClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data # petal length and width
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
log_model = LogisticRegression()
tree_model = DecisionTreeClassifier()
svc_model = SVC()
voting_model = VotingClassifier(
estimators=[('lr', log_model), ('df', tree_model), ('sf', svc_model)],
voting='hard'
)
for model in (log_model, tree_model, svc_model, voting_model):
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(model, accuracy_score(y_test, y_pred))运行结果

该示例代码可以看到各个模型在相同数据集上的性能测试,该示例的数据集较小,所以性能相差不大,当数据集增大时 ,集成学习的性能往往比单个模型更优
软投票与硬投票
当基本模型可以计算每个类的概率时,集成学习将概率进行平均计算得出结果,这种方法被称作软投票,当基本模型只能输出类别时,只能实行硬投票(以预测次数多的为最终结果)
bagging与pasting
介绍
除了投票分类这种集成方法,我们还有其他方法,例如:使用相同的基础分类器,但是每个分类器训练的样本将从数据集中随机抽取,最后再结合性能,若抽取样本放回,则叫做bagging方法,若不放回,则叫做pasting方法
核心代码
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
model = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1
)
model.fit(X_train, y_train)若基本分类器可以计算每个类的概率,BaggingClassifier自动执行软分类方法
bootstrap = True设置模型采用Bagging放回采样法
n_jobs参数代表用多少CPU内核进行训练何预测(-1代表使用所有可用内核)
设置为False时采用Pasting不放回采样法
随机森林
介绍

随机森林就是一种基本模型是决策树的Bagging方法,你可以使用BaggingClassifier集成DecisionTreeClassifier,也可以使用现成的库
代码
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, max_leaf_nodes=16, n_jobs=-1)
model.fit(X_train, y_train)max_leaf_nodes限制了子分类器的最大叶子节点数量
结语
集成学习就是利用了一个很基本的思想:多数人的想法往往比一个人的想法更优,同时概率论中也有这样一个场景:实验次数越多,概率越接近本质